Phoenix には Ecto と呼ばれるデータベース操作ライブラリがあり、PostgreSQL や MySQL(MariaDB)、SQLite といったものに対応しています。
Ecto を使うと定義したモデルを元に簡単に(SQL を書かずに)CRUD 操作ができるようなのですが、今回はあえて生の SQL を発行して MariaDB に問い合わせることをしたいと思います。
Phoenix アプリケーションの作成についてはコチラを参照してください。
なぜ生 SQL なのか
Ecto はモデル定義さえすれば、それを使った CRUD 操作やテーブルの作成、果ては JSON API や HTML までも生成してくれる優れものです。
ただ、自分の経験上、DB 操作を伴う大規模な WebAPI を開発していくと、以下のようなケースに遭遇し、どうしても生 SQL を書きたくなることが多いです。
- レコード数が増加するにつれパフォーマンスが低下し、SQL を細かくチューニングする必要がでてくる
- データベースが提供するコアな関数が使いたくなってくる
- テーブルのリレーションが複雑化し、フレームワークが提供する CRUD 操作では対応しきれなくなってくる
- 句が複雑化するにつれ、DSL の DSL という存在にイラ立ちを覚え始める
もちろん、フレームワークの範疇に収まるようにテーブルを設計していくのがベストではあるのですが、どうにもこうにもならなくなっていくのが世の常でもあります。
保険の意味も込めて、生 SQL も書けるようにしておきたいところです。
下準備: MariaDB をセットアップする
今回はローカルで MariaDB を起動させて使います。
インストールされていない場合は、公式サイトからダウンロードするか、Mac であれば homebrew を使ってインストールします。
(ちなみに執筆時点での最新安定バージョンは 10.0.21 です。)
インストールが完了したら、MariaDB サーバを起動して、ターミナルから操作していきます。
まずは phoenix_sample というデータベースを作成しましょう。
MariaDB [(none)]> CREATE DATABASE phoenix_sample;
次にテーブルを作成します。
今回は ipa_t というテーブルで IPA(インディア・ペールエール)の種類を管理してみます。
MariaDB [(none)]> use phoenix_sample
Database changed
MariaDB [phoenix_sample]> CREATE TABLE ipa_t (
-> id INT AUTO_INCREMENT,
-> name varchar(256) NOT NULL,
-> abv FLOAT NOT NULL,
-> PRIMARY KEY (id)
-> );
以上で下準備は完了です。
Phoenix アプリケーションをセットアップする
mariadb_sample というアプリケーションを作成します。
オプションに --database mysql をつけることで、利用DB がデフォルトの PostgreSQL から MySQL(MariaDB)に変更されます。
$ mix phoenix.new mariadb_sample --database mysql
mix.exs に MariaDB 接続用ライブラリ mariaex が追加されていることが確認できます。
defmodule MariadbSample.Mixfile do
...
defp deps do
[{:phoenix, "~> 0.17"},
{:phoenix_ecto, "~> 1.1"},
{:mariaex, ">= 0.0.0"},
{:phoenix_html, "~> 2.1"},
{:phoenix_live_reload, "~> 1.0", only: :dev},
{:cowboy, "~> 1.0"}]
end
end
DB 接続情報は config/dev.exs というファイルに記載されています。
database の名前をデフォルトの mariadb_sample_dev から phoenix_sample に変えておきましょう。
...
# Configure your database
config :mariadb_sample, MariadbSample.Repo,
adapter: Ecto.Adapters.MySQL,
username: "root",
password: "",
# database: "mariadb_sample_dev",
database: "phoenix_sample",
pool_size: 10
以上でアプリケーションの設定は完了です。
Insert と Select のエンドポイントを作成する
IPA の情報を Insert する口と Select する口を作ります。
web/router.ex に以下のスコープを追加します。
defmodule MariadbSample.Router do
...
scope "/ipa", MariadbSample do
pipe_through :api
get "/", MariadbSample, :select_all
get "/:id", MariadbSample, :select
post "/", MariadbSample, :insert
end
...
end
次に、web/controllers/page_controller.ex に各エンドポイントを実装します。
defmodule MariadbSample.PageController do
...
def to_column_map(columns, rows) do
Enum.map(rows, fn row -> Enum.into(List.zip([columns, row]), %{}) end)
end
def select_all(conn, _params) do
case Ecto.Adapters.SQL.query(MariadbSample.Repo, "SELECT id, name, abv from ipa_t", []) do
{:ok, result} -> json conn, to_column_map(result[:columns], result[:rows])
{:error, e} -> json conn, %{error: e}
end
end
def select(conn, %{"id" => id}) do
case Ecto.Adapters.SQL.query(MariadbSample.Repo, "SELECT id, name, abv from ipa_t where id = ?", [id]) do
{:ok, result} -> json conn, to_column_map(result[:columns], result[:rows])
{:error, e} -> json conn, %{error: e}
end
end
def insert(conn, _params) do
{:ok, data, _conn_details} = Plug.Conn.read_body(conn)
posted = Poison.Parser.parse!(data)
case Ecto.Adapters.SQL.query(MariadbSample.Repo, "INSERT INTO ipa_t(name, abv) VALUE (?, ?)", [posted["name"], posted["abv"]]) do
{:ok, result} -> json conn, %{succeed: 1}
{:error, e} -> json conn, %{error: e}
end
json conn, nil
end
end
Select 系エンドポイントで発行している SQL は極めて単純で、select_all では全件取得、select では id を指定した検索を行います。
Ecto.Adapters.SQL.query/3 が生 SQL を発行する関数で、第1引数に Repo、第2引数に SQL(プリペアドステートメント)、第3引数にバインドするパラメータのリストを指定します。
返却は、成功したら {:ok, ...}、失敗したら {:error, ...} という形になっているので、case で処理を分岐させています。
成功時に呼び出される to_column_map/2 という関数が定義されていますが、これは「カラム名リスト」と「値リスト」の2つのリストを合体させてマップにするものです。
内部で呼ばれている各関数の働きは以下のような感じです。
iex(31)> keys = ["a", "b", "c"]
["a", "b", "c"]
iex(32)> values = ["1", "2,", "3"]
["1", "2,", "3"]
iex(33)> zipped = List.zip([keys, values])
[{"a", "1"}, {"b", "2,"}, {"c", "3"}]
iex(34)> Enum.into(zipped, %{})
%{"a" => "1", "b" => "2,", "c" => "3"}
組み込み関数でここまでできるのは、さすがモダン言語という感じがしますね。
Insert エンドポイントで発行されている SQL も、特に変わったことはしていません。
一点、今回は POST リクエストの body に詰められた JSON をパースして Insert 用のデータを作成しています。
(unofficial っぽいですが)Phoenix では {:ok, data, _conn_details} = Plug.Conn.read_body(conn) と書くだけで簡単に body の文字列を取得できますので、あとはそれを Poison を使ってパースしています。
例外処理を一切無視した状態ではありますが、Ecto を使った生 SQL 発行の実装はこんな感じになります。
API を叩いてみる
早速作成した API を叩いてみましょう。
まずは DHC を使ってデータを POST してみます。
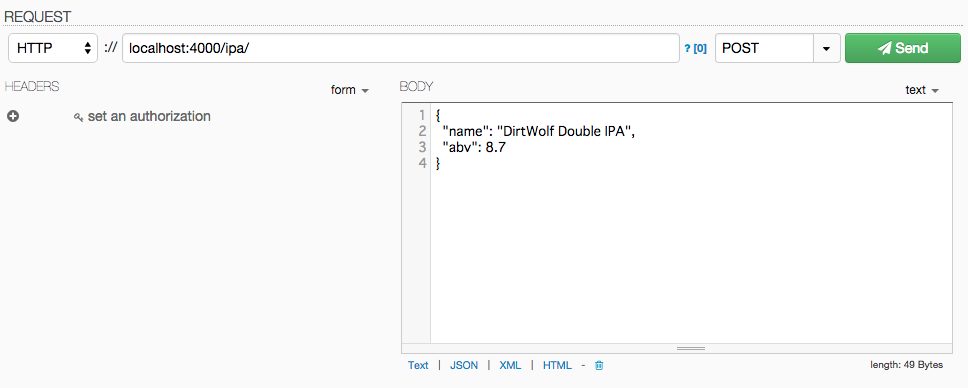
Send ボタンを押して {"succeed": 1} と返却されれば成功です。
Top 10 IPAs の情報をもとに、適当に 2,3 種類の IPA を登録しましょう。
データを入れ終わったら、検索してみます。
全件検索するとこんな感じです。
$ curl -s "http://localhost:4000/ipa/" | jq .
[
{
"abv": 5,
"id": 1,
"name": "Samuel Smith's India Ale"
},
{
"abv": 5.599999904632568,
"id": 2,
"name": "Toasted Oak India Pale Ale"
},
{
"abv": 8.699999809265137,
"id": 3,
"name": "DirtWolf Double IPA"
}
]
何やら小数値がアヤシイ感じになってしまいましたが、だいたい期待通りの結果となりました。
次に ID 引きをするとこんな感じです。
$ curl -s "http://localhost:4000/ipa/2" | jq .
[
{
"abv": 5.599999904632568,
"id": 2,
"name": "Toasted Oak India Pale Ale"
}
]
こちらも小数値以外は期待通りの挙動です。
感想
- Ecto にも(一応)生 SQL を実行する API があって、ちゃんと使えた
- ただし、小数値の挙動をみる限り型の考慮がアヤシイ
- このままだと日付とかの扱いが面倒なことになりそう
- なんとか手をうったほうがよい
- SQL と関係ないけど Request Body を取得するスニペットの挙動もアヤシイ
- curl コマンドで JSON 食わせるとうまく動かなかった