はじめに
こんにちは。ARISEでデータ基盤構築業務を主に行う「データアーキテクト」というキャリアトラックに所属しているエンジニアの田畑です。先日当社のテックブログの記事でも触れましたが、現在私はSnowflakeでの大規模データ基盤構築に携わっています。
そのプロジェクトにおいて、データ基盤のインフラ面における品質担保の負担軽減を図るべく、自動テストを導入しました。今回はその経緯や実装概要、今後の展望を共有したいと思います。
前提
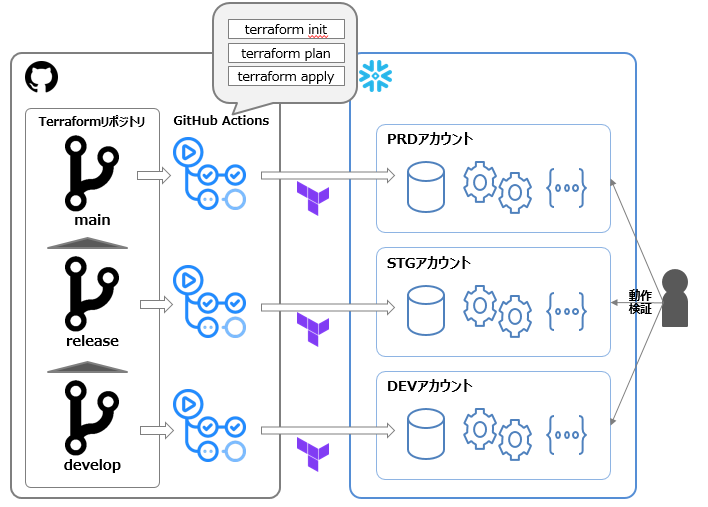
- SnowflakeはPRD, STG, DEVの3面構成(アカウントレベルで分離)
- Snowflakeのオブジェクトは基本Terraformで管理
- TerraformコードのリポジトリはGitHubで管理
- リポジトリはGit-flowで開発
- 各環境に対応するブランチに対してPR作成をするとterraform plan, マージをするとterraform applyされるよう、GitHub Actionsを用いてCI/CDを構成
- terraform applyを実施後、実際にSnowsightにて対象環境にアクセスし、アクセス制御などの各種挙動を確認する
なぜ自動テストを導入することになったのか
自動テストを導入することに決めた理由は大きく2つです。
手作業でのテストがつらい
先述したように、今回の実装対象であるデータ基盤は大規模なものであり、試験対象のリソースは大量です。これを全て手作業で行うと、確認するだけで大きな工数が発生します。加えて、商用環境においては、個人情報を取り扱う関係で、セキュリティ上の理由から、オフィス内の特定の区画からのアクセスが必要だったり、特定端末を用いての操作が必要だったり、特定のメンバーでないと操作ができなかったりなど、手作業のハードルが高くなります。こういった理由から手作業でのテストのつらさはチームの課題となっていました。
Snowflake向けのTerraformプロバイダのバージョンアップが控えていた
Terraformには、プロバイダとよばれる、クラウドプロバイダやSaaSプロバイダ、その他のAPIとやり取りするために利用するプラグインが存在します。それが提供されているため、様々なクラウドやSaaSのTerraform実装が楽になっている側面があるのですが、他のプログラムにおけるライブラリやプラグイン同様、アクセス先のバージョンアップなどに応じて、このプラグインもバージョンアップをする必要が生じます。実際、本件の検討タイミングでは、Snowflake向けのTerraformプロバイダのバージョンアップをしないと発生する不具合や不便に悩まされていました。一方で、プロバイダの最新版には、Snowflakeで非常に重要な概念であるアクセス制御を行う設定部分について、破壊的変更が入っていたため、大きなコード修正と、修正後の綿密かつ大量の動作検証が必要があることも見えていました。そのため、既存の手作業での動作検証では心許ないと感じていました。
上記2点の理由を踏まえて、我々は自動テストを導入することに決めました。
なぜpytestを選んだのか
では自動テストを導入するにあたって、なぜpytestを選んだのか。こちらについても大きく2つの理由があります。
PythonとSnowflakeの親和性が高い
Snowflakeに接続してすべての標準操作を実行できる、Pythonアプリケーションを開発するための公式のインターフェイスが提供されています。またPythonコードで他のライブラリで利用するようなデータフレームのインターフェースでコーディングし、実処理をSnowflakeの計算資源で実行可能なSnowparkというライブラリも利用可能です。加えて、Snowflake公式ブログにもpytest x Snowflakeの利用事例があったことなどから、PythonとSnowflakeの親和性があることがうかがえたのは理由の1つです。
チームメンバーのスキルマッチ
チームメンバーにPythonおよびpytestの商用利用経験があるメンバーがいたことも大きいです。品質担保という面でプロダクトに価値は出すものの、触ったことのない技術でテストコード実装に時間をかけすぎてしまうと本末転倒になってしまうので、ある程度慣れた技術であることは重要なファクターでした。
どのように実装したのか
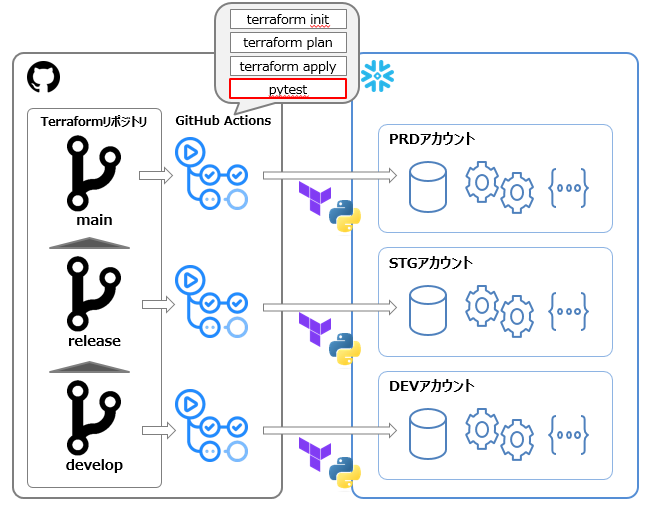
インフラ構成
まずはインフラ面ですが、先述したGitHub ActionsのCI/CDにpytestを実行するステップを追加する形で実装しました。各環境でterraformを実行し、Snowflake上でオブジェクトが構築された状態でpytestを実行する形です。
テストコード
続いて実際のテストコードです。
テスト実行に向けたログイン処理
まずはSnowflakeでの動作確認を行うために事前準備として必要不可欠なログイン処理ですが、こちらはセッションスコープのfixtureで定義しました。
fixtureというのはpytestの機能の1つで、テストにおける事前処理/事後処理を定義できるものです。それらをどの単位で実施するかは先述したスコープという形で設定が可能です。
先ほどのログイン処理はセッションスコープなので1セッションで1度、つまりpytestコマンド実行につき1度だけ実行される事前/事後処理になります。
加えて、各単体テストを実行する際に、適切なロールに切り替えるのですが、その際に切り替え漏れによるテストの不備が発生しないよう、毎度PUBLICロールに戻す処理を実行したいなと考えました。その処理も、テスト関数のスコープのfixtureとして実装しました。これにより、各単体テストごとに、この事前処理が行われるかたちになります。
@pytest.fixture(scope="session")
def _sf_con():
# Snowflakeへの接続のセットアップ
connection = connect(
user=os.getenv("SNOWFLAKE_USER"),
password=os.getenv("SNOWFLAKE_PASSWORD"),
account=f'{os.getenv("SNOWFLAKE_ACCOUNT")}.ap-northeast-1.aws',
session_parameters={
"QUERY_TAG": "PYTEST",
},
)
# 接続オブジェクトを返す
yield connection
# クリーンアップ
connection.close()
@pytest.fixture(scope="function")
def sf_con(_sf_con):
_sf_con.cursor().execute(f"USE ROLE public;")
return _sf_con
アクセス権限設定確認
現時点でpytestでテスト対象としているのは主にアクセス制御周りになっています。
そのテスト方法は更に2つに大別されます。機能ロールベースのテストとアクセスロールベースのテストです。
機能ロールベース
テーブルに対してのSELECTや、ウェアハウスに対してのUSEなど、テストで実行してもデータへの変更などの副作用が発生しえないものについては、機能ロールベースで実行して動作確認を行う形にしています。
なお、こちらは両者共通の実装ですが、parametrizeデコレータを利用することで、同一テストケースを、異なる複数のパラメータで実行しています。
@pytest.mark.parametrize(
"database, schema, role",
[
("A_DB", "A_1_SCHEMA", "A_1_FUNC_ROLE"),
("A_DB", "A_2_SCHEMA", "A_2_FUNC_ROLE"),
("B_DB", "B_1_SCHEMA", "B_1_FUNC_ROLE"),
],
)
def test_views_normal_select(database, schema, role, sf_con):
"""機能ロールによるビューのアクセステスト 正常系(SELECT)"""
with sf_con.cursor() as cursor:
cursor.execute(f"USE ROLE {role};")
cursor.execute(f"USE WAREHOUSE {FUNC_ROLE_WAREHOUSE_MAP[role]};")
cursor.execute(f"USE DATABASE {database};")
cursor.execute(f"USE SCHEMA {schema};")
rows = sf_con.cursor(DictCursor).execute("SHOW VIEWS;")
# SHOW VIEWSで想定される行数が返ってくることを確認
assert rows.rowcount == SCHEMA_VIEW_COUNTS[database][schema]
for row in rows:
cursor.execute(f"SELECT 'TEST' FROM \"{row['name']}\" LIMIT 1")
アクセスロールベース
我々が実装している基盤では、定期的な処理を実装するためのSnowflakeタスクや、データをロードするうえで引数を渡して数ステップの操作を行うストアドプロシージャなども実装しています。こちらのテストも実装が必要となるのですが、これらは実際にEXECUTEやCALLなどをすると、データに影響が出てしまいます。ダミーのテーブルなどを一時的に用意するなどの方法もあったのですが、よりシンプルな方法で実行するべく、SHOW GRANTS文でアクセスロールへ権限が付与されていることの確認 + アクセスロールが正しく機能ロールに継承されていることの確認 を行うことで、機能ロールに正しく権限が付与されていることを確認する方法を取りました。
@pytest.mark.parametrize(
"database, schema, privilege, access_role",
[
("TEST_DB", "TEST_SCHEMA", "MONITOR", "A_ACCESS_ROLE"),
("TEST_DB", "TEST_SCHEMA", "OPERATE", "B_ACCESS_ROLE"),
],
)
def test_task_privilege(database, schema, privilege, access_role, sf_con):
with sf_con.cursor(DictCursor) as cursor:
role = "ADMIN_ROLE"
cursor.execute(f"USE ROLE {role};")
cursor.execute(f"USE WAREHOUSE {FUNC_ROLE_WAREHOUSE_MAP[role]};")
cursor.execute(f"USE DATABASE {database}")
cursor.execute(f"USE SCHEMA {schema}")
# future grantsが設定されていることを確認
cursor.execute(f"SHOW FUTURE GRANTS IN SCHEMA {database}.{schema}")
future_grants_result = cursor.execute(
f"""
SELECT * FROM TABLE(result_scan('{cursor.sfqid}'))
WHERE \"grant_on\" = 'TASK' AND
\"privilege\" = '{privilege}'
AND \"grantee_name\" = '{access_role}';
"""
)
assert future_grants_result.rowcount == 1
rows = list(cursor.execute("SHOW TASKS"))
assert len(rows) == SCHEMA_TASK_COUNTS[database][schema]
for row in rows:
cursor.execute(f"SHOW GRANTS ON TASK {row['name']}")
result = cursor.execute(
f"""
SELECT * FROM TABLE(result_scan('{cursor.sfqid}'))
WHERE \"privilege\" = '{privilege}' AND \"grantee_name\" = '{access_role}';
"""
)
assert result.rowcount == 1
@pytest.mark.parametrize(
"role, grantee_roles",
[
("A_ACCESS_ROLE", ["A_1_FUNC_ROLE", "A_2_FUNC_ROLE"]),
("B_ACCESS_ROLE", ["B_1_FUNC_ROLE", "B_2_FUNC_ROLE"]),
],
)
def test_grants_access_role_to_func_role(role, grantee_roles, sf_con):
""" アクセスロールが然るべき機能ロールに付与されていることを確認するテスト
"""
with sf_con.cursor(DictCursor) as cursor:
exec_role = "ADMIN_ROLE" # 各リソースの所有者など強い権限を持つロール
cursor.execute(f"USE ROLE {exec_role};")
cursor.execute(f"USE WAREHOUSE {FUNC_ROLE_WAREHOUSE_MAP[exec_role]};")
results = cursor.execute(f"SHOW GRANTS OF ROLE {role}")
assert results.rowcount == len(grantee_roles)
show_grants_query_id = cursor.sfqid
for grantee_role in grantee_roles:
result = cursor.execute(
f"""
SELECT * FROM TABLE(result_scan('{show_grants_query_id}'))
WHERE \"grantee_name\" = '{grantee_role}';
"""
)
assert result.rowcount == 1
実装後どうなったか/今後どうしていきたいか
このPytest導入について、現在のプロジェクトチームでも活用しているKPTのフレームベースで振り返りました。
Keep
手作業工数の大幅削減!
当初課題として感じていた、大量のテスト作業が無くなり、他作業に充てる時間の増加による生産性向上 & 退屈な作業からの解放により開発者の開発体験向上 につながりました。
デグレ無しでTerraformプロバイダバージョンアップ完遂!(約200のGRANT設定変更)
もう1つの当初課題としてあげていたTerraformプロバイダバージョンアップについても、約200のGRANT設定変更を含むものでありながら、自動テストを実行しながら対応することで、不安を感じることなく、デグレ無しで完遂しました。
Problem
テストコードに実装不備があると、バグを見逃してしまう
当たり前ですが、テストコード自体に不備があると、実装のバグを見逃してしまう可能性があります。テスト観点の整理と、それに対応するテストの実装については、手作業でのテスト以上に注意を払う必要があるかと思います。
テストコードの実行時間が長い
先述したように我々が扱っているデータ基盤は大量のSnowflakeオブジェクトを取り扱っています。それゆえに自動テストを導入しているとはいえ、実行にはかなりの時間がかかっている状態です(もちろん手作業よりは所要時間は短いですし、その間に他のタスクを進めることができるので、手作業対比状況は改善していますが、、)。
Try
テスト対象/タイミング/方法のブラッシュアップ
現状は、修正範囲に関わらず、これまで実装してきたテストを全て実行しています。一方で、修正範囲によっては実行する必要がないテストもあるので、そこを最適化し、テスト時間を短縮する余地はまだあるので、その点は進めていきたいと考えています。
pytestの並列数増加
pytestの実行時間短縮において、最もポピュラーな方法はpytest-xdistを用いたpytestの並列化かなと思うので、その点も進めていきたいと考えています。一方で、この並列実行数はコア数に依存するのですが、現在我々のプロジェクトのGitHub Actionsでは、諸般の事情でセルフホステッドランナーを利用しており、かつ最小のインスタンスで実装しているので、そこの構成変更から対応が必要になります、、
おわりに
以上が、Snowflake x terraformでのデータ基盤実装に自動テストを導入した経緯や取組概要、今後の展望でした。
もちろんリリースサイクルなどプロジェクトの特性によって異なる部分はあると思いますが、自動テストは、時間を生み出すだけでなく、手作業でのミスの削減や退屈な作業の撲滅による開発体験の向上など、数多くのメリットを持っているので、導入のメリットは十分にあると思います。もし日々の大量の手作業での動作確認などにお悩みでしたら、自動テストの導入をご検討されてみてはいかがでしょうか?
本記事の内容がどなたかのお役に立てれば幸いです。