はじめに
去年のアドカレ以来の投稿になるという体たらくを発揮してしまいました。
12月なので、最近よく話題に上がるsnowflakeを触ってみようと思います。
ロゴもすごい。12月感すごい。

題材
フリートライアル用ハンズオン資料が公開されていますので、これを題材に進めます。
HANDS-ON LAB GUIDE FOR SNOWFLAKE FREE TRIAL
やること
ハンズオンのMODULE 1~5を中心に、ざっくり以下をやってみます。
- snowflake上でテーブル作成
- AWS S3上にあるcsvファイル郡をsnowflakeにロード
- snowflakeのコンピュートノード(ウェアハウス)を利用して分析
狙い
以下基本的な概念、インターフェースや流れを掴む所を目指します。
- テーブル
- ステージ
- ウェアハウス
1. トライアルサインアップ
以下URLよりトライアルサインアップしてください。
https://signup.snowflake.com/?_l=ja

以下の通り選択して作成します。
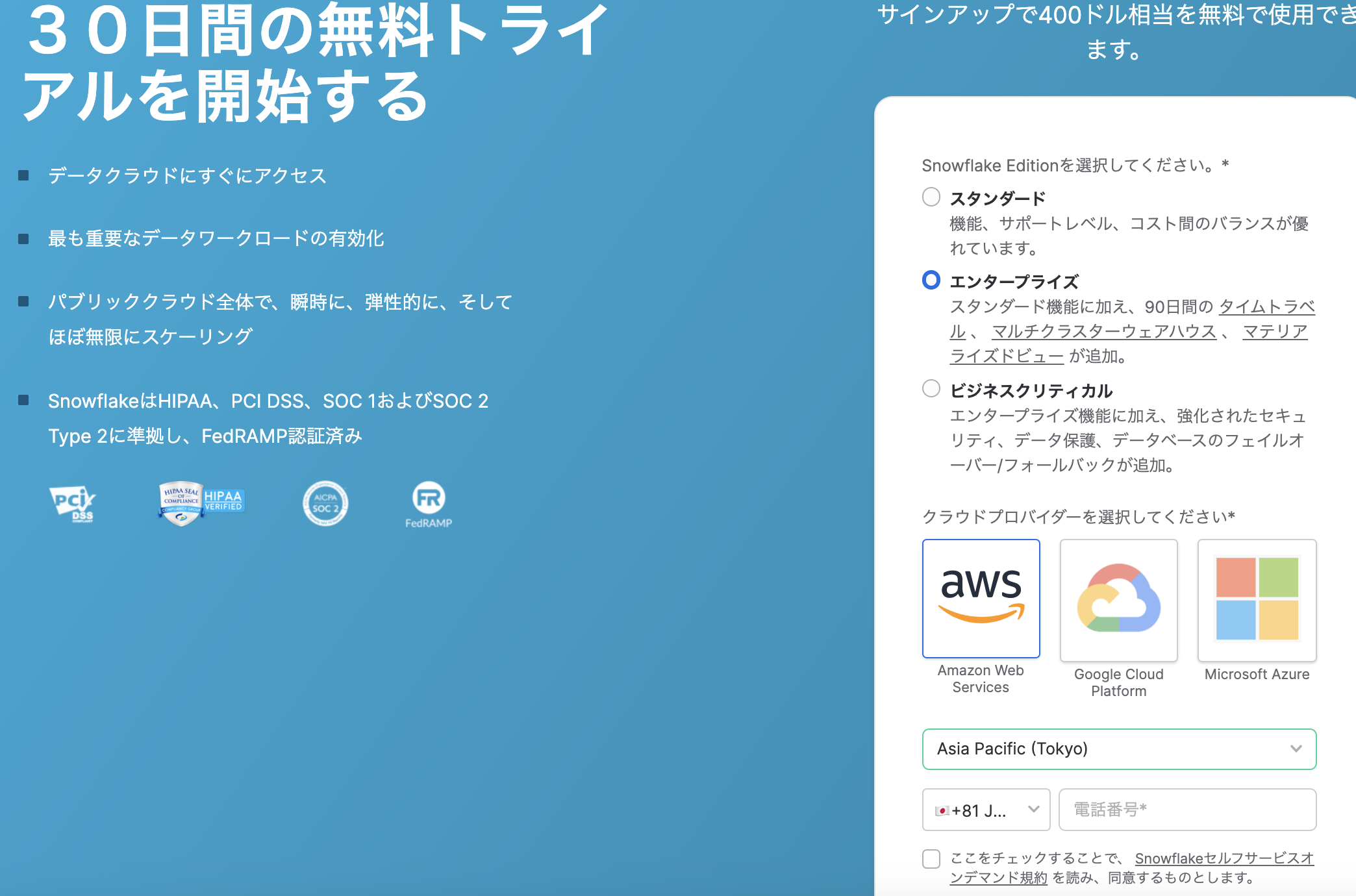
UIが表示されました。

ここでURLが以下になってるのに気付きます。
https://(account).ap-northeast-1.aws.snowflakecomputing.com/
snowflakeはクラウドプラットフォーム(AWS/GCP/Azure)で稼働します。
これは既に別のサービスがクラウド上でホスティングしている(例えばAWSのap-northeast-1を中心にサービス稼働している)場合、同じクラウドプラットフォーム上でsnowflakeをホストできることを意味します。
なんとなくピンとくるかもしれませんが、これはデータ転送料金など関係してきそうですね。
ドキュメント: サポート対象のクラウドプラットフォーム
2. UI確認/準備
データベース をクリックしてみましょう。
データベースタブには作成した、もしくはアクセス権限を持っているデータベースに関する情報が表示されます。
フリートライアル環境にいくつかのデータベースが既に存在していますね。
(ラボではこれらは使用しませんでした)
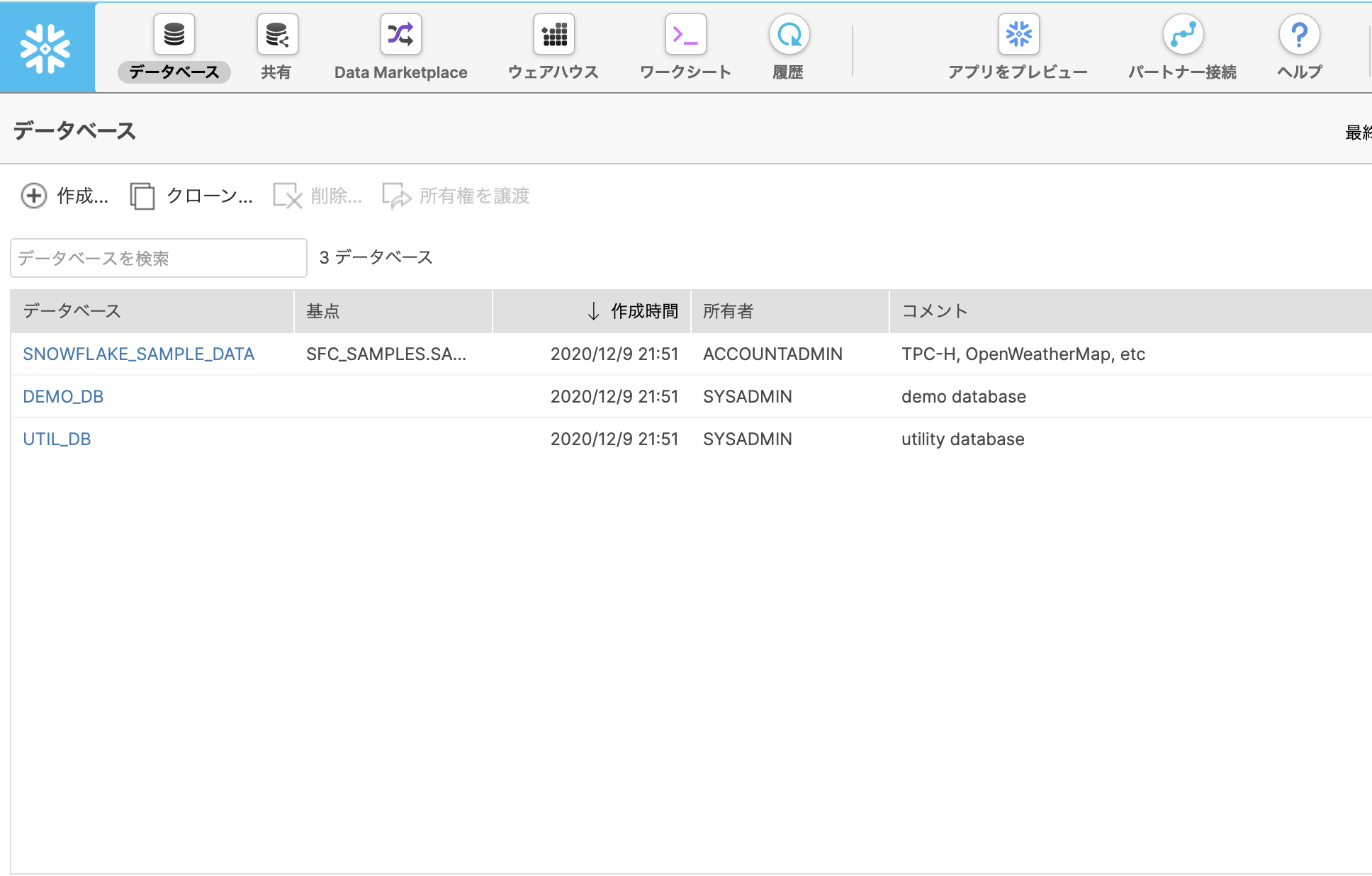
ワークシート は SQLを実行、結果を確認する画面です。
基本的にこの画面でSQLを実行しながら進めていきます。

ラボで利用するsqlファイルを以下からダウンロードしましょう。
lab_scripts_free_trial.sql
ワークシート の ▼ を選択し、 スクリプトをロード から、DLしたsqlファイルを選択します。

SQLが表示されました。このSQLを一部選択 -> 実行を繰り返してラボは進みます。

3. データロード
3-1. データベース作成
このラボには以下のシナリオがあるようです。
ニューヨーク市にある公共自転車共有システム
CitiBikeのデータを分析しライダーに最適なサービスを提供する方法を理解したい。
まずはデータベース Citibike を作成しましょう

ロードしたSQLの以下部分のみ選択し、 実行をクリックします。
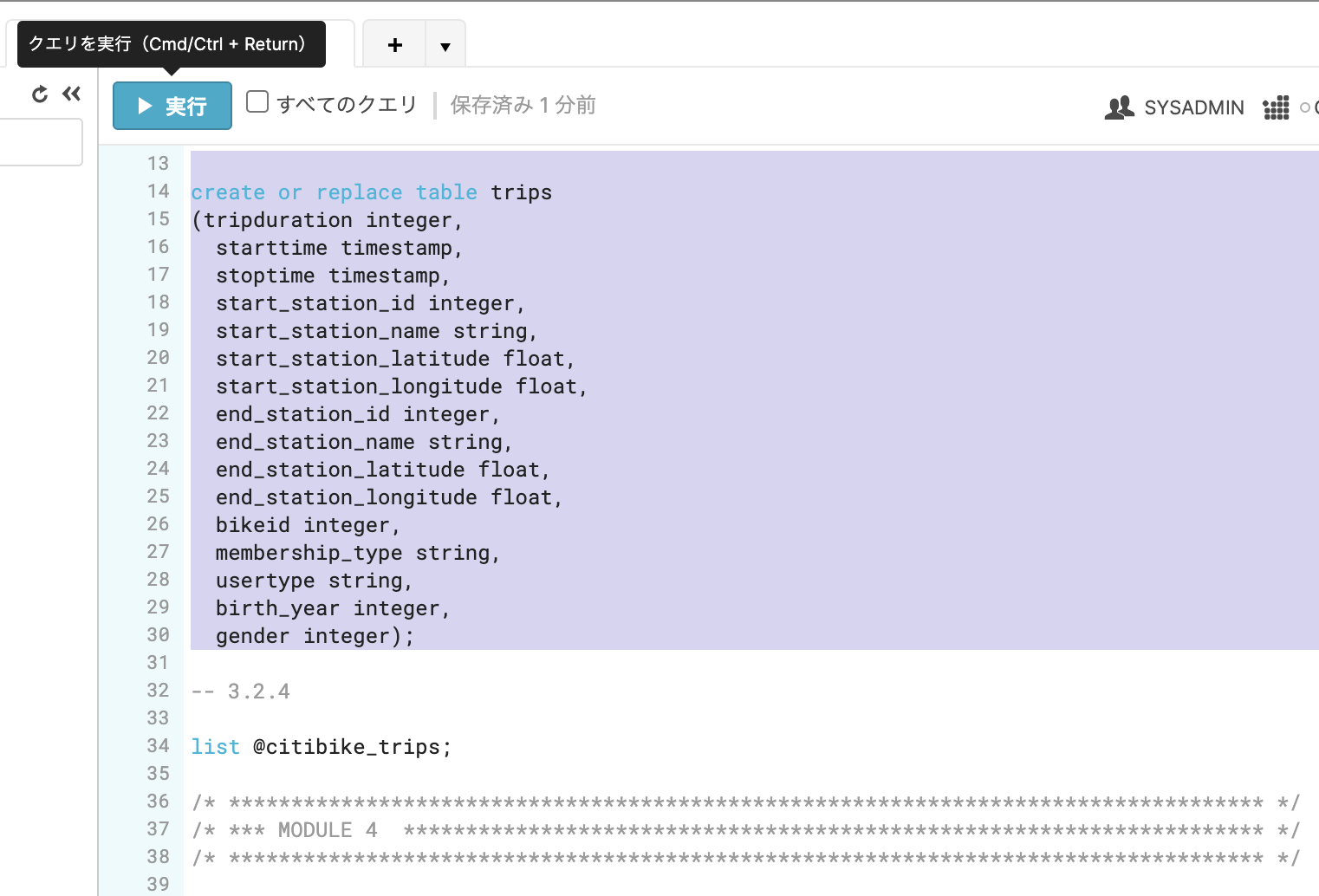
create or replace table trips
(tripduration integer,
starttime timestamp,
stoptime timestamp,
start_station_id integer,
start_station_name string,
start_station_latitude float,
start_station_longitude float,
end_station_id integer,
end_station_name string,
end_station_latitude float,
end_station_longitude float,
bikeid integer,
membership_type string,
usertype string,
birth_year integer,
gender integer);
結果が表示されました。成功したようです。

データベース のテーブルを見ると、確かにテーブルが作成されています。
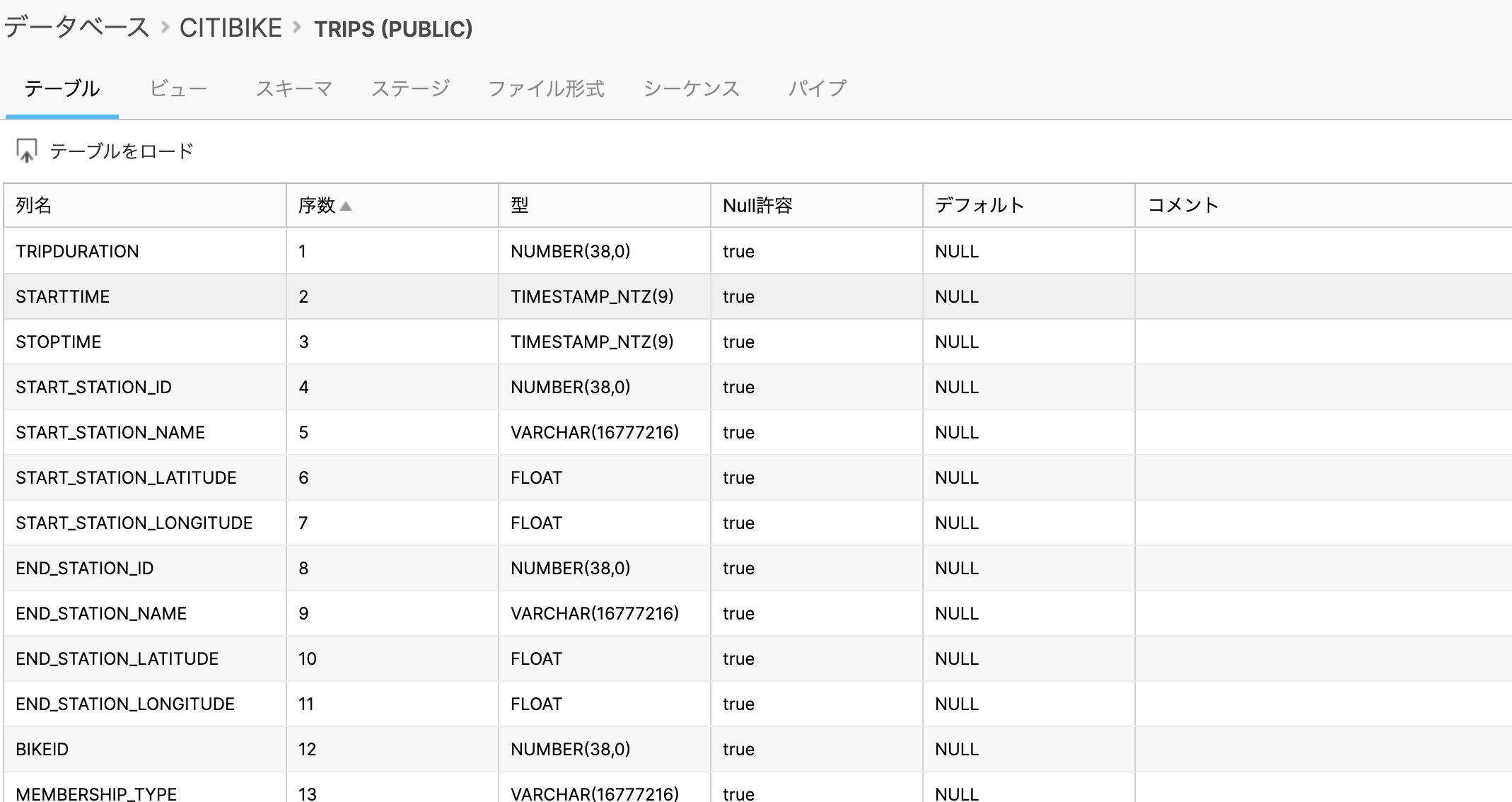
3-2. ステージ設定
このテーブルに外部に存在するCitibike利用ユーザのトランザクションデータをロードします。
データはpublicなs3 bucket上に存在するようです。
そのためにはステージ という設定を作成します。

ステージを選択できるので、 S3を選択します。

名前: citibike_trips
スキーマ名: PUBLIC
URL: s3://snowflake-workshop-lab/citibike-trips

ステージ設定ができました。(まだ実際のロードはしていません。)

ワークシート で以下SQLを実行してstageの中を覗いてみましょう。
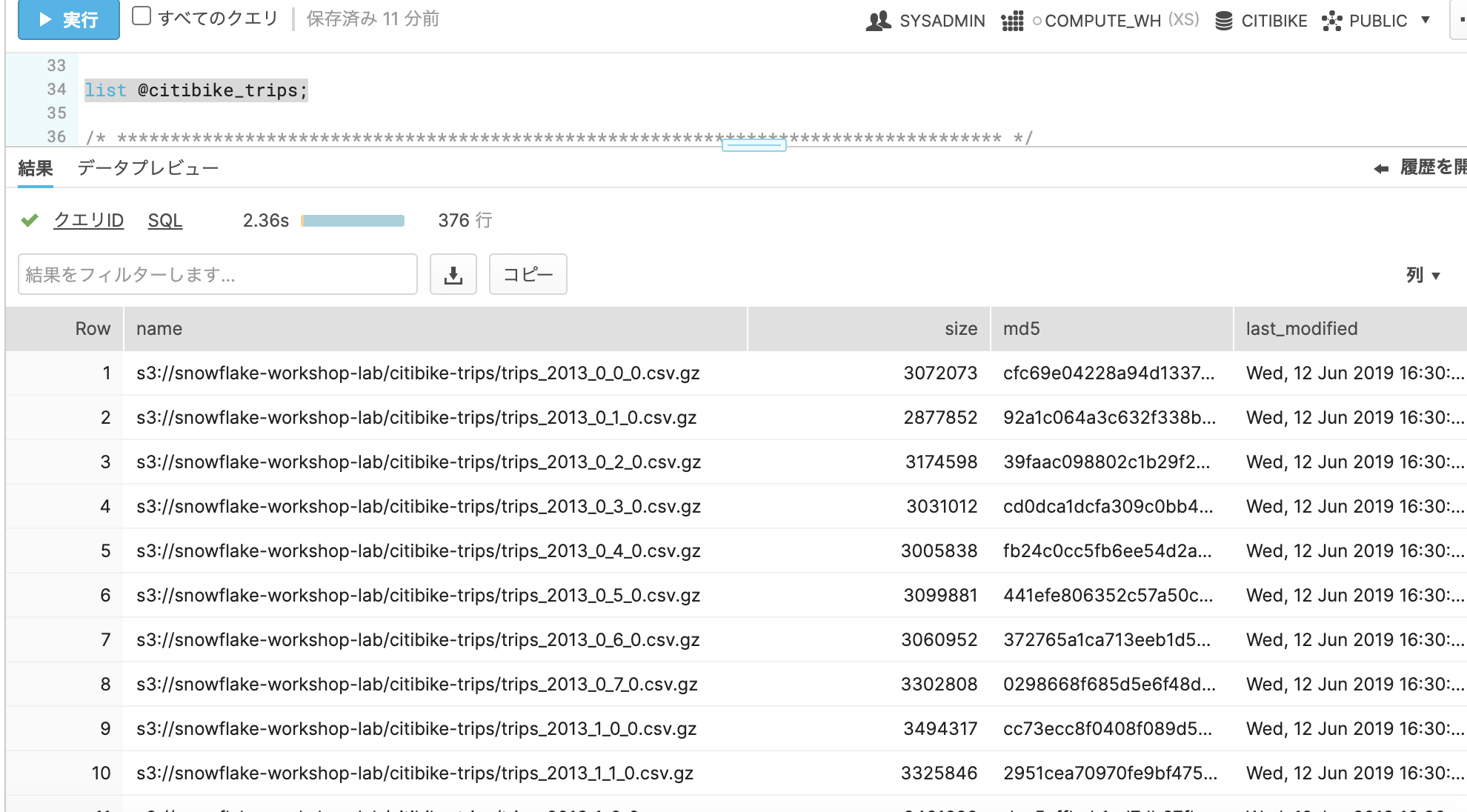
list @citibike_trips;
たくさんのcsv(gz圧縮)が存在することがわかります。
3-3. ファイル形式設定
続いてより詳細なcsv形式について設定します。
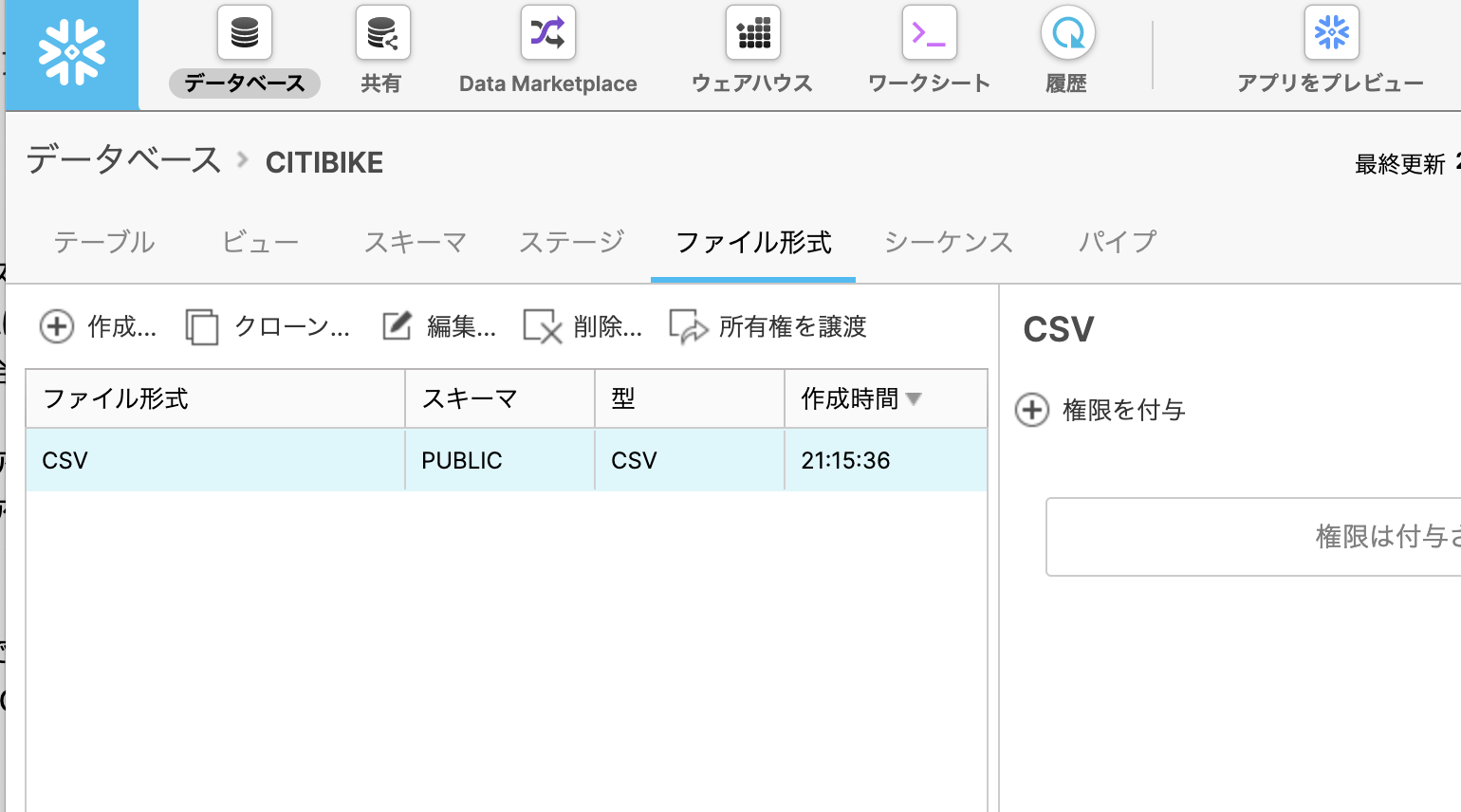
ファイル形式 タブにて、以下の通り設定します。

(スクロール下の設定)

ファイル形式設定も完了しました。(まだまだ実際のロードはしていません)
3-4. ウェアハウス作成
続いて実際にcsvをsnowflakeにロードしてみます。
ロードするにはコンピューティングリソースが必要です。
Snowflakeのコンピュートノードは ウェアハウス と呼ばれ、ワークロードに応じて動的にスケールできます。
ウェアハウス タブを選択すると、既にデフォルトのウェアハウスが存在しているようです。
選択して構成 をクリックしてみます。

サイズなど、コンピューティングリソースの設定ができるようです。
サイズを Sと設定します。

3-5. COPYコマンド実行
ワークシート に移動します。
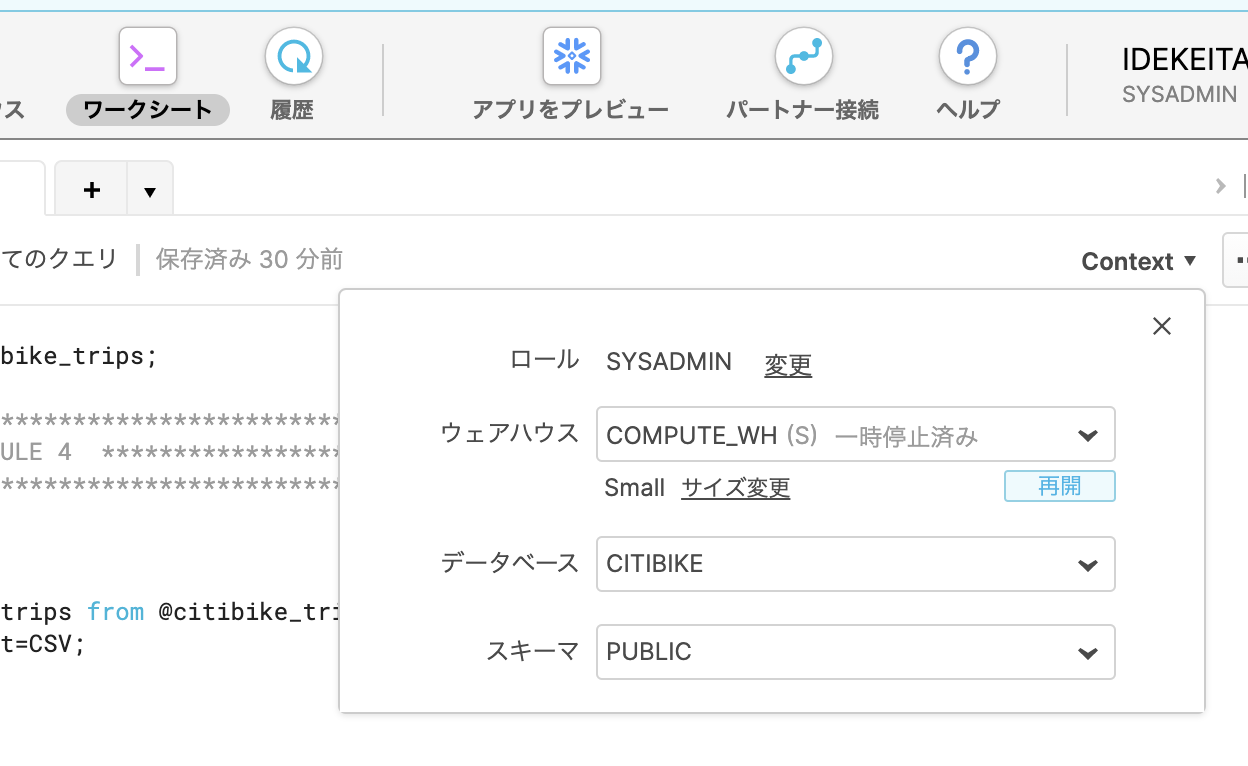
SQL実行画面の Context をクリックすると、ウェアハウス が確認でき、サイズも S となっています。
SQL実行時にどのウェアハウス (コンピューティングノード) で実行するかを選択できるようですね。
では、以下SQLで実際にデータをロードします。
copy into trips from @citibike_trips file_format=CSV;
ロードできました。
実行後、履歴 タブに移動すると実行時間やスキャンサイズなど、クエリの詳細がわかります。

以下にて、実際にテーブルにデータが存在していることがわかります。
select * from trips limit 20;

4. 分析
では、分析開始です。
1時間ごとの統計をだしてみます。
select date_trunc('hour', starttime) as "date",
count(*) as "num trips",
avg(tripduration)/60 as "avg duration (mins)",
avg(haversine(start_station_latitude, start_station_longitude, end_station_latitude, end_station_longitude)) as "avg distance (km)"
from trips
group by 1 order by 1;
サイズ S のウェアハウスで実行しました。
44,295行 を 84ms で結果が返ってきています。

サイズを L に変更してもう一度実行してみました。
84ms -> 62ms となりました。
サイズに応じてスケールできていますね。

おわりに
snowflakeのハンズオンを題材にさわりだけやってみました。
まだまだ色々できそうですが、概念レベルは掴めた感じがします。
もう少し触ってみようと思います。