一年ぶりにQiita書きます。M1のmoffyです。
二日目のリレーを担当します。もう12月ですね。時が経つのが早過ぎてびっくりですね。
昨日は@hcpmiyuki先輩の【Face Swapping】推しとの思い出2022を"作る"でした。画像系のAIの技術の進化に度肝を抜かれました。いやほんとに2年前こんなのなかったよ!?そのうち動画でも同じようなことができそうになるのかな?
さて、今回は大規模なシステムてどうやって作っていくんだろう?ていう疑問に対して参考になりそうな記事を紹介します。
「そんなん知ってるわ」というつよつよエンジニアさんはお手柔らかに。
明日はk8sでの実践編の記事が出ます。たぶん?
目次
All for One
この章では大規模なシステムを作る考え方の説明と基本的なwebシステムの構造について紹介します。
大規模なシステム。多くのユーザがいて毎日あなたの作ったシステムに利用してくれる。これってすごく幸せなことだけど毎秒10000リクエスト飛んできたらどうしますか?
どうにかしてこのリクエストに耐えれるようにしたい!でも具体的に何をすれば良いか全くわからない...
多くのリクエストに耐えられるシステムの考え方と取り組みについて紹介していく。
考え方
まずは一人のユーザのためのシステム構成(アーキテクチャ)を考える。
そこから大量のリクエストに耐えられるように少しずつシステムを変化させていく。
一人のユーザのためのシステム構成例
非常にシンプルなシステムアーキテクチャ。登場するコンポーネントは3つでユーザとDNSサーバとWEBサーバだ。
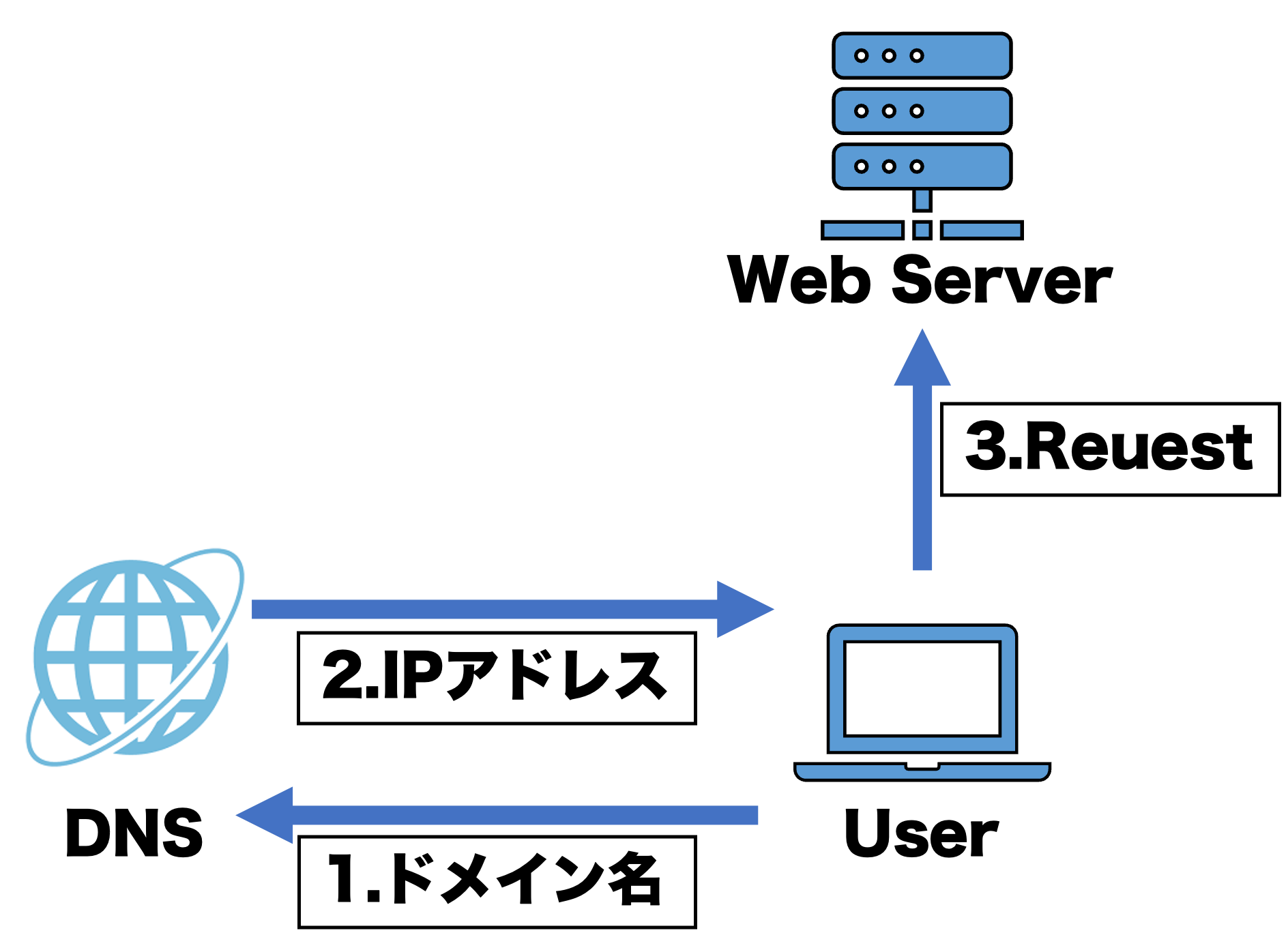
UserはDNSサーバにドメイン名を送ってアクセスしたいWEBサーバのIPアドレスを取得する。その後IPアドレスに直接リクエストを送信してサービスにアクセスできる。
ここに登場しているWEBサーバはサービスのアプリケーションを提供する役割ととデータを保存するDBの役割を兼務している。要するにこのサーバはサービスの全ての役割を担当している。
個人開発中のアプリのアーキテクチャは大体こんな感じだ。
このサービスへのリクエスト数が増えたら、アーキテクチャの問題点は主に二つある。一つ目は一つのサーバで捌けないほどの量のリクエストや処理能力を超える重い処理の要求が来たら動作が遅くなったり応答しなくなることだ。二つ目は何らかの原因でサーバにエラーが出てしまった時、大体のサーバがないので全くサービスを提供できなくなることだ。
これらの問題を解決したい。まずはWEBアプリケーションの機能とデータベースの機能を分割して、アーキテクチャを拡張しやすいようにする。
ScaleUpとScaleOut
問題を解決するために知っておく概念は二つある。ScaleUpとScaleOutだ。
ScaleUpは縦方向のリソースの向上を意味している。サーバのハードウェアの性能を上げることだ。CPU性能を上げたりRAMのメモリ量増やしたりとかそんな感じ。ScaleUpはリクエストを大量に捌くというよりは重い処理をコンスタントに提供できるようにするときにとられる解決策。
ScaleOutは横方向のリソースの向上を意味している。サーバの台数を増やすことだ。同じサービスを提供するサーバの数を増やして大量のリクエストをそれぞれのサーバが分割して処理をする。ユーザが増えた来た時に取られる解決策はこっちが有効だ。
Distribute Requests
この章では前の章で紹介したScaleOutをして大量のリクエストに耐えられるネットワークアーキテクチャについて紹介する。
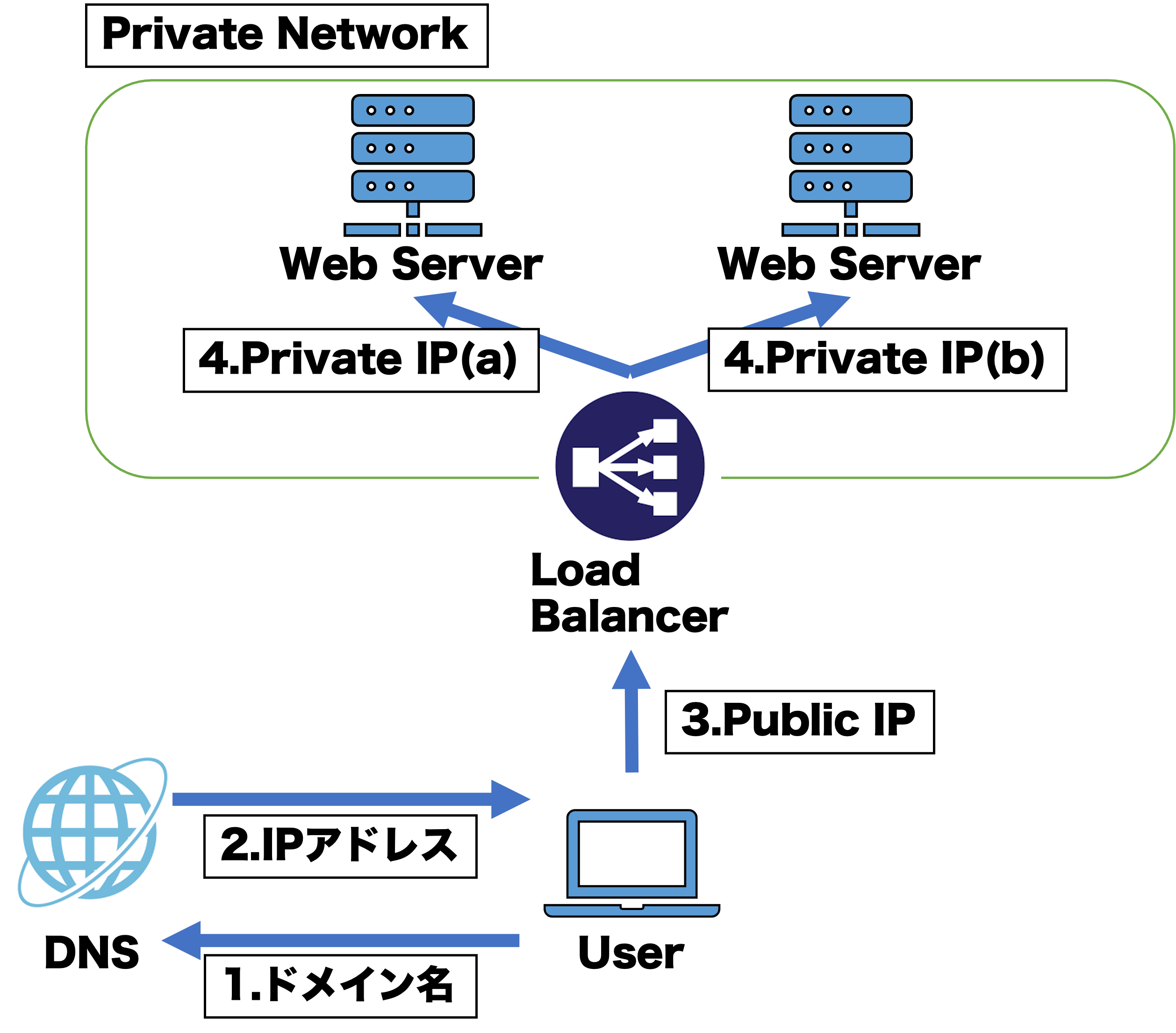
このアーキテクチャではデータベースを省略している。重要な部分はLoad BalancerがUserからのリクエストを二つのサーバに分散して渡しているところだ。UserとLoad Blancerはグローバルネットワークで繋がっていて、二つのサーバとLoad Balancerはプライベートネットワーク内で接続されている。つまり、Userはもう直接サーバにアクセスすることはできなくなっている。このLoad Balacerの利点はサーバのスケーリングを自由にできるところだ。リクエスト数がより多くなり二つのサーバでは対処しきれなくなっても、新たに三つ目のサーバを立てて分散することが簡単にできる。これによってサーバをコールド(ホットでも可)スタンバイさせておくことで、すぐにスケールの調整ができる。また、もし全てのサーバがダウンしてしまっても蘇生可能である(フェイルオーバー対策)。つまり可用性の能力が向上する。
しかし、このアーキテクチャにも問題がある。サーバの数が多くなってもデータベースの負担はまだ変化していない。でもデータベースを同じようにスケールアウトすることはできない。もしそれをやってしまうとデータを保存して読み出す際にどこのデータベースに保存されているのかサーバ側にはわからないからだ。保存したはずのデータがデータベースに存在しないなんてことが起こりうる。
どうしたら良いだろうか。
Who's Origin?
この章ではデータベースのマスタースレーブについて紹介する。
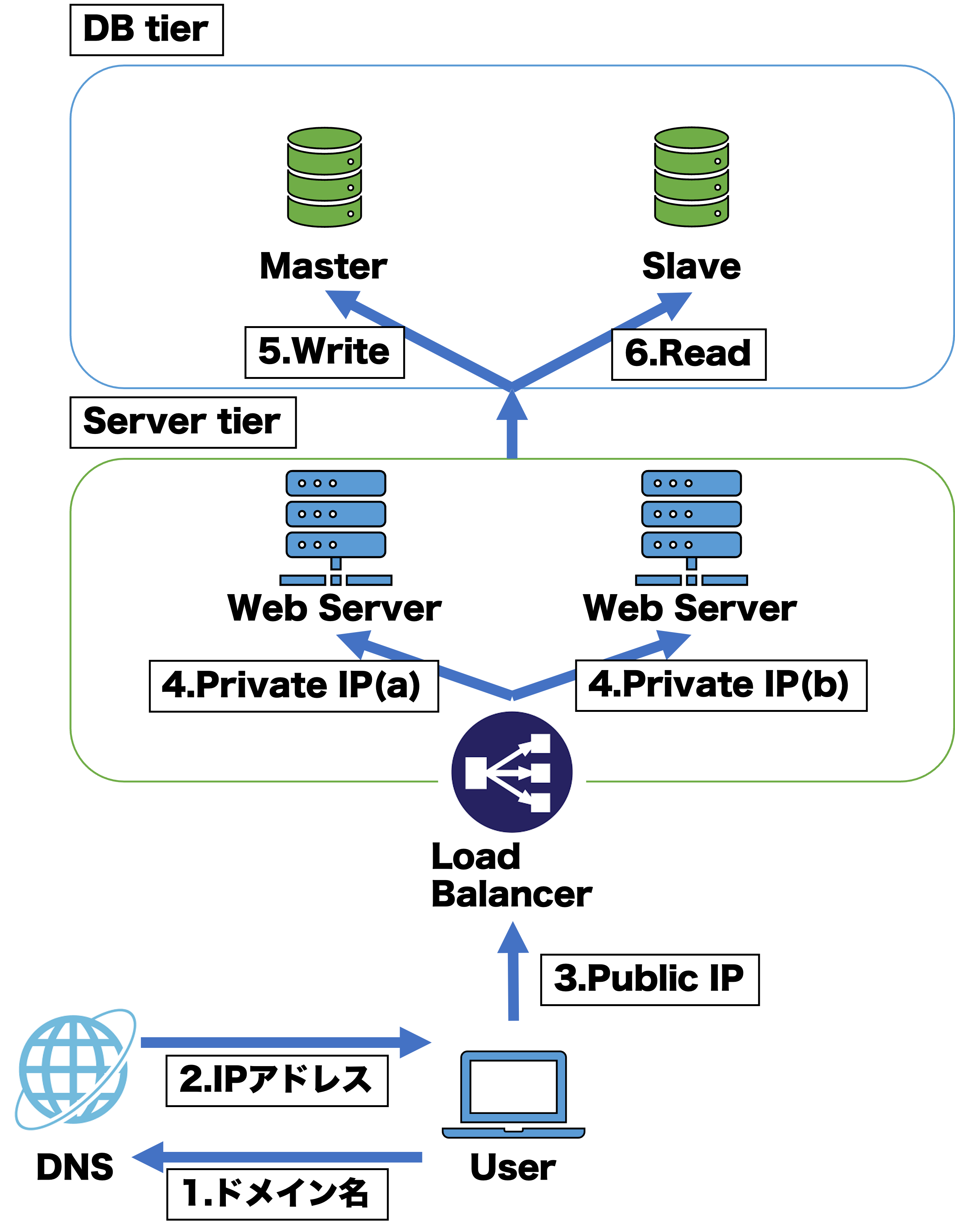
データベースをそのまま複数増やしてしまうとデータの一貫性が保てなくなる。それにどこのデータベースにデータを保存したのかはロードバランサの機嫌次第なのでデータのありかがわからなくなってしまう。したがって、そのまま増やすのではなくデータベースへの要求の目的ごとに分担する。データの書き込みを担当するデータベースをマスター、データの読み込みを担当するデータベースをスレーブと呼ぶ。最近では呼び方が良くないとのことでリーダー、フォロワーと呼ばれていることもある。マスターは基本的に一つしかない。スレーブは複数あっても良い。仕組みはマスターにデータが保存される。一定の期間ごとにスレーブはマスターのデータを自分にコピーする。そうすることでデータの一貫性を守りつつ、書き込みと読み込みで通信量を分散することができる。書き込みにおいては結局通信量が変化していないが、それに関してもシャーディングという対応策があるがこの記事では紹介しない。ちなみにもしなんらかの原因でマスターがダウンしてしまった時にどれか一つのスレーブがマスターに昇格することができる。これでデータベースの可用性の能力も向上することができる。
まとめ
今回はここまで、結論スケールアウト中心のお話になってしまいました。本当はまだここからさらに通信量を分散化するための取り組みや、レスポンスの速度効率化の取り組みがあるのですが時間がないので断念しました。紹介したかったことの名前だけ書いて終わりにしようと思います。
CDN, Cache, queとworker, shadingとpartitioning, loggingとmetrixとautoscaling, DATA Center。
明日は今日紹介した知識をk8sを使って実践した記事を書きます。