LLMのFine-Tuning手法まとめ
この記事のまとめ+補足説明を加えたものです。
https://dr-bruce-cottman.medium.com/part-1-eight-major-methods-for-finetuning-an-llm-6f746c7259ee
LLM に対してパラメータ Fine-Tuning を行う手法
- Gradient-based
- LoRA
- QLoRA
- その他の手法
について見ていきます。
0. 初期の Fine-Tuning 方法
初期の Fine-Tuning 方法はシンプルで、事前にトレーニングされた言語モデル (当時の用語は NLP (自然言語処理) と呼ばれていました) を取得し、それをラベル付きデータの小さなデータセットで微調整することが含まれていました。
目標は、モデルのパラメーターを調整することで、ラベル付きデータに対するモデルのパフォーマンスを向上させることでした。
LLM の規模が大きくなり、膨大な量のテキストでトレーニングされるにつれて、スペル、文法、単語間の文脈上の関係などの言語タスクについて一般的な理解を示し始めました。
しかし、LLM は、コーディング、画像関連タスク、数学的計算など、テキスト理解の範囲外のタスクを実行する能力が低く、実行できませんでした。
この制限により、LLM に追加のスキルを装備するためのさらなるトレーニングや微調整の必要性が生じました
1. Universal Language Model Finetuning (ULMFiT)
参考[1]:Universal Language Model Fine-tuning for Text Classification
https://arxiv.org/abs/1801.06146
ULMFiT は、他の 4 つの微調整方法すべてを説明および比較できるベースラインのテクニックを確立しました。
1-1. ULMFiT の 3 つの主要なステップ
-
Language Model training
ラベルのないテキストの大規模なコーパスで言語モデルをトレーニングします。 -
Target Model Layer (Parameter) Fine-tuning
ラベル付きで元のトレーニング データセットより小さい、ターゲット タスクに固有のデータセットを取得し、このデータに基づいてモデルをさらにトレーニングします。目標は、教師あり学習を使用して、当面のタスクの特定の言語パターンと概念にモデルを適応させることです。 -
Target Task Model Fine-tuning with Classifier Layers
最後のステップでは、微調整された言語モデルの上に 1 つ以上のタスク固有の分類子レイヤーを追加します。これらの追加レイヤーはランダムに初期化され、ターゲット タスクからのラベル付きデータを使用してトレーニングされます。言語モデルの残りの部分は、このステップ中は凍結されたままになります。分類子レイヤーを使用すると、モデルは一般的な言語モデルと微調整ステージの両方から学習した情報に基づいてタスク固有の予測を行うことができます。
最新の LLM アーキテクチャ手法、つまりトランスフォーマーとAttension により、ULMFiT ステップ 3 が不要になります。
1-2. ULMFiT ステップ 2: ターゲット モデル レイヤー (パラメーター) のFine-tuning
パラメータのサブセットを選択します。
これは、他の 3 つのより高度な Fine-tuning メソッドである LoRA、QLoRA、および他の 4 つのFine-tuning メソッドのベースである HiggingFace PEFT の親です。
「選択的パラメータ サブセット Fine-tuning」は、ビジョン モデルのニューラル ネットワーク層の動作から生まれました。
下位層のパラメータは画像の大まかなパターンまたは一般的なパターンを保持し、最上層のパラメータは画像のより完全なパターンを保持して、視覚モデルがトレーニングされます。
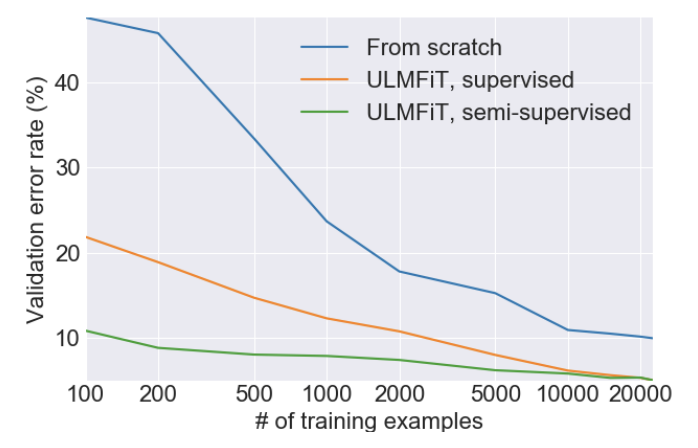
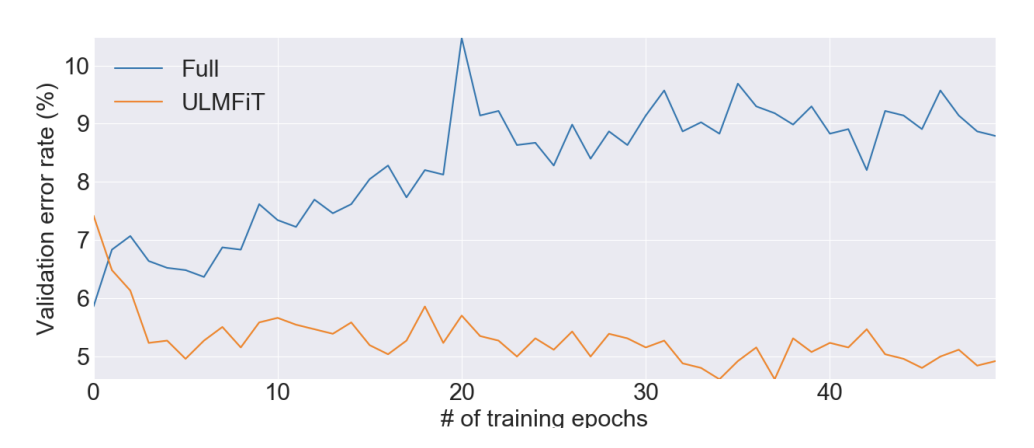
「選択的パラメータ サブセットの Fine-tuning」の目標は、視覚モデルと同じ方法で NLP を Fine-tuning することで、NLP が一般的な言語知識 (視覚モデルの特徴) を保持しながら、より高いレベルでターゲットに適応できるようにすることでした。
ULMFiTの論文では、 NLP を改善するための 3 つの手法が発見され、その結果「選択的パラメーター サブセットの Fine-tuning」が行われました。
1-2-1. gradual unfreezing
すべてのレイヤーをすぐにトレーニングするのではなく、最後のレイヤーから始めて最初のレイヤーに向かって、レイヤーを徐々に「Unfreezing」します、すなわち、徐々に学習範囲を広げます。
「gradual unfreezing」と呼ばれるこの方法は、新しい学習に対応するためにモデルが突然変更されたときに発生する可能性のある壊滅的な忘却を防ぐのに役立ちます。
より一般的な機能を学習した初期の層は、ゆっくりと更新されます。
よりタスク固有の機能を学習する後の層は、より積極的に更新されます。
1-2-2. Slanted Triangular Learning Rates (STLR):傾斜三角学習率
ULMFiT の次のユニークなアプローチは、分類器の Fine-tuning 中に傾斜三角学習率(STLR)を適用することです。
これは、最初は学習率がゆっくりと増加し、その後、より高い率で徐々に減少することを意味します。
この戦略は、最初にモデルがパラメーター空間のより広い部分を探索し (学習率が高い場合)、次に最適な解に収束することができるため (学習率が低下する場合)、効果が発揮されます。
1-2-3. Discriminative Fine-tuning
最後に、モデルの各層が異なる学習率で微調整されます。この手法は Discriminative Fine-tuning と呼ばれます。
これは、ニューラル ネットワークの各層が独自の学習率を持つことができることを意味します。
モデルのさまざまなレイヤーがさまざまなタイプの情報をキャプチャするため、さまざまな速度で微調整する必要があるためです。
ULMFiT は、大規模なコーパスで言語モデルをトレーニングし、タスク固有のデータで微調整することによって確立されました。
2.勾配ベースのパラメータ重要度ランキングまたはランダムフォレストベースの重要度ランキング
ULMFiT と同様に、パラメータ重要度ランキング (PIR) は、微調整プロセス中に更新するパラメーターのサブセットを選択します。PIR の核心はパラメータ選択プロセスです。
現在のタスクを分析し、モデル内のすべてのパラメーターに重要度のランク付けを割り当てます。
次に、タスクのパフォーマンスに最も大きな影響を与えるものが選択されます。
| 手法 | 概要 |
|---|---|
| ULMFiT | レイヤーをフリーズし、それらのレイヤーのパラメーターを変更しないままにします。 |
| PIR | パラメータがどのレイヤにあるかに関係なく、選択されていないパラメータをフリーズします。レイヤではなくパラメータをフリーズすることで、PIR はタスクに直接関係のない領域に LLM の知識を残します。 |
パラメータの選択は、PIR の重要なステップで、タスク分析と重要度ランキングを通じて、タスクのパフォーマンスに最も大きな影響を与えるパラメータを特定します。
2-1.PIR を実装する主な方法
勾配ベースの重要度ランキング
勾配ベースの重要度ランキングは、LLM の各パラメーターに関する損失関数の勾配を計算することによって機能します。
パラメーターの勾配は、パラメーターが損失関数にどの程度影響を与えるかを示す尺度で、最も高い勾配を持つパラメーターが最も重要であるとみなされます。
ランダム フォレスト重要度ランキング
ランダム フォレスト重要度ランキングは、LLM のパラメーターでランダム フォレスト モデルをトレーニングすることによって機能します。
ランダム フォレスト モデルの出力を予測するために最も重要なパラメーターは、LLM の最も重要なパラメーターであると考えられます。
実際には、LLM のパラメーターの数により、PIR は放棄されました。
3. LoRA: Low Ranking Adaptation of Large Language Models
LoRA: Low-Rank Adaptation of Large Language Models
https://arxiv.org/abs/2106.09685
現在のLLMのFine-tuning 手法になります.
3-1. 高ランク行列の低ランク近似への変換
LoRA について説明する前に、行列を低ランク近似に減らす方法について簡単に復習します。
重み行列は、行列分解と呼ばれる手法を使用して、より小さな行列の積として表すことができます。
matrix decomposition(行列分解)にはいくつかの異なるタイプがありますが、最も一般的なのは以下です。
SVD (特異値分解)
行列を 3 つの小さな行列 (特異値の対角行列、左特異ベクトルの行列、右特異ベクトルの行列) に分解します。
中央の行列 (V) の特異値は主成分の大きさを表し、左の特異ベクトルは主成分の方向を表し、右の特異ベクトルは主成分の重みを表します。
PCA (主成分分析)
特異値がすべて一意である SVD の特殊なケースです。
PCA は、データを最初のいくつかの主成分に投影することでデータセットの次元を削減するために使用されます。
低ランク近似
行列をより低いランクの小さな行列の積として近似する手法です。
特異値切り捨て(SVD)、主成分分析、行列因数分解などのさまざまな方法を使用して実行できます。
論文では著者は SVD を使用したと思われます。
3-2. LoRA の Fine-tuning
- LoRA (低ランク パラメーター化更新行列) は、ニューラル ネットワーク、特に LLM のアテンション層に適用されます。
- トランスフォーマー層などの高密度層を使用する他の深層学習モデルにも適用できます。
- ただし、これらの層は疎ではなく密 (パラメーターの独立した層) であるため、行列は下位のランクの近似はよくない。
We limit our study to only adapting the attention weights for downstream tasks
and freeze the MLP modules (so they are not trained in downstream tasks) both for simplicity.
3-2-1. 補足1
トランスフォーマーのアーキテクチャは、エンコーダーとデコーダーで構成されます。
エンコーダーは入力データを受け取り、それを一連の隠れ状態に変換します。
次に、デコーダは隠れた状態を取得し、出力データを生成します。
トランスフォーマー アーキテクチャのエンコーダーとデコーダーは MLP モジュールで構成されます。
エンコーダの MLP モジュールは入力ワード間の関係を学習し、デコーダの MLP モジュールは隠れ状態と出力ワード間の関係を学習します。
3-2-2. 補足2
トランスフォーマーが「エンコーダーとデコーダーで構成されている」と言うとき、
私は対話型チャット モードではなく、LLM の内部を指しています。
- LoRAの前提:Fine-tuning 中に、以前に訓練されたLLMの attention 層の元の重みの低ランク行列で重みの更新を表すことができる。
- 論文ではタスクを Fine-tuning するために必要な情報はより少ないパラメータに保存できるという仮定をしている。
- 論文ではLoRAを attention の重みに適用し、MLPモジュールの他の1734億のパラメータをフリーズし、まずGPT-3のパラメータの約0.01、つまり1%を対象としている。
3-2-3. LoRAの問題点
LoRAは、モデルが特定のパターンを学習する必要があるタスクに対して、伝統的な Fine-tuning 方法よりも効果が低い(作動しない)ことがあります。
- 言語的なタスク、たとえば分類、要約、質問-回答のペアなど、GPT-3のファインチューニングから、LoRAは素晴らしいスコアを出します。
- しかし、算数やポーカーのようなゲームにはLoRAは作用しません。
- LoRAは、伝統的なファインチューニング方法よりも実装が難しいことがある。
LoRA実装例
4. 量子化
量子化は Fine-tuning 方法ではありませんが、QLoRA およびその他の微調整方法 (PEFT) に含まれています。
量子化は、LLM のサイズを削減するために使用できる手法です。量子化によりモデルのパラメータの精度が低下し、必要なスペースが減ります。
- 通常、量子化により LLM の精度が低下します。秘訣は、パラメータとアクティベーションの精度を下げ、さらに一部のパラメータを削除して、LLM の応答の精度が少し失われます。
- LLM がはるかに小さい場合は、ラップトップや携帯電話などの小型デバイスに適合します。
4-1. 量子化はどのように機能するのか
1,000 億のパラメータを持つ LLM があるとします。
これらの各パラメーターは、32 ビット浮動小数点数で表されています。
これらの浮動小数点数 (パラメーター) を 8 ビット整数に置き換えると、サイズが 4 分の 1 に圧縮されます。
この論文の著者らは、パフォーマンスの低下を最小限に抑えながら、410M から 52B までのサイズのモデルを量子化できると報告しています。
- 精度わずか 0.1% の損失で GPT-3 モデルを量子化に成功
- この結果に基づいて、トレーニングまたは微調整された LLM を係数 4 または 8 (4 ビットの重み) でスリム化できる。
- 量子化を使用して、LLM のサイズを削減できます。それぞれの小さな LLM をトレーニングし、特定のタスクに合わせて任意の方法で Fine-tuning できます。
- 量子化は、標準的なコンピューティング プラットフォーム上でより広範囲のタスクに LLM のスタックを使用できる可能性を開くことが可能
4-2. 量子化の実装
SmoothQuant
MIT-Han Lab が開発。
LLM の 8 ビット重み、8 ビット アクティベーション (W8A8) 量子化を可能にする、トレーニング不要で精度を維持する汎用のポストトレーニング量子化 (PTQ) ソリューション。
AWQ
MIT-Han Lab が開発。
メモリ フットプリントを削減し、LLM の推論パフォーマンスを向上させるために使用できるアクティベーション対応重み量子化 (AWQ) 手法。
Intel Neural Compressor
Intel AI Analytics Toolkit の一部。
ポストトレーニング量子化 (PTQ) ツール、量子化対応トレーニング (QAT) ツール、量子化対応推論 (QAI) ツールなど、LLM 用の量子化ツールを多数提供している。
量子化と蒸留を引き続きフォローしていく必要がある。どちらも活発に動きがあり、さらなる発展が見込まれる重要な分野であることが予想される。
5. QLoRA
- QLoRA: Efficient Finetuning of Quantized LLMs
https://arxiv.org/abs/2305.14314
この論文と実装では、LoRA と量子化を基礎とした新しいメソッドQLoRAを提案しています。
- QLoRA は量子化に bitsandbytes を使用し、Huggingface の PEFT (ed. LoRA) および transformers ライブラリと統合されています。
QLoRA の新しい量子化手法の 3 つの主要な特徴は以下になります
- NF4(4 ビット NormalFloat)
- Double quantization
- Paged optimizers
5-1. Quantile Quantization(分位量子化)
Quantile Quantization(分位量子化)はかなり一般的な手法で、Python にはまさにそれを行う関数があります。
- 「分位量子化」では、各ビンに同じ数の値が含まれるように、データをビンに分割します。
- ニューラル ネットワークの重みの場合、重み値の範囲をビンに分割し、各ビンに同じ数の重みが含まれます。
分位量子化の制限
分位量子化にはいくつかの制限があります。主な問題は、分位数の推定に計算コストがかかる可能性があることです。
5-2. NF4(4 ビット NormalFloat)
再現量子化は、32 ビット浮動小数点数など、LLM 内の選択されたパラメーターのセットを取得し、それらを 4 ビット整数などのより小さな出力値のセットに変換するプロセスです。
QLoRAの論文には、 Quantile Quantizationの概念に基づいた NormalFloat (NF4) データ型である分位量子化のソリューションが記載されています。
- この手法は、入力テンソルが定数を除いて固定された分布 (ゼロ中心の正規分布など) に由来する場合に最適です。
- このような場合、入力テンソルは同じ分位数を持つため、推定が容易になります。
- ほとんどの事前トレーニング済みニューラル ネットワークの重みがゼロ中心正規分布に従うことも利用している。
- これらの重みをスケーリングすることにより、固定分布に適合するように重みを変換できる。
注意1
事前トレーニングされたニューラル ネットワークの重みはゼロ中心正規分布に従うため、QLoRA は重みが正規分布「ではない」LLM には適していない。大きく偏った分布がその例になります。
- 重みを変換した後、NF4 データ型を作成可能。
- NF4 を使用すると、著者らは 32 ビットの浮動ウェイトで 8 分の 1 の削減を実現している。
5-2. Double quantization(二重量子化)
QLoRAの論文では、「二重量子化」と呼ばれる 2 番目の手法が紹介されており、ビン量子化定数である量子化定数を再度量子化している。
5-3. Paged optimizers
トレーニング中のメモリ スパイクを効率的に処理するために、QLoRA はページ オプティマイザーと呼ばれる方法を採用しています。
メモリのスパイクは、モデルが大量のデータに同時にアクセスする必要がある場合に発生します。
なので、ページ オプティマイザーはモデルをページに分割し、現在のトレーニング反復に必要なページのみを読み込みます。
これにより、メモリの枯渇が防止され、スムーズな実行が保証されます。
5-4. QLoRAの3つの機能まとめ
- QLoRAの 3 つの機能にはそれぞれ、分位数の推定と NF4 データ型の作成に使用される特定の方程式や、パフォーマンスの低下を避けるための二重量子化の考慮事項などが含まれる
- 指示への従うことやチャットボットのパフォーマンスなど、さまざまなタスクに効果的であることが示された
- QLoRA は、Vicuna ベンチマークで以前に公開されたすべてのモデルを上回り、ChatGPT のパフォーマンス レベルの 99.3% に達し、単一の GPU で 24 時間の微調整のみを必要とする
(ワシントン大学の UW NLP グループ) - QLoRA は、大きすぎて 1 つの GPU に収まらない LLM を微調整するための最新の方法
- 実質的には1/16のサイズに縮小される
- 現時点で知られている QLoRA の実装は 1 つだけ
6. その他の手法
PEFT(Parameter-efficient Fine-tuning)
PEFTは一部のパラメータだけをファインチューニングするアプローチ。
Full Fine-tuningと同程度の精度を保ちつつ計算コストを削減し、優れた汎化性能を獲得することが可能。
現在発展しているPEFTのアプローチは大きく3つのコンセプトに分類可能
- トークン追加型
- Adapter型
- LoRA型
HuggingFaceによるPEFTの実装
https://github.com/huggingface/peft
Prefix Tuning: Prefix-Tuning
生成のための連続的なプロンプトの最適化を行う。
https://arxiv.org/pdf/2110.07602.pdf

P-Tuning
GPT Understands, Too
https://arxiv.org/abs/2103.10385
- GPTが訓練可能な連続的なプロンプト埋め込みを活用し、NLUタスクにおいて同等のサイズのBERTよりも優れた結果を出すことができる
- 知識探索(LAMA)ベンチマークでは、最も優れたGPTはテスト時に追加のテキストを提供せずに世界知識の64%を回復し、これは前回の最高記録を20パーセンテージポイント以上向上させた
- プロンプトエンジニアリングの必要性を大幅に減らしながら、少数のショットと教師データの設定でBERTの性能も向上させることを確認
- 少数のショットでSuperGlueベンチマークにおいて最先端のアプローチを上回る性能を発揮
Prompt Tuning
The Power of Scale for Parameter-Efficient Prompt Tuning
https://arxiv.org/abs/2104.08691
- プロンプトチューニングの探索を行っている。「ソフトプロンプト」を学習し、固定された言語モデルを特定の下流タスクを実行するように条件付けるためのシンプルかつ効果的なメカニズム
- ソフトプロンプトはバックプロパゲーションを通じて学習され、任意の数のラベル付き例からのシグナルを取り込むようにチューニングすることができる
- このエンドツーエンドの学習アプローチは、GPT-3の「few shot」学習を大きく上回る。
- ソフトプロンプトで固定モデルを条件付けることが、全体的なモデルチューニングと比較して、ドメイン転送に対するロバスト性の向上に利点をもたらす
AdaLoRA
Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning
https://arxiv.org/abs/2303.10512
- 重要性スコアに応じてパラメータ予算を重み行列間で適応的に割り当て。具体的には、AdaLoRAは増分更新を特異値分解の形でパラメータ化する。
- この新たなアプローチにより、我々は不要な更新の特異値を効果的に削除することができる。これは本質的にはそのパラメータ予算を減らすことであり、厳密なSVD計算を回避することを意味する
- 自然言語処理、質問応答、自然言語生成などのいくつかの事前訓練済みモデルに対する広範な実験を行った結果、特に低予算の設定において、AdaLoRAがベースラインを大幅に上回る改善を示した
7. 参考文献
-
Universal Language Model Fine-tuning for Text Classification, 2018 年 5 月
https://arxiv.org/abs/1801.06146 -
Truncated SVD and its Applications
https://langvillea.people.cofc.edu/DISSECTION-LAB/Emmie'sLSI-SVDModule/p5module.html -
A Step-by-Step Explanation of Principal Component Analysis (PCA)
https://builtin.com/data-science/step-step-explanation-principal-component-analysis -
Active Geophysical Monitoring
https://www.sciencedirect.com/topics/engineering/singular-value-decomposition#:~:text=Singular%20Value%20Decomposition%20(SVD)%20is%20a%20widely%20used%20technique%20to,properties%20of%20the%20original%20matrix. -
行列分解
https://developers.google.com/machine-learning/recommendation/collaborative/matrix?hl=ja -
LoRA: Low-Rank Adaptation of Large Language Models
https://arxiv.org/abs/2106.09685 -
Intriguing Properties of Quantization at Scale
https://arxiv.org/abs/2305.19268 -
量子化実装 SmoothQuant by MIT-Han Lab
https://github.com/mit-han-lab/smoothquant -
量子化実装 AWQ by MIT-Han Lab
https://github.com/mit-han-lab/llm-awq -
量子化実装 Intel Neural Compressor by Intel
https://github.com/intel/neural-compressor -
QLoRA: Efficient Finetuning of Quantized LLMs, 2023/05/23
https://arxiv.org/abs/2305.14314 -
QLoRAの実装
https://github.com/artidoro/qlora -
量子化実装 bitsandbytes
https://github.com/TimDettmers/bitsandbytes -
peft by HuggingFace
https://github.com/huggingface/peft -
transformers by HuggingFace
https://github.com/huggingface/transformers/ -
Binning Data with Pandas qcut and cut
https://pbpython.com/pandas-qcut-cut.html -
Prefix-Tuning: Optimizing Continuous Prompts for Generation
https://aclanthology.org/2021.acl-long.353/ -
P-Tuning v2: Prompt Tuning Can Be
Comparable to Fine-tuning Universally Across Scales and Tasks
https://arxiv.org/pdf/2110.07602.pdf -
GPT Understands, Too
https://arxiv.org/abs/2103.10385 -
The Power of Scale for Parameter-Efficient Prompt Tuning
https://arxiv.org/abs/2104.08691 -
Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning
https://arxiv.org/abs/2303.10512
https://github.com/QingruZhang/AdaLoRA