「データの現場から,初心者まで.待望の第1回開催!」(2025年11月17日開催)

データサイエンスとデータエンジニアリングの共同開催,待望の第1回である.アットホームな雰囲気の中,42名の参加者と実務経験豊富な登壇者たちが,実践的な知見を次々とシェアされた.初心者から実務経験者まで,誰もが「明日から試したい」という具体的な学びを持ち帰れた,素晴らしいイベントになった.
ご参加いただいた42名の皆様,貴重な知見をシェアしてくださった登壇者の皆様,コミュニティ運営の協力をいただいた庵原さん,檜山さん,そして会場と飲食の提供,その他の支援をしてくださったSnowflake合同会社に心から感謝申し上げます.皆様の参加と貢献があってこそ,このような素晴らしいイベントが実現できました.
イベント概要
開催日時:2025年11月17日(月)18:30 - 20:30
開催形式:オフライン(Snowflake合同会社 オフィス / 東京都中央区八重洲)
参加者数:42名 / 定員50名
参加費:無料
登壇内容
福井 克法 さん(株式会社NTTドコモ)
「誰でも使えるデータ抽出アプリをLLMとStreamlitで作った話」
NTTドコモで社内向けのデータ分析・アプリ開発を担当する福井さんが,LLMとStreamlitの組み合わせで,非エンジニアでもデータを扱えるアプリケーションを実装した事例を紹介された.
「データ活用の民主化」というテーマのもと,複雑なクエリ知識がなくても誰でも必要なデータにアクセスできるアプローチは,まさに現場の課題を解決する実践的なソリューションである.
LLMとStreamlitの組合せの強力さが本当によく伝わってきた.これまで「データ抽出=技術者の仕事」という固定観念があったが,福井さんのアプローチだと「ビジネスサイドの誰もが欲しいデータを自分で取得できる」という世界が実現するのだと理解できた.シンプルながらも,組織全体のデータリテラシー向上に繋がるアイデアだと感じた.最近ではSnowflake Intelligenceをはじめ,Cortex Agentsサービスで実装が楽になったり,表現力も大幅に向上しているため,ぜひ,目新しいサービスでの実装の体験談を次回共有いただけると嬉しい.
島崎 啓一 さん(Neuro Dive横浜)
「財務データETL基盤の設計・開発プロジェクト」
Neuro Dive横浜でデータ分析・データエンジニアリング技術を学習中の島崎さんが,財務データを扱うETL基盤の設計・開発プロジェクトの経験を共有された.
システム開発会社,デジタルマーケティング企業,帳票SaaS企業と多様なキャリアを経た島崎さんならではの,複数の業界視点から見たデータ基盤構築のポイントが話題に上った.初心者から実務経験者まで参考になる内容である.
発表資料(財務データETL基盤の個人開発)には,実装の詳細ステップが丁寧に記載されており,後からの学習リソースとしても価値の高い内容となっている.
島崎さんのキャリアパスそのものが「データエンジニアリングの実践的な学び方」を示しているようで興味深かった.複数の業界を経験された視点から,「ETL基盤を設計するときに何が重要か」という本質的な議論が展開されたのは,参加者の皆さんにとって大きな気づきになったはずである.後からスライド資料を参照することで,セッション内容をさらに深掘りできるのも良い点だと感じた.また,個人開発レベルでここまでの実装をされていたため,次回はビジネスへの適用での体験談をシェアいただけると嬉しい.
発表資料はこちら
喜田 紘介 さん(エクスチュア株式会社)
「オンプレ企業に送るSnowflakeはじめの一歩」
Snowflake Data Superheroes である喜田さんが,オンプレミス環境から Snowflake への移行・導入を検討している企業向けの実践的なアドバイスを話されていた.
日本PostgreSQLユーザ会 理事長として,データベース技術コミュニティを牽引する喜田さんならではの,「既存システムとの共存」「段階的な導入」といった現実的なアプローチが,参加者の関心を集めていた.
オンプレからクラウドへの移行は,技術的な課題だけでなく,組織的・運用的な課題も山積みである.その複雑さに向き合う喜田さんの実践的な知見は本当に価値がある.「いきなり全部移行する必要はない」「まずはこのデータから始めよう」という,段階的で無理のないアプローチが,特に意思決定層にとって参考になったと感じた.内部ステージとSnowpipeを使ったデモでは,Snowflakeデータベースへのデータのロードの手軽さを感じられる内容であった.また,デモ時のエラーをその後即座に対処されていた点も,さすが喜田さんだなと感じた.
古幡 征史 さん(株式会社GRI)
「Snowflakeを2倍使う方法」
Ph.D.を取得し,KPMG,USC,ドワンゴなど,AI領域での研究と複数の業界での実務経験を積んだ古幡さんが,Snowflakeの機能を最大限に活用するための実践的なTipsを紹介された.
単なる機能解説ではなく,「データ基盤としての Snowflake をどう戦略的に活用するか」という,経営的視点も交えたセッションである.発表資料(「Snowflakeを2倍使う方法」)では,組織導入のシナリオから実装パターンまで,具体的な戦略が示されている.
「Snowflakeを2倍使う」というタイトルは,最初は「新機能紹介かな?」と思ったが,実際には古幡さんの多業種での経験から生まれた「Snowflakeという基盤をどう組織内に浸透させるか」という,より深い議論だったのだ.データベースとしての性能だけでなく,組織のデータ文化づくりまで含めた包括的なアプローチが印象的である.レガシーなパイプライン処理をLLMを駆使しながら再現するデモをその場で披露されていて,専門家だけなくても一定ETL処理を実装することが手軽な世界になってきているように感じた.
発表資料はこちら
Snowflakeを2倍使う方法
田中 翔 さん(Snowflake合同会社)
「Snowflake のAgentic AI - Cortex CodeとData Science Agentのデモ」
Snowflake本社でデモ開発を担当する田中さんが,生成AIの最新トレンド「Agentic AI」を Snowflake の最新機能で実装する方法をライブデモで紹介された.
Cortex Code と Data Science Agent という,まさに「今,この瞬間のホットなテクノロジー」を,実際の動作を見ながら学べるセッションである.
ライブデモは本当に迫力があった.抽象的な「AI Agent」という概念が,Snowflake上でどのように動作し,何ができるのかが一目で理解できた.チャットでも「これはすぐに試したい」「営業チームにも見せたい」という反応が次々と上がり,参加者の皆さんのテンションが一気に高まったのが伝わってきた.技術的な先進性と実用性が両立したセッションである.私もこれらの新サービスを使うことで,実装の効率化を図っていきたい.
高須賀 将秀(NTT西日本株式会社)発表より
「初心者でもわかる数理最適化関連の話」
本セッションでは,数理最適化という一見難しそうなテーマを,初心者にもアクセス可能な形で解説した.博士号(情報学)を取得し,社会人ドクターとして研究活動を続けるとともに,実社会に役立つデータ活用プラットフォームを運営する立場から,「理論と実践の橋渡し」に注力した.特に強調したポイントは以下の3点で,
- なぜ数理最適化が大切なのか:ビジネスの現場で「最適な意思決定」がもたらす効果
- 具体的な応用例:Snowflakeを活用した実装の可能性
- 今後の数理最適化の展望:数理最適化を浸透させていくためにやるべきこと
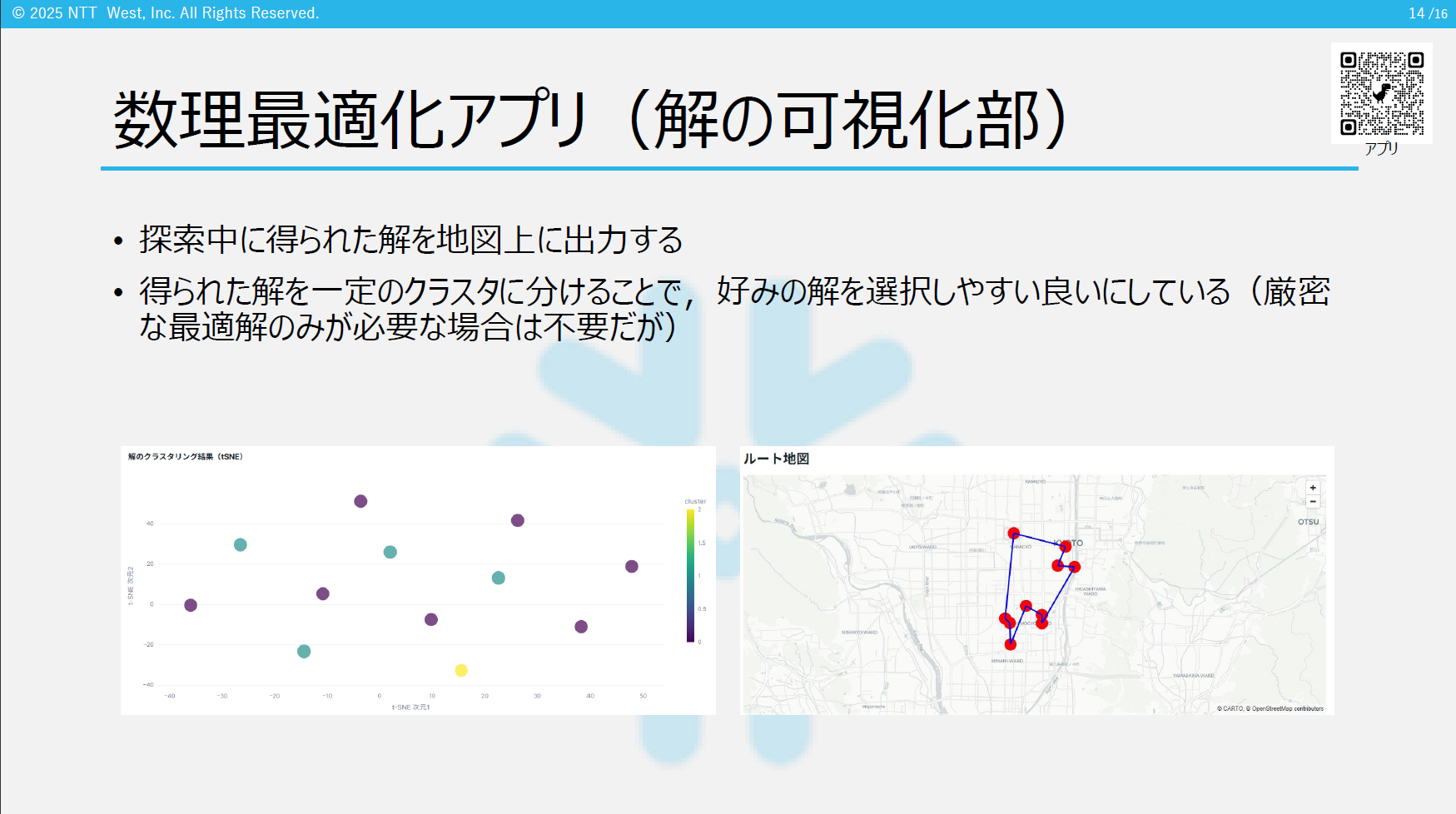
セッション内では,実際に動作する Streamlit アプリケーションをデモで紹介した.このアプリは,巡回セールスマン問題(TSP)という古典的な最適化問題を,Snowflakeとの連携でビジュアル化・実装できるものである.参加者が実際に「どんな風に最適化が動作するのか」を目で見ることで,数理最適化の価値がより直感的に理解できるようになっている.
さらに,今後の継続的な学習機会として,来週から始まる「数理最適化勉強会」)への招待も行った.このコミュニティでは,本イベントでの発表資料(初心者でもわかる数理最適化の話)をベースに,より深く,段階的に数理最適化を学んでいく場が提供していく.

発表資料はこちら
ネットワーキングタイム ~流動的な交流で深まる繋がり~
当初予定で19:50からのネットワーキングタイムは,最初から終了時刻を厳密に区切るのではなく,セッションの進行状況と参加者の雰囲気に合わせて,臨機応変に適宜休憩を入れながら流動的に実施した.
Snowflake合同会社が提供してくださったピザを前に,参加者たちが自然と輪を作り,和やかな雰囲気が形成された.お酒も用意され,登壇者と参加者,参加者同士が肩の力を抜いて交流できる空間を生み出せていた.
このような流動的な運営により,参加者たちは「時間に追われることなく」自然とペースを保ちながら交流できたように感じる.疲れた時には一呼吸置き,興味深い話が出てきたらそこに集中するという,人間関係構築に最適な環境が実現されたのだと感じた.
今回のサマリー
DataScience&DataEngineering MeetUp #1 は,42名の参加者が集まり,記念すべき第1回として相応しい充実した内容になった.テーマは大きく5つの軸で構成され,充実した内容であった.
- データ活用の民主化(LLM × Streamlit)
- データエンジニアリングの実践(ETL基盤設計)
- クラウド移行の現実(オンプレ→Snowflakeへの移行の手軽さの実演)
- プラットフォーム戦略(Snowflakeの最大活用)
- Snowflakeの最新AI技術(実装デモを通じた実現性の高さ,Agentic AI)
登壇者には,データ領域の第一線で活躍するエキスパートが揃い,「理論」だけでなく「実務の現場で何が起きているのか」という生のナレッジが惜しみなく共有された.特に注目すべきは,セッション内容が「その場限りの知識」で終わらない設計になっていた点である.数理最適化勉強会のように,参加者が学習を継続できるコミュニティへの導線が準備したり,実装アプリやスライド資料が公開されたりと,イベント後も参加者が深掘りできる環境を整えられた.
また,流動的なネットワーキング運営とSnowflakeさんの気配りが合わさった結果,参加者たちの心理的な距離が自然と縮まり,より本音での交流が生まれたと考える.時間制限に追われるのではなく,参加者のペースに合わせた運営が,コミュニティ形成の大切な要素だったのだと思う.
LT枠も申し込み満席となるなど,登壇したいというエンジニアの関心の高さも伝わってきた.会場は一貫して盛り上がりを見せ,短い時間ながらも確実に参加者の皆さんに「次のアクション」と「新しい仲間との繋がり」の両方を持ち帰っていただけたイベントになったと感じた.
本当に学びと繋がりの多い2時間であった.「敷居が高い」というコミュニティイベントのイメージを払拭し,初心者から実務経験者まで,全ての方が気軽に参加できる雰囲気づくりがここまで実現されているのは,参加者の皆様の温かい雰囲気づくりと,登壇者の皆様の熱心なシェア,そして庵原さん,檜山さんとのコミュニティ運営の協力,Snowflake合同会社の場所と心遣いがあってこそだと思う.

皆様へのお礼
昨日の DataScience&DataEngineering MeetUp #1 にご参加いただきました皆様,本当にありがとうございました!
参加者の皆様,登壇者の皆様,庵原さん,檜山さん,そしてSnowflakeさんあっての会だったと思います.初回,良いスタートがきれました!
このコミュニティは,皆様一人ひとりの参加と貢献によって成り立っています.セッション内容も素晴らしかったですが,何より参加者同士が自然に情報交換し,新しい仲間との繋がりが生まれたあのネットワーキングタイムの雰囲気こそが,このコミュニティの最大の価値だと考えています.
次回以降も,皆さんで一緒にこのコミュニティを盛り上げていけたら幸いです.
次回予告
半年に1回程度のペースで開催予定です.次回は 2026年5月頃 の開催を企画しています.今回参加できなかった方もぜひご参加,ご登壇いただけますと幸いです!

セッション登壇者をお探ししています.「実は自分の実務経験をシェアしたい」「このテーマについて話してみたい」という皆様のご登壇を心よりお待ちしています.
詳細が決まりましたら,SnowVillageの#data-science,#data-engineering チャネルで発信するため,ぜひチェックしてお申し込みください.また,本セッションで紹介した 数理最適化勉強会(https://opt-research.connpass.com/)も来週から開始されます.セッションでの「初めての一歩」を,継続的な学習へ繋げたい皆様はぜひご参加ください.
周りのデータ関連の仲間にもお声がけいただければ幸いである.データの世界で一緒に学び,成長しましょう!