xgboost: treeの勾配ブースティングによる高性能な分類・予測モデル。kaggleで大人気。
参考
インストール(公式document)
@mac
$ cd <workspace>
$ git clone --recursive https://github.com/dmlc/xgboost
$ cd xgboost; cp make/minimum.mk ./config.mk; make -j4
$ cd python-package; sudo python setup.py install
@ubuntu
$ cd <workspace>
$ git clone --recursive https://github.com/dmlc/xgboost
$ cd xgboost; make -j4
$ cd python-package; sudo python setup.py install
使い方 1: 回帰モデル
regressor.py
import xgboost as xgb
from sklearn.model_selection import GridSearchCV
from sklearn.datasets import load_boston
from sklearn.metrics import mean_squared_error
# データ読み込み
boston = load_boston()
X_train, X_test = boston.data[:400], boston.data[400:]
y_train, y_test = boston.target[:400], boston.target[400:]
# xgboostモデルの作成
reg = xgb.XGBRegressor()
# ハイパーパラメータ探索
reg_cv = GridSearchCV(reg, {'max_depth': [2,4,6], 'n_estimators': [50,100,200]}, verbose=1)
reg_cv.fit(X_train, y_train)
print reg_cv.best_params_, reg_cv.best_score_
# 改めて最適パラメータで学習
reg = xgb.XGBRegressor(**reg_cv.best_params_)
reg.fit(X_train, y_train)
# 学習モデルの保存、読み込み
# import pickle
# pickle.dump(reg, open("model.pkl", "wb"))
# reg = pickle.load(open("model.pkl", "rb"))
# 学習モデルの評価
pred_train = reg.predict(X_train)
pred_test = reg.predict(X_test)
print mean_squared_error(y_train, pred_train)
print mean_squared_error(y_test, pred_test)
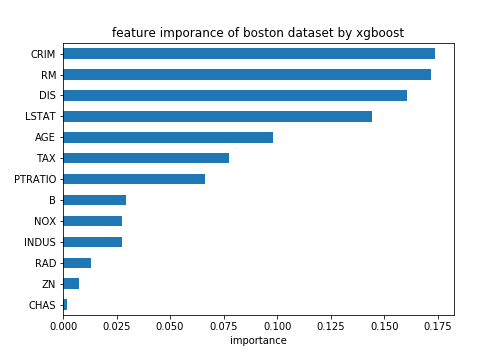
# feature importance のプロット
import pandas as pd
import matplotlib.pyplot as plt
importances = pd.Series(reg.feature_importances_, index = boston.feature_names)
importances = importances.sort_values()
importances.plot(kind = "barh")
plt.title("imporance in the xgboost Model")
plt.show()
使い方 2: 分類モデル
classifier.py
import xgboost as xgb
from sklearn.model_selection import GridSearchCV
from sklearn.datasets import load_digits
from sklearn.metrics import confusion_matrix, classification_report
# データ読み込み
digits = load_digits()
X_train, X_test = digits.data[:1000], digits.data[1000:]
y_train, y_test = digits.target[:1000], digits.target[1000:]
# xgboostモデルの作成
clf = xgb.XGBClassifier()
# ハイパーパラメータ探索
clf_cv = GridSearchCV(clf, {'max_depth': [2,4,6], 'n_estimators': [50,100,200]}, verbose=1)
clf_cv.fit(X_train, y_train)
print clf_cv.best_params_, clf_cv.best_score_
# 改めて最適パラメータで学習
clf = xgb.XGBClassifier(**clf_cv.best_params_)
clf.fit(X_train, y_train)
# 学習モデルの保存、読み込み
# import pickle
# pickle.dump(clf, open("model.pkl", "wb"))
# clf = pickle.load(open("model.pkl", "rb"))
# 学習モデルの評価
pred = clf.predict(X_test)
print confusion_matrix(y_test, pred)
print classification_report(y_test, pred)
# precision recall f1-score support
#
# 0 0.94 0.97 0.96 79
# 1 0.90 0.79 0.84 80
# 2 0.99 0.88 0.93 77
# 3 0.89 0.82 0.86 79
# 4 0.94 0.90 0.92 83
# 5 0.92 0.95 0.93 82
# 6 0.95 0.97 0.96 80
# 7 0.96 0.96 0.96 80
# 8 0.82 0.91 0.86 76
# 9 0.79 0.90 0.84 81
#
# avg / total 0.91 0.91 0.91 797