急がないと!先を越されちゃう!
Bedrock AgentCoreで提供されるもろもろは、こんな感じ。(らしい)
📚 Amazon Bedrock AgentCore Tutorials
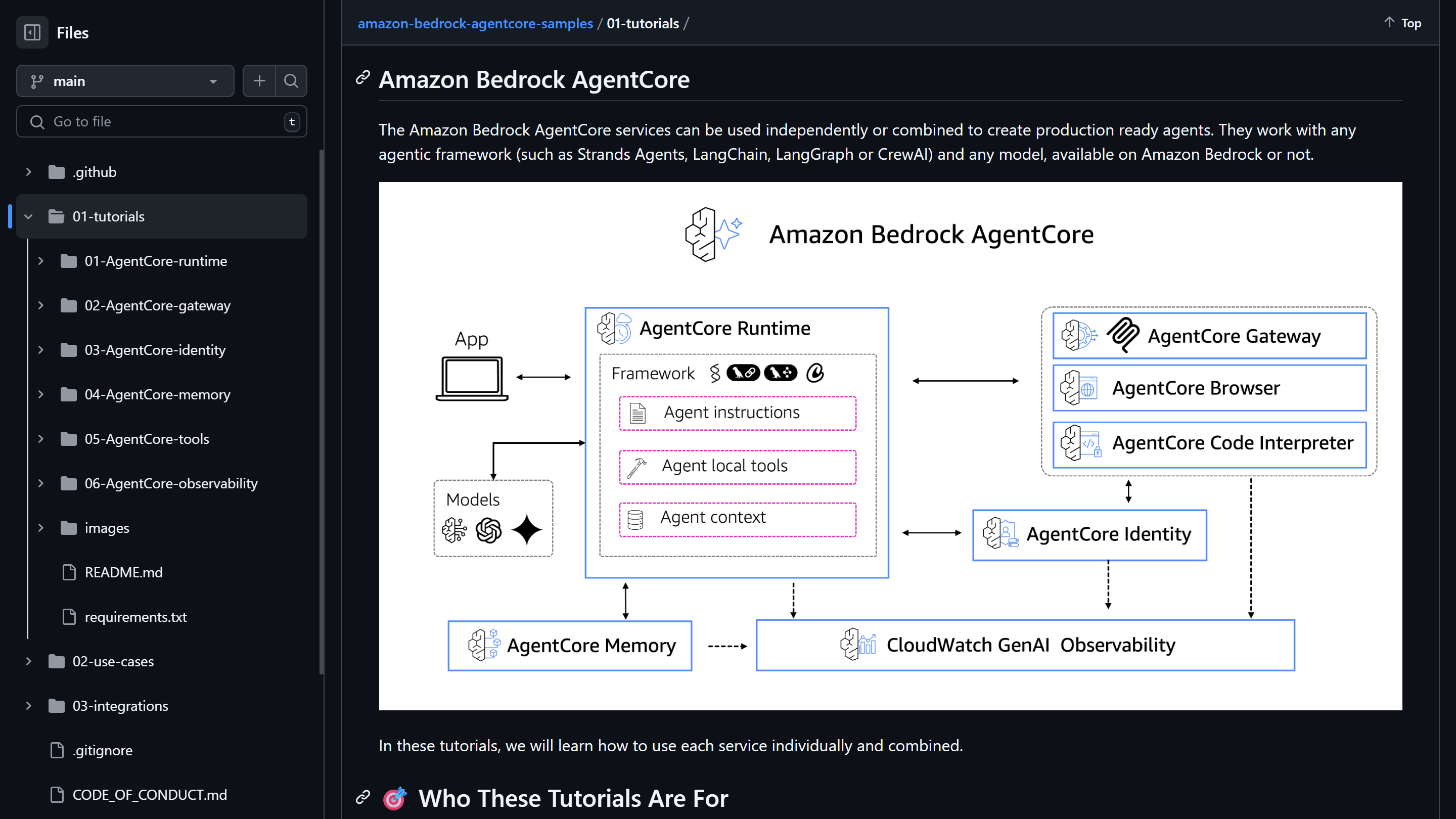
右側にある上から2つ目の「AgentCore Browser」を試しました!
これは何者なのか?
「AWS側にあるブラウザ」です。
やってみた。
GitHubには、サンプルとしてNovaActを使ったものと、Browser-Useを使ったものがあります。
今回は、よりシンプルに、Playwrightから直接呼ぶものを作りました。
uv init
uv add bedrock-agentcore playwright strands-agents
Strands Agentsは後で使います。
まず、AgentCore Browserですが、こんな感じ使います。
from bedrock_agentcore.tools.browser_client import BrowserClient
region = "us-east-1"
client = BrowserClient(region)
client.start()
ws_url, headers = client.generate_ws_headers()
# ...ここでブラウザ操作する
client.stop()
AWSの認証情報を渡す口がないのですが、内部的には認証情報が利用されています。
client.generate_ws_headers()を実行すると、WebSocketのエンドポイントと、ヘッダーが取得できます。
エンドポイント
wss://bedrock-agentcore.us-east-1.amazonaws.com/browser-streams/aws.browser.v1/sessions/********/automation
ヘッダー
{
"Host": "bedrock-agentcore.us-east-1.amazonaws.com",
"X-Amz-Date": "20250717T100340Z",
"Authorization": "AWS4-HMAC-SHA256 Credential=***",
"Upgrade": "websocket",
"Connection": "Upgrade",
"Sec-WebSocket-Version": "13",
"Sec-WebSocket-Key": "***",
"User-Agent": "BrowserSandbox-Client/1.0 (Session: ***)",
"X-Amz-Security-Token": "***"
}
このエンドポイントとヘッダーの情報を使って、AWSにあるブラウザへPlaywrightから接続します。playwright.chromium.connect_over_cdpのところです。
from playwright.sync_api import sync_playwright
with sync_playwright() as playwright:
browser = playwright.chromium.connect_over_cdp(
endpoint_url=ws_url, headers=headers
)
ブラウザに接続してしまえば、あとは普通(?)に使うだけです。
default_context = browser.contexts[0]
page = default_context.pages[0]
page = browser.new_page()
page.goto(url)
page.screenshot(path=file_name)
browser.close()
Strands Agentsのツールとして呼び出す
最後に、Strands Agentsから呼び出す感じにしてみます。
ユーザーが希望したURLにアクセスし、Playwrightでスクリーンショットを取るツールを作ります。
@tool
def capture_page(url: str) -> str:
"""
URLにアクセスし、スクリーンショットを取得します。
取得したスクリーンショットのファイルパスを返却します。
"""
file_name = "image.png"
client = BrowserClient(region)
client.start()
ws_url, headers = client.generate_ws_headers()
with sync_playwright() as playwright:
browser = playwright.chromium.connect_over_cdp(
endpoint_url=ws_url, headers=headers
)
default_context = browser.contexts[0]
page = default_context.pages[0]
page = browser.new_page()
page.goto(url)
page.screenshot(path=file_name)
browser.close()
client.stop()
return file_name
ツールを追加したエージェントを作成します。
bedrock = BedrockModel(model_id="us.amazon.nova-lite-v1:0", region_name=region)
agent = Agent(model=bedrock, tools=[capture_page])
そして呼ぶ
agent("Yahoo Japanのトップページをキャプチャして!")
すると、image.pngとしてファイルが作成されました。
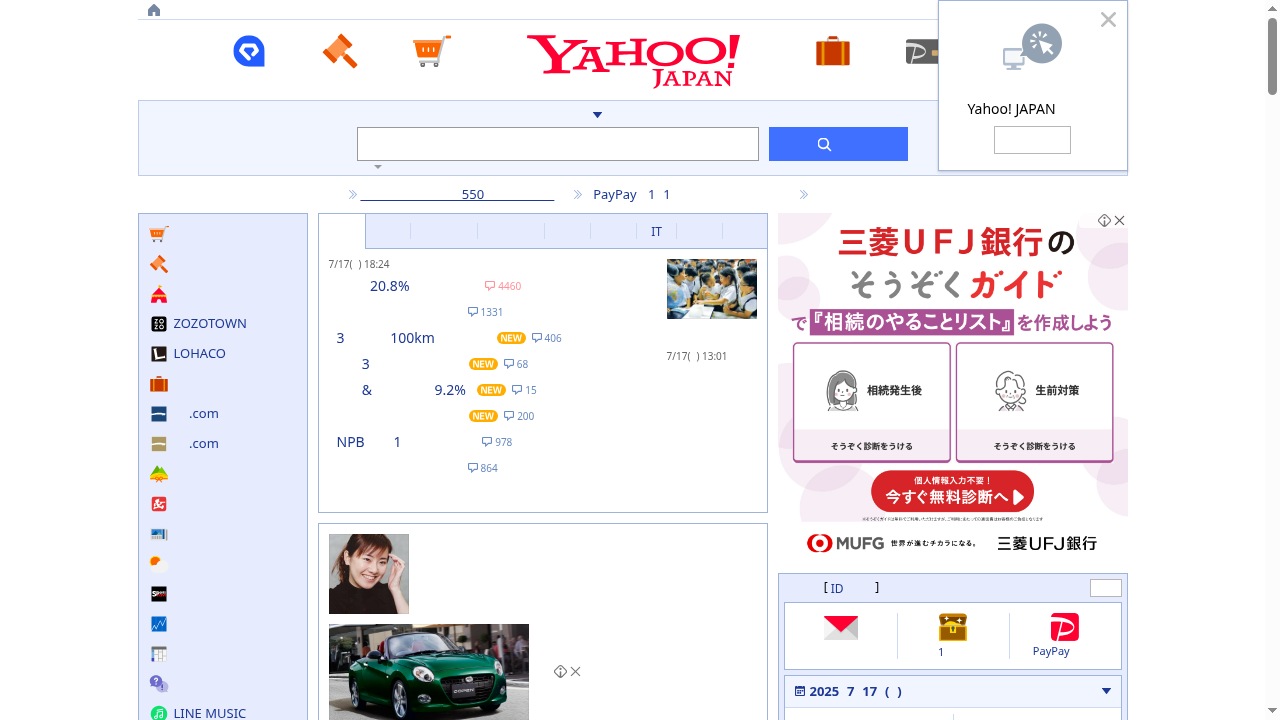
あ。。。
ソース置いときます。
main.py
import sys
from bedrock_agentcore.tools.browser_client import BrowserClient
from playwright.sync_api import sync_playwright
from strands import Agent, tool
from strands.models import BedrockModel
region = "us-east-1"
@tool
def capture_page(url: str) -> str:
"""
URLにアクセスし、スクリーンショットを取得します。
取得したスクリーンショットのファイルパスを返却します。
"""
file_name = "image.png"
client = BrowserClient(region)
client.start()
ws_url, headers = client.generate_ws_headers()
with sync_playwright() as playwright:
browser = playwright.chromium.connect_over_cdp(
endpoint_url=ws_url, headers=headers
)
default_context = browser.contexts[0]
page = default_context.pages[0]
page = browser.new_page()
page.goto(url)
page.screenshot(path=file_name)
browser.close()
client.stop()
return file_name
bedrock = BedrockModel(model_id="us.amazon.nova-lite-v1:0", region_name=region)
agent = Agent(model=bedrock, tools=[capture_page])
if __name__ == "__main__":
if len(sys.argv) < 2:
print('使用方法: python main.py "プロンプト"')
sys.exit(1)
prompt = sys.argv[1]
agent(prompt)
uv run main.py "Yahoo Japanのトップページをキャプチャして!"