日本国内における COVID19 の状況を Splunk でダッシュボードにしました。GitHub にて公開しています。
-
Splunk-COVID19-Japan: COVID19 Japan Dashboard for Splunk - GitHub
-
「「東京都 新型コロナウイルス感染症対策サイト」から派生した各ページとデータソースの状況 - Qiita」に「おまけ」として載せたものになります。
-
【2020/05/09 追記】 "COVID19 Japan Toyo Keizai Online" ダッシュボードについて記載。
データソース
以下のデータを利用しています。
COVID19 感染者データ
1. Coronavirus Disease (COVID-19) Japan Tracker
Shane Reustle 氏らによって、非常に詳細なデータが提供されています。
- Coronavirus Disease (COVID-19) Japan Tracker (以下、「Japan Tracker」と記載)
2. NHK 特設サイト 新型コロナウイルス 都道府県別の感染者数・感染者マップ
NHK のデータは、サイトとしては公開されていますが、埋め込まれた JSON ファイルの URL 自体は公開されていません。ページのソースから、URL を勝手に取得しています。
3. 東洋経済オンライン 新型コロナウイルス国内感染の状況
東洋経済オンラインで公開されている「新型コロナウイルス国内感染の状況」ページの元データおよびソースコードが GitHub で公開されています。
マップデータ
緯度経度データ
地方自治体データ
- 総務省|電子自治体|全国地方公共団体コード
- J-LIS 地方公共団体コード住所
- 市区町村名・コード | 政府統計の総合窓口
- 住民基本台帳に基づく人口、人口動態及び世帯数調査 調査の結果 年次 2019年 | ファイル | 統計データを探す | 政府統計の総合窓口
これらの地方自治体データと緯度経度データを統合して利用しています。
人口データ
-
人口推計 010 都道府県,年齢(5歳階級),男女別人口-総人口,日本人人口 | データベース | 統計データを探す | 政府統計の総合窓口
(いずれ使用する予定ですが、現在のところ、使用していません。)
各ダッシュボード
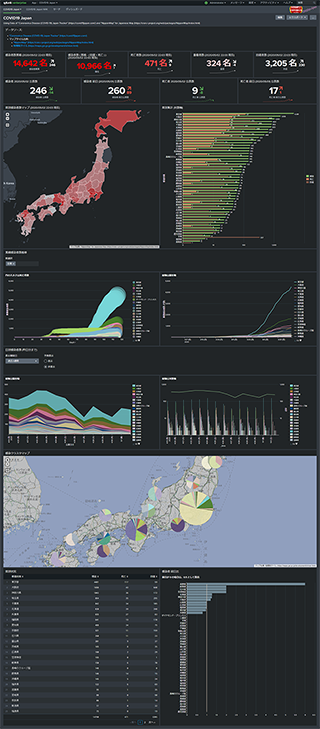
1. COVID19 Japan
日本全国の状況を示す、メインのダッシュボードです。
- 感染者数累積等の数値表示
- 当日、前日の公表数の数値表示
- 感染者数による Choropleth Map
- 各県の感染者数 Bar Chart
- 各県の感染者数と死亡者数推移 Bubble Chart
- 日毎公表数推移
- 地域別感染者数 Cluster Map
- 公表数前日比
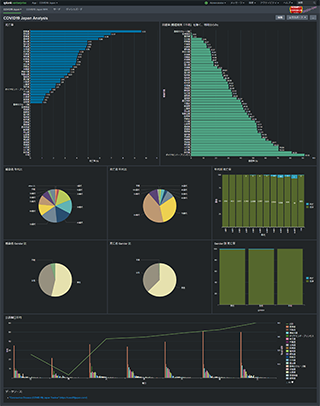
2. COVID19 Japan Analysis
傾向等の分析ダッシュボードです。
- 各県の死亡率
- 各県の回復率
- 感染者数と死亡者数の年代比
- 同 Gender 比
- 曜日別公表数平均
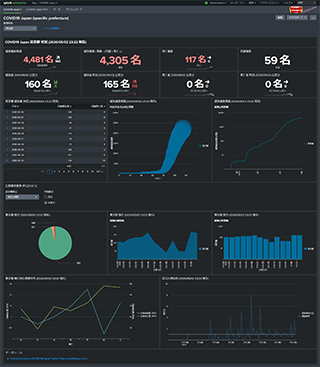
3. COVID19 Japan (specific prefecture)
県単位のダッシュボードです。メインダッシュボード "COVID19 Japan" の Choropleth Map のドリルダウンからリンクしています。
- 感染者数累積等数値表示
- 当日、前日公表数
- 感染者数推移
- 公表数推移
- 曜日毎の公表数平均
- 公表数前日比
ここで各県の一次データを利用したかったのですが、「「東京都 新型コロナウイルス感染症対策サイト」から派生した各ページとデータソースの状況 - Qiita」に書いた通りの状態なので、断念しました。
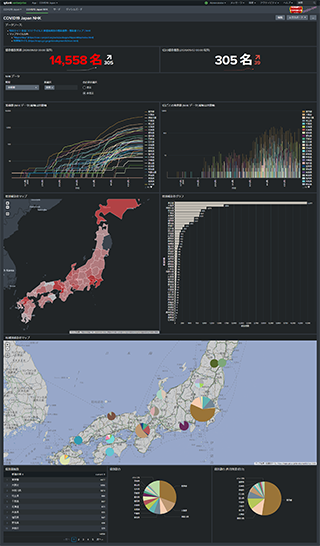
4. COVID19 Japan NHK
NHK データを用いたダッシュボードです。
- 感染者数累積、1日の感染者数
- 累積感染者数推移
- 1日毎の公表数推移
- 感染者数による Choropleth Map
- 各県の感染者数 Bar Chart
- 地域別感染者数 Cluster Map
- 各県の占める割合
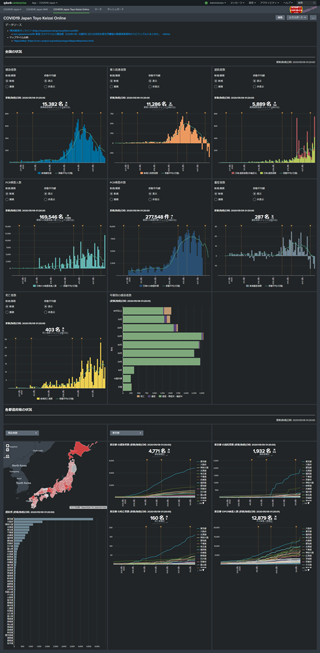
5. COVID19 Japan Toyo Keizai Online
東洋経済オンラインのデータを用いて、同 新型コロナウイルス 国内感染の状況 ページを Splunk ダッシュボードでエミュレートしてみました。
時系列グラフに「緊急事態宣言」のタイミングなどの annotation を独自に追加しています。
データ加工
データ取り込み
JSON データは加工せず、JSON のまま Splunk に取り込んでいます。
CSV は Lookup テーブルとして登録しています。
Japan Tracker
/var/local/COVID19/Japan/json_source/ に取得日時を付加した .json ファイルをダウンロード、/var/local/COVID19/Japan/ 下に固定ファイル名で最新ファイルへのシンボリックリンクを作成しています。
CSV を取得する場合には、lookups にルックアップテーブルを作成するためにも使用しているため、lookups へのリンクの作成部分がありますが、JSON ファイルの場合には利用していません。
# !/bin/sh
# -*- coding: utf-8 -*-
# for test
# set -x
# SPLUNK_HOME=${HOME}/work/Develop.d/docker-splunk-dev/dirs/opt-001.d/splunk
# VAR_DIR=${HOME}/work/Develop.d/docker-splunk-dev/dirs/var-001.d
#### end of test setting
SPLUNK_HOME=${SPLUNK_HOME:-"/opt/splunk"}
APP_BASE=${APP_BASE:-"${SPLUNK_HOME}/etc/apps/covid19-japan"}
RUN_SCRIPT_NAME=${RUN_SCRIPT:-"wget"}
RUN_SCRIPT=${RUN_SCRIPT:-"${RUN_SCRIPT_NAME}"}
LOGNAME=${LOGNAME:-"splunk"}
export TZ="Asia/Tokyo"
NOW=$(date "+%Y%m%d%H%M%S")
COVID19_JAPAN_DATA_URL="https://data.covid19japan.com"
if type flock > /dev/null 2>&1
then
LOCK_PROGRAM="flock -x -n"
else
LOCK_PROGRAM="lockf -ks -t 0"
fi
run_script(){
target="$1"
original_file=$2
var_dir=$3
relative_dir=$4
symlink_path=$5
lookup_dir=$6
lookup_file=$7
lock_file=$8
cd /var/tmp
[ -f ${original_file} ] && mv ${original_file} ${original_file}.backup-${NOW}
${LOCK_PROGRAM} ${lock_file} ${RUN_SCRIPT} -q -T 60 -O ${original_file} ${COVID19_JAPAN_DATA_URL}/$target.json
[ -f ${original_file} ] || return 255
echo "" >> ${original_file}
if cmp ${symlink_path} ${original_file} > /dev/null
then
touch ${lock_file}
rm -f ${original_file}
return 1
fi
chown ${LOGNAME}:splunk ${original_file}
chmod 0664 ${original_file}
mv ${original_file} ${var_dir}/${relative_dir}/${original_file}
touch ${var_dir}/${relative_dir}/${original_file}
rm -f ${symlink_path}
ln -s ${relative_dir}/${original_file} ${symlink_path}
if [ "${lookup_file}" != "" ]
then
[ -e ${lookup_dir}/${lookup_file} -a -h ${lookup_dir}/${lookup_file} ] && return 0
[ -f ${lookup_dir}/${lookup_file} ] && mv ${lookup_dir}/${lookup_file} ${lookup_dir}/${lookup_file}.backup-${NOW}
ln -s ${symlink_path} ${lookup_dir}/${lookup_file}
fi
return 0
}
TargetName="
patient_data/latest
summary/latest
tokyo/counts
"
_future_TargetName="
"
TARGET_PREFIX="japan_covid_19_coronavirus_tracker"
VAR_DIR="/var/local/COVID19/Japan"
RELATIVE_DIR="json_source"
LOOKUP_DIR="${APP_BASE}/lookups"
if [ ! -d ${VAR_DIR}/${RELATIVE_DIR} ]
then
mkdir -p ${VAR_DIR}/${RELATIVE_DIR}
chown -R ${LOGNAME}:splunk ${VAR_DIR}/${RELATIVE_DIR}
chmod -R 03775 ${VAR_DIR}
fi
echo "${TargetName}" | while read target
do
[ "$target" = "" ] && continue
postfix=$(echo "$target" | sed -e 's|/|_|g')
ORIGINAL_FILE="${TARGET_PREFIX}-${postfix}-${NOW}.json"
SYMLINK_PATH="${VAR_DIR}/${TARGET_PREFIX}-${postfix}.json"
LOOKUP_FILE=""
LOCK_FILE=${VAR_DIR}/${RELATIVE_DIR}/${TARGET_PREFIX}-${postfix}.lock
run_script "$target" ${ORIGINAL_FILE} ${VAR_DIR} ${RELATIVE_DIR} ${SYMLINK_PATH} ${LOOKUP_DIR} "${LOOKUP_FILE}" ${LOCK_FILE}
done
- 「データ入力」でスクリプトとして実行しています。ただし、スクリプトからの入力ではなく、cron 呼び出しとしてのみ使用しています。
- cron 設定:
10 */2 * * *(毎偶数時(2時間おき)の10分) -
flockを用いて、二重起動されないようにしています。 - 【2020/05/06 追記】BSD 系で flock がない場合には lockf を使用するように修正しました。
作成されるファイルは以下のとおりです。
/var/local/COVID19/Japan/
├─ json_source
│ ├─ japan_covid_19_coronavirus_tracker-patient_data_latest-YYYYmmddHHMMSS.json
│ ├─ japan_covid_19_coronavirus_tracker-patient_data_latest.lock
│ ├─ japan_covid_19_coronavirus_tracker-summary_latest-YYYYmmddHHMMSS.json
│ ├─ japan_covid_19_coronavirus_tracker-summary_latest.lock
│ ├─ japan_covid_19_coronavirus_tracker-tokyo_counts-YYYYmmddHHMMSS.json
│ └─ japan_covid_19_coronavirus_tracker-tokyo_counts.lock
├─ japan_covid_19_coronavirus_tracker-patient_data_latest.json -> json_source/japan_covid_19_coronavirus_tracker-patient_data_latest-YYYYmmddHHMMSS.json
├─ japan_covid_19_coronavirus_tracker-summary_latest.json -> json_source/japan_covid_19_coronavirus_tracker-summary_latest-YYYYmmddHHMMSS.json
└─ japan_covid_19_coronavirus_tracker-tokyo_counts.json -> json_source/japan_covid_19_coronavirus_tracker-tokyo_counts-YYYYmmddHHMMSS.json
- 取り込み対象は
/var/local/COVID19/Japan/下の 3ファイル。
NHK データ
/var/local/COVID19/Japan/NHK/ に取得日時を付加した .json ファイルをダウンロード、/var/local/COVID19/Japan/ 下に固定ファイル名で最新ファイルへのシンボリックリンクを作成しています。
CSV を取得する場合には、lookups にルックアップテーブルを作成するためにも使用しているため、lookups へのリンクの作成部分がありますが、JSON ファイルの場合には利用していません。
取得先等が変わるのみで updateCovid19Japan_JSON.sh と同じなので、省略。
- 「データ入力」でスクリプトとして実行しています。ただし、スクリプトからの入力ではなく、cron 呼び出しとしてのみ使用しています。
- cron 設定:
30 1-23/2 * * *(毎奇数時(2時間おき)の30分) -
flockを用いて、二重起動されないようにしています。
作成されるファイルは以下のとおりです。
/var/local/COVID19/Japan/
├─ NHK
│ ├─ NHK-47newpatients-data-YYYYmmddHHMMSS.json
│ ├─ NHK-47newpatients-data.lock
| ├─ NHK-47patients-data-YYYYmmddHHMMSS.json
| └─ NHK-47patients-data.lock
├─ NHK-47newpatients-data.json -> NHK/NHK-47newpatients-data-YYYYmmddHHMMSS.json
└─ NHK-47patients-data.json -> NHK/NHK-47patients-data-YYYYmmddHHMMSS.json
東洋経済オンライン データ
- 「データ入力」でスクリプトとして実行しています。ただし、スクリプトからの入力ではなく、cron 呼び出しとしてのみ使用しています。
- cron 設定:
20 1-23/2 * * *(毎奇数時(2時間おき)の20分) -
flockを用いて、二重起動されないようにしています。
作成されるファイルは以下のとおりです。
/var/local/COVID19/Japan/
├─ toyo_keizai_online_csv_source
| ├─ toyo_keizai_online-demography-YYYYmmddHHMMSS.csv
| ├─ toyo_keizai_online-prefectures-2-YYYYmmddHHMMSS.csv
| ├─ toyo_keizai_online-prefectures-YYYYmmddHHMMSS.csv
| └─ toyo_keizai_online-summary-YYYYmmddHHMMSS.csv
├─ toyo_keizai_online-demography.csv -> toyo_keizai_online_csv_source/toyo_keizai_online-demography-YYYYmmddHHMMSS.csv
├─ toyo_keizai_online-prefectures-2.csv -> toyo_keizai_online_csv_source/toyo_keizai_online-prefectures-2-YYYYmmddHHMMSS.csv
├─ toyo_keizai_online-prefectures.csv -> toyo_keizai_online_csv_source/toyo_keizai_online-prefectures-YYYYmmddHHMMSS.csv
└─ toyo_keizai_online-summary.csv -> toyo_keizai_online_csv_source/toyo_keizai_online-summary-YYYYmmddHHMMSS.csv
取り込みは行っていません。lookup テーブルとして登録しています。
${SPLUNK_HOME}/etc/apps/covid19-japan/lookups/
├─ toyo_keizai_online-demography.csv -> /var/local/COVID19/Japan/toyo_keizai_online-demography.csv
├─ toyo_keizai_online-modtime.csv
├─ toyo_keizai_online-prefectures-2.csv -> /var/local/COVID19/Japan/toyo_keizai_online-prefectures-2.csv
├─ toyo_keizai_online-prefectures.csv -> /var/local/COVID19/Japan/toyo_keizai_online-prefectures.csv
└─ toyo_keizai_online-summary.csv -> /var/local/COVID19/Japan/toyo_keizai_online-summary.csv
CSV ファイル自体に更新時刻が含まれていないので、toyo_keizai_online-modtime.csv に更新時刻を記録しています。
"modtime","filename"
"2020-05-09T01:20:00+0900","toyo_keizai_online-summary.csv"
"2020-05-09T01:20:00+0900","toyo_keizai_online-prefectures.csv"
"2020-05-09T01:20:01+0900","toyo_keizai_online-prefectures-2.csv"
"2020-05-09T01:20:01+0900","toyo_keizai_online-demography.csv"
"2020-05-09T19:20:00+0900","toyo_keizai_online-summary.csv"
"2020-05-09T19:20:00+0900","toyo_keizai_online-prefectures.csv"
"2020-05-09T19:20:01+0900","toyo_keizai_online-prefectures-2.csv"
"2020-05-09T19:20:01+0900","toyo_keizai_online-demography.csv"
input.conf
[default]
[monitor:///var/local/COVID19/Japan/NHK-47newpatients-data.json]
disabled = false
index = covid19japan_nhk
sourcetype = covid19japan_nhk_json
[monitor:///var/local/COVID19/Japan/NHK-47patients-data.json]
disabled = false
index = covid19japan_nhk
sourcetype = covid19japan_nhk_json
[monitor:///var/local/COVID19/Japan/japan_covid_19_coronavirus_tracker-Aichi.csv]
disabled = false
index = covid19japan
sourcetype = covid19japan_csv
[monitor:///var/local/COVID19/Japan/japan_covid_19_coronavirus_tracker-Chiba.csv]
disabled = false
index = covid19japan
sourcetype = covid19japan_csv
[monitor:///var/local/COVID19/Japan/japan_covid_19_coronavirus_tracker-Hokkaido.csv]
disabled = false
sourcetype = covid19japan_csv
index = covid19japan
[monitor:///var/local/COVID19/Japan/japan_covid_19_coronavirus_tracker-Kanagawa.csv]
disabled = false
index = covid19japan
sourcetype = covid19japan_csv
[monitor:///var/local/COVID19/Japan/japan_covid_19_coronavirus_tracker-Osaka.csv]
disabled = false
index = covid19japan
sourcetype = covid19japan_csv
[monitor:///var/local/COVID19/Japan/japan_covid_19_coronavirus_tracker-Patient_Data.csv]
disabled = false
index = covid19japan
sourcetype = covid19japan_csv
[monitor:///var/local/COVID19/Japan/japan_covid_19_coronavirus_tracker-Saitama.csv]
disabled = false
sourcetype = covid19japan_csv
index = covid19japan
[monitor:///var/local/COVID19/Japan/japan_covid_19_coronavirus_tracker-Tokyo.csv]
disabled = false
index = covid19japan
sourcetype = covid19japan_csv
[monitor:///var/local/COVID19/Japan/japan_covid_19_coronavirus_tracker-patient_data_latest.json]
disabled = false
index = covid19japan
sourcetype = covid19japan_json
[monitor:///var/local/COVID19/Japan/japan_covid_19_coronavirus_tracker-summary_latest.json]
disabled = false
index = covid19japan
sourcetype = covid19japan_summary_json
[monitor:///var/local/COVID19/Japan/japan_covid_19_coronavirus_tracker-tokyo_counts.json]
disabled = false
index = covid19japan
sourcetype = covid19japan_json
[script://$SPLUNK_HOME/etc/apps/covid19-japan/bin/updateCovid19JapanCSV.sh]
disabled = true
sourcetype = updatecovid19japan
interval = 0 */2 * * *
[script://$SPLUNK_HOME/etc/apps/covid19-japan/bin/updateCovid19Japan_JSON.sh]
disabled = false
sourcetype = updatecovid19japan
interval = 10 */2 * * *
[script://$SPLUNK_HOME/etc/apps/covid19-japan/bin/updateCovid19Japan_NHK_JSON.sh]
disabled = false
sourcetype = updatecovid19japan
interval = 30 1-23/2 * * *
[script://$SPLUNK_HOME/etc/apps/covid19-japan/bin/updateCovid19Japan_ToyoKeizaiOnline_CSV.sh]
disabled = false
sourcetype = updatecovid19japan
interval = 20 1-23/2 * * *
props.conf
[default]
TZ = Asia/Tokyo
[covid19japan_csv]
disabled = false
category = Structured
description = CSV data for COVID19 in Japan
pulldown_type = true
INDEXED_EXTRACTIONS = csv
DATETIME_CONFIG =
TIMESTAMP_FIELDS = acquisition_time
TIME_FORMAT = %Y/%m/%d %H:%M:%S -0900
BREAK_ONLY_BEFORE_DATE =
LINE_BREAKER = ([\r\n]+)
KV_MODE = none
NO_BINARY_CHECK = true
TRUNCATE = 0
SHOULD_LINEMERGE = false
TZ = Asia/Tokyo
[covid19japan_json]
category = Structured
disabled = false
description = JSON data for COVID19 in Japan
pulldown_type = true
INDEXED_EXTRACTIONS = json
DATETIME_CONFIG = CURRENT
LINE_BREAKER = ([\r\n]+)
KV_MODE = none
AUTO_KV_JSON = true
NO_BINARY_CHECK = true
TRUNCATE = 0
TZ = Asia/Tokyo
[covid19japan_nhk_json]
disabled = false
category = Structured
description = JSON NHK data for COVID19 in Japan
pulldown_type = true
INDEXED_EXTRACTIONS = json
DATETIME_CONFIG = CURRENT
MAX_TIMESTAMP_LOOKAHEAD =
BREAK_ONLY_BEFORE = ^{
BREAK_ONLY_BEFORE_DATE =
LINE_BREAKER = ^{
KV_MODE = none
AUTO_KV_JSON = true
NO_BINARY_CHECK = true
TRUNCATE = 0
SHOULD_LINEMERGE = false
TZ = Asia/Tokyo
[covid19japan_summary_json]
disabled = false
category = Structured
description = JSON summary data for COVID19 in Japan
pulldown_type = true
INDEXED_EXTRACTIONS = json
DATETIME_CONFIG =
TIMESTAMP_FIELDS = updated
TIME_FORMAT = %FT%T%z
LINE_BREAKER = ([\r\n]+)
KV_MODE = none
NO_BINARY_CHECK = true
AUTO_KV_JSON = true
TRUNCATE = 0
TZ = Asia/Tokyo
データ変換
JSON データの構造が、そのままでは Splunk で使いづらい形なので、SavedSearch を使用して CSV 形式の lookup テーブルに変換しています。
特に MultiValue を分解するために mvexpand を連続して使用すると、すぐにメモリがパンクする1ので、インタラクティブに mvexpand を使わないようにして、バッチ処理で CSV に変換しています。
| Saved Search | 説明 | 実行タイミング |
|---|---|---|
gen_covid19japan_confirmed_by_prefecture_summary_csv |
県単位の感染者数のサマリを作成。 | */15 */2 * * * |
gen_covid19japan_deceased_by_prefecture_summary_csv |
県単位の死亡者数サマリを作成。 | 1-59/15 */2 * * * |
gen_covid19japan_daily_summary_csv |
日毎サマリを作成 | 5-59/15 */2 * * * |
gen_covid19japan_nhk_47patients_data_csv |
NHKデータの累積サマリを作成 | 4-59/15 7-17/2 * * * |
gen_covid19japan_nhk_47newpatients_data_csv |
NHKデータの日毎サマリを作成。 | 3-59/15 7-17/2 * * * |
[default]
[gen_covid19japan_confirmed_by_prefecture_summary_csv]
action.logevent = 1
cron_schedule = */15 */2 * * *
request.ui_dispatch_view = search
dispatch.earliest_time = -24h@h
relation = equal to
description = Generate covid19japan_confirmed_by_prefecture_summary.csv
alert.track = 0
action.logevent.param.host = splunk001
counttype = number of events
display.page.search.tab = statistics
enableSched = 1
display.page.search.mode = verbose
dispatch.latest_time = now
request.ui_dispatch_app = covid19-japan
action.logevent.param.event = Empty in Generate covid19japan_confirmed_by_prefecture_summary.csv
display.visualizations.charting.chart = bubble
alert.expires = 60s
display.general.type = statistics
alert.suppress = 0
quantity = 0
search = index=covid19japan source="*/japan_covid_19_coronavirus_tracker-summary_latest.json" \
| head 1\
| fields - daily*\
| spath output=prefectures prefectures{}\
| mvexpand prefectures\
| spath input=prefectures\
| fields updated, name, name_ja, newlyConfirmed, yesterdayConfirmed, newlyDeceased, yesterdayDeceased, confirmed, deceased, recovered, dailyConfirmedStartDate, dailyDeceasedStartDate, confirmedByCity.*, dailyConfirmedCount{}, dailyDeceasedCount{}, cruisePassenger\
\
\
| eval lc_min_time=strptime(dailyConfirmedStartDate,"%F")\
| eval days_confirmed_count=mvcount('dailyConfirmedCount{}')\
| eval tmp=mvrange(0, days_confirmed_count)\
| eval daily_confirmed=mvzip(tmp, 'dailyConfirmedCount{}')\
\
| fields - _raw\
\
| table _time, updated, name, name_ja, lc_min_time, dailyConfirmedStartDate, days_confirmed_count, daily_confirmed, newlyConfirmed, yesterdayConfirmed, confirmed, deceased, recovered, cruisePassenger, confirmedByCity.*\
| mvexpand daily_confirmed\
| eval daily_confirmed=split(daily_confirmed, ",")\
| eval tmp=mvindex(daily_confirmed, 0), daily_confirmed=mvindex(daily_confirmed, 1)\
| eval _time=lc_min_time + (tmp*86400)\
| fields - tmp\
| sort 0 + name, _time\
| eval newlyConfirmed=daily_confirmed, yesterdayConfirmed=0\
| streamstats current=false window=1 allnum=true global=false reset_on_change=true sum(daily_confirmed) as yesterdayConfirmed by name\
| streamstats current=true allnum=true global=false reset_on_change=true sum(daily_confirmed) as cumulativeConfirmed by name\
| addinfo\
\
| outputlookup output_format=splunk_mv_csv override_if_empty=false covid19japan_confirmed_by_prefecture_summary.csv
[gen_covid19japan_daily_summary_csv]
action.logevent = 1
cron_schedule = 5-59/15 */2 * * *
request.ui_dispatch_view = search
dispatch.earliest_time = -24h@h
relation = equal to
description = Generate covid19japan_daily_summary.csv
alert.track = 0
action.logevent.param.host = splunk001
counttype = number of events
display.page.search.tab = statistics
enableSched = 1
display.page.search.mode = verbose
dispatch.latest_time = now
request.ui_dispatch_app = covid19-japan
action.logevent.param.event = Generate covid19japan_daily_summary.csv
display.visualizations.charting.chart = bubble
alert.expires = 60s
display.general.type = statistics
alert.suppress = 0
quantity = 0
search = index=covid19japan source="*/japan_covid_19_coronavirus_tracker-summary_latest.json" \
| head 1\
| spath output=daily daily{}\
| fields daily, updated\
| mvexpand daily\
| spath input=daily\
| eval _time=strptime(date, "%F")\
| table _time, updated, confirmed, confirmedAvg3d, confirmedAvg7d, confirmedCumulative, confirmedCumulativeAvg3d, confirmedCumulativeAvg7d, criticalCumulative, deceased, deceasedCumulative, recoveredCumulative, testedCumulative\
| addinfo\
| outputlookup output_format=splunk_mv_csv override_if_empty=false covid19japan_daily_summary.csv
[gen_covid19japan_deceased_by_prefecture_summary_csv]
action.logevent = 1
cron_schedule = 1-59/15 */2 * * *
request.ui_dispatch_view = search
dispatch.earliest_time = -24h@h
relation = equal to
description = Generate covid19japan_deceased_by_prefecture_summary.csv
alert.track = 0
action.logevent.param.host = splunk002
counttype = number of events
display.page.search.tab = statistics
enableSched = 1
display.page.search.mode = verbose
dispatch.latest_time = now
request.ui_dispatch_app = covid19-japan
action.logevent.param.event = Empty in Generate covid19japan_deceased_by_prefecture_summary.csv
display.visualizations.charting.chart = bubble
alert.expires = 60s
display.general.type = statistics
alert.suppress = 0
quantity = 0
search = index=covid19japan source="*/japan_covid_19_coronavirus_tracker-summary_latest.json" \
| head 1\
| fields - daily*\
| spath output=prefectures prefectures{}\
| mvexpand prefectures\
| spath input=prefectures\
| fields updated, name, name_ja, newlyConfirmed, yesterdayConfirmed, newlyDeceased, yesterdayDeceased, confirmed, deceased, recovered, dailyConfirmedStartDate, dailyDeceasedStartDate, confirmedByCity.*, dailyConfirmedCount{}, dailyDeceasedCount{}, cruisePassenger\
\
\
| eval ld_min_time=strptime(dailyDeceasedStartDate,"%F")\
| eval days_deceased_count=mvcount('dailyDeceasedCount{}')\
| eval tmp=mvrange(0, days_deceased_count)\
| eval daily_deceased=mvzip(tmp, 'dailyDeceasedCount{}')\
\
| fields - _raw\
\
| table _time, updated, name, name_ja, ld_min_time, dailyDeceasedStartDate, days_deceased_count, daily_deceased, newlyDeceased, yesterdayDeceased, confirmed, deceased, recovered, cruisePassenger, confirmedByCity.*\
| mvexpand daily_deceased\
| eval daily_deceased=split(daily_deceased, ",")\
| eval tmp=mvindex(daily_deceased, 0), daily_deceased=mvindex(daily_deceased, 1)\
| eval _time=ld_min_time + (tmp*86400)\
| fields - tmp\
| sort 0 + name, _time\
| eval newlyDeceased=daily_deceased, yesterdayDeceased=0\
| streamstats current=false window=1 allnum=true global=false reset_on_change=true sum(daily_deceased) as yesterdayDeceased by name\
| streamstats current=true allnum=true global=false reset_on_change=true sum(daily_deceased) as cumulativeDeceased by name\
| addinfo\
\
| outputlookup output_format=splunk_mv_csv override_if_empty=false covid19japan_deceased_by_prefecture_summary.csv
[gen_covid19japan_nhk_47newpatients_data_csv]
display.visualizations.chartHeight = 826
action.logevent = 1
cron_schedule = 3-59/15 7-17/2 * * *
request.ui_dispatch_view = search
display.statistics.rowNumbers = 1
relation = equal to
description = Generate covid19japan_nhk_47newpatients_data.csv
alert.track = 0
action.logevent.param.host = splunk001
counttype = number of events
display.page.search.tab = statistics
enableSched = 1
display.page.search.mode = verbose
display.visualizations.type = singlevalue
action.logevent.param.event = gen_covid19japan_nhk_47newpatients_data_csv
display.visualizations.charting.chart = line
request.ui_dispatch_app = covid19-japan
display.general.type = statistics
alert.suppress = 0
quantity = 0
search = index=covid19japan_nhk source="*/NHK-47newpatients-data.json"\
| head 1\
| spath output=data47 data47{}\
| fields - name\
| mvexpand data47\
| spath input=data47\
| eval data=mvzip('category{}', 'data{}')\
| mvexpand data\
| eval data=split(data, ",")\
| eval updated=_time\
| eval _time=strptime("2020/" . mvindex(data,0), "%Y/%m/%d"), daily=mvindex(data,1)\
| xyseries _time, name, daily\
| outputlookup override_if_empty=false covid19japan_nhk_47newpatients_data.csv
[gen_covid19japan_nhk_47patients_data_csv]
display.visualizations.chartHeight = 826
action.logevent = 1
cron_schedule = 4-59/15 7-17/2 * * *
request.ui_dispatch_view = search
display.statistics.rowNumbers = 1
relation = equal to
description = Generate covid19japan_nhk_47patients_data.csv
alert.track = 0
action.logevent.param.host = splunk001
counttype = number of events
display.page.search.tab = statistics
enableSched = 1
display.page.search.mode = verbose
display.visualizations.type = singlevalue
action.logevent.param.event = gen_covid19japan_nhk_47patients_data_csv
display.visualizations.charting.chart = line
request.ui_dispatch_app = covid19-japan
display.general.type = statistics
alert.suppress = 0
quantity = 0
search = index=covid19japan_nhk source="*/NHK-47patients-data.json"\
| head 1\
| spath output=data47 data47{}\
| fields - name\
| mvexpand data47\
| spath input=data47\
| eval data=mvzip('category{}', 'data{}')\
| mvexpand data\
| eval data=split(data, ",")\
| eval updated=_time\
| eval _time=strptime("2020/" . mvindex(data,0), "%Y/%m/%d"), daily=mvindex(data,1)\
| xyseries _time, name, daily\
| outputlookup override_if_empty=false covid19japan_nhk_47patients_data.csv
当初、Summary Index を作成しようと思ったのですが、CSV のルックアップテーブルを作成したほうが軽くなったので、この方法に切り替えました。
lookups
covid19japan_*.csv という 5つのファイルは、それぞれ gen_covid19japan_*_csv という Saved Search によって生成されています。
他の 4つのファイルは、都道府県に関する県庁所在地、名前変換、地理情報などを提供するファイルです。
lookups
├─ covid19japan_daily_summary.csv
├─ covid19japan_confirmed_by_prefecture_summary.csv
├─ covid19japan_deceased_by_prefecture_summary.csv
├─ covid19japan_nhk_47newpatients_data.csv
├─ covid19japan_nhk_47patients_data.csv
├─ CapitalJapan.csv
├─ LocalGovernmentCode.csv
├─ latlongJapan.csv
└─ PrefecturesList.csv
さいごに
一日も早く新型コロナウイルス肺炎が終息することを祈っています。
データを作成していらっしゃる皆様に感謝しております。
-
Splunk (splunkd) 自体が落ちることもあり、Version 7.2.10.1 がリリースされたことと関連するのではないかと推測しています。 ↩