
TL;DR;
新サービスや既存サービスをKubernetesに移行するたびに、ログの収集設定のためインフラエンジニア待ちになってしまうのは面倒ですよね。
そこで、アプリのログをFluentdとDatadog LogsやStackdriver Loggingで自動的に収集する方法を紹介します。
主に以下のOSSを利用します。
今回はDatadog Logsを使いますが、Stackdriver Loggingを使う場合でもUIやAPIクレデンシャル等の設定以外は同じです。
お急ぎの方へ: アプリ側の設定手順
標準出力・標準エラーログを出力するだけでOKです。
参考: The Twelve-Factor App (日本語訳)
詳しくは、この記事の「サンプルアプリからログを出力する」以降を読んでください。
あとはクラスタ側に用意しておいたFluentdの仕事ですが、Kubernetesがノード上に特定のフォーマットで保存するため、アプリ毎の特別な設定は不要です。
まえおき1: なぜDatadogやStackdriver Loggingなのか
分散ロギングのインフラを準備・運用するのがつらい
分散ロギングと一口にいっても、実現したいことは様々です。例えば、多数のサービス、サーバ、プロセス、コンテナから出力されたログを
- 分析などの用途で使いやすいようにETLしてRedshiftのようなデータウェアハウスに投入しておきたい
- S3などのオブジェクトストレージに低コストでアーカイブしたい
- ほぼリアルタイムでストリーミングしたり、絞込検索したい
- Web UI、CLIなど
1.はtd-agent + TreasureData or BigQuery、2.はfluentd (+ Kinesis Streams) + S3、3.はfilebeat or Logstash + Elasticsearch + Kibana、Graylog2、専用のSaaSなど、ざっとあげられるだけでも多数の選択肢があります。
方法はともかく、できるだけ運用保守の手間を省いて、コアな開発に集中したいですよね。
メトリクス、トレース、ログを一つのサービスで一元管理したい・運用工数を節約したい
「Kubernetesにデプロイしたアプリケーションのメトリクスを自動収集する - Qiita」でも書きましたが、例えばKubernetesの分散ロギング、分散トレーシング、モニタリングをOSSで実現すると以下のような構成が定番だと思います。
- 基本的なグラフ作成とメトリクス収集、アラート設定はPrometheus
- 分散ログはEKF(Elasticsearch + Kibana Fluentd)
- 分散トレースはZipkinやJaeger
もちろん、ソフトウェアライセンス費用・サポート費用、将来の拡張性などの意味では良い判断だと思います。
一方で、
- アラートを受けたときに、その原因調査のために3つもサービスを行ったり来たりするのは面倒
- 人が少ない場合に、セルフホストしてるサービスの運用保守に手間をかけたくない
- アカウント管理を個別にやるだけでも面倒・・最低限、SSO対応してる?
などの理由で
- 個別のシステムではなく3つの役割を兼ねられる単一のシステム
がほしいと思うことがあると思います。
なぜfluentd + Datadog Logs/Stackdriver Loggingなのか
StackdriverとDatadogはSaaSで、かつ(それぞれサブサービスで、サブサービス間連携の度合いはそれぞれではありますが、)3つの役割を兼ねられます。
fluentd
SaaSへログを転送する目的でfluentdを利用します。
Kubernetesのログを収集するエージェントとしてfluentdがよく使われている関係で、Kubernetes界隈でよく使われるfluentdプラグインに関しては、よくある「メンテされていない、forkしないと動かない」という問題に遭遇しづらいというのが大きな利点です。
fluentdの代替とログ収集・集約システムのアーキテクチャ
最もコンテナと近い場所で動くログフォワーダー・ログコレクターの候補は
- fluentd
- Filebeat
- rsyslogd
- fluent-bit
などがあります。
fluent-bitはcで書かれていて、kubernetesメタデータをログに付与する機能などもあり、今後が楽しみなOSSです。Filebeatは最近Dockerコンテナの自動発見機能が追加され、また直感的な設定でコンテナの条件によってログパーサーを選択できる点が期待できます。ただ、本番利用の事例はfluentdのほうが多い印象です。
Filebeatはfluent-bit同様に将来有望そうですが、現実的に利用するためにはいくつか足りない点があると思います。以下に参考リンクを貼っておきます。
- filebeat add_kubernetes_metadata kicks in too late · Issue #5377 · elastic/beats
- Filebeat deployment in Kubernetes/Docker - Beats / Filebeat - Discuss the Elastic Stack
- Implement default fallback option when using templates in autodiscover · Issue #6084 · elastic/beats
ただ、カスタマイズがし易いという利点があるので、ある程度の開発コストを許容できるなら有望かもしれません。
また、ログフォワーダーからのログを加工などの目的で中継する先としては、
- LogZoom
- Logstash
- AWS Kinesis Firehose
- AWS Kinesis Data Streams
などがあります。
LogZoomは既に構造化されたログを対象としている、Grok Parserがない、LogstashはRubyベースでfluentd同様ログの加工が得意、Kinesis Firehose/Data Streamsはaws公式のfluentプラグインの存在や、ログの加工をAWS Lambdaを使ってAWS側におまかせできる、などそれぞれ特徴があるので、用途によって選択するとよいでしょう。
参考:
最終的にログを蓄積する先には
- Elasticsearch
- CloudSearch
- Datadog
- CloudWatch Logs
- S3
- Redshift
- BigQuery
- ...
などがあります。
目的に応じて、1つ以上のログ蓄積先を選ぶとよいです。
どこで何をやるか
ログの2次加工や蓄積にマネージドサービスが使える場合は、できるだけクラスタ外で2次加工や蓄積を行ったほうがよいです。
クラスタ内で動くログエージェントでは、
- 非構造的なログがあれば、それをJSONなどに構造化する
- クラスタやPod、コンテナ等のその場でしか知り得ないメタデータをログに付与する
- ログを一つ二つの転送先に転送する
ということに集中して、ETLやログのアーカイビング、比較的短期間のログを準リアルタイムで見るためのログビュワーへの転送、などは転送先で一元的に行ったほうが楽です。
Kubernetes on AWSでの設計例
Kubernetes on AWSでマネージドサービスを最大限活用するなら以下のようにするといいでしょう。
- ログフォワーダー
- 各ノードにfluentd
- aws-fluent-plugin-kinesisでKinesis Data Streamsへ(Firehoseではなく)
- fluent-plugin-datadog、fluent-plugin-datadog-logでDatadog Logsへ
- ここは他にも選択肢あり
- fluent-plugin-google-cloudでGCP Stackdriver Loggingへ
- fluent-plugin-aws-elasticsearch-serviceでESへ
- ここは他にも選択肢あり
- 各ノードにfluentd
- 中継先
- KPLでKinesis Data Streamsへ。
- そのあと、S3へgzip形式でアーカイビング、ElasticsearchやRedshiftへの準リアルタイムな取り込みはFirehoseへ。
- その他、独自アプリからログを読む場合は、Data Streamsに自作のConsumerをつなげる。
- (任意) ETL
- AWS GlueのCrawlerでS3に蓄積されたgzip圧縮されたログをカタログ化(AthenaやRedshift Spectrumからテーブルとして認識させる)
- AthenaやRedshift Spectrum集計用にAWS Glue JobでParquet等の列指向のフォーマットに変換
- 最終的な宛先
- AWS Elasticsearch
- Redshift
- 利用
- S3に蓄積された(生)ログ、Glue Jobで変換後のテーブルは、必要に応じてAthenaやRedshift Spectrumで分析
- Glue Crawlerでカタログ化したあとAthenaからテーブルとして見えるようになる
- FirehoseからRedshiftに入れたデータはRedshiftで分析
- S3に蓄積された(生)ログ、Glue Jobで変換後のテーブルは、必要に応じてAthenaやRedshift Spectrumで分析
参考:
- Kinesis Producer Library(KPL)とfluentdとLambdaを連携してKinesisのスループットを上げる | Developers.IO
- KinesisStreamにKPLで入れたデータをKinesisFirehoseを通し、Lambdaで加工してからS3に保存してみたり - はじめに。
まえおき2: なぜDatadogなのか
もともとStackdriver Loggingを利用していたのですが、以下の理由で乗り換えたので、この記事ではDatadog Logsの例を紹介することにします。
- メトリクスやAPMで既にDatadogを採用していた
- UI面で使いやすさを感じた
UI面に関して今のところ感じている使いやすさは以下の2点です。
- ログメッセージの検索ボックスでメタデータの補完が可能
-
hostで絞込をしようとすると、hostの値が補完される - あとで説明します
-
- 柔軟なFaceting
- Datadog LogsもStackdriver Loggingもログにメタデータを付与できるが、Datadog Logsは任意のメタデータキーで絞り込むためのショートカットを簡単に追加できる
- あとで説明します
Stackdriver Loggingを利用する場合でも、この記事で紹介する手順はほぼ同じです。Kubernetesの分散ロギングをSaaSで実現したい場合は、せっかくなので両方試してみることをおすすめします。
Fluentdのセットアップ手順
DatadogのAPIキー取得
Datadog > Integratinos > APIsの「New API Key」から作成できます。

以下では、ここで取得したAPIキーをDD_API_KEYという環境変数に入れた前提で説明を続けます。
fluentdのインストール
今回はkube-fluentdを使います。
$ git clone git@github.com:mumoshu/kube-fluentd.git
$ cd kube-fluentd
# 取得したAPIキーをsecretに入れる
$ kubectl create secret generic datadog --from-literal=api-key=$DD_API_KEY
# FluentdにK8Sへのアクセス権を与えるためのRBAC関連のリソース(RoleやBinding)を作成
$ kubectl create -f fluentd.rbac.yaml
# 上記で作成したsecretとRBAC関連リソースを利用するfluentd daemonsetの作成
$ kubectl create -f fluentd.datadog.daemonset.yaml
設定内容の説明
今回デプロイするfluentdのmanifestを上から順に読んでみましょう。
kind: DaemonSet
Kubernetes上のアプリケーションログ(=Podの標準出力・標準エラー)は各ノードの/var/log/containers以下(より正確には、そこからsymlinkされているファイル)に出力されます。それをfluentdで集約しようとすると、必然的に各ノードにいるfluentdがそのディレクトリ以下のログファイルをtailする構成になります。fluentdに限らず、何らかのコンテナをデプロイしたいとき、KubernetesではPodをつくります。Podを各ノードに一つずつPodをスケジュールするためにはDaemonSetを使います。
updateStrategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1
DaemonSetをアップデートするとき(例えばDockerイメージを最新版にするためにタグの指定を変える)、Podを1つずつローリングアップデートします。アップデートによってfluentdが動かなくなった場合の影響を抑えることが目的ですが、気にしない場合はこの設定は記述は不要です。
serviceAccountName: fluentd-cloud-logging
kubectl -f fluent.rbac.yamlで作成されたサービスアカウントを利用する設定です。これがないとデフォルトのサービスアカウントが使われてしまいますが、ほとんどのツールでつくられたKubernetesクラスタではデフォルトのサービスアカウントに与えられる権限が絞られているので、デフォルトのサービスアカウントではkube-fluentdが動作しない可能性があります。
tolerations:
- operator: Exists
effect: NoSchedule
- operator: Exists
effect: NoExecute
- operator: Exists
KubernetesのMasterノードや、その他taintが付与された特定のワークロード専用のWorkerノード含めて、すべてのノードにfluentd podをスケジュールための記述です。何らかの理由でfluentdを動作させたくないノードがある場合は、tolerationをもう少し絞り込む必要があります。
env:
- name: DD_API_KEY
valueFrom:
secretKeyRef:
name: datadog
key: api-key
- name: DD_TAGS
value: |
["env:test", "kube_cluster:k8s1"]
一つめは、secretに保存したDatadog APIキーを環境変数DD_API_KEYにセットする、二つめはfluentdが収集したすべてのログに二つのタグをつける、という設定です。タグはDatadogの他のサブサービスでもよく見られる形式で、"key:value"形式になっています。
Datadogタグのenvは、Datadogで環境名を表すために慣習的に利用されています。もしDatadogでメトリクスやトレースを既に収集していて、それにenvタグをつけているのであれば、それと同じような環境名をログにも付与するとよいでしょう。
kube_clusterは個人的におすすめしたいタグです。Kubernetesクラスタは複数同時に運用する可能性があります。このタグがあると、メトリクスやトレース、ログをクラスタ毎に絞り込むことができ、何か障害が発生したときにその原因が特定のクラスタだけで起きているのかどうか切り分ける、などの用途で役立ちます。
ports:
- containerPort: 24231
name: prometheus-metrics
「Kubernetesにデプロイしたアプリケーションのメトリクスを自動収集する」で紹介した方法でdd-agentにfluentdのPrometheusメトリクスをスクレイプさせるために必要なポートです。
サンプルアプリからログを出力する
適当なPodを作成して、testmessage1というメッセージを出力します。
$ kubectl run --image ruby:2.4.2-slim-stretch distlogtest-$(date +%s) --command -- ruby -e '10.times { puts %q| mytestmessage1|; sleep 1 }'
ログの確認
何度か同じコマンドを実行したうえで、DatadogのLog Explorerでtestmessage1を検索してみると、以下のようにログエントリがヒットします。
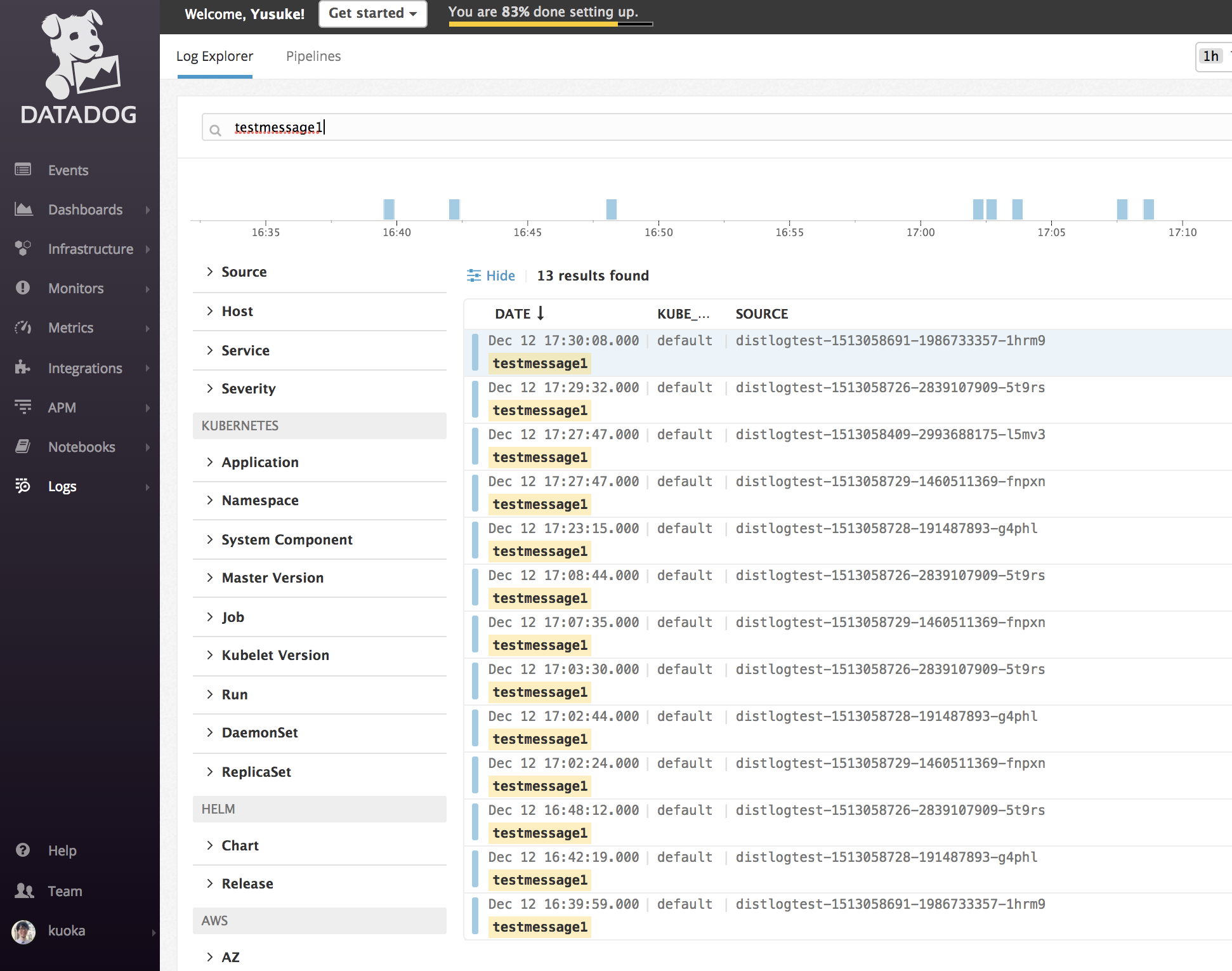
ログエントリを一つクリックして詳細を開いてみると、testmessage1というログメッセージの他に、それに付随する様々なメタデータが確認できます。
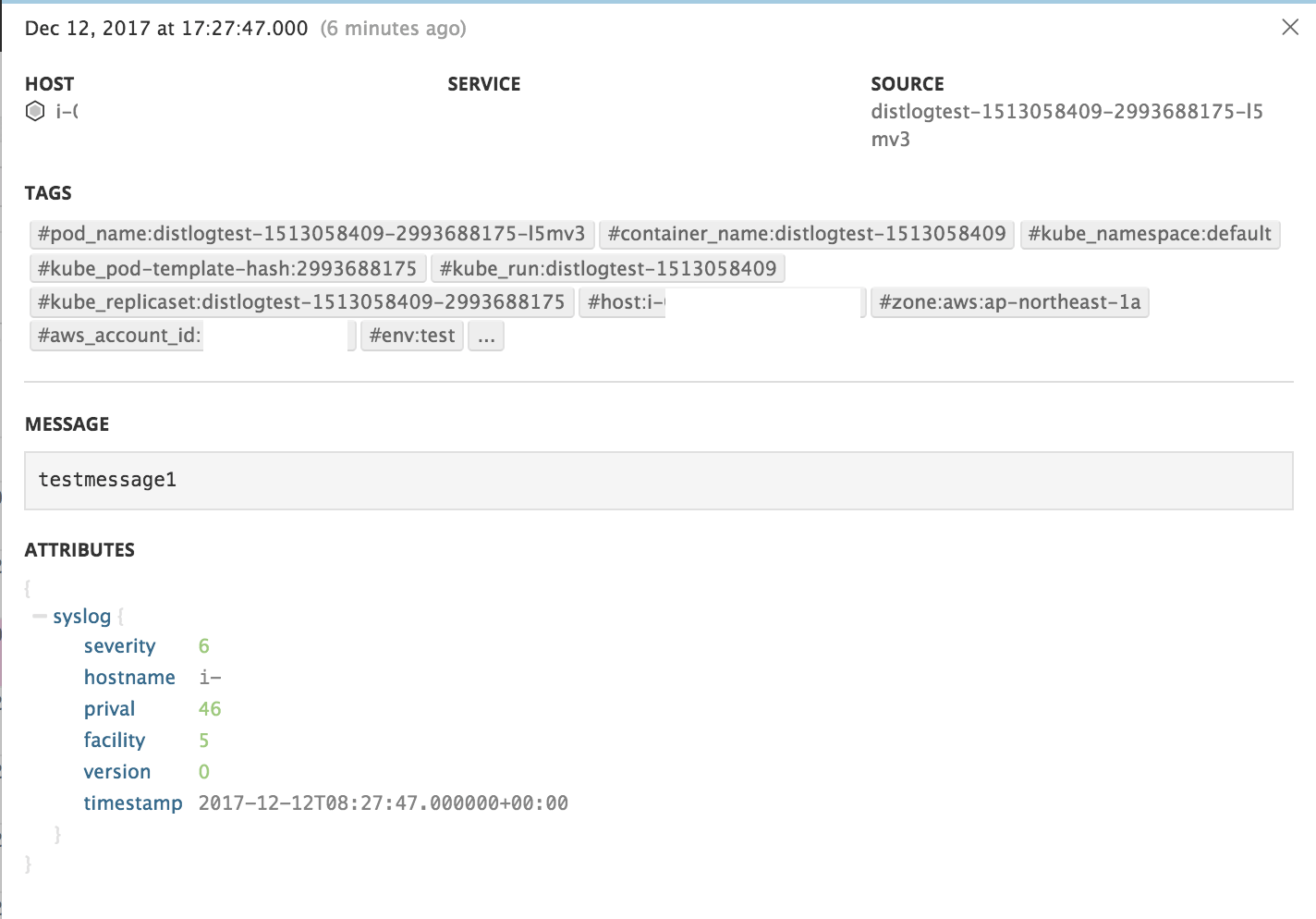
ログエントリに自動付与されたメタデータの確認
- HOST: ログを出力したPodがスケジュールされているホスト名(=EC2インスタンスのインスタンスID)
- SOURCE: コンテナ名
- TAGS: Datadogタグ
- pod_name: Pod名
- kube_replicaset: ReplicaSet名
- container_name: Dockerコンテナ名
- kube_namespace: PodがスケジュールされているNamespace名
- host: PodがスケジュールされているKubernetesノードのEC2インスタンスID
- zone: Availability Zone
- aws_account_id: AWSアカウントID
- env: 環境名
Log Explorerを使うと、すべてのAWSアカウントのすべてのKubernetesクラスタ上のすべてのPodからのログが一つのタイムラインで見られます。それを上記のようなメタデータを使って絞り込むことができます。
ログエントリの絞り込み
ログエントリの詳細から特定のタグを選択すると、「Filter by」というメニュー項目が見つかります。
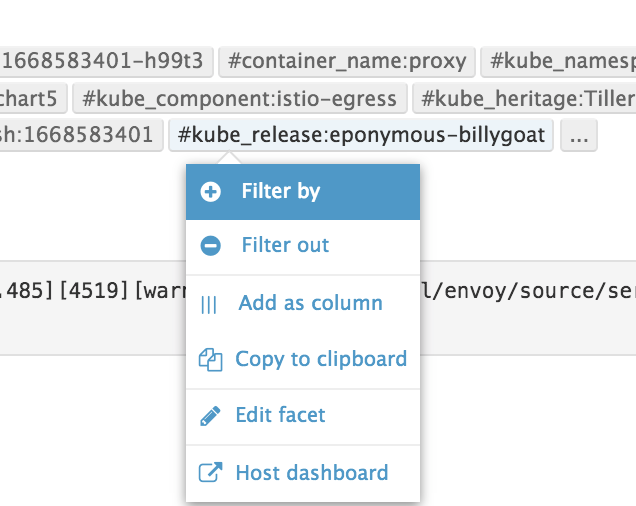
これを選択すると、検索ボックスに選択したタグがkey:value形式で入力された状態になり、そのタグが付与されたログエントリだけが絞り込まれます。
もちろん、検索ボックスに直接フリーワードを入力したり、key:value形式でタグを入力してもOKです。
Facetingを試す
定型的な絞り込み条件がある場合は、Facetを作成すると便利です。
ログエントリの詳細から特定のタグを選択すると、「Create new facet」というメニュー項目が見つかります。
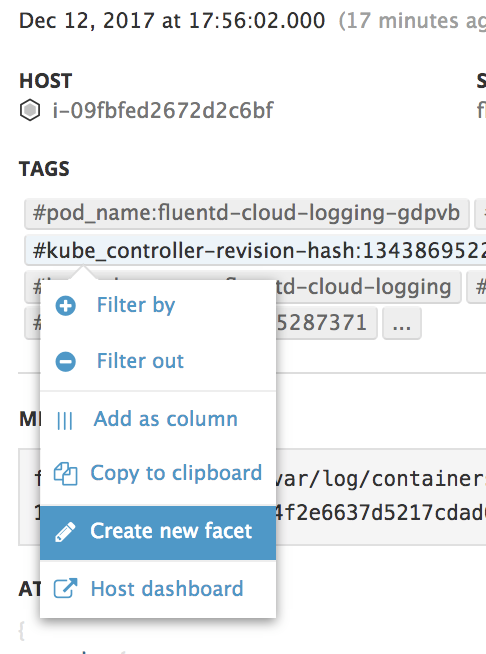
これを選択すると、以下のようにどのような階層のどのような名前のFacetにするかを入力できます。
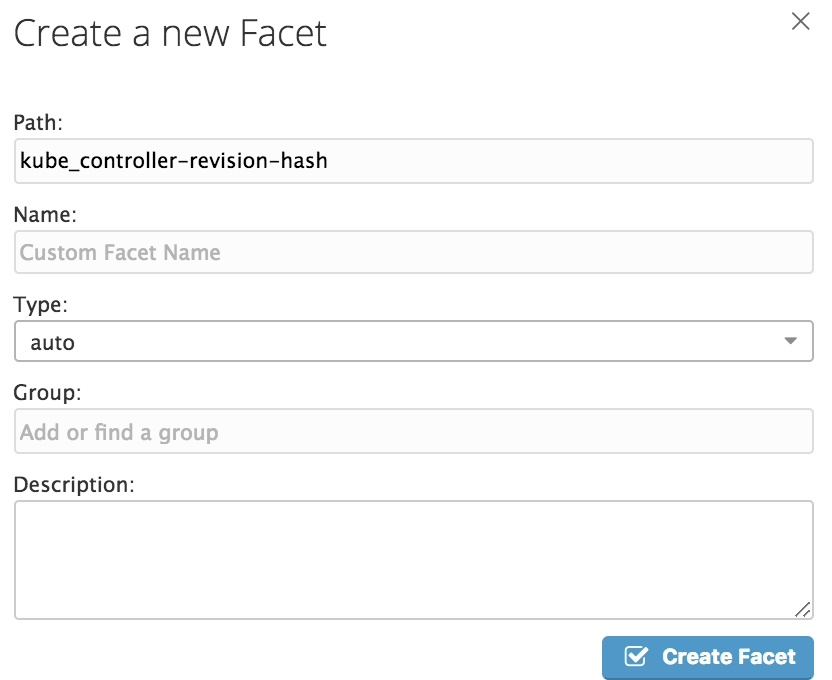
例えば、
- Path: kube_namespace
- Name: Namespace
- Group: Kubernetes
のようなFacetを作成すると、ログエントリに付与されたkube_namespaceというタグキーとペアになったことがある値を集約して、検索条件のショートカットをつくってくれます。実際のNamespace Facetは以下のように見えます。
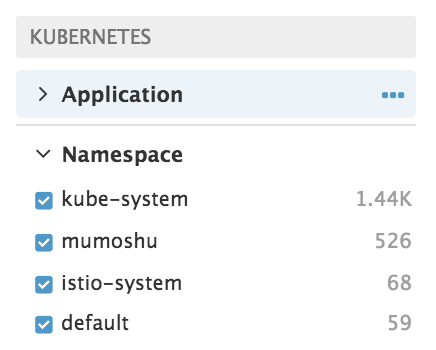
kube-system、mumoshu、istio-system、defaultなどが表示されていますが、それぞれkube_namespaceというタグキーとペアになったことがある値(=クラスタに実在するNamespace名)です。また、その右の数値はそのNamespaceから転送されたログエントリの件数です。この状態で例えばistio-systemを選択すると、kube_namespace:istio-systemというタグが付与されたログエントリだけを絞り込んでみることができます。
アーカイブ、ETLパイプラインへの転送など
kube-fluentdにはアーカイブやETLパイプラインのサポートは今のところないので、必要に応じてはfluentd.confテンプレート変更して、それを含むDockerイメージをビルドしなおす必要があります。
fluentd.confテンプレートは以下の場所にあります。
fluentd.confテンプレートから参照できる環境変数を追加したい場合は、以下のconfd設定ファイルを変更します。
// 今後、configmap内に保存したfluent.confの断片をfluentdの@includeを使ってマージしてくれるような機能を追加してもよいかもしれませんね。
まとめ
FluentdとDatadog Logsを使って、Kubernetes上のアプリケーションログを自動的に収集し、Datadog LogsのWeb UIからドリルダウンできるようにしました。
アプリ側はTwelve-Factor Appに則って標準出力・標準エラーにログを出力するだけでよい、という簡単さです。ドリルダウンしたり、そのためのFacetを作成するときも、グラフィカルな操作で完結できます。
また、ログの収集をするためだけにいちいちインフラエンジニアが呼び出されることもなくなって、楽になりますね!
Kubernetes上のアプリケーションの分散ロギングを自動化したい方は、ぜひ試してみてください。
(おまけ) 課題: ログメッセージに含まれるメタデータの抽出
Stackdriver Loggingではできて、Datadog Logsでは今のところできないことに、ログメッセージに含まれるメタデータの抽出があります。
例えば、Stackdriver Loggingの場合、
- ログにメタデータを付与して検索対象としたい
- 例えば「ログレベルDEBUGでHello World」のようなログを集約して、Web UIなどから「DEBUGレベルのログだけを絞り込みたい」
というような場合、アプリからは1行1 jsonオブジェクト形式で標準出力に流しておいて、fluent-plugin-google-cloud outputプラグイン(kube-fluentd内で利用しているプラグイン)でStackdriver Loggingに送ると、jsonオブジェクトをパースして、検索可能にしてくれます。
例えば、
{"message":"Hello World", "log_level":"info"}
のようなログをStackdriver Loggingにおくると、log_levelで検索可能になる、ということです。
このユースケースに対応する必要がある場合は、いまのところDatadog LogsではなくStackdriver Loggingを採用するとよいと思います。
今後の展望
同じくkube-fluentdでDatadog Logsへログを転送するために利用しているfluent-plugin-datadog-logに、fluent-plugin-google-cloudと同様にJSON形式のログをパースしてDatadogのタグに変換する機能を追加することはできるかもしれません。
また、Datadog Logsには、ログエントリのメッセージ部分に特定のミドルウェアの標準的な形式のログ(例えばnginxのアクセスログ)が含まれる場合に、それをよしなにパースしてくれる機能があります。その場合にログエントリに付与されるメタデータは、タグではなくアトリビュートというものになります。アトリビュートはタグ同様に検索条件に利用することができます。
ただ、いまのところfluent-plugin-datadog-logからの出力はすべてsyslog扱いになってしまっており、ログの内容によらず以下のようなアトリビュートが付与されてしまっています。
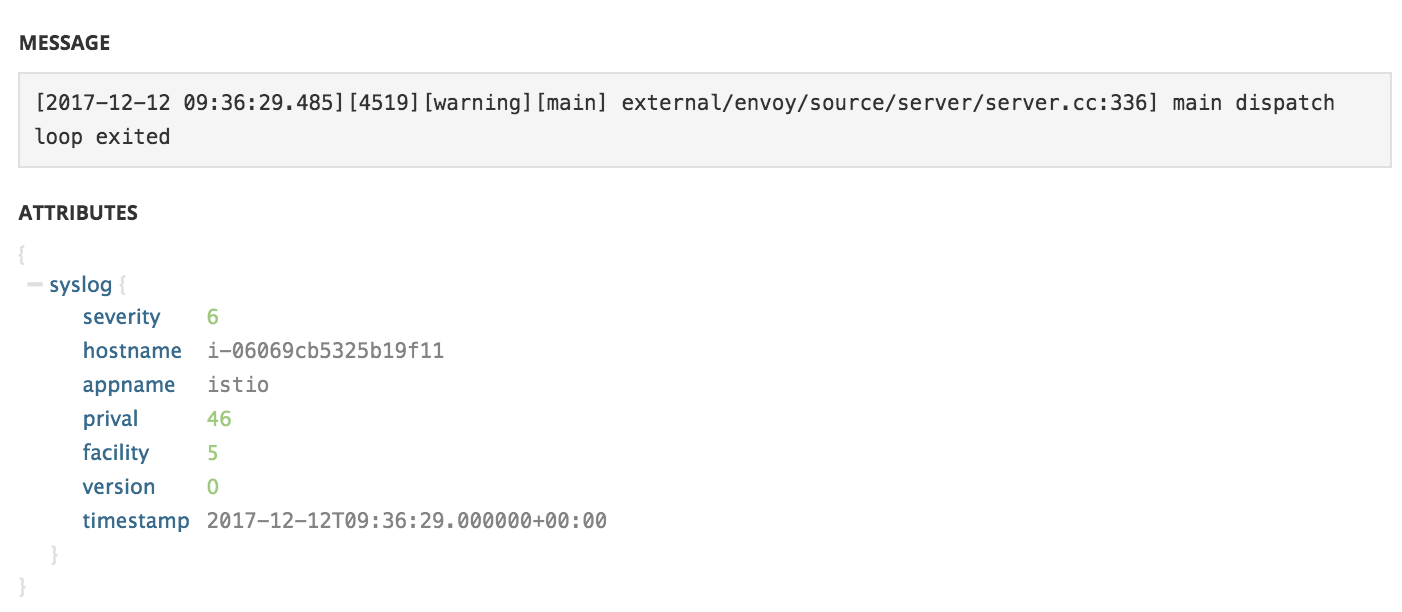
JSONをパースした結果がこのアトリビュートに反映されるような実装が可能であれば、それが最適なように思えます。
トラブルシューティング
ログがDatadogに表示されない
DatadogのEvent Streamを見て、fluentdがOOMで落ちていないかどうかを確認してみてください。
OOMで落ちている場合は以下のようなイベントが記録されています。
