Automating PHI Removal from Healthcare Data With Natural Language Processingの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
保護対象保健情報の非識別化と難読化を大規模に実現可能なDatabricksとJohn Snow Labのソリューションアクセラレータのご紹介
医療研究における必要最小限方針と保護対象保健情報
HIPPA(医療保険の携行性と責任に関する法律)では、HIPPAの対象となる(医療機関、保険会社等の)機関は、保護対象保健情報(PHI, Protected Health Information)へのアクセスは、特定の使用、開示または要求の意図した目的を達成するために必要最小限なものに留めるように合理的な努力をすることが求められています。
ヨーロッパでは、GDPRにより、企業が医療データを分析、共有するためには匿名化や仮名化をしなければならないことが定められています。いくつかのケースでは、企業は性別、人種、宗教、労働組合への加入状況を黒塗りすることが求められている点でアメリカの規制より厳しくなっています。ほぼ全ての国で、機微個人情報や医療情報についての法的規制が存在しています。
個人識別可能な医療情報の取り扱いにおける課題
これらの必要最小限方針は、集団レベルの医学研究を進める際の障害となり得ます。なぜなら、医療データにおける値の多くは準構造化の説明文と非構造化の画像中にあり、これらはしばしば除去が困難な個人識別可能医療情報を含んでいるからです。これらの保護対象保健情報は、医療従事者、研究者やデータサイエンティストが、たとえば疾患の進行を予知するようなモデルの注釈、トレーニング、開発をすることを困難にします。
コンプライアンスの理由以外にも、保護対象保健情報や医療データの匿名化をする規制以外の主な理由(とりわけデータサイエンスのプロジェクトにとって)は、データバイアスと、偽の相関関係から学習することを避けることができるというものです。患者の住所、苗字、人種、職業、病院名や医師名などのデータフィールドを除去することにより、機械学習のアルゴリズムが予測や提案をする際にこれらのフィールドに頼ることを回避することができます。
DatabricksとJohn Snow Labsを使った、保護対象保健情報の自動除去
医療業界における自然言語処理のリーダーであるJohn Snow LabsとDatabricksは共同で、よくある自然言語処理のユースケースのためのソリューションアクセラレータのノートブックテンプレートシリーズを用意して、組織がテキストデータを処理、分析することをサポートしています。私たちのパートナーシップについてさらに知りたい方は、過去のブログ記事である, ヘルスケアにおける大規模テキストデータへの自然言語処理の適用をご覧ください。
組織が機微の患者情報を自動的に除去することを助けるため、私たちは保護対象保健情報の除去のための共同ソリューションアクセラレータを、ヘルスケアとライフサイエンスのためのDatabricks Lakehouse上で構築しました。John Snow Labsは、オープンソースのSpark NLPライブラリに追加可能な2つの商用の(両方とも非識別化と匿名化に有用な)拡張パッケージを提供しており、それらはアクセラレータに含まれます:
-
Spark NLP for Healthcareはヘルスケアとライフサイエンス業界で最も広く使われている自然言語処理のライブラリーです。Spark NLP for HealthcareはDatabricks上での実行に最適化されており、大規模な臨床とバイオメディカルテキストデータに対して最高水準の精度で継ぎ目ない抽出、分類、構造化が可能です。
-
Spark OCR は、ドキュメントの理解、帳票の理解と情報抽出といった各種画像処理のための実用レベルの学習可能で大規模に拡張可能なアルゴリズムとモデルを提供しています。デジタル文章の分析というコアライブラリの機能を拡張して、PDFやDOCX文書の読み書きに加え、これら文書に含まれる画像や、JPG、TIFF、DICOMや同様の画像フォーマットからテキストを抽出することができます。
私たちのソリューションアクセラレータについてのハイレベルなウォークスルーは以下になります。
保護対象保健情報の除去の実際
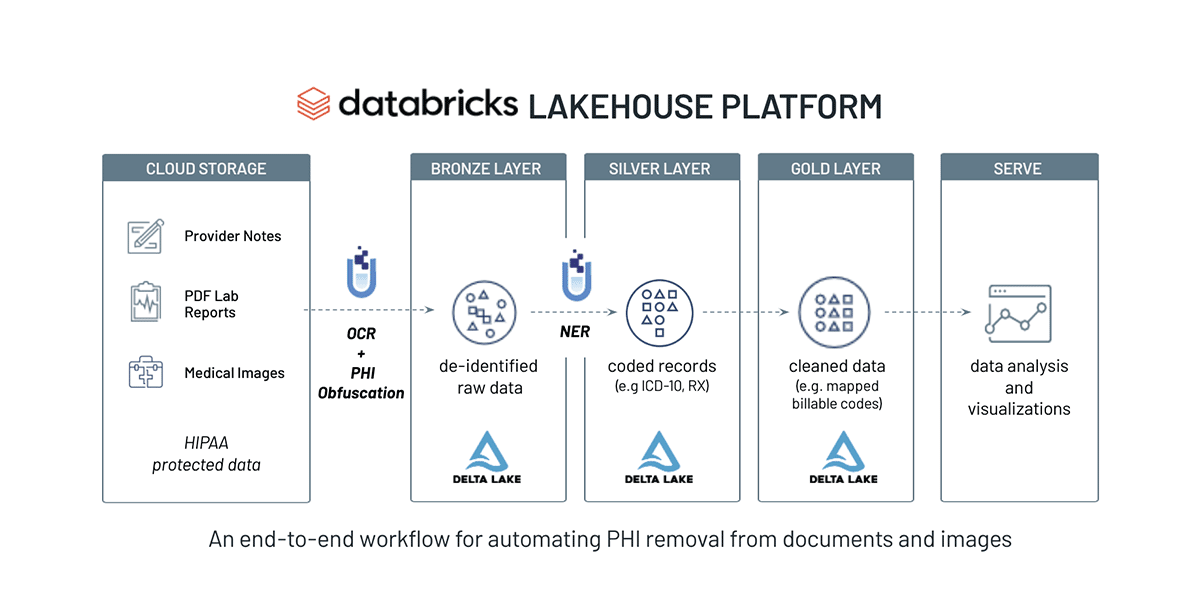
このソリューションアクセラレータでは、患者の識別情報を開示することなく医療文書を共有し分析するためにどのようにして医療文書から保護対象保健情報を除去するかをお示しします。以下が、ワークフローのハイレベルな概要です:
- PDF文書を処理するOCRパイプラインの構築
- 自然言語処理モデルを用いた非構造文書からの保護対象保健情報の検出と抽出
- 保護対象保健情報のテキストの難読化による非識別化
- 画像形式の文書中の保護対象保健情報の黒塗りによる非識別化
ノートブックにアクセスし、このソリューションの全てをウォークスルーできます。
OCRによるファイルの処理
最初のステップとして、クラウドストレージからPDFを取り込み、それぞれにユニークなIDを付け、生成されたデータフレームをLakehouseのブロンズレイヤーに格納します。生のPDFの中身は、バイナリー形式のカラムに格納されて後段のステップにてアクセスされることにご注意ください。

次のステップでは、それぞれのファイルから生のテキストを抽出します。PDFファイルは2ページ以上の可能性があるため、最初にそれぞれのページを(PdfToImage()を使って)画像に変換してから、ImageToText()をそれぞれの画像に適用することで画像からテキストを抽出するのが効率が良いです。
# ページごとにPDF文書を画像に変換する
pdf_to_image = PdfToImage()\
.setInputCol("content")\
.setOutputCol("image")
# OCRを実行する
ocr = ImageToText()\
.setInputCol("image")\
.setOutputCol("text")\
.setConfidenceThreshold(65)\
.setIgnoreResolution(False)
ocr_pipeline = PipelineModel(stages=[
pdf_to_image,
ocr
])
SparkNLPと同様に、他のSpark関連のトランスフォーマーに合わせて、Spark OCRにおいてもトランスフォームが標準化されたステップであり、1行のコードで実行可能です。
ocr_result_df = ocr_pipeline.transform(pdfs_df)
以下で示すように、ノートブック内において個別の画像を直接確認することが可能なことに注目してください:

このパイプラインを適用後、データフレームに、抽出されたテキストと生の画像を保存します。注目して欲しいのは、画像、抽出されたテキスト、元のPDFの間の関連性はクラウドストレージ中のPDFファイルへのパス(とユニークID)の形式で維持されることです。

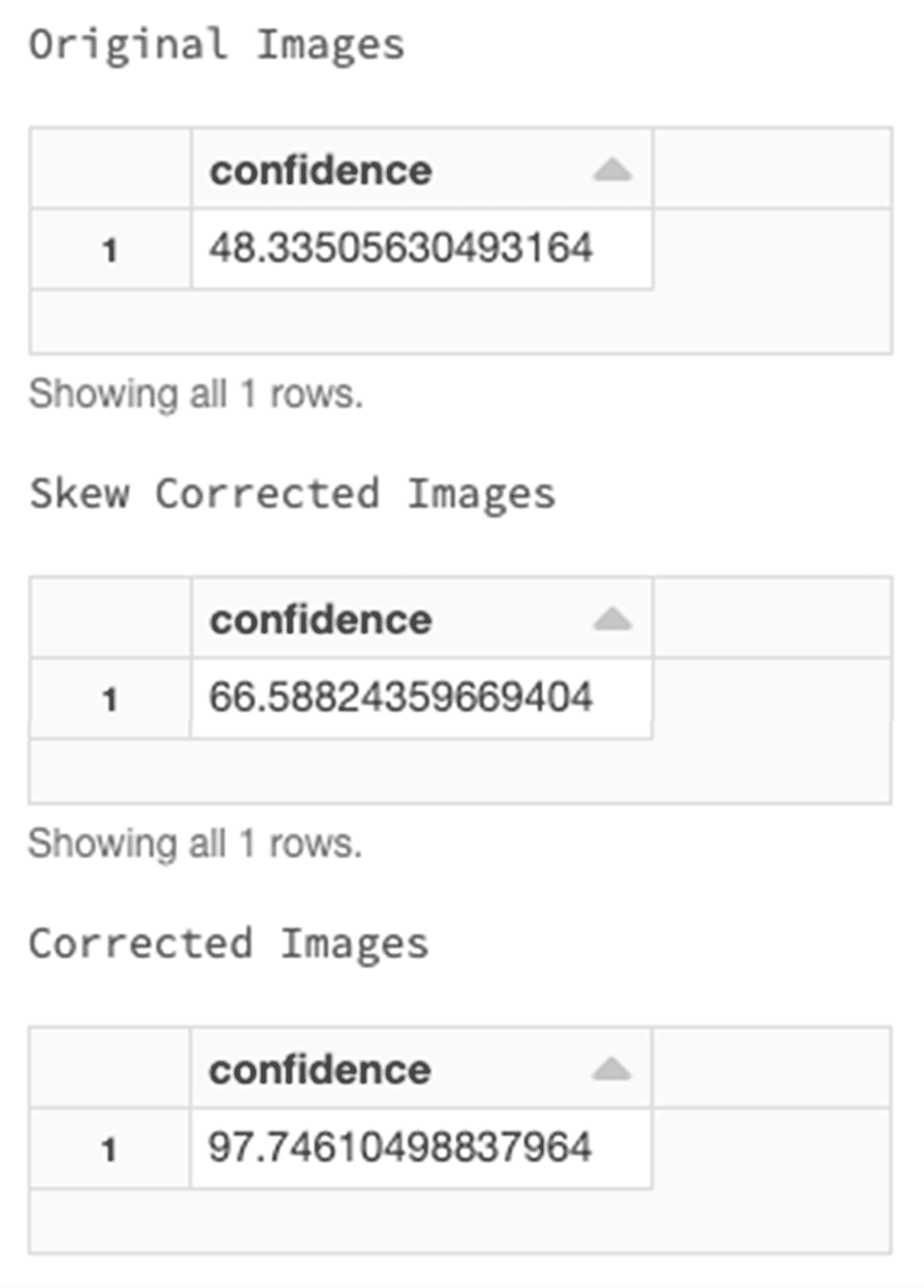
しばしば、スキャンされた文書は(画像の傾きや低解像度などにより)低品質であることから、不正確なテキストや低いデータ品質に陥ります。この問題に対応するため、SparkOCRに組み込まれた画像の前処理を実行して抽出テキストの品質を改善できます。
傾き訂正と画像処理
次のステップでは、信頼度を増すために画像を処理します。Spark OCRは画像の傾きを検出して回転するためのImageSkewCorrectorを持っています。このツールをOCRパイプラインに適用することで、画像を適切に調節する助けとなります。次に、ImageAdaptiveThresholdingというツールを同様に利用することで、近傍の局所的なピクセルに基づいて画像をマスクするための閾値を算出し、それを画像に適用することができます。パイプラインに加えたこれ以外の画像処理の手法は、形状処理の手法です。ImageMorphologyOperationを使うことで、削り取り(オブジェクト境界からのピクセル除去)、拡張(画像中のオブジェクト境界へのピクセル付加)、開放(画像中の大きなオブジェクトの形状と大きさを維持しての画像からの小型オブジェクトと細い線の除去)、閉鎖(開放の逆の操作で、画像中の小さな穴を埋めるのに有効)をサポートできます。
ImageRemoveObjectsを使った背景のオブジェクトの除去や、ImageLayoutAnalyzerをパイプラインに加えることにより画像を分析によるテキスト領域の判定も可能です。アクセラレータのノートブックには、完全版のOCRパイプラインのコードが含まれています。
元画像と、訂正後の画像をご覧ください。

画像処理後には、きれいになった画像と共に、97%という信頼度を得ることができました。
ここまでで、画像の傾きと背景のノイズを訂正し、画像から訂正されたテキストを抽出し、それにより得たデータフレームをDeltaのシルバーレイヤーに書き込みました。
保護対象保健情報エンティティの抽出と難読化
Spark OCRにより文書を処理し終えたあと、臨床の固有表現抽出(Named-Entity Recognition:NER)パイプラインを使って文書に含まれる(名前、誕生地などの)興味のあるエンティティを検出して抽出することができます。このプロセスは、研究レポートから腫瘍学についての知見を得るという過去のブログ投稿で詳細に説明しています。
しかしながら、臨床ノートには、個人を特定し(例えば病状などの)臨床のエンティティと関連づけるために用いる保護対象保健情報が含まれています。そのため、文書に含まれるそれら保護対象保健情報を特定し、これらのエンティティを難読化することは不可欠です。
プロセスは、保護対象保健情報エンティティの抽出、そしてそれを隠すという二段階のステップからなり、しかも出力となるデータセットが後段の分析に有用な情報を含むようになっています。
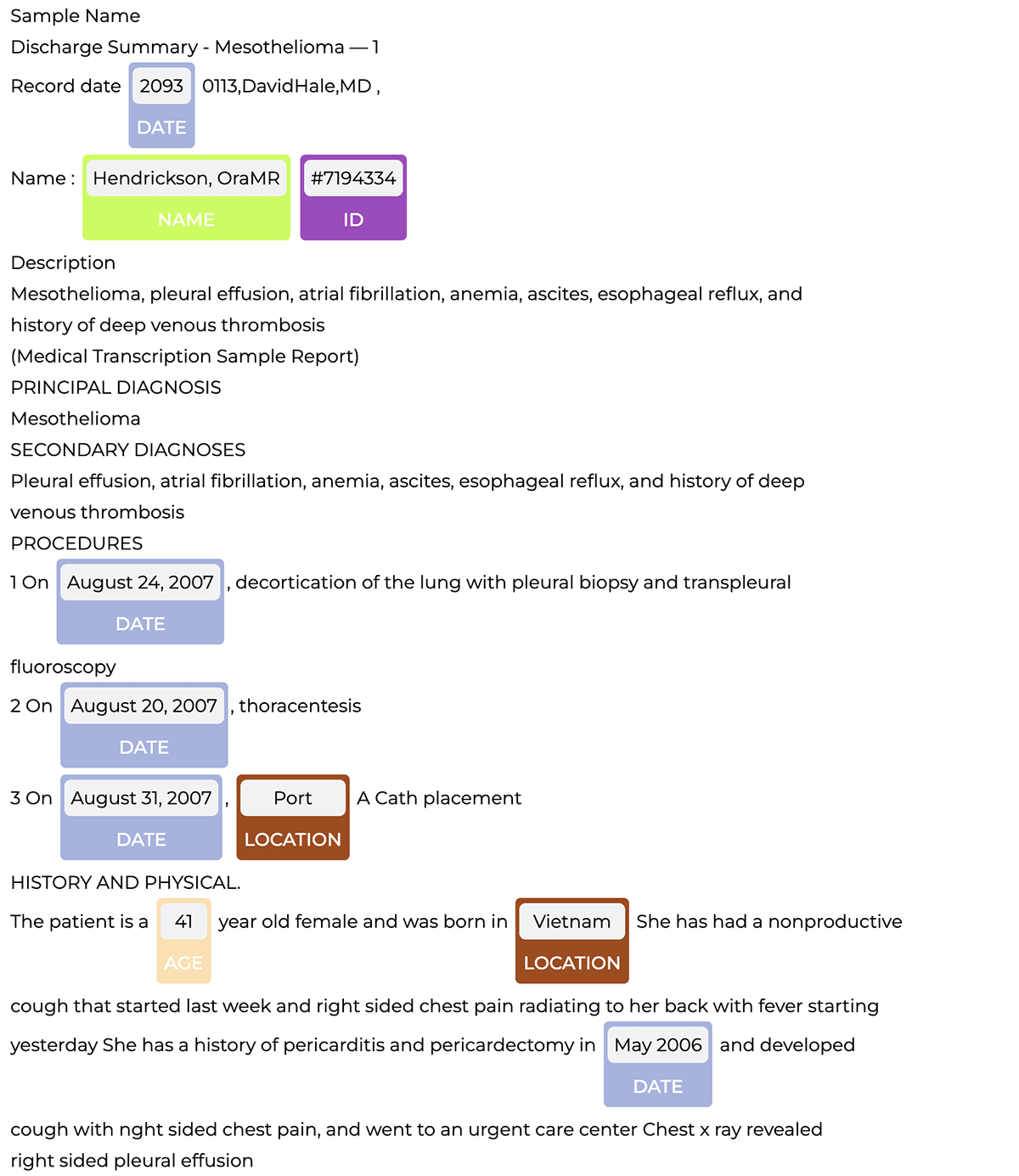
臨床の固有表現抽出と同様に、医療の固有表現抽出モデル(ner_deid_generic_augmented) により保護対象保健情報を検出し、「偽造手法」を用いてそれらのエンティティを難読化します。完全版の保護対象保健情報抽出パイプラインは、アクセラレータのノートブックに含まれています。
パイプラインは保護対象保健情報エンティティを検出し、それをNerVisualizerを用いて以下のように可視化します。
ここで、端から端まで非識別化パイプラインを完成させるため、保護対象保健情報を偽のデータに置換する保護対象保健情報パイプラインに、難読化のステップを追加します。
obfuscation = DeIdentification()\
.setInputCols (["sentence", "token", "ner_chunk"]) \
.setOutputCol("deidentified") \
.setMode("obfuscate")\
.setObfuscateRefSource("faker")\
.setObfuscateDate (True)
obfuscation_pipeline = Pipeline(stages=[
deid_pipeline,
obfuscation
])
以下の例では、患者の誕生地を黒塗りし、偽の地名に置き換えています:

難読化に加え、SparkNLP for Healthcareは黒塗りのための訓練済みモデルを提供します。以下は、黒塗りパイプラインの出力を示すスクリーンショットです。

PDF内の画像は保護対象保健情報エンティティを黒塗りするための黒線が加えられます。
SparkNLPとSpark OCRは保護対象保健情報の大規模な非識別化のために連携して動作します。多くのシナリオで、連邦政府や産業の規制により元のテキストファイルの配布や共有が禁じられています。デモでお見せしたように、PDF内のテキストを分類し、保護対象保健情報を難読化あるいは黒塗りし、その結果をLakehouseに出力する、大規模で自動化された実用的なパイプラインを作ることができます。データチームはこれらの整形されたデータと非識別化された情報を、患者のプライバシーをさらすことなく、後段の分析やデータサイエンティストやビジネスユーザーに快適に共有することができます。以下はDatabricksにおけるこのデータフローの概要を示す図です。
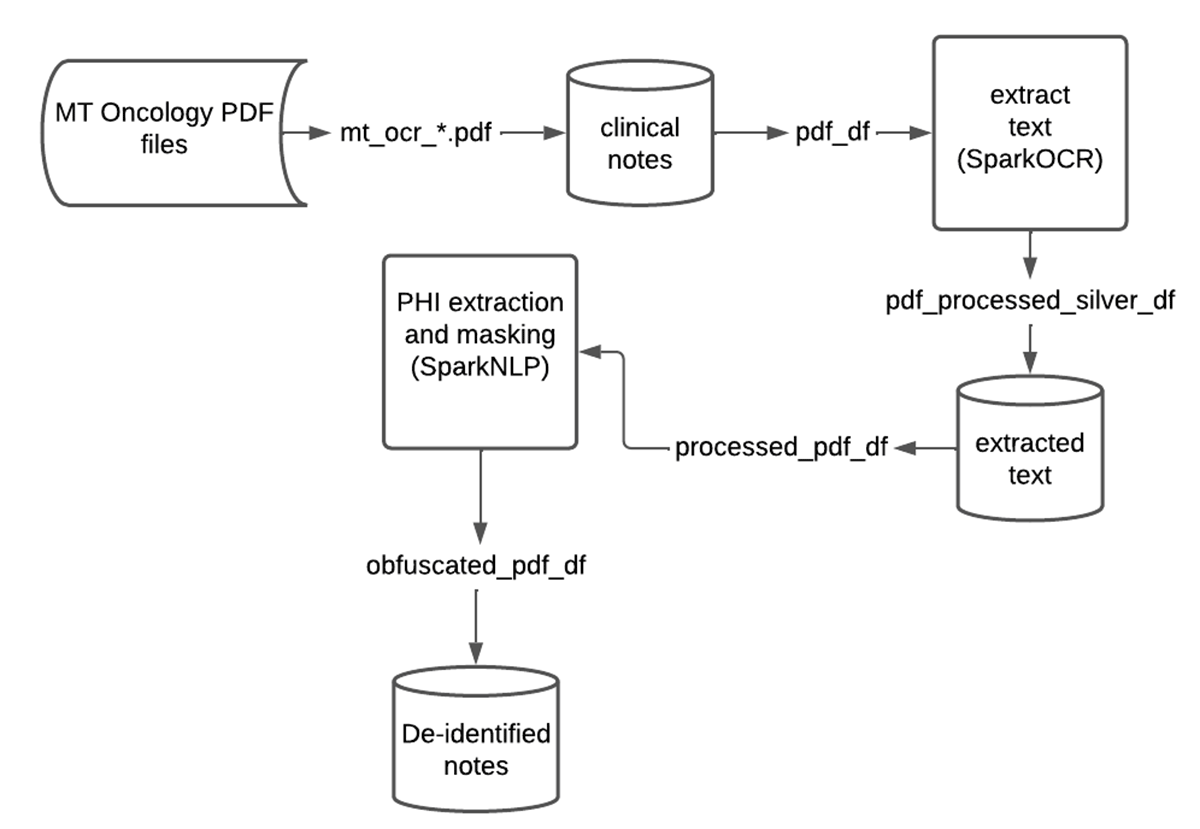
Databricks上でSpark OCRとSparkNLPを用いた保護対象保健情報の難読化のデータフローチャート
保護対象保健情報の除去パイプラインを構築しましょう
このソリューションアクセラレータによりDatabricksとJohn Snow Labsは、PDFの医療文書に含まれる機微情報の非識別化と難読化の自動化を容易にします。
このソリューションアクセラレータでは、あなたはノートブックをオンラインであらかじめ見た上で、それらをDatabricksのあなたのアカウントにインポートすることができます。ノートブックは、関連するJohn Snow Labsの自然言語処理ライブラリとライセンスキーをインストールする方法の案内が含まれています。
また、ヘルスケアとライフサイエンスのためのLakehouseのページでは、私たちの全てのソリューションを知ることができます。