はじめに
この記事は Futureアドベントカレンダー の21日目のエントリーです。昨日は @ppputtyo さんの 【ISUCON14】ISUCONに初参加しました
でした。
今回のアドベントカレンダーに限らず、生成AIというワードが非常にブームとなり、かつてDXやブロックチェーンが盛んに叫ばれたのと同じように、今ではやれChatGPTだやれGeminiといった単語をよく聞きます。案件においてもAIを使いたいという声は聞きます。しかし、個人的にはAIはまだまだ万能の道具ではなく、特にすでにある大量のデータから特定の情報を見出すときなどは、人間がデータを組み合わせるほうが一日の長があると考えますし、なによりデータの分析をできないと、AIが出してきた結果のもっともらしさの評価すらできないと考えるからです。
今回のモチベーション
現在も自分で手を動かし分析することは良くしますが、どうしても長く案件を続けていると、その開発環境に合わせたツールを長く使うことになります。
コードを直接書くことが少なくなりつつも、私の場合はAWS LambdaやGlueでPythonなどを中心に扱います。
PythonだとLambdaは3.13まで対応していますが、Glueは最新のAWS Glue 4.0でもサポートは3.10のため、どうしてもそれくらいのものになりがちです。
これではなかなか新しい技術の習得も腰が重くなりがちなので、直近流行っていそうなツールを比較しつつ、実際業務を考えてどれが使えそうか見ていきたいと思います。
想定する状況
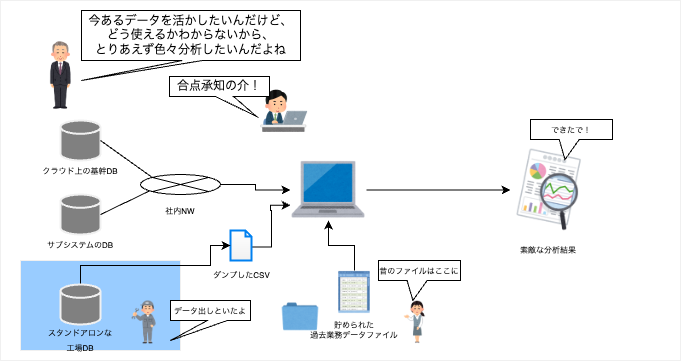
すでに企業内では多くのデータが蓄積されています。
それは製造時の記録だったり、営業時のデータだったり、あるいは料金請求時のデータだったり様々です。
それが仮にすべて一つのDBに入っていればそこでSQLを一発投げればよいかもしれませんが、実際はシステムの導入時期などによって、別システム・別DBになっていることもままあり、場合によってはNW自体独立していることも少なくありません。
実際にデータ分析を行う際は各所からどのようにデータを持ってくるか考える必要がありますが、その最初のステップは「今あるデータから何が見えるか」です。
といわけで、直接データを複数のDBにアクセスして抜いてくるなり、CSVなりにダンプしてローカルに持っていることからスタートとします。
想定するシチュエーションとデータのイメージ
複数のCSVやExcel等のデータを各所からかき集めて、とりあえず結合して行くことを考えます。
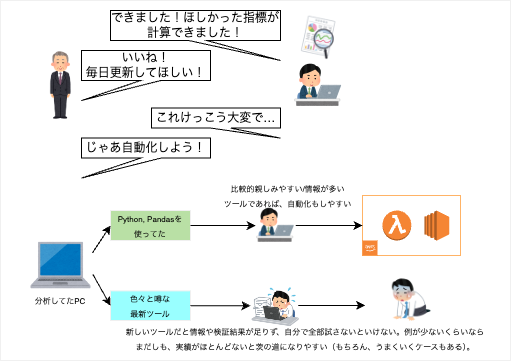
なお、最初の分析こそローカルで作業しますが、簡単な集計であればそのままクラウドに乗せて動作させることを考えたくなります。
特に一度結果を出してみてそれが良いものだった場合、この分析を定常的に欲しくなります。
例えば、業務状況を可視化するようなダッシュボードなどの形にできれば、長く活用していくことができます。
そうなると、このデータのうち必要なものだけをクラウドなどに用意し、クイックに自動化していくことになります。ここまで考えたうえで、自動化もしやすく、同時に使い勝手も良いようなツールを探していきたいと思います。 (冒頭で生成系AIについて色々言っておきながら自分もpandas以外に少しは新しいものを使っていきたいという矛盾を抱えているなんてきっとない。)
個人的に比較的よく使うということで、今回は最終的にAWS Lambdaに乗せることも含めて考えてみます。
実際に比較する
今回は、以下のマシンで検証するものとします。
- マシン MacBookPro
- CPU Apple M1 Pro
- OS Sonoma 14.7
- Python 3.13.1
- 環境構築用に poetry 1.8.5
pandas以外だと、候補として上がってくるツールはこのへんかなと思い、記載しました。
Google Trendでみても、やはりpandasが強者だというのがわかります。
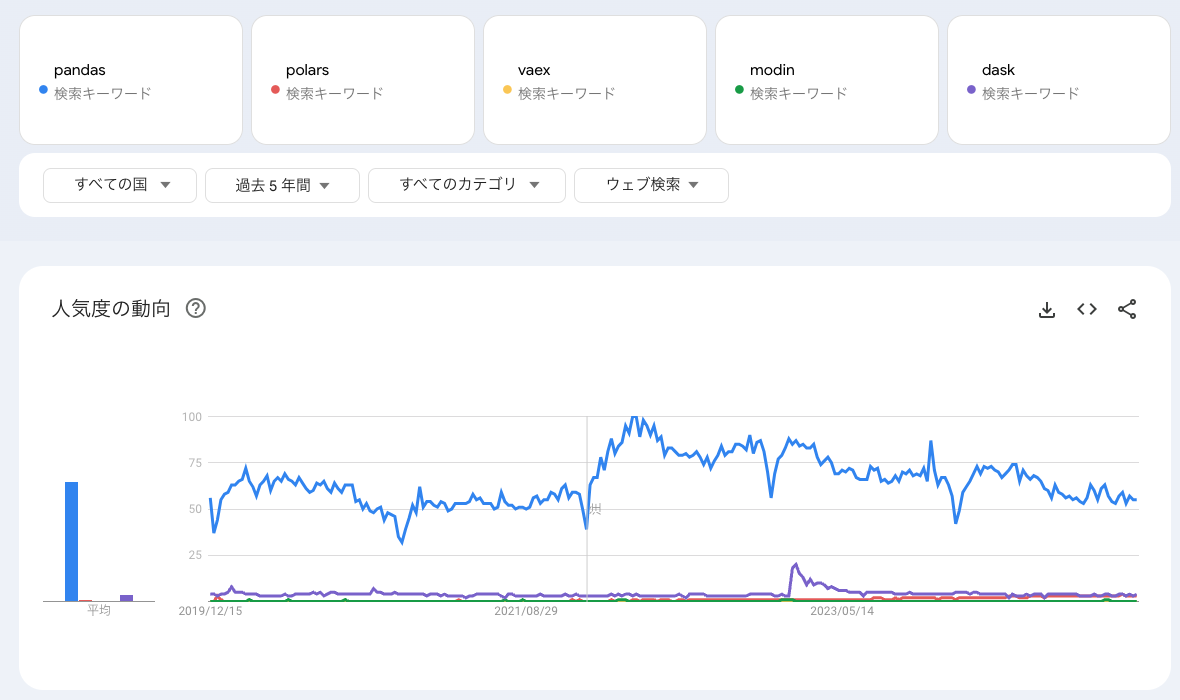
- 今回比較するもの
- pandas
- dask
- modin
- Polars
- 今回比較外とするもの
- Fireducks
- PySpark
- vaex
他にもあったら教えていただきたいです。
比較外としたものも含め、紹介などはこの後順番に行います。
ただ、先に結論としては、pandasと同程度のデータ量で同じような使い勝手を前提に、自動化やできれば高速化もめざすとなると、 現状はPolars一択になりそうな気がします。
いったん、個々のライブラリの超簡単な操作について、見ていきます。
pandas
Python使用者なら間違いなく聞いたことがあるだろうライブラリの一つであり、テーブルデータを簡単に処理できます。
トレンドを見ても圧倒的強者でありますが、パフォーマンス特化ではないため、中規模を超えるようなデータセットを扱う場合、パフォーマンスなどに問題があります。
使い勝手も紹介するまでもないですが、いつものような形です。
なお、データはkaggleよりtitanicのデータです。
import pandas as pd
dfx = pd.read_csv("../titanic/gender_submission.csv")
dfy = pd.read_csv("../titanic/test.csv")
dfz = pd.read_csv("../titanic/train.csv")
print(dfx)
print(dfy)
print(dfz.describe())
$ python pandas_main.py
PassengerId Survived
0 892 0
1 893 1
2 894 0
3 895 0
4 896 1
.. ... ...
413 1305 0
414 1306 1
415 1307 0
416 1308 0
417 1309 0
[418 rows x 2 columns]
PassengerId Pclass ... Cabin Embarked
0 892 3 ... NaN Q
1 893 3 ... NaN S
2 894 2 ... NaN Q
3 895 3 ... NaN S
4 896 3 ... NaN S
.. ... ... ... ... ...
413 1305 3 ... NaN S
414 1306 1 ... C105 C
415 1307 3 ... NaN S
416 1308 3 ... NaN S
417 1309 3 ... NaN C
[418 rows x 11 columns]
PassengerId Survived ... Parch Fare
count 891.000000 891.000000 ... 891.000000 891.000000
mean 446.000000 0.383838 ... 0.381594 32.204208
std 257.353842 0.486592 ... 0.806057 49.693429
min 1.000000 0.000000 ... 0.000000 0.000000
25% 223.500000 0.000000 ... 0.000000 7.910400
50% 446.000000 0.000000 ... 0.000000 14.454200
75% 668.500000 1.000000 ... 0.000000 31.000000
max 891.000000 1.000000 ... 6.000000 512.3
Dask
Pythonで並列・分散処理などを扱うライブラリで、pandasではメモリに乗り切らないデータでも、データを少しずつメモリ上にもってくることで、扱うことができます。
最初に紹介するツールですが、pandasの置き換えとはちょっと違い、どちらかというとpandasだけでは解決しきれないデータセットを扱う際に、拡張目的で使われることが多そうです。
import dask.dataframe as dd
dfx = dd.read_csv("../titanic/gender_submission.csv")
dfy = dd.read_csv("../titanic/test.csv")
dfz = dd.read_csv("../titanic/train.csv")
print(dfx)
print(dfy)
print(dfz.describe())
$ python main.py
Dask DataFrame Structure:
PassengerId Survived
npartitions=1
int64 int64
... ...
Dask Name: to_string_dtype, 2 expressions
Expr=ArrowStringConversion(frame=FromMapProjectable(dfea077))
Dask DataFrame Structure:
PassengerId Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked
npartitions=1
int64 int64 string string float64 int64 int64 string float64 float64 string
... ... ... ... ... ... ... ... ... ... ...
Dask Name: to_string_dtype, 2 expressions
Expr=ArrowStringConversion(frame=FromMapProjectable(4f730d8))
Dask DataFrame Structure:
PassengerId Survived Pclass Age SibSp Parch Fare
npartitions=1
float64 float64 float64 float64 float64 float64 float64
... ... ... ... ... ... ...
Dask Name: concat, 17 expressions
Expr=Concat(frames=[ArrowStringConversion(frame=FromMapProjectable(4655e2d))['PassengerId'].describenumeric(split_every=False), ArrowStringConversion(frame=FromMapProjectable(4655e2d))['Survived'].describenumeric(split_every=False), ArrowStringConversion(frame=FromMapProjectable(4655e2d))['Pclass'].describenumeric(split_every=False), ArrowStringConversion(frame=FromMapProjectable(4655e2d))['Age'].describenumeric(split_every=False), ArrowStringConversion(frame=FromMapProjectable(4655e2d))['SibSp'].describenumeric(split_every=False), ArrowStringConversion(frame=FromMapProjectable(4655e2d))['Parch'].describenumeric(split_every=False), ArrowStringConversion(frame=FromMapProj
Polars
Rust製のライブラリで、Pythonバインディングを利用します。
ベンチマーク比較においても、高速なライブラリとしてされています。今回この記事を書くことにした理由の一つです。
import polars as pl
dfx = pl.read_csv("../titanic/gender_submission.csv")
dfy = pl.read_csv("../titanic/test.csv")
dfz = pl.read_csv("../titanic/train.csv")
print(dfx)
print(dfy)
print(dfz.describe())
$ python main.py
shape: (418, 2)
┌─────────────┬──────────┐
│ PassengerId ┆ Survived │
│ --- ┆ --- │
│ i64 ┆ i64 │
╞═════════════╪══════════╡
│ 892 ┆ 0 │
│ 893 ┆ 1 │
│ 894 ┆ 0 │
│ 895 ┆ 0 │
│ 896 ┆ 1 │
│ … ┆ … │
│ 1305 ┆ 0 │
│ 1306 ┆ 1 │
│ 1307 ┆ 0 │
│ 1308 ┆ 0 │
│ 1309 ┆ 0 │
└─────────────┴──────────┘
shape: (418, 11)
┌─────┬─────┬─────┬─────┬───┬─────┬─────┬─────┬───────┐
│ Pas ┆ Pcl ┆ Nam ┆ Sex ┆ … ┆ Tic ┆ Far ┆ Cab ┆ Embar │
│ sen ┆ ass ┆ e ┆ --- ┆ ┆ ket ┆ e ┆ in ┆ ked │
│ ger ┆ --- ┆ --- ┆ str ┆ ┆ --- ┆ --- ┆ --- ┆ --- │
│ Id ┆ i64 ┆ str ┆ ┆ ┆ str ┆ f64 ┆ str ┆ str │
│ --- ┆ ┆ ┆ ┆ ┆ ┆ ┆ ┆ │
│ i64 ┆ ┆ ┆ ┆ ┆ ┆ ┆ ┆ │
╞═════╪═════╪═════╪═════╪═══╪═════╪═════╪═════╪═══════╡
│ 892 ┆ 3 ┆ Kel ┆ mal ┆ … ┆ 330 ┆ 7.8 ┆ nul ┆ Q │
│ ┆ ┆ ly, ┆ e ┆ ┆ 911 ┆ 292 ┆ l ┆ │
│ ┆ ┆ Mr. ┆ ┆ ┆ ┆ ┆ ┆ │
│ ┆ ┆ Jam ┆ ┆ ┆ ┆ ┆ ┆ │
│ ┆ ┆ es ┆ ┆ ┆ ┆ ┆ ┆ │
│ 893 ┆ 3 ┆ Wil ┆ fem ┆ … ┆ 363 ┆ 7.0 ┆ nul ┆ S │
│ ┆ ┆ kes ┆ ale ┆ ┆ 272 ┆ ┆ l ┆ │
│ ┆ ┆ , ┆ ┆ ┆ ┆ ┆ ┆ │
│ ┆ ┆ Mrs ┆ ┆ ┆ ┆ ┆ ┆ │
│ ┆ ┆ . ┆ ┆ ┆ ┆ ┆ ┆ │
│ ┆ ┆ Jam ┆ ┆ ┆ ┆ ┆ ┆ │
│ ┆ ┆ es ┆ ┆ ┆ ┆ ┆ ┆ │
│ ┆ ┆ (El ┆ ┆ ┆ ┆ ┆ ┆ │
│ ┆ ┆ len ┆ ┆ ┆ ┆ ┆ ┆ │
│ ┆ ┆ Nee ┆ ┆ ┆ ┆ ┆ ┆ │
│ ┆ ┆ d… ┆ ┆ ┆ ┆ ┆ ┆ │
│ 894 ┆ 2 ┆ Myl ┆ mal ┆ … ┆ 240 ┆ 9.6 ┆ nul ┆ Q │
│ ┆ ┆ es, ┆ e ┆ ┆ 276 ┆ 875 ┆ l ┆ │
│ ┆ ┆ Mr. ┆ ┆ ┆ ┆ ┆ ┆ │
│ ┆ ┆ Tho ┆ ┆ ┆ ┆ ┆ ┆ │
│ ┆ ┆ mas ┆ ┆ ┆ ┆ ┆ ┆ │
│ ┆ ┆ Fra ┆ ┆ ┆ ┆ ┆ ┆ │
│ ┆ ┆ nci ┆ ┆ ┆ ┆ ┆ ┆ │
│ ┆ ┆ s ┆ ┆ ┆ ┆ ┆ ┆ │
│ 895 ┆ 3 ┆ Wir ┆ mal ┆ … ┆ 315 ┆ 8.6 ┆ nul ┆ S │
│ ┆ ┆ z, ┆ e ┆ ┆ 154 ┆ 625 ┆ l ┆ │
│ ┆ ┆ Mr. ┆ ┆ ┆ ┆ ┆ ┆ │
│ ┆ ┆ Alb ┆ ┆ ┆ ┆ ┆ ┆ │
│ ┆ ┆ ert ┆ ┆ ┆ ┆ ┆ ┆ │
│ 896 ┆ 3 ┆ Hir ┆ fem ┆ … ┆ 310 ┆ 12. ┆ nul ┆ S │
│ ┆ ┆ von ┆ ale ┆ ┆ 129 ┆ 287 ┆ l ┆ │
│ ┆ ┆ en, ┆ ┆ ┆ 8 ┆ 5 ┆ ┆ │
│ ┆ ┆ Mrs ┆ ┆ ┆ ┆ ┆ ┆ │
│ ┆ ┆ . ┆ ┆ ┆ ┆ ┆ ┆ │
│ ┆ ┆ Ale ┆ ┆ ┆ ┆ ┆ ┆ │
│ ┆ ┆ xan ┆ ┆ ┆ ┆ ┆ ┆ │
│ ┆ ┆ der ┆ ┆ ┆ ┆ ┆ ┆ │
│ ┆ ┆ (He ┆ ┆ ┆ ┆ ┆ ┆ │
│ ┆ ┆ lg… ┆ ┆ ┆ ┆ ┆ ┆ │
│ … ┆ … ┆ … ┆ … ┆ … ┆ … ┆ … ┆ … ┆ … │
│ 130 ┆ 3 ┆ Spe ┆ mal ┆ … ┆ A.5 ┆ 8.0 ┆ nul ┆ S │
│ 5 ┆ ┆ cto ┆ e ┆ ┆ . ┆ 5 ┆ l ┆ │
│ ┆ ┆ r, ┆ ┆ ┆ 323 ┆ ┆ ┆ │
│ ┆ ┆ Mr. ┆ ┆ ┆ 6 ┆ ┆ ┆ │
│ ┆ ┆ Woo ┆ ┆ ┆ ┆ ┆ ┆ │
│ ┆ ┆ lf ┆ ┆ ┆ ┆ ┆ ┆ │
│ 130 ┆ 1 ┆ Oli ┆ fem ┆ … ┆ PC ┆ 108 ┆ C10 ┆ C │
│ 6 ┆ ┆ va ┆ ale ┆ ┆ 177 ┆ .9 ┆ 5 ┆ │
│ ┆ ┆ y ┆ ┆ ┆ 58 ┆ ┆ ┆ │
│ ┆ ┆ Oca ┆ ┆ ┆ ┆ ┆ ┆ │
│ ┆ ┆ na, ┆ ┆ ┆ ┆ ┆ ┆ │
│ ┆ ┆ Don ┆ ┆ ┆ ┆ ┆ ┆ │
│ ┆ ┆ a. ┆ ┆ ┆ ┆ ┆ ┆ │
│ ┆ ┆ Fer ┆ ┆ ┆ ┆ ┆ ┆ │
│ ┆ ┆ min ┆ ┆ ┆ ┆ ┆ ┆ │
│ ┆ ┆ a ┆ ┆ ┆ ┆ ┆ ┆ │
│ 130 ┆ 3 ┆ Sae ┆ mal ┆ … ┆ SOT ┆ 7.2 ┆ nul ┆ S │
│ 7 ┆ ┆ the ┆ e ┆ ┆ ON/ ┆ 5 ┆ l ┆ │
│ ┆ ┆ r, ┆ ┆ ┆ O.Q ┆ ┆ ┆ │
│ ┆ ┆ Mr. ┆ ┆ ┆ . ┆ ┆ ┆ │
│ ┆ ┆ Sim ┆ ┆ ┆ 310 ┆ ┆ ┆ │
│ ┆ ┆ on ┆ ┆ ┆ 126 ┆ ┆ ┆ │
│ ┆ ┆ Siv ┆ ┆ ┆ 2 ┆ ┆ ┆ │
│ ┆ ┆ ert ┆ ┆ ┆ ┆ ┆ ┆ │
│ ┆ ┆ sen ┆ ┆ ┆ ┆ ┆ ┆ │
│ 130 ┆ 3 ┆ War ┆ mal ┆ … ┆ 359 ┆ 8.0 ┆ nul ┆ S │
│ 8 ┆ ┆ e, ┆ e ┆ ┆ 309 ┆ 5 ┆ l ┆ │
│ ┆ ┆ Mr. ┆ ┆ ┆ ┆ ┆ ┆ │
│ ┆ ┆ Fre ┆ ┆ ┆ ┆ ┆ ┆ │
│ ┆ ┆ der ┆ ┆ ┆ ┆ ┆ ┆ │
│ ┆ ┆ ick ┆ ┆ ┆ ┆ ┆ ┆ │
│ 130 ┆ 3 ┆ Pet ┆ mal ┆ … ┆ 266 ┆ 22. ┆ nul ┆ C │
│ 9 ┆ ┆ er, ┆ e ┆ ┆ 8 ┆ 358 ┆ l ┆ │
│ ┆ ┆ Mas ┆ ┆ ┆ ┆ 3 ┆ ┆ │
│ ┆ ┆ ter ┆ ┆ ┆ ┆ ┆ ┆ │
│ ┆ ┆ . ┆ ┆ ┆ ┆ ┆ ┆ │
│ ┆ ┆ Mic ┆ ┆ ┆ ┆ ┆ ┆ │
│ ┆ ┆ hae ┆ ┆ ┆ ┆ ┆ ┆ │
│ ┆ ┆ l J ┆ ┆ ┆ ┆ ┆ ┆ │
└─────┴─────┴─────┴─────┴───┴─────┴─────┴─────┴───────┘
shape: (9, 13)
┌─────┬─────┬─────┬─────┬───┬─────┬─────┬─────┬───────┐
│ sta ┆ Pas ┆ Sur ┆ Pcl ┆ … ┆ Tic ┆ Far ┆ Cab ┆ Embar │
│ tis ┆ sen ┆ viv ┆ ass ┆ ┆ ket ┆ e ┆ in ┆ ked │
│ tic ┆ ger ┆ ed ┆ --- ┆ ┆ --- ┆ --- ┆ --- ┆ --- │
│ --- ┆ Id ┆ --- ┆ f64 ┆ ┆ str ┆ f64 ┆ str ┆ str │
│ str ┆ --- ┆ f64 ┆ ┆ ┆ ┆ ┆ ┆ │
│ ┆ f64 ┆ ┆ ┆ ┆ ┆ ┆ ┆ │
╞═════╪═════╪═════╪═════╪═══╪═════╪═════╪═════╪═══════╡
│ cou ┆ 891 ┆ 891 ┆ 891 ┆ … ┆ 891 ┆ 891 ┆ 204 ┆ 889 │
│ nt ┆ .0 ┆ .0 ┆ .0 ┆ ┆ ┆ .0 ┆ ┆ │
│ nul ┆ 0.0 ┆ 0.0 ┆ 0.0 ┆ … ┆ 0 ┆ 0.0 ┆ 687 ┆ 2 │
│ l_c ┆ ┆ ┆ ┆ ┆ ┆ ┆ ┆ │
│ oun ┆ ┆ ┆ ┆ ┆ ┆ ┆ ┆ │
│ t ┆ ┆ ┆ ┆ ┆ ┆ ┆ ┆ │
│ mea ┆ 446 ┆ 0.3 ┆ 2.3 ┆ … ┆ nul ┆ 32. ┆ nul ┆ null │
│ n ┆ .0 ┆ 838 ┆ 086 ┆ ┆ l ┆ 204 ┆ l ┆ │
│ ┆ ┆ 38 ┆ 42 ┆ ┆ ┆ 208 ┆ ┆ │
│ std ┆ 257 ┆ 0.4 ┆ 0.8 ┆ … ┆ nul ┆ 49. ┆ nul ┆ null │
│ ┆ .35 ┆ 865 ┆ 360 ┆ ┆ l ┆ 693 ┆ l ┆ │
│ ┆ 384 ┆ 92 ┆ 71 ┆ ┆ ┆ 429 ┆ ┆ │
│ ┆ 2 ┆ ┆ ┆ ┆ ┆ ┆ ┆ │
│ min ┆ 1.0 ┆ 0.0 ┆ 1.0 ┆ … ┆ 110 ┆ 0.0 ┆ A10 ┆ C │
│ ┆ ┆ ┆ ┆ ┆ 152 ┆ ┆ ┆ │
│ 25% ┆ 224 ┆ 0.0 ┆ 2.0 ┆ … ┆ nul ┆ 7.9 ┆ nul ┆ null │
│ ┆ .0 ┆ ┆ ┆ ┆ l ┆ 25 ┆ l ┆ │
│ 50% ┆ 446 ┆ 0.0 ┆ 3.0 ┆ … ┆ nul ┆ 14. ┆ nul ┆ null │
│ ┆ .0 ┆ ┆ ┆ ┆ l ┆ 454 ┆ l ┆ │
│ ┆ ┆ ┆ ┆ ┆ ┆ 2 ┆ ┆ │
│ 75% ┆ 669 ┆ 1.0 ┆ 3.0 ┆ … ┆ nul ┆ 31. ┆ nul ┆ null │
│ ┆ .0 ┆ ┆ ┆ ┆ l ┆ 0 ┆ l ┆ │
│ max ┆ 891 ┆ 1.0 ┆ 3.0 ┆ … ┆ WE/ ┆ 512 ┆ T ┆ S │
│ ┆ .0 ┆ ┆ ┆ ┆ P ┆ .32 ┆ ┆ │
│ ┆ ┆ ┆ ┆ ┆ 573 ┆ 92 ┆ ┆ │
│ ┆ ┆ ┆ ┆ ┆ 5 ┆ ┆ ┆ │
└─────┴─────┴─────┴─────┴───┴─────┴─────┴─────┴───────┘
Jupyter Notebookで使えばpandasも遜色ないですが、こうやってターミナルで見ると、Polarsはきれいに表示されました。
modin
並列処理と分散処理を活用し、pandasの処理を高速化します。Modin自体はDaskあるいはRayをベースに構築されているため、やはり大規模なデータを扱うことができます。
pandasの拡張を目指しているようですが、完全な互換ではないため、導入時はコードの調整が必要なほか、小さなデータセットでは逆にオーバーヘッドが発生して不利になることもあります。
modinはデフォルトだとDaskベースで動きますが、モジュールの外で使うとエラーがでました。
import modin.pandas as pd
dfx = pd.read_csv("../titanic/gender_submission.csv")
公式に説明があるように、裏で動くDaskがフォークしてプロセスを始めてしまうからだそうです。
これを回避するため、次のように if __name__ == "__main__" の中で実行すると、うまくいきます。
import modin.pandas as pd
if __name__ == "__main__":
dfx = pd.read_csv("../titanic/gender_submission.csv")
dfy = pd.read_csv("../titanic/test.csv")
dfz = pd.read_csv("../titanic/train.csv")
print(dfx)
print(dfy)
print(dfz.describe())
$ python modin_main.py
PassengerId Survived
0 892 0
1 893 1
2 894 0
3 895 0
4 896 1
.. ... ...
413 1305 0
414 1306 1
415 1307 0
416 1308 0
417 1309 0
[418 rows x 2 columns]
PassengerId Pclass ... Cabin Embarked
0 892 3 ... NaN Q
1 893 3 ... NaN S
2 894 2 ... NaN Q
3 895 3 ... NaN S
4 896 3 ... NaN S
.. ... ... ... ... ...
413 1305 3 ... NaN S
414 1306 1 ... C105 C
415 1307 3 ... NaN S
416 1308 3 ... NaN S
417 1309 3 ... NaN C
[418 rows x 11 columns]
PassengerId Survived ... Parch Fare
count 891.000000 891.000000 ... 891.000000 891.000000
mean 446.000000 0.383838 ... 0.381594 32.204208
std 257.353842 0.486592 ... 0.806057 49.693429
min 1.000000 0.000000 ... 0.000000 0.000000
25% 223.500000 0.000000 ... 0.000000 7.910400
50% 446.000000 0.000000 ... 0.000000 14.454200
75% 668.500000 1.000000 ... 0.000000 31.000000
max 891.000000 1.000000 ... 6.000000 512.329200
[8 rows x 7 columns]
<以下略。ログが多く出た。>
これだと、たとえばJupyter Notebookなどで色々使うとき使いづらいので、そのときは色々調べてみる必要がありそうです。
その他①FireDucks
NECが開発するライブラリで、pandas互換性をもたせたAPIの提供を目指しています。
今回この記事を書こうと思った理由のうちの一つでしたが、インストール時にうまくいかず、よくみたらドキュメントに以下のように書いてありました。
FireDucks is currently available for Linux (manylinux) on the x86_64
architecture and it can be simply installed using pip as follows:
今回私が用意した環境が M1 Mac だったので、次回以降に検証してみようと思います(また、執筆時点でPython 3.13は未対応でしたが、M1さえクリアできればバージョン落としてでも試してみたかったところはあります。)。
公式にも記載の通り、 import fireducks.pandas as pd で既存のpandasでつくったツールを置き換えられるのは魅力ではあります。
その他②PySpark
Sparkを利用するためのPythonAPIです。
AWS Glueの裏で使われているのもPySparkであり、大規模なデータを扱うことができますが、いかんせん環境に手間がかかります。
そのため、今回はPySparkも見送ります。
その他③ Vaex
pandasよりも大規模なデータを扱うことに優れたライブラリで、数十倍〜の計算が高速に可能なようです。Daskと同じように通常メモリに乗り切らないデータでも扱うことができます。
本家をみるとPytho3.10までの対応のようだったのと、実際私の3.13.1環境ではうまく入らなかったため、今回こちらも見送ります。うまくいく方法あれば、また試してみたいところです。
AWS Lambdaに乗せてみよう
すみません、乗せて完全に動かすまではやりませんが、大事なのは依存関係のあるライブラリをしっかり読めるかです。
分析に使うライブラリはどうしても複数の依存関係が効いてしまい、大きくなりがちです。
一部のライブラリはzip圧縮するときに一緒にいれれば動くこともありますが、今回はそうは素直にいきません。
例えばpandasに対して実際にやってみると、次のようになります。
zip: libraries
zip -j lambda_pandas.zip handler.py
libraries:
@if [ ! -e tmp ]; then\
mkdir tmp;\
fi
@if [ -e lambda_pandas.zip ]; then\
rm lambda_pandas.zip;\
fi
poetry export --format requirements.txt --output requirements.txt --only test_pandas
pip install --no-cache-dir -r requirements.txt -t ./tmp
@if cd ./tmp; then\
zip -r9 ../lambda_pandas.zip .;\
fi
@rm -r ./tmp
@rm requirements.txt
import pandas as pd
def main():
pass
def lambda_handler():
main()
これをLambdaですると、次のようなエラーがでます。
{
"errorMessage": "Unable to import module 'handler': Unable to import required dependencies:\nnumpy: Error importing numpy: you should not try to import numpy from\n its source directory; please exit the numpy source tree, and relaunch\n your python interpreter from there.",
"errorType": "Runtime.ImportModuleError",
"requestId": "",
"stackTrace": []
}
今回はnumpy周りでエラーが出ていますが、依存関係が多いものなどだと面倒です。
これの解決するのためLambda Layerを自作してもいいですが、それもちょっとしたツール目的で用意するには大変です。そのため、公開されているツールを使うことにします。
AWSが公開しているものもありますが、有志の方々によるものであれば keithrozario/Klayers
などが有名かと思います。
ちなみにKlayersだとpandasは当然ありますが、今回紹介した中だとPolarsも提供されています。
実際にAWSで使うことを考えると、この2つになりそうな気がします。
もちろん他のライブラリ用に公開されているLambda Layerを使ったり、自作で用意するのもありです。
まとめ
実際に深く使い分けれられていないので、試せた範囲と調べた範囲ですが、主観込みで比較したライブラリは以下のような次第です。?は不明か、おおよそこんな感じかなという感想程度のレベルです。目的が、さほど大きくないデータをとりあえず分析して新しいものをみたい、という感じだったのと、今回挙げたライブラリがpandasよりも多くのデータを早く効率的に扱うことを目的としたものが多かったため、どうしてもpandas強いよね、という結果になっています。
| ライブラリ | pandas | dask | Polars | modin | FireDucks | PySpark | vaex |
|---|---|---|---|---|---|---|---|
| ローカルでの はじめやすさ |
◯ | ◯ | ◯ | △ | ? | ☓ | ? |
| 小規模分析の 使い勝手 |
◯ | △? | △?~◯? | △? | ? | △ | ? |
| Lambdaでの 利用しやすさ |
◯ | △? | ◯? | △? | ? | ☓ | ? |
| 総合評価 | ◯ | △? | ◯? | △? | ? | ☓ | ? |
実際に使うケースまで考えてみましたが、クイックに使えてツールにも組み込みやすいという立ち位置だと、やはりpandasは強かったです。
ただ、使い勝手などをみてもPolarsは候補になりそうだなというのはわかったので、今後こっそり使っていってみようと思います。