2022年11月にAmazon S3 から Amazon Redshift へのデータの読み込みを簡素化する自動コピー機能のプレビューの提供が開始されました。
https://aws.amazon.com/jp/about-aws/whats-new/2022/11/amazon-redshift-supports-auto-copy-amazon-s3/
すでに使ってみた等の簡単な動作確認は他の記事でも紹介されていますが、振る舞いについて細かく確認していきます。
注意
プレビュー版の終了時期が設定されているのでご注意ください。
パブリックプレビューは 2023 年 10 月 15 日に終了します。プレビュークラスターは、プレビュー終了 2 週間後に自動的に削除されます。
概要
自動コピー機能はCOPYコマンドを拡張したものです。
COPYコマンドを発行すると、COPYジョブとしてテーブル名などのパラメータと共に保存されます。
従来はコピーのたびにジョブの実行が必要でしたが、今回のプレビュー機能により自動で継続的に取り込むことが可能になります。
詳細はドキュメントをご確認ください。
https://docs.aws.amazon.com/ja_jp/redshift/latest/dg/r_COPY-JOB.html
準備
すでに実行できる環境があれば飛ばしてください。
S3バケットの作成
任意のバケット、フォルダを作成します。
IAMロール作成
COPY コマンドを実行するためにロール・ポリシーが必要です。
・Redshiftテーブルへロードするための INSERT権限
・S3バケットへアクセスする権限
プレビュー版のクラスター構築
クラスタの作成
• IAMロールを関連付ける
-
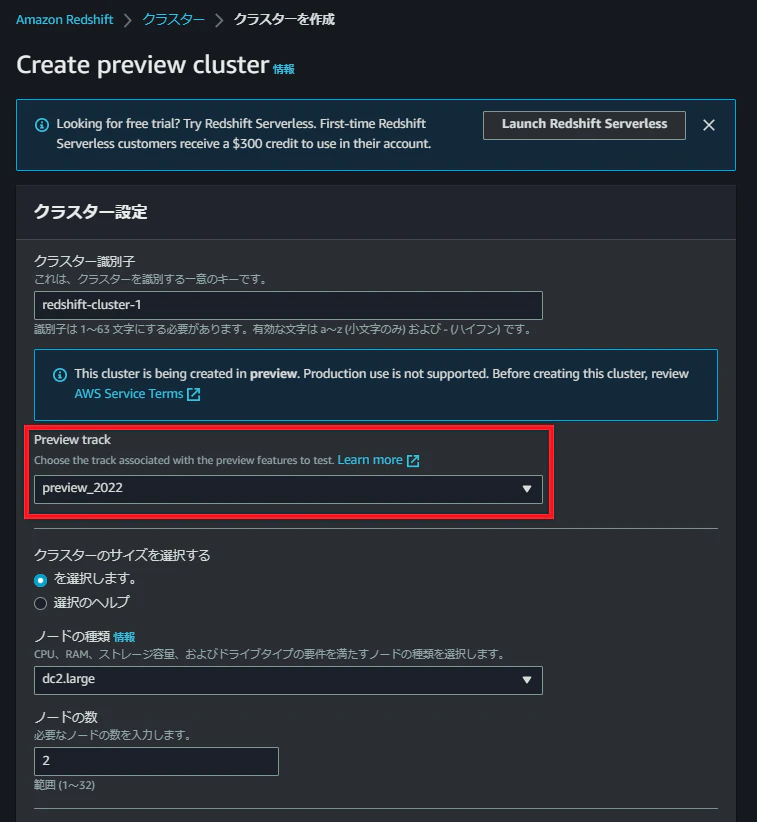
Redshiftのクラスター作成画面の上部に表示される「Create preview cluster」を選択します。
ここで作成したIAMロールを紐づけます。

-
クラスター設定で「Preview track」から「preview_2022」を選択します。
-
クラスターを起動します。
クラスターの起動には数分かかります。
テーブルの作成
クラスターが起動できたら、テーブルを作成します。
CREATE TABLE "public"."table-sample" (
id INTEGER
, value VARCHAR(100)
);
テストデータ作成
2カラムでヘッダーを含む1行のCSVを3種類用意しています。
id,value
1,aaa
id,value
2,bbb
id,value
3,ccc
基本
①自動コピーのCOPYコマンドを実行
自動コピー機能を実行するCOPYコマンドです。
パラメータは必要に応じて変更してください。参考:COPY 構文概要
COPY "スキーマ名"."テーブル名"
FROM 'S3バケットディレクトリ'
IAM_ROLE 'IAMロール'
IGNOREHEADER 1
JOB CREATE "ジョブ名"
AUTO ON;
②基本動作
今回の例では以下の通りです。

作成したテーブルは空の状態です。

COPYジョブに指定したS3のフォルダにテストファイルを置きます。
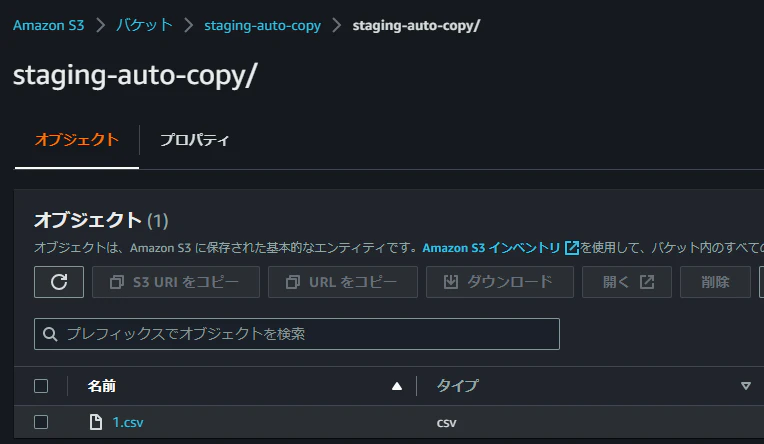
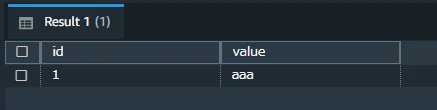
その後、テーブルを確認するとCSVファイルの中身が取り込まれています。
③JOBのステータスの確認方法
COPYジョブの内容や実行履歴は以下のコマンドで確認できます。
| コマンド | 内容 |
|---|---|
| SYS_COPY_JOB | 現在定義されている各 COPY JOB の一覧(プレビュー) |
| SYS_LOAD_HISTORY | ロード履歴 |
| STL_LOAD_COMMIT | ロード履歴の詳細 |
| STL_LOAD_ERRORS | ロードエラー概要 |
| SYS_LOAD_ERROR_DETAIL | ロードエラーの詳細 |
④対応するファイル形式
COPYコマンドで使用できる取り込めるファイル形式は以下の通りです。
- FORMAT
- CSV
- DELIMITER
- FIXEDWIDTH
- SHAPEFILE
- AVRO
- JSON
- ENCRYPTED
- BZIP2
- GZIP
- LZOP
- PARQUET
- ORC
- ZSTD
詳細
①バケットとジョブの状態による動作
色々なパターンでの動作を確認します。
-
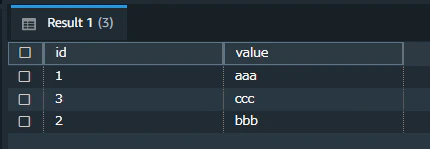
複数ファイルをまとめて追加する
2.csvと3.csvを追加します。

追加した行が増えていますが、登録順はランダムになっています。
-
ファイルを上書きする
3.csvの内容を「valueをddd」として書き換えた状態で上書きしてみます。
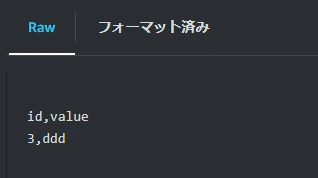
valueがcccのままとなり、更新されません。
-
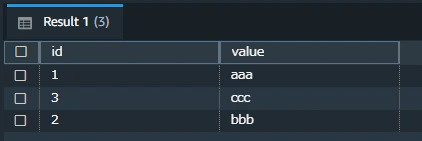
ファイルを削除する
2.csvのファイルを削除します。

こちらも変化は置きません。
確認したパターンをまとめると以下の通りでした。
| ジョブON | ジョブOFF→ON | |
|---|---|---|
| ファイルが既に置かれている場合 | 〇 | 〇 |
| ファイルを上書きした場合 | × | × |
| ファイルを削除した場合、削除されるか | × | × |
OFFにした後、一度読み取ったものを削除し、再度ONにしても読み取りません。
すでに読み取ったファイルパスは除外されるため、ジョブの初期化が必要となります。
②ファイルの形式やカラムが変わった場合
- ファイル形式が変わった場合
基本的にはないと思われますが、誤って置かれた場合に読み取られないかどうか、ファイル形式が変わった場合の動作を確認します。
JSONファイルを追加してみます。
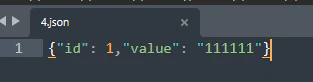
テーブルに変化はありません。

HISTRYを確認すると、4.jsonは認識していますがフォーマットはCSVであるため取り込まれません。

- カラムの並び順を入れ替える
カラムの並び順を変えてみます。
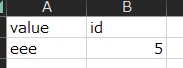
テーブルに変化がなくERRORSを確認すると、
ヘッダーは考慮されずvalue列をid列として認識したためTypeエラーとなっていました。

- カラムを追加する
カラムを新たに追加してみます。

Extra column(s) found のエラーとなり取り込まれません。

これらの動作はCOPYコマンド自体によるものであり、
列名を指定する設定を行うことで取り込むことも可能です。
③同一バケット内の別フォルダのファイルで同一テーブルを更新させる場合
3カラムでヘッダーを含む5行のCSVを2種類用意しています。
ID,Name,Category
0001,test0001,01
0002,test0002,04
0003,test0003,04
0004,test0004,03
0005,test0005,03
ID,Name,Category
0006,test0006,04
0007,test0007,01
0008,test0008,02
0009,test0009,04
0010,test0010,04
テーブルに制約を付けない場合
- コピー先のテーブルを作成
s3のファイルの内容をコピーするテーブルを作成します。
CREATE TABLE "AutoCopyTest_08"(
"ID" CHAR(4) NULL,
"Name" VARCHAR(10) NULL,
"Category" CHAR(3) NULL
) ;
データは何も挿入しない状態でcreateしました。
- S3の同一バケット内にフォルダを2つ作成
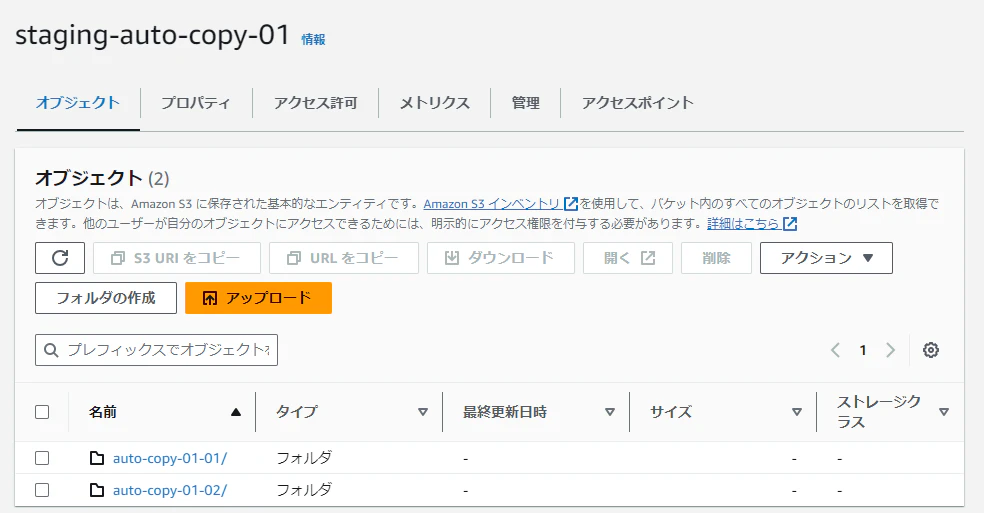
- copyジョブを作成
それぞれのフォルダから同一のテーブルを更新するcopyジョブを作成します。
COPY "autocopytest_08"
FROM 's3のバケット/auto-copy-01-01/'
IAM_ROLE 'IAMロール'
FORMAT AS CSV
DELIMITER ','
QUOTE '"'
IGNOREHEADER 1
JOB CREATE "staging-auto-copy-job-08-01"
AUTO ON
COPY "autocopytest_08"
FROM 's3のバケット/auto-copy-01-02/'
IAM_ROLE 'IAMロール'
FORMAT AS CSV
DELIMITER ','
QUOTE '"'
IGNOREHEADER 1
JOB CREATE "staging-auto-copy-job-08-02"
AUTO ON
- それぞれのフォルダに別々のファイルを配置
作成した2つのs3のフォルダに、それぞれデータが異なるファイルを配置します。
「auto-copy-01-01」フォルダには sample1.csv、
「auto-copy-01-02」フォルダには sample2.csv を配置しました。


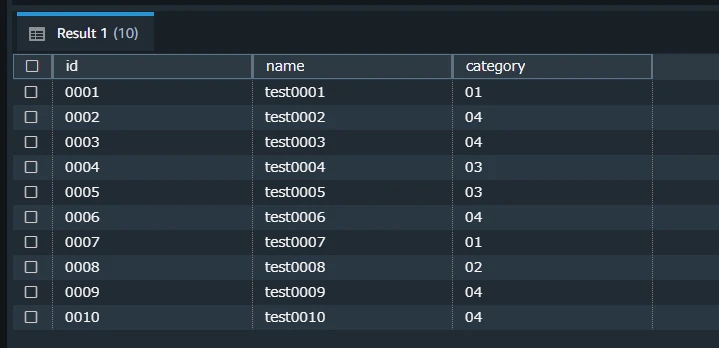
テーブルを見ると、2ファイル分のデータが同一テーブルにinsertされたことを確認できました。
select * from "AutoCopyTest_08"
「auto-copy-01-01」フォルダに、「auto-copy-01-02」フォルダに配置したファイル sample2.csv と全く同一のファイルを配置します。

テーブルを見ると、追加したファイル分のデータがテーブルに追加でinsertされたことを確認できました。
select * from "AutoCopyTest_08"

結果として、同じファイルの内容が2度重複してテーブルにinsertされたことになります。
テーブルに一意キー制約を付けた場合
- コピー先のテーブルを作成
s3のファイルの内容をコピーするテーブルを作成します。
CREATE TABLE "AutoCopyTest_08_unique"(
"ID" CHAR(4) NULL,
"Name" VARCHAR(10) NULL,
"Category" CHAR(3) NULL
UNIQUE ("ID")
) ;
データは何も挿入しない状態でcreateしました。
- S3の同一バケット内にフォルダを2つ作成
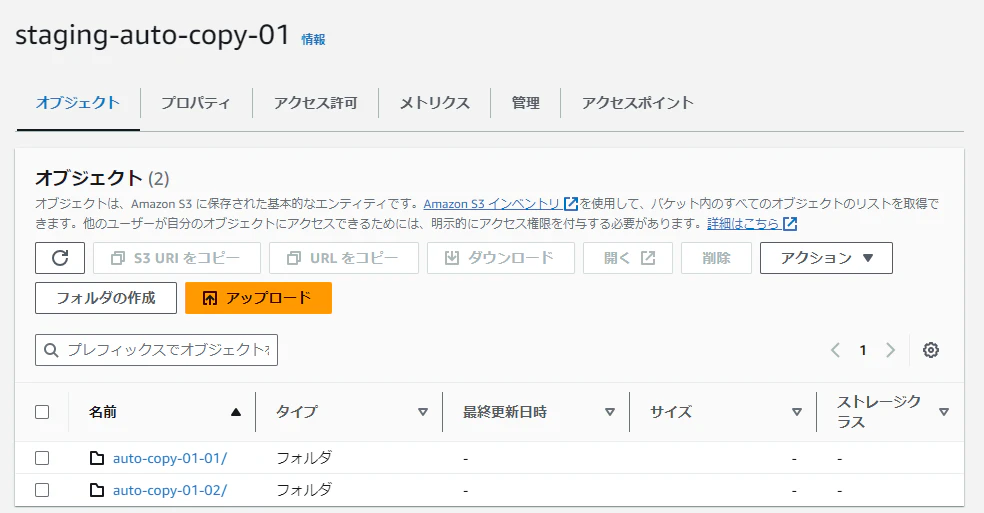
- copyジョブを作成
それぞれのフォルダから同一のテーブルを更新するcopyジョブを作成します。
COPY "autocopytest_08_unique"
FROM 's3のバケット/auto-copy-01-01/'
IAM_ROLE 'IAMロール'
FORMAT AS CSV
DELIMITER ','
QUOTE '"'
IGNOREHEADER 1
JOB CREATE "staging-auto-copy-job-08-01-unique"
AUTO ON
COPY "autocopytest"."autocopytest_08_unique"
FROM 's3のバケット/auto-copy-01-02/'
IAM_ROLE 'IAMロール'
FORMAT AS CSV
DELIMITER ','
QUOTE '"'
IGNOREHEADER 1
JOB CREATE "staging-auto-copy-job-08-02-unique"
AUTO ON
- それぞれのフォルダに別々のファイルを配置
作成した2つのs3のフォルダに、それぞれデータが異なるファイルを配置します。
「auto-copy-01-01」フォルダには sample1.csv、
「auto-copy-01-02」フォルダには sample2.csv を配置しました。


テーブルを見ると、2ファイル分のデータが同一テーブルにinsertされたことを確認できました。
select * from "AutoCopyTest_08_unique"

「auto-copy-01-01」フォルダに、「auto-copy-01-02」フォルダに配置したファイル sample2.csv と全く同一のファイルを配置します。
テーブルを見ると、追加したファイル分のデータがテーブルに追加でinsertされたことを確認できました。
select * from "AutoCopyTest_08_unique"
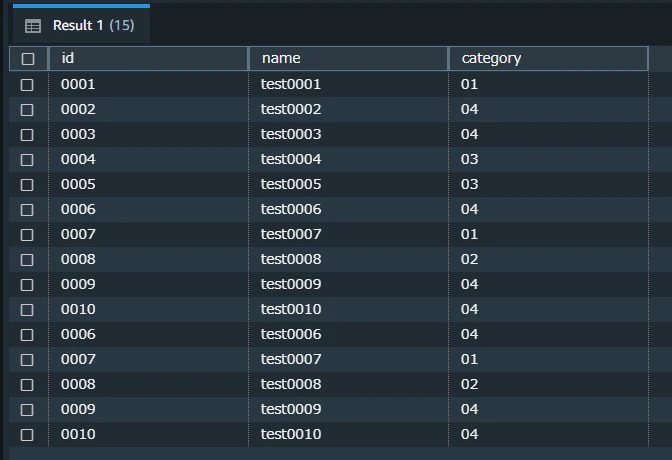
結果として、同じファイルの内容が2度重複してテーブルにinsertされたことになります。
RedShift上での一意キー制約は意味をなさないので、重複したファイルの登録を避けることはできませんでした。
④別バケットのファイルで同一テーブルを更新させる場合
3カラムでヘッダーを含む5行のCSVを2種類用意しています。
ID,Name,Category
0001,test0001,01
0002,test0002,04
0003,test0003,04
0004,test0004,03
0005,test0005,03
ID,Name,Category
0011,test0011,01
0012,test0012,04
0013,test0013,04
0014,test0014,03
0015,test0015,04
テーブルに制約を付けない場合
- コピー先のテーブルを作成
s3のファイルの内容をコピーするテーブルを作成します。
CREATE TABLE "AutoCopyTest_09"(
"ID" CHAR(4) NULL,
"Name" VARCHAR(10) NULL,
"Category" CHAR(3) NULL
) ;
データは何も挿入しない状態でcreateしました。
- S3にバケットを2つ作成
今回は赤枠内の2バケットを使用します。
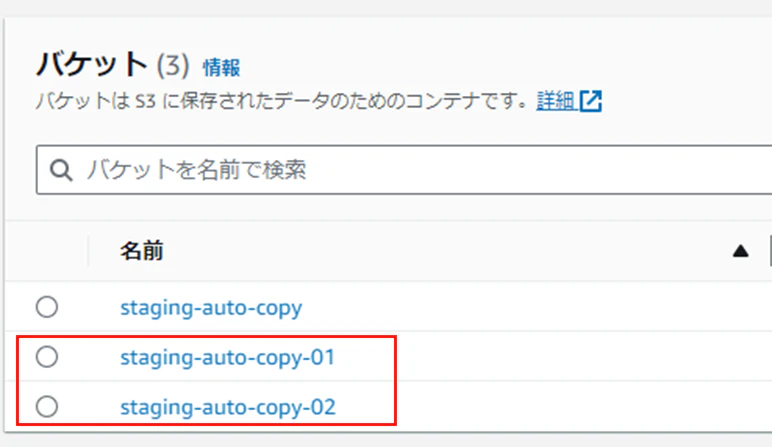
- copyジョブを作成
それぞれのバケットから同一のテーブルを更新するcopyジョブを作成します。
COPY "autocopytest_09"
FROM 's3://staging-auto-copy-01/バケット内のフォルダ/'
IAM_ROLE 'IAMロール'
FORMAT AS CSV
DELIMITER ','
QUOTE '"'
IGNOREHEADER 1
JOB CREATE "staging-auto-copy-job-08-03"
AUTO ON
COPY "autocopytest_09"
FROM 's3://staging-auto-copy-02/バケット内のフォルダ/'
IAM_ROLE 'IAMロール'
FORMAT AS CSV
DELIMITER ','
QUOTE '"'
IGNOREHEADER 1
JOB CREATE "staging-auto-copy-job-08-04"
AUTO ON
- それぞれのフォルダに別々のファイルを配置
作成した2つのs3のフォルダに、それぞれデータが異なるファイルを配置します。
「staging-auto-copy-01」バケットには sample1.csv、
「staging-auto-copy-02」バケットには sample3.csv を配置しました。


テーブルを見ると、2バケット分のデータが同一テーブルにinsertされたことを確認できました。
select * from "AutoCopyTest_09"
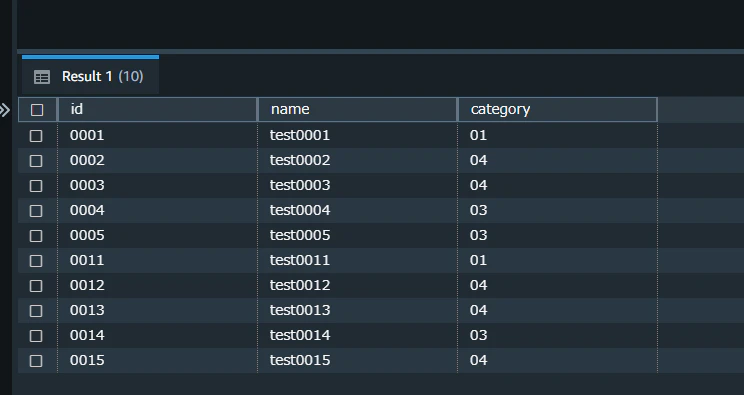
「staging-auto-copy-01」バケットに、「staging-auto-copy-02」バケットに配置したファイル sample3.csv と全く同一のファイルを配置します。

テーブルを見ると、追加したファイル分のデータがテーブルに追加でinsertされたことを確認できました。
select * from "AutoCopyTest_09"
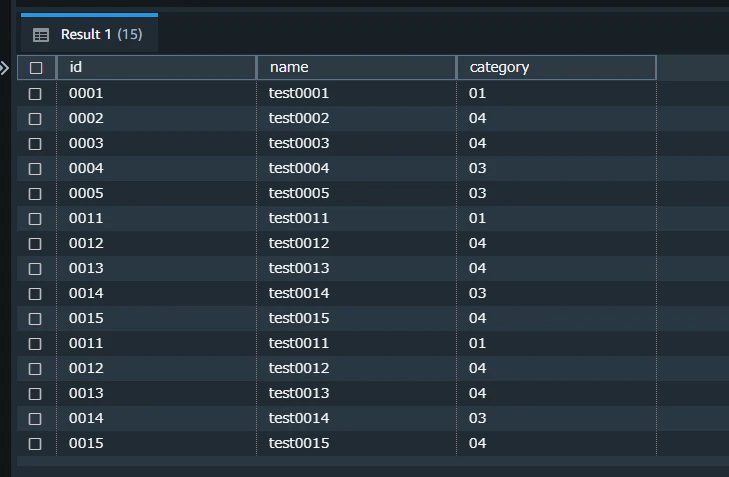
結果として、同じファイルの内容が2度重複してテーブルにinsertされたことになります。
④と同じ結果となりました。
テーブルに一意キー制約を付けた場合
- コピー先のテーブルを作成
s3のファイルの内容をコピーするテーブルを作成します。
CREATE TABLE "AutoCopyTest_09_unique"(
"ID" CHAR(4) NULL,
"Name" VARCHAR(10) NULL,
"Category" CHAR(3) NULL
UNIQUE ("ID")
) ;
データは何も挿入しない状態でcreateしました。
- S3にバケットを2つ作成
今回は赤枠内の2バケットを使用します。

- copyジョブを作成
それぞれのバケットから同一のテーブルを更新するcopyジョブを作成します。
COPY "autocopytest_09_unique"
FROM 's3://staging-auto-copy-01/バケット内のフォルダ/'
IAM_ROLE 'IAMロール'
FORMAT AS CSV
DELIMITER ','
QUOTE '"'
IGNOREHEADER 1
JOB CREATE "staging-auto-copy-job-08-03-unique"
AUTO ON
COPY "autocopytest_09_unique"
FROM 's3://staging-auto-copy-02/バケット内のフォルダ/'
IAM_ROLE 'IAMロール'
FORMAT AS CSV
DELIMITER ','
QUOTE '"'
IGNOREHEADER 1
JOB CREATE "staging-auto-copy-job-08-04-unique"
AUTO ON
- それぞれのフォルダに別々のファイルを配置
作成した2つのs3のフォルダに、それぞれデータが異なるファイルを配置します。
「staging-auto-copy-01」バケットには sample1.csv、
「staging-auto-copy-02」バケットには sample3.csv を配置しました。


テーブルを見ると、2バケット分のデータが同一テーブルにinsertされたことを確認できました。
select * from "AutoCopyTest_09_unique"

「staging-auto-copy-01」バケットに、「staging-auto-copy-02」バケットに配置したファイル sample3.csv と全く同一のファイルを配置します。

テーブルを見ると、追加したファイル分のデータがテーブルに追加でinsertされたことを確認できました。
select * from "AutoCopyTest_09_unique"
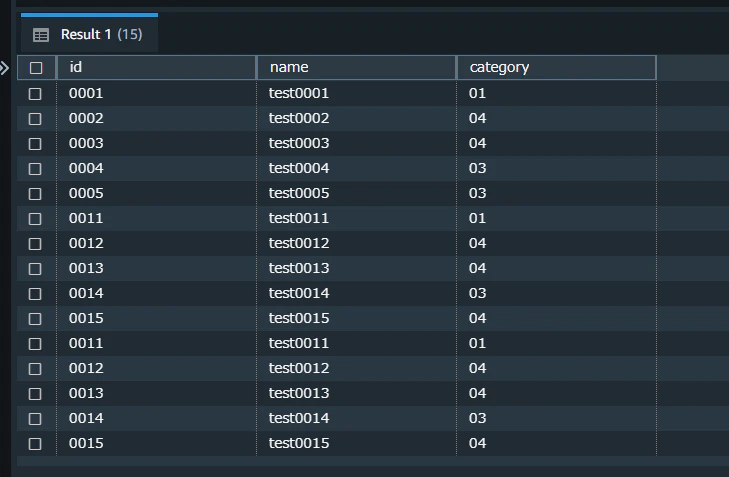
結果として、同じファイルの内容が2度重複してテーブルにinsertされたことになります。
④と同じ結果となりました。
RedShift上での一意キー制約は意味をなさないので、重複したファイルの登録を避けることはできませんでした。
最後に
今回検証に用いた自動コピーはCOPYコマンドの拡張版であり、ロードするファイルに合わせてパラメータを設定することで調整が可能です。
従来はロードをGlue等のETLジョブ等で実行する必要がありました。自動コピーによって直接Redshiftでロードが減ります。ただ現在はプレビュー版ですので、一般公開を待ちましょう。
株式会社ジールでは、初期費用が不要で運用・保守の手間もかからず、ノーコード・ローコードですぐに手元データを分析可能なオールインワン型データ活用プラットフォーム「ZEUSCloud」を提供しております。
ご興味がある方は是非下記のリンクをご覧ください:
https://www.zdh.co.jp/products-services/cloud-data/zeuscloud/