一言で言うと
VQAなどのタスクで用いられるscene-graphを生成するモデルであるgraph-rcnnを触ってみたのでまとめました.
論文はこちら
元実装コードはこちら
可視化結果を追加したコードはこちら
何のための記事?
- Graph R-CNN for Scene Graph Generationの解説
- ↑の実装を回す際の道標
VQAとは?
VQAとはVisual Question Answeringの略で,画像と選択肢付きの質問文が与えられた時に正解の選択肢を選ぶと言うタスクです.こちらの記事でも説明されていますが,下の画像のようなイメージです.

https://arxiv.org/pdf/1505.00468.pdf
画像の内容と質問文の内容を理解する必要があるので,CVとNLPを掛け合わせた技術といえるでしょう.
scene graphとは?
上記のVQAのタスクを解くために,CV側の処理として提案されているのがscene graph生成です.
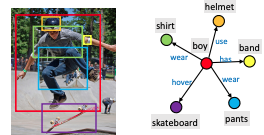
scene graphとは,図のように画像中のオブジェクトを検出し,検出されたオブジェクト同士の位置関係およびオブジェクト同士の意味的な関係(use, wearなど)をグラフで表現したものです.スケートボードに乗っている男性の写真から,男性を取り巻く様々な物体(skateboard, pants, shirts等)をノードとして,それぞれの位置関係をエッジとして記述しています.
画像の中から物体同士の関係を記述することができるscene graph生成はVQAだけではなくキャプショニングなどCVとNLPをつなげる様々なタスクに応用することができます.
手法
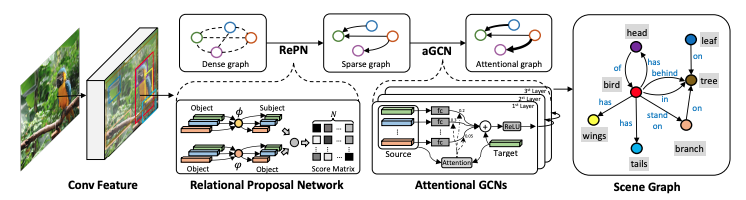
提案手法の流れとしては.
- Mask RCNNによりBounding box検出
- Relation proposal networkによりBounding box同士の組み合わせを抽出
- attentional GCNにより抽出された組み合わせをリファインする
です.このうち主要なcontributionは,2および3になります.
1. maskRCNNによる物体検出
mask RCNNにより物体検出を行います.これによりBounding boxの大きさ,位置情報,クラス情報が推定されます.
2. Relation proposal networkによる組み合わせ抽出
本論文の一つ目のcontributionです.RCNNにおけるrelgion proposal network(RePN)の如くrelation proposal network(RelPN)を設けました.Bounding boxの各組み合わせごとに関係性のラベルを推定するのは大変なので,二つのBounding boxのクラスロジット$p_i, p_j$に対して関係性ラベル$f(p_i, p_j)$を,
$f(p_i, p_j) = \phi(p_i)\cdot\psi(p_j)$
と計算しています.ここで$\phi(), \psi()$は二層パーセプトロンです.
つまり,関係性ラベルを二つの物体の特徴量の掛け合わせで推定するようにしたということですね.
また,ここで物体ペアをスコアが高かった順にK個の候補に絞っています.
3. attentional Graph Convolutionによるグラフ構造の決定
本論文の二つ目のcontributionです.グラフ畳み込みにアテンション構造を付与しました.
通常のグラフ畳み込みでは,ノード$z_i$の畳み込みは接続行列$\alpha$を用いて
$z_i^{l+1}=sigmoid(z_i^l + \sum_{j}\alpha_{ij}Wz_j^l)$
となります.Wは重みです.ここで,接続行列の各要素は0か1をとり,0ならiとjは繋がっていない・1なら繋がっているという具合です.
一方,提案手法のアテンション付きグラフ畳み込みでは,この接続行列の値を0から1の実数値となるようにします.具体的には学習する重み$W_a, w_h$を用い,
$\alpha_{ij}=softmax(w_h^Tsigmoid(W_a[z_i^l, z_j^l]))$
として学習します.[・,・]は結合です.
このほかにも論文では生成したscene graphに対する新しい評価指標(SGGen+)なども提案していました.
コードを回してみる
実装はgithub上に丁寧な解説付きで乗っていますが,一通りの流れを載せておきます
1. データセットの準備
cloneしてrequirementを入れたのち,データセットをダウンロードします.データセットはvisual genomeを使用します.ダウンロードのために,このページに飛び,
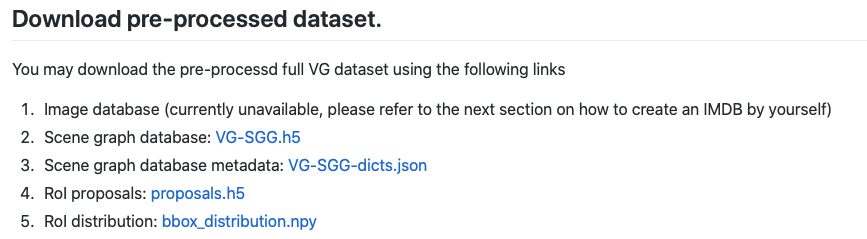
1~5をダウンロードします.ここで,1はまだ用意されていないとのことなので,その下にある
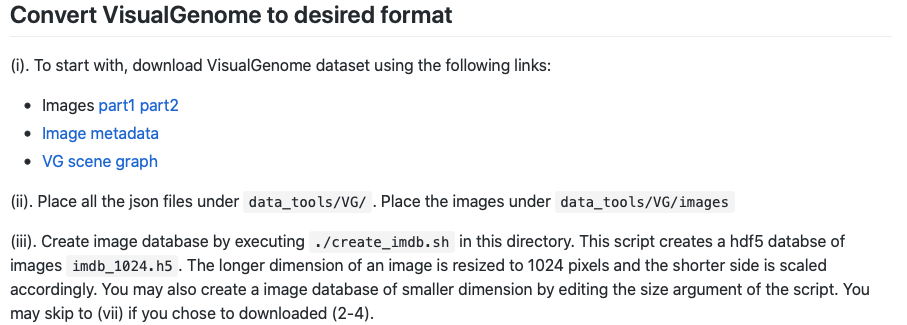
この手順を踏みます.スクリプトをダウンロードして実行する必要がありますが,リポジトリ全体をcloneする必要はありません.ただし,このスクリプトはpython2系で動いているようなので,pythonのバージョンだけここで切り替える必要があります.
これらの手順で,data下に
data/vg/imdb_1024.h5
data/vg/bbox_distribution.npy
data/vg/proposals.h5
data/vg/VG-SGG-dicts.json
data/vg/VG-SGG.h5
を用意できれば準備完了です.
2.モデルの訓練
次に,コードを実行します.まず物体検出モデルを訓練し,次にグラフ生成モデルを訓練します.(両者を一括でできる"train scene graph generation model jointly"の方はエラーで動きませんでした)
python main.py --config-file configs/faster_rcnn_res101.yaml
python main.py --config-file configs/sgg_res101_step.yaml --algorithm 試したいアルゴリズム名
3.モデルの検証
モデルの検証は以下のコードで行います.--visualizeオプションで推論結果を可視化できます.
python main.py --config-file configs/sgg_res101_step.yaml --inference --visualize
4.結果
3のテストコードを回すとこのような結果が表示されます.
020-03-02 05:05:03,016 scene_graph_generation.inference INFO: ===================sgdet(motif)=========================
2020-03-02 05:05:03,017 scene_graph_generation.inference INFO: sgdet-recall@20: 0.0300
2020-03-02 05:05:03,018 scene_graph_generation.inference INFO: sgdet-recall@50: 0.0563
2020-03-02 05:05:03,019 scene_graph_generation.inference INFO: sgdet-recall@100: 0.0699
2020-03-02 05:05:03,019 scene_graph_generation.inference INFO: =====================sgdet(IMP)=========================
2020-03-02 05:05:03,020 scene_graph_generation.inference INFO: sgdet-recall@20: 0.03372315977691639
2020-03-02 05:05:03,021 scene_graph_generation.inference INFO: sgdet-recall@50: 0.06264976651796783
2020-03-02 05:05:03,022 scene_graph_generation.inference INFO: sgdet-recall@100: 0.07724741486207399
また,--visualizeするとこのような写真が./visualize下に生成されます.

可視化...?
ですが,上の図では物体検出の結果だけで肝心のscene graphを可視化できていないと思いませんか?
なので,シーングラフを可視化できるpythonスクリプトを追加しました(こちら).
上の画像に対するscene graphの可視化結果が以下の通りです.
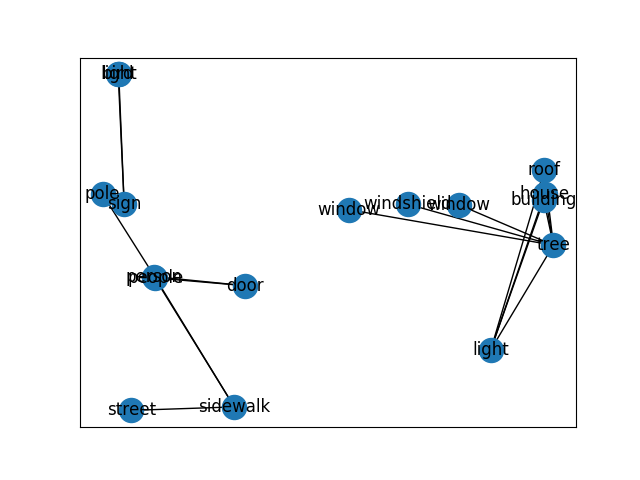
近くにある物体同士の関係がうまく抽出できていますね!エッジにも関係性ラベルを反映できるようにしたいです.
結論
画像からシーングラフを生成するGraph R-CNN for Scene Graph Generationの解説でした.興味深いタスク&実装の説明が親切なので,ぜひ試してみてください!