概要
今月(2022年12月)行われた某サッカー大会の日本対クロアチア戦についてのツイートを、Delta Live Tablesを使ってリアルタイムで分析してDatabricks SQLのダッシュボードで可視化しました。
Delta Live Tablesとは
Delta Live Tables(以下、DLT)とは、databricksのETLの管理ツールです。品質管理やモニタリングの機能がついており、バッチ処理にもストリーミング処理にも対応しています。
処理の流れ
- 試合時間中に、日本代表戦に関するツイートをTwitterのfiltered streamからストリーミングで取得
- 日本語のNLPライブラリGiNZAを使ってツイートから人名(Person)を抽出
- 日本代表選手名のテーブルとjoinして、日本代表選手に関するツイートのみをフィルタリング
- 各選手について、その時間帯にいくつツイートされたかを集計(ウィンドウ時間5分)
- Databricks SQLダッシュボードで、選手ごとのツイート数、ワードクラウド等を可視化
DLTでの処理の概要
以下は、DLTを連続(Continuous)実行モードで動作させた時のDLTの画面の様子です。ストリーミングで入力されるツイートの情報をスタートとして、各Live Tableの間で連続的にデータが連携されます。

Databricks SQLでの可視化
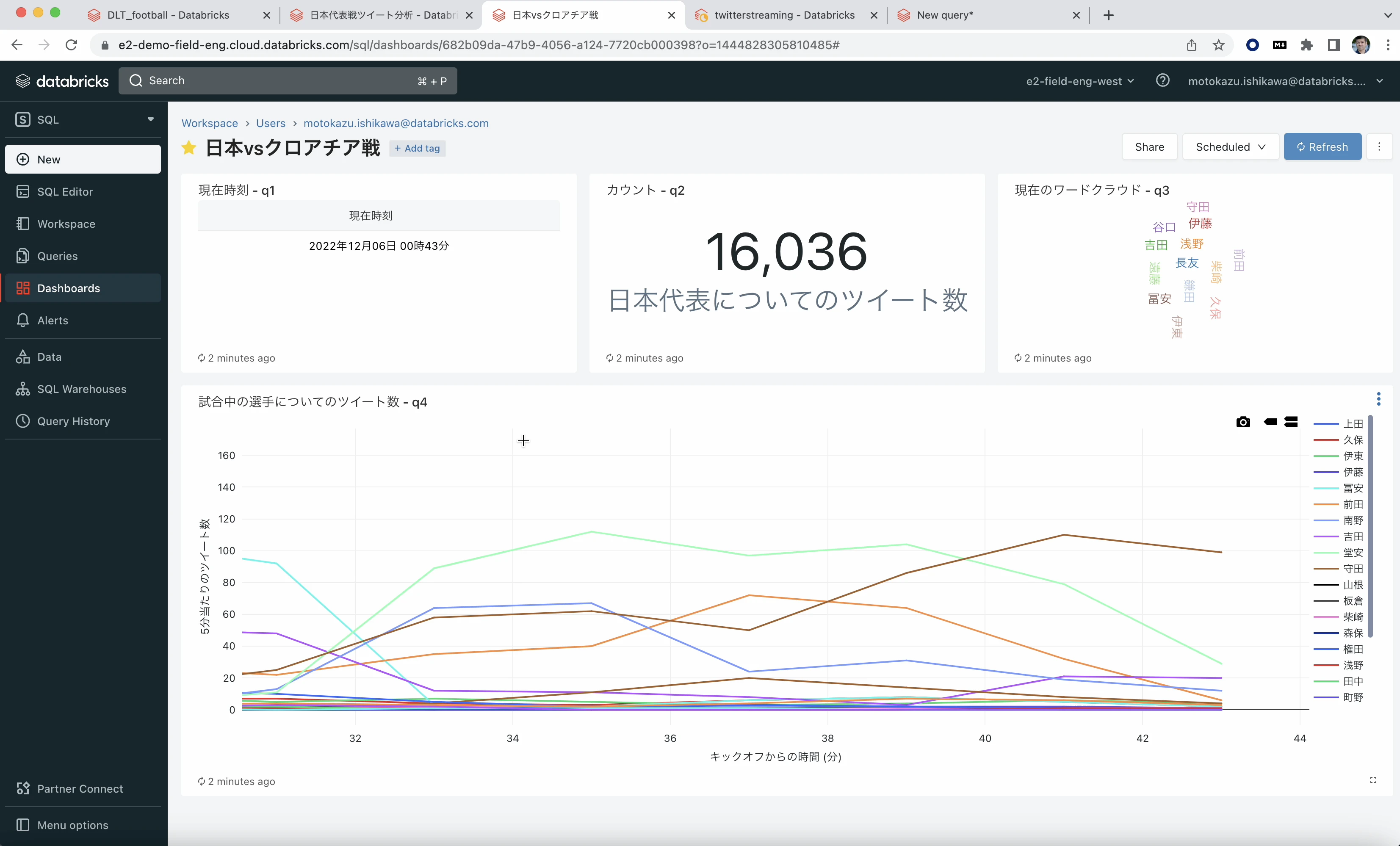
ダッシュボードでの結果の可視化。下部にはキックオフからの時間ごとに選手についてのツイート数を折れ線グラフで表示。右上にはツイートされた選手のワードクラウド。
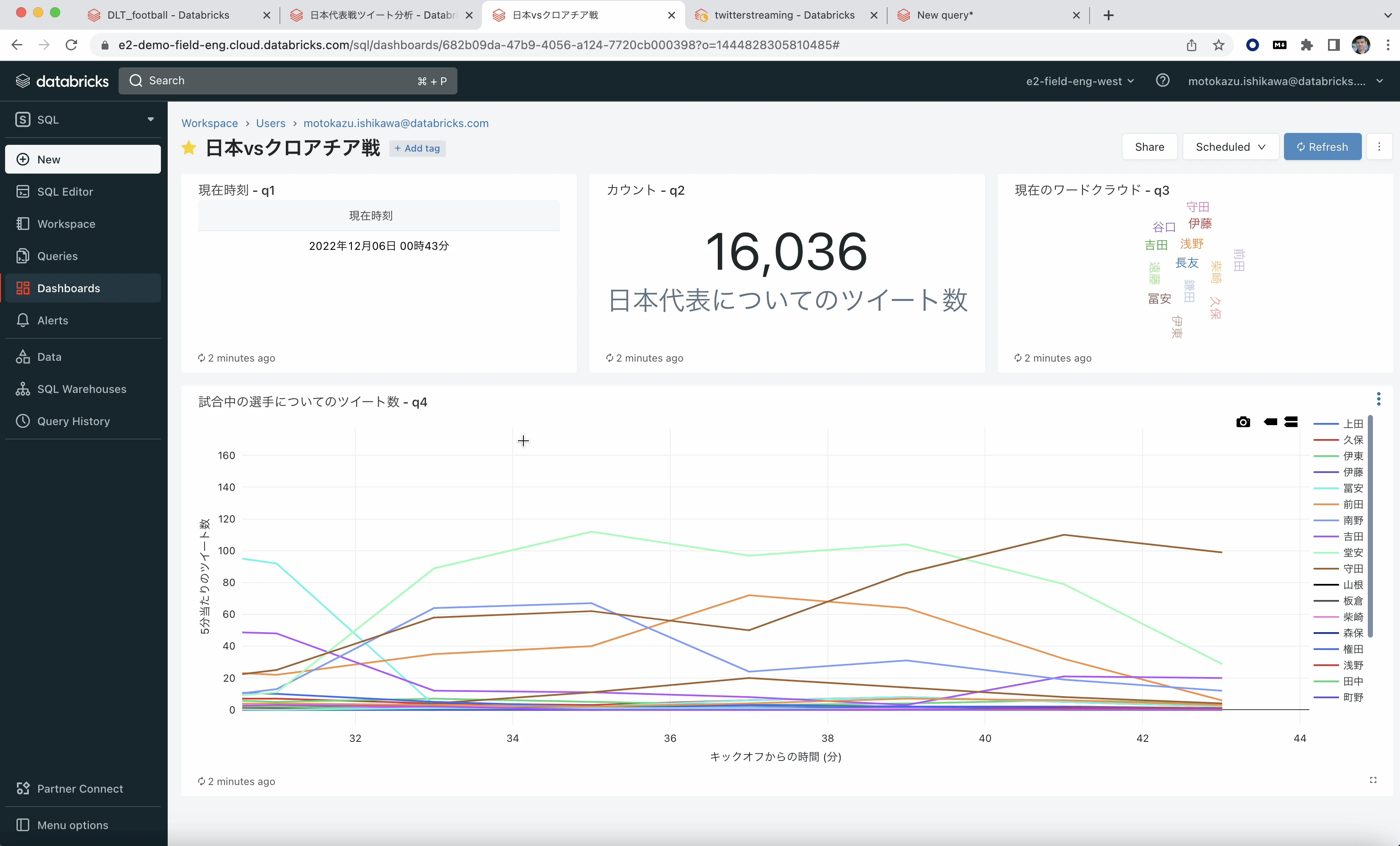
前半最後に前田選手がゴール⚽️した直後には前田選手に関するツイートが突発的に増えて、ワードクラウドも前田選手一色!ブラボー!
アーキテクチャと処理のフロー
アーキテクチャはこのようになっています。以下、各要素と、DLT内でのデータ処理を順を追って説明します。

1. Twitter APIから日本対クロアチア戦のツイートをストリーミングで取得
twitterのfiltered streamingを操作するためにtweepyを活用しました。filtered streamingでは、あらかじめルールを設定することで、twitterからそのルールに沿ったツイートを取得できます。詳細は割愛しますが、サッカー日本代表に関するハッシュタグ複数をルールとして設定しました。(APIから取得できるツイート数の上限に引っかからないようにかなり限定したハッシュタグを使いました。)取得したツイートをツイートごとに1つのJSONとしてS3にPUTします。
2. Auto LoaderでJSONファイルをDLTに取り込む
Auto Loaderの機能を使うことで、s3に追加されたJSONファイルを自動でDLTに取り込むことができます。
参考) Delta Live TablesでAuto Loaderを使う
import dlt
from pyspark.sql.types import *
from pyspark.sql.functions import current_timestamp, explode, get_json_object, split, udf, col
from pyspark.sql import functions as f
@dlt.table
@dlt.expect_or_drop("Valid_tweet", "text IS NOT NULL")
def tweet():
return (
spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("/user/motokazu.ishikawa@databricks.com/tweet/")
.withColumn( "text", get_json_object( "data", "$.text").alias("text") )
.withColumn( "id", get_json_object( "data", "$.id").alias("id") )
.withColumn( "timestamp", current_timestamp() )
.drop("data")
)
3. 自然言語処理でツイートから人名を抽出
日本語のNLPライブラリGiNZAを使ってツイートから人名(Person)を抽出します。このライブラリがSparkクラスターで分散処理されるように、ライブラリを使う関数をUDFとして定義して利用しました。
from pyspark.sql.functions import length
import spacy
nlp = spacy.load("ja_ginza")
@udf
def get_ner(s):
for ent in nlp(s).ents:
if ent.label_ == 'Person':
return ent.text
return ""
@dlt.table
def tweeted_person():
return ( dlt.read_stream("tweet")
.withColumn( "person", get_ner( f.col("text") ) )
.filter( length("person") != 0 ) )
4. 日本代表選手のみを抽出
ツイートには、選手以外の人名も含まれているので、日本代表選手のみを抽出することが必要になります。あらかじめplayer_nameというLive Tableに日本選手のリストを登録しておいて、これと選手名をキーにしてInner Joinすることで、日本代表選手に関するツイートのみを抽出しました。
@dlt.table
def tweeted_player():
df_tweeted_person = dlt.read_stream("tweeted_person").drop("matching_rules")
df_player_name = dlt.read("player_name")
return ( df_tweeted_person
.join( df_player_name, df_tweeted_person.person == df_player_name.name_alias )
.drop( "text", "name_alias" ) )
5. 各選手について、その時間帯にいくつツイートされたかを集計
各選手が、5分間のウィンドウ内で何回ツイートされたかを以下の処理で集計します。前後の5分間のウィンドウは2分間ずつオーバーラップしています。
参考) Spark構造化ストリーミングにおけるセッションウィンドウのネイティブサポート
from pyspark.sql.functions import window
@dlt.table
def player_count():
return ( dlt.read_stream("tweeted_player")
.withWatermark("timestamp", "10 minutes")
.groupBy( window( "timestamp", "5 minutes", "2 minutes"), "name_canonical" )
.count())
6. Databricks SQLダッシュボードで、選手ごとのツイート数、ワードクラウド等を可視化
Databricks SQLはSQLを使いデータ分析をすることができる機能です。
データ分析のクエリーをDatabricks SQLのダッシュボードを使ってグラフなどを使い可視化することができます。集計結果などのDLTの結果をダッシュボードを使って可視化しました。あらかじめ設定した時間ごとに定期的にダッシュボードのデータを更新することも可能です。
最後に
- 今回使ったDLTのノートブックはgithubから利用可能です。