この記事はスタンバイ Advent Calendar 2023 の11日目の記事です。
こんにちは。求人検索サービスを提供する株式会社スタンバイでプロダクト開発部長をしている大須賀です。
普段の仕事は開発組織運営などのマネジメントが中心です。一般的にマネージャは、業務として直接的に開発に携わることが少なくなり、Individual Contributor (IC) としてスペシャリストを目指すエンジニアから敬遠されがちです。確かにその通りかもしれませんが、幸運なことに私の場合、仕事をではマネージャとして、OSS 活動ではエンジニアとして、今年一年、充実したキャリアを積むことができたと思っています。
そこで今回は、会社でマネージャをしながらも、OSS の活動でエンジニアとして貢献できた OSS 全文検索サーバー Meilisearch を紹介したいと思います。
私が Meilisearch にかかわり始めたのは、2022年5月に miiton 氏のコントリビューションによって、私が開発している形態素解析器 Lindera が Meilisearch の日本語 Segmenter として組み込まれたことがきっかけです。
OSS 開発者として、自分が開発したソフトウェアが製品に組み込まれることは、この上なく嬉しいものです。そのことが私自身の活動の励みにもなり、その頃から、形態素解析器のパフォーマンス改善や Meilisearch の日本語サポート周辺の課題解決を積極的に手伝うようになりました。(もちろん業務外の時間で。)
その私の活動が Meilisearch のエンジニアの目に留まったのか、今年の5月に Meilisearch の言語サポートのメインコントリビューター (Meilistars) のひとりとして認められ、インタビュー記事 (Minoru Osuka: POV of a main language contributor) まで書いてもらいました。
Meilisearch のコントリビューターのひとりとして、日本国内への普及に少しでも貢献できればと思います。
Meilisearch とは

Meilisearch はフランス パリの検索エンジンスタートアップ Meilisearch 社が開発する Rust 製の全文検索サーバーです。読み方はメイリサーチです。
2023年2月に初の安定板であるバージョン 1.0.0 がリリースされ、Gigazine でも紹介記事が書かれたり、既にいろいろな方のブログ記事などで取り上げられているので、ご存じの方も多いかと思います。
現在は最新版のバージョン 1.5.0 がリリースされています。
以下に Meilisearch の特徴のいくつかをいくつか上げたいと思います。
高速 (Lightning fast)
Meilisearch のベンチマークは他のブログ記事などにも書かれているように数万件 (数十MB) のドキュメントを数十秒でインデクシングし、Query Auto-Completion のような Typeahead search を行ってもミリ秒単位で応答しサクサク動くとのことです。フットプリントも小さく、メモリ使用量も少ないのも特徴です。
導入が簡単 (Plug 'n play)
デフォルトで賢い初期設定がされているので、デプロイしてすぐにデータを投入して利用を開始できます。
これは検索エンジンを手軽に使いたいという人にはとても嬉しいことではないでしょうか。Elasticsearch や Solr、Vespa では、まずスキーマをどうするかなど、インデクシングを始める前に考えなければならないことが数多くあります。とりあえずすぐに全文検索機能をサービスに導入してキーワード検索を実現したい、というユーザーには非常に魅力的ではないでしょうか。
豊富な機能 (Ultra relevant)
あらゆるユースケースに対応できる検索のための機能を備えています。上記のようにプリセットされた設定でも満足できるかもしれませんが、必要であれば、カスタマイズも可能です。Filtering や Relevancy の設定をすることが可能なので、好みに合わせて検索結果の調整も可能です。
実装が容易 (Easy to integrate)
Meiliserch は HTTP をベースとした RESTful API を提供していますが、アプリケーションへの実装が容易にできるよう、様々な開発言語のための SDK が用意されています。
こちらの integration-guides を見ていただくとわかるようにメジャーな開発言語向けの SDK は揃っています。
できること
さて、そんな Meilisearch ですが、どんな用途に向いているかというと、既に多くのユースケースがあります。
全文検索 (Full text search)
もっとも一般的な使い方です。ウェブサイト、ブログ、ナレッジベースなど、情報が多くなるにつれて目的の情報にたどり着くのが困難になるケースがありますが、手軽に全文検索を用いたサイト内検索を実現できます。ファセット検索にも対応しているのでお手軽にカテゴリ毎にドキュメントをまとめるなどもできます。
-
オンラインドキュメントと日本語全文検索
実際に Sphinx のテーマに Meilisearch から検索する JavaScript を組み込んで、ドキュメントを全文検索できるようにしています。 -
MisskeyでMeilisearchを導入するやり方
Misskey という OSS の分散型 SNS プラットフォームへ組み込んで投稿を検索できるようにするといったこともできます。
位置情報検索 (Geo search)
緯度経度で検索したり、ある地点からの距離で絞り込んだりできるので、実世界の情報を利用して地図上にピンを立てるといった地図サービスのようなものも実現できます。
-
Example of Meiliseach in Japanese
こちらは位置情報も含んだ日本語検索のデモンストレーションになります。
位置情報だけでなく、ファセットも盛り込んだものになっているので、Meilisearch の機能を存分に体験できます。
セマンティック検索 (Semantic search)
2023年7月にリリースされたバージョン 1.3.0 からベクトルデータのサポートが実験的に導入されたことで、ベクトル検索を行えるようになりました。テキストを形態素解析器でトークン化するのではなく、Embedding model を使用してベクトルで表現し、ベクトル間の距離を計算することで、類似するベクトルを検索する手法です。
キーワード検索とは異なり、ドキュメントやクエリの意図や意味といったもので検索を行います。
OpenAI の ChatGPT などの大規模言語モデル (LLM:Large Language Models) が注目されていますが、その LLM と AI エージェントの開発を助ける LangChain と一緒に Meilisearch を使うことでセマンティック検索を構築することも可能です。
-
A step-by-step tutorial to building semantic search with LangChain
こちらは、実際に LLM と LangChain、Meilisearch を組み合わせてセマンティック検索を構築するための手順が説明されたオフィシャルブログの記事です。
まだ苦手なこと
どんな用途にも使えそうな Meilisearch ですが、まだ苦手なことはありそうです。
完全なカスタマイズ
Meilisearch は賢い初期設定がされており、豊富な機能を備え、カスタマイズ可能です。しかしながら、Elasticsearch や Solr、Vespa のようにフィールド単位でのきめ細かなスキーマ設定やアナライザの設定ができません。
検索のすべてを掌握し、コントロールする必要があるなら Elasticsearch や Solr、Vespa などの検索サーバーを利用する方が良いでしょう。
でも、それはそれでとても大変ですよね?サクッと全文検索できれば良いというライトユーザーにはとても面倒な作業の連続になるでしょう。意外と Meilisearch で事足りてしまうかもしれません。
ランキング学習
ルールベース (Relevancy) を用いたランキングの調整を行うことはできますが、残念ながら機械学習を用いたランキング学習 (LTR: Learning to Rank) といった、ランキングの手法をとることはまだできません。完全なカスタマイズと同様、Elasticsearch や Solr、Vespa といった検索サーバーを利用する方が良いでしょう。
ただ、Meilisearch のターゲットであるライトな検索エンジンユーザーには、LTR は運用コストを考えると重すぎるかな?とも思います。
日本語の対応状況
日本語の対応状況はどうでしょうか?
先ほども書かせてもらいましたが、2022年5月にリリースされた バージョン 0.27.0 から私がメンテナンスをしている OSS の日本語形態素解析器 Lindera を日本語の Segmenter として採用しており、日本語のドキュメントを扱うことができるようになっています。
ところが、Meilisearch のインデックス設定やドキュメントの構造、検索 API のパラメータには Segmenter を指定するような項目は見当たりません。
なんと Meilisearch は Elasticsearch や Solr、Vespa のように Tokenizer 設定をする必要はありません。Meilisearch の Tokenizer は入力されたドキュメントのテキストから、どの言語で書かれたかを自動検出し、検出できた言語用の Segmenter を使ってテキストを単語に分割します。
簡単ですね。何も難しいことはありませんし、何も悩むことはありません。よしなにやってくれます。
言語自動検出の対応状況
上記のように文字列から言語検出を行っていますが、カンの良い人は気づいたかもしれません。
漢字のみクエリの場合、日本語のつもりでも自動言語検出機能によって中国語と判定されてしまうという問題があります。
先程も紹介しましたが、Meilisearch ではフィールド毎にどの Segmenter を使用するか指定はできません。そのフィールドに入ってきたテキストを基に言語検出を行い、自動で Segmenter を切り替えます。
インデックスするテキストが「ここは東京都渋谷区」というテキストであれば、日本語固有の片仮名や平仮名が文字として含まれているので、日本語であると検出され、Tokenizer は日本語用の Segmenter (Lindera) を使って「ここ / は / 東京 / 都 / 渋谷 / 区」とトークン化します。
しかし、クエリの場合はどうでしょう?検索の時は比較的短い単語だけのクエリで検索することが多いと思います。
一般的に、「東京」というクエリで先程のテキストが検索できることを期待しますが、漢字だけの単語「東京」と言うクエリは、中国語であると検出されてしまうため、中国語用の Segmenter (Jieba) が適用され、「東 / 京」とトークン化されてしまい、ユーザーの意図した形で検索を行うことができないのです。
| テキスト | 言語検出 | Segmenter | トークン |
|---|---|---|---|
| ここは東京都渋谷区 | Japanese | Lindera | ここ / は / 東京 / 都 / 渋谷 / 区 |
| 東京 | Mandarin | Jieba | 東 / 京 |
Meilisearch の Tokenizer はテキストがどの言語で書かれているかの検出には Whatlang を使用していますが、漢字のみのテキストでは日本語なのか中国語なのかを正確に検出することは難しそうです。
次のベン図を見ていただければわかると思います。
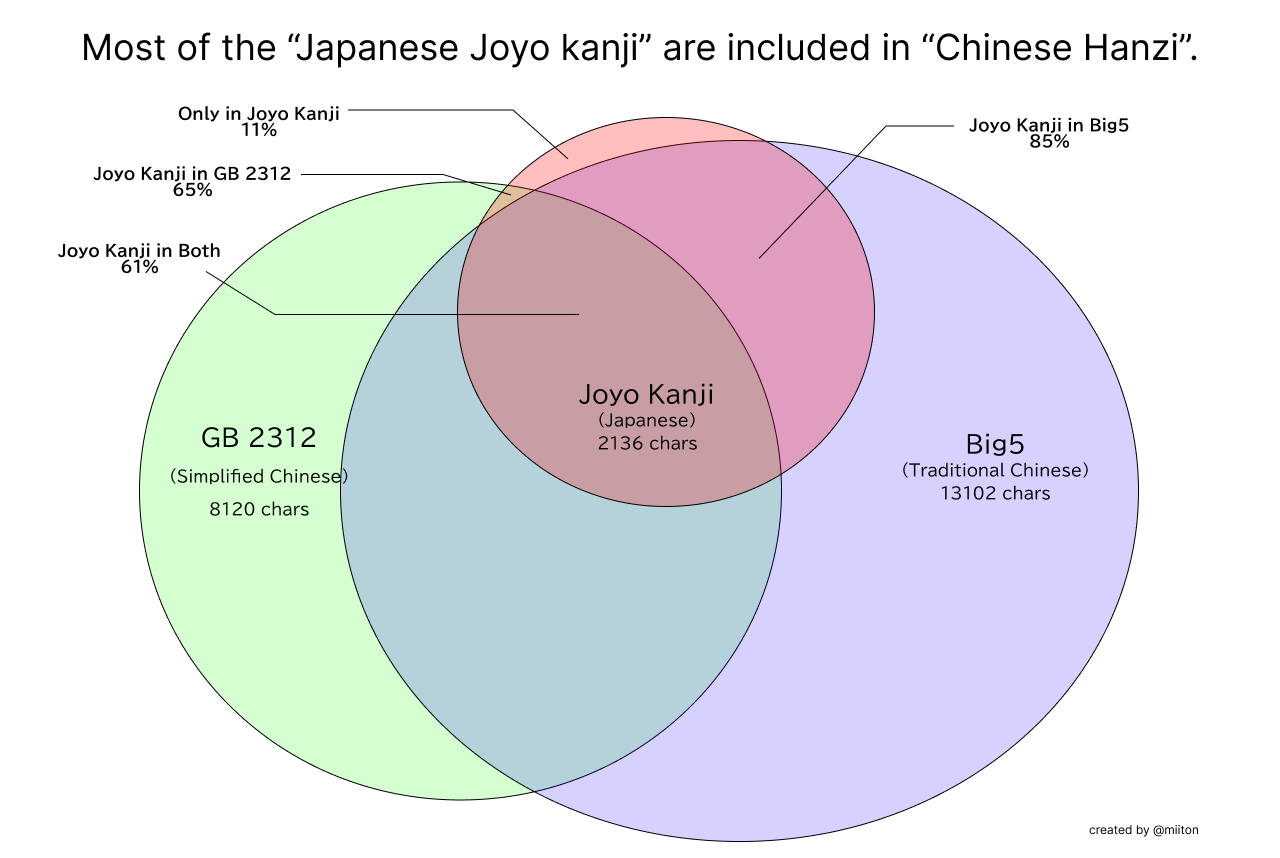
漢字は日本語だけでなく中国語でも使われています。日本語の常用漢字の殆どは中国語 (GB 2312、Big5) でも利用されている文字であるため、文字単位で何語であるかを判断できません。漢字のみの日本語テキストを Whatlang が中国語として検出してしまうのも仕方ないなと思ってしまいます。
これでは、日本語のテキストを検索することはできないじゃないかと思うかもしれませんが、Meilisearch は日本語を扱うためのビルドがされたバイナリを含むコンテナイメージを Docker Hub で配布していますので、日本語をメインとする検索サービスを構築する方は、こちらを利用することを強くお勧めします。
形態素解析辞書の対応状況
あと、日本語形態素解析器の辞書ですが、分散型 SNS プラットフォームへ組み込む取り組みの中で、コンテキスト (文脈) の有無で形態素解析の結果が異なるという問題が話題となりました。
コンテキストの有無でトークン化が変わる例を次に上げます。
| 辞書 | テキスト | トークン | |
|---|---|---|---|
| IPADIC | doc: 京都大学に行く query: 京都大学 |
doc: 京都大 / 学 / に / 行く query: 京都大学 |
× トークン不一致 検索できない |
| UniDic | doc: 京都大学に行く query: 京都大学 |
doc: 京都 / 大学 / に / 行く query: 京都 / 大学 |
○ トークン一致 検索できる |
このように IPADIC では、形態素辞書に登録されている情報により、「京都大学」という文字列が文脈の有無によってトークン化のされ方が変わってしまいます。これでは「京都大学に行く」というテキストは「京都大学」というクエリで検索できませんが、UniDic では文脈の有無によってズレが生じることなく、一貫性のあるトークン化が行えます。
UniDic にすると辞書のサイズが大きくなってしまうというデメリットがありますが、情報検索においては、このような一貫性のあるトークン化が行えることのほうが重要であると個人的にも考えていますので、Meilisearch のデフォルトの辞書を IPADIC から UniDic へ切り替えさせてもらいました。
この記事執筆時点において、デフォルトの IPADIC を内包する Lucene Kuromoji を日本語トークナイザとしている Elasticsearch や Solr では、上記のような文脈の有無によってトークン化にズレが生じ、検索できないケースなどがありますが、Meilisearch では UniDic をデフォルトで内包しているため、一貫性のあるトークン化が Elasticsearch や Solr よりも期待でき、より良い検索体験を実現できているのではないでしょうか。(※ ただし、内包される辞書が大きくなってしまい、バイナリサイズが大きくなってしまいます)
この一貫性のあるトークン化の重要性については情報検索のための単語分割一貫性の定量的評価を読んでいただければと思います。
まとめ
Meilisearch について、なんとなく理解していただけたでしょうか?
生まれたばかりで、今後の成長が楽しみなプロダクトにコントリビューターとして関われたのはエンジニアとしてとても良い経験ができました。
まだまだ日本語を扱うには課題が多い Meilisearch ですが、日本語のサポートについては Meilisearch の開発者だけでなく、私達のような多くのコミュニティの開発によって支えられています。特に言語周りの処理については、その言語を母国語とするソフトウェアエンジニアの力必要となります。
Meilisearch の日本語サポートについて興味がありましたら、ぜひこちらのディスカッションに参加していただけたらと思います。
そして、今年一年お世話になった、OSS 開発コミュニティの皆さんに改めて感謝いたします。
最後に

私達スタンバイでは、事業成長に伴い、一緒にサービス作りと事業を支えてくれるエンジニアを募集しています。
スタンバイ Advent Calendar 2023 や、Stanby Tech Blog の記事を読んで、弊社に興味もっていただけたら幸いです。
カジュアル面談などで、弊社について詳しくご説明させていただきますので、一度お話してみませんか?
ぜひお声がけください!