この記事はヤフー株式会社の2018年新卒有志でつくるYahoo! JAPAN 18 新卒 Advent Calendar 2018の5日目の記事です。
前回は @saike1119 さんによる新卒エンジニアが個人的に実務で役に立った本とかを紹介してみるでした。
次回はYoshiki Satodateさんによる一歩引いて「何故」を考えるです。
こんにちは。2018年新卒エンジニアの橘です。
師走に入り、大掃除を意識している方も少なくないと思います。しかし、大掃除した後の奇麗な状態を維持するのは意外と難しい、という方もいらっしゃるのではないでしょうか。実際僕は奇麗な状態を維持することが非常に苦手で、すぐ机や床の上に物が散乱していきます…
僕がこの問題で悩んでいたところ、半年ほど前に以下のような機能がGoogle Cloud Vision APIから提供され始めたことを見つけました。
今週の GCP 7/30
[Beta] Cloud Vision API object localizer w/ bounding boxes (訳注: Cloud Vision API で画像内の複数オブジェクトを検出し、それぞれの境界となる矩形を取得可能になりました。)
提供され始めた機能は、GoogleのCloud Vision APIにObject Localizerという画像の中に映る物体の種類と場所を識別する機能です。(Object Localizer 公式ドキュメント)
執筆地点ではObject Localizerはまだβ版ですが、これを使えばモノを散らかしたらすぐ注意してくれるIoTシステムを実現できるのではないか、何もしないより少しくらい片づけることができるのではないか、と思い立ちました。
以上のことから、今回は実際にお片付け支援IoTを作ってみようと思います。
注意 : この内容は筆者が実際に実装した方法のご紹介です。最適な実装とは異なる場合がありますがご了承ください。また、最低限のセキュリティなどには配慮している所存ではありますが、実装される際は各自の責任でお願いいたします。本記事で述べる実装は筆者が個人として実装したものであることをご留意願います。
システム構成
今回のシステム構成はおおよそ以下の通りです。
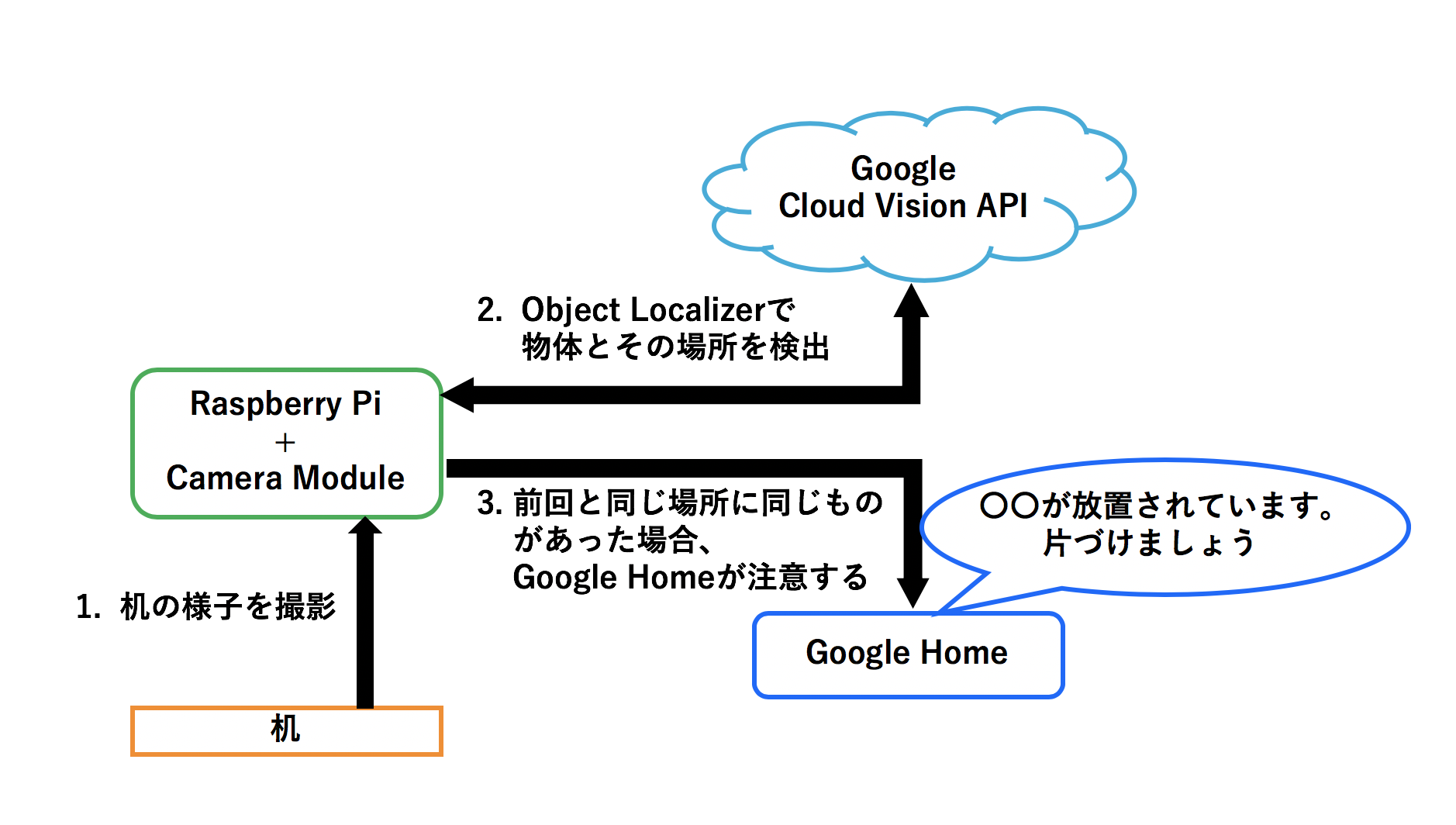
使用するのはRaspberry Pi + Camera Module, Google Cloud Platform(Cloud Vision API, Cloud Translation API), そしてGoogle Homeです。
Raspberry Piで撮影した画像をObject Localizerに通し、机の上に乗っているモノと場所を識別し、保存しておきます。一定時間経過後、再び画像を撮影、識別し、近い場所に同じモノが写っていた場合、「モノを放置している」とみなし、Google Homeが音声で注意してくれる、といったシステムを目指します。
実装の前に…Google Cloud Platformを使用する下準備
基本的には公式入門ガイドに従って下準備を進めていきます。
今回の実装に当たって必要な手順は
- GCPログイン
- 課金情報の有効化とCloud Vison API, Cloud Translation APIの有効化
- GCloud(コマンドラインツール)のインストール
- サービスアカウント作成、鍵作成・取得
- 取得した鍵を使用したサービスアカウントに対する認証
です。公式の入門ガイドなどが充実しているため、本記事では1. ~ 4.の手順については割愛させていただきます。
サービスアカウントに対する認証
実際にAPIを有効にするため、以下のコマンドで鍵を使って認証します。
$ gcloud auth activate-service-account --key-file <鍵ファイル>
コマンドラインで実際にAPIを呼び出す
まず、Cloud Vision APIのドキュメントVision API リクエストを作成するに登場する犬の画像 (https://cloud.google.com/vision/docs/images/faulkner.jpg) を拝借させていただいて、実際にObject Localizerを実行します。
手順は以下の通りです。curlコマンドの内部で実行しているgcloud auth application-default print-access-tokenが環境変数 GOOGLE_APPLICATION_CREDENTIALSを使用してサービスアカウントの鍵ファイルを参照するため、事前に環境変数の定義が必要です。
$ export GOOGLE_APPLICATION_CREDENTIALS=<鍵ファイル>
$ curl -X POST \
-H "Authorization: Bearer "$(gcloud auth application-default print-access-token) \
-H "Content-Type: application/json; charset=utf-8" \
--data "{
'requests': [
{
'image': {
'source': {
'imageUri': 'https://cloud.google.com/vision/docs/images/faulkner.jpg'
}
},
'features': [
{
'type': 'OBJECT_LOCALIZATION'
}
]
}
]
}" "https://vision.googleapis.com/v1p3beta1/images:annotate"
# 結果
{
"responses": [
{
"localizedObjectAnnotations": [
{
"mid": "/m/0bt9lr",
"name": "Dog",
"score": 0.98962307,
"boundingPoly": {
"normalizedVertices": [
{
"x": 0.13500002,
"y": 0.46535298
},
{
"x": 0.585,
"y": 0.46535298
},
{
"x": 0.585,
"y": 0.9850001
},
{
"x": 0.13500002,
"y": 0.9850001
}
]
}
}
]
}
]
}
実際に実行すると、JSON形式で"name": "Dog"と犬を検出したこと、"boundingPoly"で画像内の相対位置(矩形の頂点4つ)が検出できたことがわかります。
また今回は最終的にGoogle Homeに日本語で発話してもらうため、結果の翻訳が必要です。そのため同様にCloud Translation APIも呼び出します。
$ curl -s -X POST -H "Content-Type: application/json" \
-H "Authorization: Bearer "$(gcloud auth application-default print-access-token) \
--data "{
'q': 'dog',
'source': 'en',
'target': 'ja',
'format': 'text'
}" "https://translation.googleapis.com/language/translate/v2"
# 結果
{
"data": {
"translations": [
{
"translatedText": "犬"
}
]
}
}
正しく犬と返ってきます。
これで準備は整いました。それでは実際に実装に移ります。
お片付け支援IoTの実装
今回は要件を満たすために、Google Cloud Platformの他に以下のライブラリ/コンポーネントを使用します。
- TinyDB (直前の識別結果を保存するために使用します)
- google-home-notifier (Google Homeに発話してもらうために使用します)
- picamera (Raspberry Pi Camera Moduleの制御をするために利用します)
また今回使用言語はPython3(pyenv不使用)、とNode.js, OSはRaspbian Stretchを使用します。
環境構築
今回の実装に必要なライブラリ、コンポーネントをインストールします。
# Google Cloud Platformのクライアントライブラリと依存関係
$ python3 -m pip install pillow
$ python3 -m pip install --upgrade google-cloud-Vision
$ python3 -m pip install --upgrade google-cloud-translate
# TinyDB
$ python3 -m pip install tinydb
# picamera
$ sudo apt-get install python3-picamera
google-home-notifierですが、今回は少し特殊な環境構築の手順をとります。理由は、https://qiita.com/ezmscrap/items/24b3a9a8548da0ab9ff5 などに記述されているように、Google側の仕様変更によりモジュールの一部に手を加えなければならないことと、どういう訳か普通に$ npm install google-home-notifierコマンドで環境構築して実行すると 日本語じゃない何か (何語かわからなかった)でGoogle Homeが話し始めたためです。
そのため今回は以下の手順で環境構築します。(ただし基本的には公式のREADMEに従います)
# Node.jsのインストール
$ curl -sL https://deb.nodesource.com/setup_10.x | sudo -E bash -
$ sudo apt-get install nodejs
# 依存関係のインストール
$ sudo apt-get install git-core libnss-mdns libavahi-compat-libdnssd-dev
# リポジトリをクローンしてインストール
$ git clone https://github.com/noelportugal/google-home-notifier
$ cd google-home-notifier
$ npm install
# Googleの仕様変更部分を修正
$ wget https://raw.githubusercontent.com/zlargon/google-tts/master/lib/key.js
$ cp key.js node_modules/google-tts-api/lib/key.js
その後、READMEに記述されている通り、node_modules/mdns/lib/browser.jsの一部を書き換えます。
以上で環境構築は完了です。
実装:PythonスクリプトからGoogle Cloud Platformを呼び出す
今回作成したコードの全文は別途GitHubにアップロードしてありますのでご参照ください。
まずは画像を受け取ってCloud Vision APIとCloud Translation APIを呼び出し、結果を取得するスクリプトを書いてみます。
localize_objects()で、指定されたパスの画像を読み込み、Cloud Vision APIへリクエストを送信し、結果を返します。
from google.cloud import vision_v1p3beta1 as vision
def localize_objects(path):
# Client API 初期化
client = vision.ImageAnnotatorClient()
# 画像読み込み
with open(path, 'rb') as image_file:
content = image_file.read()
# Object Loclizer へリクエストを送信し、結果を取得
image = vision.types.Image(content=content)
objects = client.object_localization(image=image).localized_object_annotations
# 以下省略
objects で取得した結果を、人間にもわかりやすくするためview_results()で実際の画像に矩形とラベルを描画します。
from PIL import Image as im
def view_results(path, save_dir, objects):
# 画像表示
im = Image.open(path)
(im_w, im_h) = im.size
draw = ImageDraw.Draw(im)
for object_ in objects:
poly_xy =[]
for vertex in object_.bounding_poly.normalized_vertices:
poly_xy.append((vertex.x * im_w, vertex.y * im_h))
# 対象物の周辺に多角形を描画
draw.polygon(poly_xy, outline=(255, 0, 0))
text_x = poly_xy[0][0] + (im_w * 0.05)
text_y = poly_xy[0][1] - (im_h * 0.03)
# ラベル付与
draw.text((text_x, text_y), object_.name , fill=(255, 0, 0))
# 画像保存
now = datetime.datetime.now()
save_path = save_dir + "result_" + now.strftime("%y%m%d%H%M%S") + ".jpg"
im.save(save_path)
任意の英語テキストを日本語に変換できるよう、translate_ja() を用意します。
from google.cloud import translate
def translate_ja(text):
# Client API 初期化
translate_client = translate.Client()
# 翻訳
translation = translate_client.translate(
text,
target_language='ja')
result = translation['translatedText']
# 以下省略
データを保存して、前回の分析結果と比較する
ここではTinyDBを利用します。
今回は書き込み、読み込み、全削除の3つの機能を用意します。
from tinydb import TinyDB, Query
def save_data(detected_objects_json):
db = TinyDB("detected.json")
db.insert_multiple(detected_objects_json)
def get_saved_data(search_key):
db = TinyDB("detected.json")
query = Query()
searched = db.search(query.name == search_key)
return searched
def remove_all():
db = TinyDB("detected.json")
db.purge()
TinyDBにアクセスするメソッドを書いたら、前回に識別されたデータと似た位置に同じオブジェクトがあるかチェックするロジックを書きます。矩形の位置がおおよそ同じか判定するために今回はJaccard係数を使って判定します。今回はJaccard係数が0.8を超えたらおおよそ同じ位置にモノが置かれていると判定することにします。
# 矩形の重なり具合をチェック
def check_analogy(objects_json1, objects_json2):
# 省略
# 前回に識別されたデータと似た位置に同じオブジェクトがあるかチェック
def check_analogy_object_from_past(detected_objects):
detected_json = convert_to_objects_json(detected_objects)
analogy_objects = []
for d in detected_json:
# 前回のデータから同じ名前のオブジェクトを取得
past_json = get_saved_data(d["name"])
for p in past_json:
analogy = check_analogy(d,p)
if analogy > 0.8:
analogy_objects.append(d)
# DB内のデータを書き換え
remove_all()
save_data(detected_json)
return analogy_objects
Google Homeに発話してもらう
任意のテキストをGoogle Homeに発話してもらいます。この機能はほとんど公式のREADME中のUsageと同様のコードで実現できます。
var googlehome = require('./google-home-notifier');
var language = 'ja';
googlehome.device('Google Home', language); // Change to your Google Home name
// or if you know your Google Home IP
//googlehome.ip('192.168.1.1', language);
var msg = 'こんにちは。世界。';
if(process.argv.length > 2){
msg = process.argv[2];
}
googlehome.notify(msg, function(res) {
console.log(res);
});
アプリケーションとして仕上げる
アプリケーションとして実行するためには、まず画像を撮影する必要があるので、Raspberry PiのCamera Moduleを操作するメソッドtake_photo()を作ります。
import picamera
# Raspberry Piで撮影
def take_photo():
# セットアップ、解像度を(1280, 720)に
camera = picamera.PiCamera()
camera.resolution = (1280, 720)
# ファイル名セット
now = datetime.datetime.now()
pname = "/home/pi/img/"+ now.strftime("%y%m%d%H%M%S") + ".jpg"
triname = "/home/pi/img/"+ now.strftime("%y%m%d%H%M%S") + "_tri.jpg"
# 撮影
camera.capture(pname)
# 以下省略
最後に、今まで実装した各コンポーネントをつなげて、完成させます。
import localizer
import analogy_detector
import sys
import subprocess
import time
def execute(imgpath, save_dir):
# GCP Object Loclizerを呼び出して結果を取得
detected_objects = localizer.localize_objects(imgpath)
# 結果表示
localizer.view_results(imgpath, save_dir, detected_objects)
# 前回実行時の分析結果と似たオブジェクトがあるか判定
analogied_objects = analogy_detector.check_analogy_object_from_past(detected_objects)
for ao in analogied_objects:
# 名前を日本語に変換
name_ja = localizer.translate_ja(ao["name"])
msg = "{:.2f}".format(ao["vertices"][0]["x"]) + "," + "{:.2f}".format(ao["vertices"][0]["y"]) + "付近の" + name_ja + "が放置されています。片づけましょう。"
cmds = ['node', 'google-home-notifier/notify.js', msg]
print(msg)
# google-home-notifierを起動
subprocess.call(cmds)
# 連続して発言する場合、次の発言が前の発言にかぶってしまうため一定時間待機
time.sleep(6)
if __name__ == '__main__':
if len(sys.argv) < 2:
print("Err : save_dir is not set.")
sys.exit(1)
save_dir = sys.argv[1]
execute(take_photo(), save_dir)
実行する
ここまで来たら、Raspberry PiとCamera Moduleを撮影場所に設置します。
幸いなことに、僕の家の居間には洗濯物を干すための竿が天井からぶら下がっているため、ここにRaspberry PiとCamera Moduleを設置し、真上から撮影できるようにします。
ちなみに上から撮影した画像は以下の通りです。今回は本、財布、ペットボトル、はさみ、お皿を机の上に放置します。

物を放置したら、実際にプログラムを実行します。
$ pytnon3 application.py /path/to/save_dir
最初は前回実行時の分析結果を持っていないため、撮影しても何も起こりません。
もう一度同じコマンドを実行します。するとGoogle Homeが以下の通り発言しました。
0.34,0.64付近のはさみが放置されています。片づけましょう。
0.60,0.10付近のボトルが放置されています。片づけましょう。
0.36,0.39付近のプレートが放置されています。片づけましょう。
0.36,0.39付近のキッチン用品が放置されています。片づけましょう。
0.36,0.39付近の食器が放置されています。片づけましょう。
Google Homeが注意してくれました。
ここでObject Localizerはどのように物体を認識したか確認してみます。

認識した物体は3つしかないという結果になっています。あれ? と思いましたが、よく見てみると同じ場所のオブジェクトに対して「プレート」「キッチン用品」「食器」と三つも結果を返しています。どうもObject Localizerはある程度確からしいと思った候補を全て出す仕様となっているようです。複数候補があるオブジェクトに対しては、このままだとGoogle Homeが同じものに対して何回も発言してしまうので、防ぎたい場合はObject Localizerの返却結果にある score を利用して、同一地点では最もscoreが高いもののみを識別結果にするなどの対策をすると良いと思います。
一方で本と財布は認識されませんでした。本や財布はものによって形や色が違うためか、まだ認識するのは難しいようです。
また、実際にアプリケーションとして動かす場合、定期的に撮影してもらわないと困るので、crontabで
*/10 8-22 * * * /usr/bin/python3 /home/username/18advent/application.py /path/to/save_dir
のように定義をしておくと実用的になると思います。
まとめ
今回はGoogle Cloud Vision APIとGoogle Homeを使ってお片付け支援IoTをつくり、実際に動かしてみました。
音声によるプッシュ通知は、自分が他のことに注意を傾けていても聞くことができるので「そういえば片付けてなかった」ということに気づくことができるため、お片付けをするきっかけを作ってくれました。
また、実は筆者自身Google Cloud Vision APIを使うのは初めてだったのですが、ドキュメントなども充実しており、初めての人も比較的触りやすいので、ぜひチャレンジしてみてはいかがでしょうか。
あとがき
実際にこのシステムを実行するにあたり、撮影画像を記事に載せるためにいつもに増して机を掃除しました。僕がお片付けをするにはシステムで支援するのも一つの手段ですが、「人に部屋を見せる」というプレッシャーを与える方が効果的なようです…
参考文献
- 複数のオブジェクトを検出する https://cloud.google.com/vision/docs/object-localizer
- Cloud Vision API 入門ガイド https://cloud.google.com/vision/docs/how-to?hl=ja
- Cloud Vision API に対する認証 https://cloud.google.com/vision/docs/auth?hl=ja
- GoogleCloudPlatform/python-docs-samples
https://github.com/GoogleCloudPlatform/python-docs-samples/blob/277d2678017898ade4a4c2c3024df4dba22cb199/vision/cloud-client/detect/beta_snippets.py - Google Home開発入門 / google-home-notifier解説 https://qiita.com/SatoTakumi/items/c9de7ff27e5b70508066
- 矩形領域同士の一致度が欲しい http://www.thothchildren.com/chapter/5b06d94fb8dc30181ec7a805
- 矩形の重なりを求めるプログラム http://noriok.hatenablog.com/entry/2012/02/19/233543