TL;DR
- ODC分析(Orthogonal Defect Classification 分析)とは、不具合を複数の属性で分類・分析する手法
- GAS+ChatGPT APIで不具合一覧を取得し、ODC分析のタイプ属性(Defect Type:不具合を修正するために実行された作業の種類)を自動付与する仕組みを構築。分類基準の俗人化を排除
- 4時間に1回ラベリング処理を回し、ほぼリアルタイムに不具合分布の変化を可視化
- プロンプトのポイントは以下の2つ
- 「事象ではなく修正内容だけをAIに渡す」
- 「ODC分析の定義と優先順位をプロンプトにきっちり書く」
想定読者
- ODC分析や不具合分析を使って 開発プロセス改善 をしたいQAエンジニア/開発リーダー
- 不具合を収集しているが、分析まではできていないチーム
- テストの期間中に、「テストしながら改善サイクルも回したい」 と考えている人
- AI を使って、テスト・品質管理まわりを自動化/省力化したい 人
背景:ODC分析で「プロセスの怪しいところ」を探したい
単体・結合テストで見つかった不具合から、開発プロセス上の問題をあぶり出すために、ODC分析(Orthogonal Defect Classification) を使っています。
ODC分析(Orthogonal Defect Classification)とは、1992年に米IBM社のワトソン研究所で確立された「欠陥分類手法」です。不具合(欠陥)を複数の属性で体系的に分類・集計し、その出方の傾向を分析することで、開発プロセスや各工程の品質を定量的に可視化し、必要な改善アクションを導き出すための定量的分析手法です。
詳細は、ソフトウェア不具合改善手法 ODC分析 工程の「質」を可視化する(杉崎眞弘・佐々木方規 著)をご覧ください。
やりたいことはざっくり言うと:
- 不具合に タイプ属性(Defect Type) をラベリングする
- ODC分析として想定している 「期待される不具合分布」からの乖離 を見る
- 乖離している部分を「プロセス的に怪しいポイント」として特定
- テスト期間中に 改善施策の検討・実施 まで持っていく
つまり、不具合を一件ずつ眺めるのではなく、「分布の歪み」を手がかりにプロセス改善を進めたい、という狙いです。
課題:ラベリング作業が重くて、テスト期間中に間に合わない
実際にODC分析のタイプ属性を人手で付けてみると、すぐに限界が見えてきました。
- 不具合チケットを 1件ずつ読んでタイプを付ける作業がとにかく重い
- 人によって タイプ属性の判断がブレる
- 作業に時間がかかり、ラベリングがテスト期間後までずれ込む
- 結果として、
- 「テスト中に問題が大量に出ているタイミング」で打ち手を打てない
- 「ラベル付けをやり切った感」で終わり、肝心の傾向分析や改善施策の検討まで行けない
ODC分析の本来の目的は プロセス改善 なのに、その前段の 準備作業であるラベリングで手一杯 の状態でした。
解決策:タイプ属性のラベリングをAIに任せる
そこで、思い切って タイプ属性のラベリングをAI(ChatGPT)に任せる ことにしました。
構成はこんな感じです。
- 不具合をスプレッドシートに展開
- GAS(Google Apps Script)で 「タイプ属性未設定」のチケットだけ抽出
- ChatGPT API に「修正内容」とプロンプトを渡し、
タイプ属性を自動判定 させる - 判定結果をスプレッドシートに書き戻し、
- Google Looker で 期待分布との乖離をグラフ化
- テスト期間中、ほぼリアルタイムで分布を確認しつつ、約2週間に1回のペースで深掘り分析+改善施策議論
GASは 4時間に1回のトリガー で実行しているので、新しいチケットが登録されてから数時間以内には、ODC分析のタイプ属性が付与された状態でダッシュボードに反映されます。
プロンプト設計のポイント:事象ではなく「修正内容」を渡す
一番効いた工夫がこれです。
なぜ「修正内容だけ」にしたのか
最初は「不具合事象」と「修正内容」の両方をAIに渡していましたが、次のような「ズレ」が頻発しました。
- 画面の表示値が間違っている不具合(事象)
→ 実際の修正は「条件分岐の見直し」や「ロジック修正」 - 本来のタイプ属性としては「条件分岐」や「アルゴリズム」が妥当
- しかし、事象に引っ張られて「値の設定」が選ばれてしまう
ODC分析のタイプ属性の判定で重要なのは、『どこをどう直したか』という修正のアクションです。これが不具合の原因(Source)やプロセス上の問題を間接的に示唆します。
そこで割り切って、
- 不具合の修正内容 ≒ タイプ属性
とみなし、AIには修正内容だけを渡す 形にしました。
実際に使っているプロンプト
タイプ属性の定義と選択基準、優先順位をきちんと書いたうえで、「タイプ属性」を1つずつ選び、理由も書かせる プロンプトにしています。
(長いですが、そのまま貼ります)
# 命令書:
あなたはプロのQAエンジニア。単体テストの不具合分析を担当する。以下の「制約条件」、「タイプ属性の選択基準」、「修正内容」をもとに、適切なタイプ属性を1つずつ選択せよ。
## 制約条件
タイプ属性は不具合を修正するために実行された作業の種類を表す属性であり、以下の8つから1つ選択する。
- 値の設定
- 条件分岐
- アルゴリズム
- タイミング・順序
- インターフェース
- 機能性
- ビルド・パッケージ・統合
- 関連ドキュメント
レスポンス前に、選択したタイプ属性が以下の「タイプ属性の選択基準」に適合しているかを**再確認**し、**最適なタイプ属性を選択すること**。
## タイプ属性の選択基準
### 1. 値の設定(Assignment)
- 値の割り当てやマッピングの修正
- 画面項目の表示位置、設定、並び順、表示制御、表示・非表示、項目ラベルの表示内容の修正。この場合の限定子は「誤り」
- 帳票の表示桁数の修正。この場合の限定子は「誤り」
- 引数・戻り値からの値のマッピングの修正
- リストロジックやコンボボックスの設定、連携項目の設定、入力補助画面・埋め込み画面の設定の修正
### 2. 条件分岐(Checking)
- 条件分岐(if文やスイッチなど)の過不足を修正
- 分岐条件の不備
- 条件式の誤り
- 修正内容に、「××場合、〇〇」という記載がある場合
### 3. アルゴリズム(Algorithm)
- 既存ロジックへの処理追加
- ロジックの修正・内部修正、引数不足の修正
- 計算方法の修正
- 項目補完処理やイベント処理における処理対象項目の過不足修正
- 必須入力・任意入力の制御を修正
- チェック処理におけるエラー条件不足を修正
- ポップアップを含むメッセージの出力処理の追加や修正
### 4. タイミング・順序(Timing/Serialize)
- 処理のタイミングや処理順序の修正
- チェック処理の重複実行を修正
- 実行タイミングの修正
- 非同期処理の同期ミスの修正
- イベント処理の遅延の修正
### 5. インターフェース(Interface)
- モジュール間・コンポーネント間・プロダクト間連携の不備の修正
- APIや外部システムとの不整合の修正
- 別画面遷移時の連携を修正
- メイン画面と補助画面の連携を修正
- ハードウェアとソフトウェア間などの連携部分を修正
### 6. 機能性(Function)
- アプリケーションの実行そのものに関わる不具合
- 機能そのものの実装漏れ
- 機能のレベルの誤動作の修正
- 不正なデータ処理の修正
- データ構造に関する不具合の修正
- パフォーマンスの問題の修正
- イベント処理や入力制御処理の実装漏れを修正
- 機能の追加・修正・移植・削除を行った不具合
### 7. ビルド・パッケージ・統合(Bid/Pkg/Mrg)
- ビルドやクラス参照、ライブラリ・バージョン管理などの構成管理を修正
### 8. 関連ドキュメント(Documents)
- 要求仕様書や設計仕様書、コードのコメント、ガイド、マニュアル、ReadMeなどの修正
- 翻訳漏れ、テストケース・テストデータの修正
## 優先順位
複数のタイプ属性に該当する場合は、以下の優先度で選択する。
1. 関連ドキュメント
2. ビルド・パッケージ・統合
3. 値の設定
4. 条件分岐
5. アルゴリズム
6. タイミング・順序
7. インターフェース
8. 機能性
## **出力形式:**
タイプ属性:
選択理由:
GAS側では、このプロンプトに 修正内容のテキストを埋め込んで ChatGPT API を呼び、返却された「タイプ属性」「選択理由」をそのままシートに書き込むだけです。
運用してみてどう変わったか
1. テスト期間中に改善サイクルを回せるようになった
GASを 4時間に1回 自動実行することで、
- 新しい不具合が登録される
- 数時間以内に「タイプ属性」が自動付与される
- Looker のダッシュボードで タイプ別の分布と推移がほぼリアルタイムで見える
- テスト期間中も、だいたい 2週間に1回のペースで深掘り分析+エンジニアとの議論 を回せる
という状態になりました。
以前は
「ラベル付けが終わる頃にはテストが終わっていて、 改善は次フェーズの反省会で…」
となりがちでしたが、今は 「テスト中、問題が見えているうちに改善の手を打てる」 ようになっています。
不具合の分布、期待値は以下のようにグラフ化します。
棒グラフがタイプ属性の実際の割合、折れ線グラフがタイプ属性の期待値の割合を表しています。
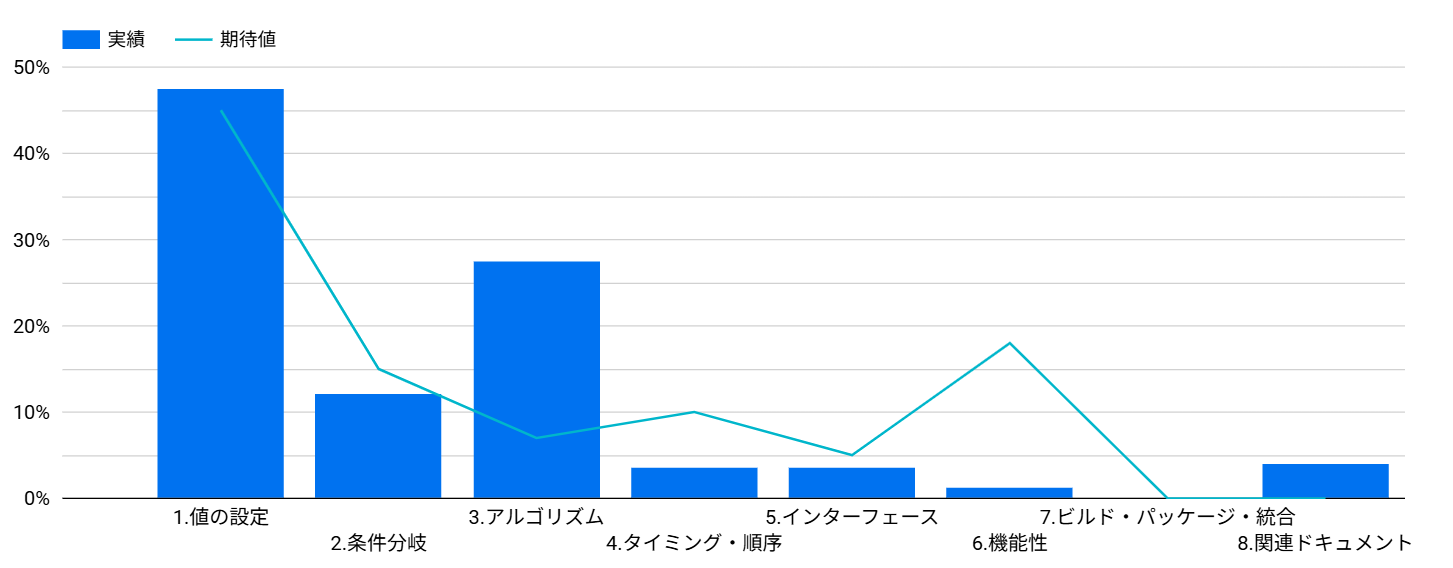
この分布の場合、アルゴリズムの実測値が期待値より高く乖離していることが分かります。
2. ラベリングのコストとブレがかなり減った
- 人手でやっていたラベリング作業がほぼなくなり、
「分布の読み解き」「現場ヒアリング」「施策検討」に集中できています - プロンプトに定義と優先順位を書いているおかげで、
同じパターンの修正には一貫したタイプ属性が付きやすくなり、ブレも減少しました
完全に人間と同じ判断にはなりませんが、「プロセスの傾向を見る」には十分な精度 が出ている感覚です。
課題と今後やりたいこと
1. AIラベルの品質モニタリング
ランダムにサンプルを取って人間が再ラベリングし、
- 一致率
- どのタイプ同士で食い違いやすいか
を確認し、プロンプトの定義や例を微調整して精度を上げたいと考えています。
2. タイプ属性以外の軸もAIに推定させる(トリガー・ソース・インパクト)
今は「タイプ属性」にフォーカスしていますが、ODC分析の考え方に沿うと、本当は 他の軸も掛け合わせてこそ深い分析 ができます。
そこで今後は、次のような属性も AI にラベリングさせて、より深い分析に広げていきたいと考えています。
-
トリガー属性(Defect Trigger)
不具合が表面化した動機を表す属性- 単体テスト/結合テスト/性能テストなど、どのテスト活動で見つかったか
- コードレビュー/仕様レビュー/静的解析など、どの検出手段で見つかったか
- 運用時/バッチ実行時/データ移行時 など、どんな状況で露見したか
-
ソース属性(Defect Source)
不具合が摘出されたコード部分、あるいは適用したプロセスの構成要素を表す属性- 画面、API、バッチ、DBスキーマ、設定ファイル などの技術的レイヤ
- 要件定義/設計/実装/テスト設計 などの工程・成果物
-
インパクト属性(Defect Impact)
不具合によって引き起こされるお客様(利用者、ユーザ、パートナー、エンジニア)への影響を表す属性- 影響対象(エンドユーザ/業務担当/パートナー/運用担当 など)
- 影響タイプ(表示誤り/業務処理誤り/データ不整合/性能劣化/サービス停止 など)
- 影響の重さ(軽微/中/重/致命的 などの簡易ランク)
これらを AI でラベリングできるようになると、例えば次のようなクロス分析ができるようになります。
-
タイプ属性 × トリガー属性
-
条件分岐 × 異常系テストが多い → 異常系シナリオ設計や仕様整理に課題がありそう
-
-
タイプ属性 × ソース属性
-
値の設定 × 画面が突出 → UIルールの共通化・設計レビューを強化すべき
-
-
インパクト属性 × ソース属性 × トリガー属性
-
業務処理誤り(重) × バッチ × 結合テストで発覚→ 「運用まで出ていたら危なかった」
要件・設計レビューや単体テスト観点の強化に繋げる、など
-
このような分析ができるようになると、「なんとなくこの辺が弱そう」から、「どの工程・どのレイヤ・どの検出活動を強化すべきか」までもう一段具体的に改善ポイントを検出できる と期待しています。
タイプ属性のラベリング運用を安定させつつ、次のステップとして トリガー属性・ソース属性・インパクト属性をラベリングするプロンプトの設計 にも着手したいと思います。
まとめ
ODC分析は「プロセス改善のためのセンサー」として強力ですが、属性のラベリングが重いと、本来やりたい改善活動までたどり着けない という問題があります
そこで、タイプ属性のラベリングをAIに任せ、テスト期間中に2週間サイクルで深掘り分析&改善施策検を回せるようにしたことで、「ラベリング作業」ではなく「プロセス改善」そのものに時間を使える 形に近づきました。
今後は、
- トリガー属性(どういうきっかけで表面化したか)
- ソース属性(どのコード/工程・成果物が源泉か)
- インパクト属性(誰にどの程度の影響を与えるか)
といった軸も AI でラベリングし、タイプ属性と掛け合わせて より深いプロセス分析 に発展させていきたいと考えています。
- 「ODC分析は気になっているけど、ラベリングが重くて続かない」
- 「テスト期間中に改善サイクルまで回せていない」
と感じている方は、まずは一部の不具合だけでもよいので、AIによるラベリング+分布の可視化 から始めてみると、かなり見える景色が変わるのではないでしょうか。