はじめに
手持ち環境を整理して以下のマシンを構築したので、ここにvLLMを使える環境をDocker containerとして構築します。また動作テスト用にOpen-WebUIも動作させます。
- CPU: AMD Ryzen 7 5700X
- メモリ: 64GB, DDR4-3200/2ch
- ストレージ: NVMe Gen.4 SSD 2TB
- GPU: NVIDIA RTX 4060Ti 16GB x2
- OS: Ubuntu 24.04 LTS Server
なお、GPUがコンテナで利用可能な状態になっていることを前提とします。以下の記事を参考にしてください。
構成
適当なディレクトリを作成して、そこに必要なファイルを置きます。私の場合は以下のようにしました。
mkdir -p ~/Containers/vLLM
cd ~/Containers/vLLM
先にモデルを保存するディレクトリを作成します。
mkdir -p ./models
次に以下のdocker-compose.ymlをカレントディレクトリに作成します。
services:
vllm:
image: vllm/vllm-openai:latest
runtime: nvidia
ipc: host
shm_size: "4g"
command: >
--model=/models/Qwen3-4B-AWQ
--tokenizer=Qwen/Qwen3-4B-AWQ
--quantization=awq
--dtype=float16
--tensor-parallel-size=2
--max-model-len=8192
--download-dir=/models
--host=0.0.0.0
--port=8000
ports: ["8000:8000"]
environment:
- VLLM_USE_V1=0
- DISABLE_CUSTOM_ALL_REDUCE=1
- NVIDIA_VISIBLE_DEVICES=0,1
volumes:
- ./models:/models
deploy:
resources:
reservations:
devices:
- capabilities: [gpu]
webui:
image: ghcr.io/open-webui/open-webui:main
ports: ["3000:8080"]
environment:
- OPENAI_API_BASE_URL=http://vllm:8000/v1
- WEBUI_AUTH=False
depends_on: [vllm]
ここではモデルをQwen3-4B-AWQにしました。このファイルはGPUが2枚刺さっているマシンを対象にしています。もし、1枚しかなかったり、2つのvLLMのコンテナを立ち上げてそれぞれ独立にGPUを使わせたい場合は、- NVIDIA_VISIBLE_DEVICES=0,1の行の=より右側を0だけ、1だけなどのように書き換えてください。
【2025/5/19 追記】
----- ここから -----
GPU1枚で実行する場合、 --tensor-parallel-size=2を削除してください。
----- ここまで -----
次にモデルをダウンロードするのですが、そのために以下のスクリプトを書きました。これは model_downloader.sh とします。
#!/usr/bin/env bash
# ------------------------------------------------------------
# 使い方:
# export HF_TOKEN=hf_xxx
# ./model_downloader.sh <repo_id>
# ------------------------------------------------------------
set -euo pipefail
HF_TOKEN=hf_********************************
if [[ $# -lt 1 ]]; then
echo "Usage: $0 <huggingface_repo_id>" >&2
exit 1
fi
REPO_ID="$1"
: "${HF_TOKEN:?Please export HF_TOKEN before running this script}"
# 保存先 ./models/<repo末尾>
BASE_DIR="$(pwd)/models"
DIR_NAME="${REPO_ID##*/}"
DEST_DIR="$BASE_DIR/$DIR_NAME"
mkdir -p "$BASE_DIR"
echo -e "\n▶ Downloading \e[1m$REPO_ID\e[0m → $DEST_DIR\n"
docker run --rm -it \
-e HF_TOKEN="$HF_TOKEN" \
-v "$BASE_DIR":/models \
python:3.11-bullseye bash -c "\
pip install --quiet --no-cache-dir 'huggingface_hub[cli]' && \
huggingface-cli download ${REPO_ID} --token \$HF_TOKEN \
--local-dir /models/${DIR_NAME} --local-dir-use-symlinks False"
echo -e "\n✅ Download finished."
# ────────────────────────────────────────────────────────────
# docker-compose 用 3 行ひな形
# ────────────────────────────────────────────────────────────
case "$DIR_NAME" in
*awq*|*AWQ*) QUANT=awq ;;
*gptq*|*GPTQ*) QUANT=gptq ;;
*gguf*|*GGUF*) QUANT=gguf ;;
*) QUANT=None ;;
esac
TOKENIZER_ID="$REPO_ID" # ← ここを『repo_id そのまま』に変更
cat <<EOF
------------------------------------------------------------
📋 docker-compose.yml にコピペする 3 行
------------------------------------------------------------
--model=/models/${DIR_NAME}
--tokenizer=${TOKENIZER_ID}
--quantization=${QUANT}
------------------------------------------------------------
EOF
model_downloader.sh内にHuggingFaceのアクセストークンを記述するので、他の人から見られないようにするため、また、実行権限を与えるため、以下の操作をしてアクセス制限をします。
chmod 700 ./model_downloader.sh
model_downloader.sh内のHF_TOKEN=hf_********************************の行の=より右側はHuggingFaceから取得したアクセストークンを書きます。HuggingFaceのアカウント作成、アクセストークン取得は以下のページを参照してください。
それでは、先程docker-compose.ymlに書いたQwen3-4Bのモデルをダウンロードします。以下のように実行してください。
./model_downloader.sh Qwen/Qwen3-4B-AWQ
ダウンロードが完了すると以下のようなメッセージが最後に表示されます。
✅ Download finished.
------------------------------------------------------------
📋 docker-compose.yml にコピペする 3 行
------------------------------------------------------------
--model=/models/Qwen3-4B-AWQ
--tokenizer=Qwen/Qwen3-4B-AWQ
--quantization=awq
------------------------------------------------------------
この「コピペする3行」に従い、はdocker-compose.ymlの該当行を書き換えます。--tokenizerと--quantizationは推定です。うまく動作しない場合はvLLMを使っている他のページを参考にしてください。今回提示したdocker-compose.ymlはすでに上記の内容が反映されています。
vLLMはモデルを動的に変更する機能がないようなので、モデル変更時に毎回docker-compose.ymlを書き換える必要があります。そのため、上記の編集したファイルは以下のようにコピーを作成しておくことをおすすめします。
cp docker-compose.yml docker-compose.yml-qwen3-4b-awq
コンテナ実行
以下のように実行し、コンテナを実行します。
docker compose up -d
docker logs -f vllm-vllm-1
vLLMのコンテナを立ち上げるには暫く時間がかかります。完全に立ち上がると、最後に以下のような表示になります。
INFO: Started server process [1]
INFO: Waiting for application startup.
INFO: Application startup complete.
この表示が出てから1分くらい後にウェブブラウザでhttp://localhost:3000、または当該マシンのIPアドレスが192.168.100.100なら、他のマシンのウェブブラウザからhttp://192.168.100.100:3000にアクセスしてください。そうすると以下のように表示されます。
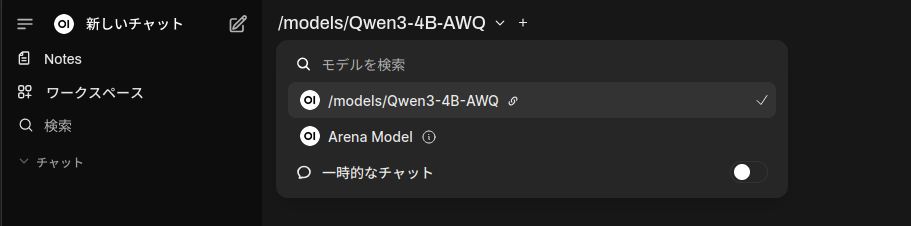
「OK、始めましょう!」ボタンを押すと会話を始められます。モデルが選択されていないことがまれにありますが、その場合は以下のように「新しいチャット」の右側にあるフィールドをクリックするとモデルが選べます。
起動ができたら、docker logs -f vllm-vllm-1の実行はCtrl-Cで止めてもらって構いません。
なお、コンテナの終了は以下のコマンドを実行します。
docker compose down
実行テスト
では、実際に入力してみます。プロンプトは以下のとおりです。
有史以来の日本の歴史について教えてください。
結果は以下のようになります。
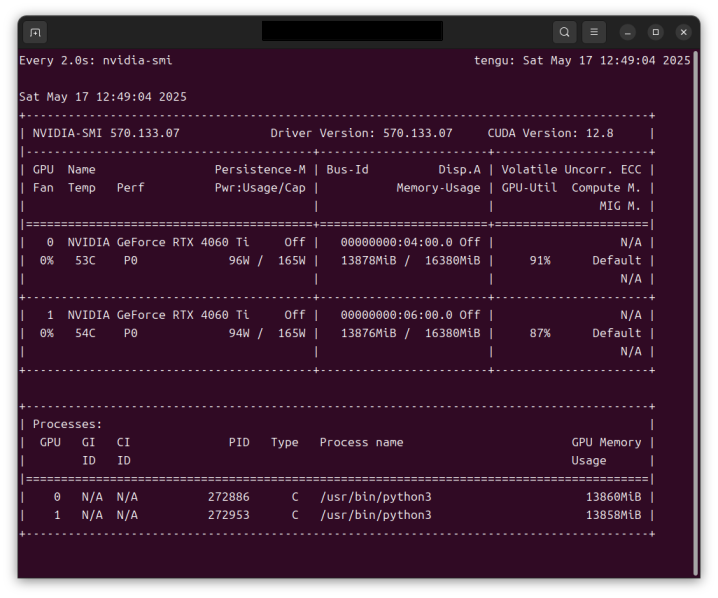
このときのGPUの実行状態は以下のとおりです。2つのGPUが使われていることが分かります。VRAMの使用量が多い気もしますが、理由は分かりません。
もう少し大きモデルでも試してみましょう。ここではAratako/DeepSeek-R1-Distill-Qwen-32B-Japanese-AWQを使います。model_downloader.shでダウンロードして、docker-compose.ymlを修正したら、以下のようにコマンドを実行します。
docker compose down
docker compose up -d
docker logs -f vllm-vllm-1
先ほどと同じように待ってからブラウザからアクセスします。モデルの名前が/models/DeepSeek-R1-Distill-Qwen-32B-Japanese-AWQと表示されていることを確認して先ほどと同じプロンプトを入力します。結果は以下のとおりです。
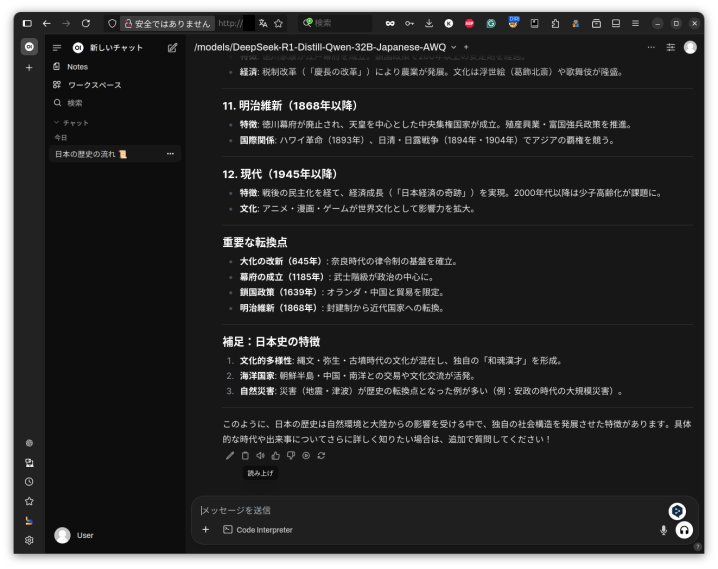
モデルが違うので内容も変わりますが、こうやって見るとQwen3-4Bはかなり頑張ってますね。
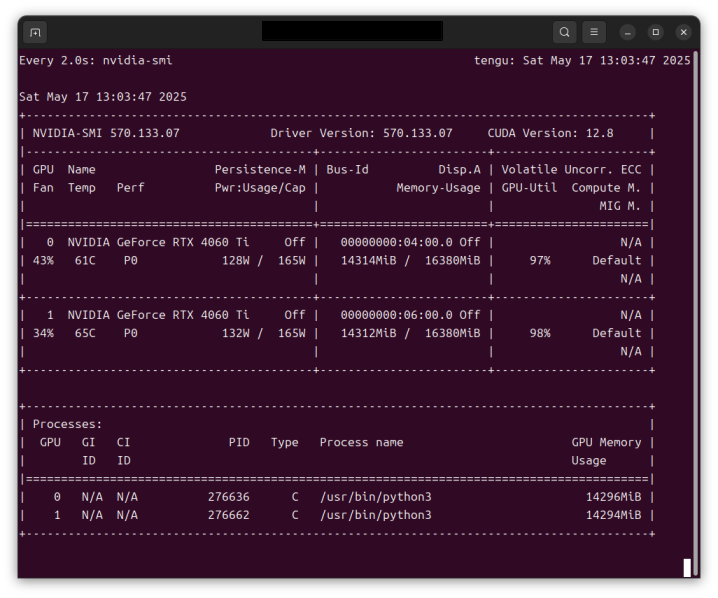
さて、このときのGPUの実行状態は以下のとおりです。2つのGPUともリソースをほぼ目一杯使っています。動作速度も実用上十分で、約 20 tokens / sec の速度になりました。
備考
以下のことにご留意ください。
-
Open WebUIの認証は外してあります。他の方が触る可能性がある環境では認証することをご検討ください。 - 今のところ、vLLMは動的にモデルを変更することができないようです。モデルを変更するには毎回
docker-compose.ymlを入れ替えてコンテナを再起動してください。 -
model-downloader.shにHuggingFaceのアクセストークンを直書きしています。この行を削除して外部環境変数とすることも可能です。都合の良いようにお使いください。特にGitHubなどへのアップロードをする場合はアクセストークンが漏洩しないようご注意ください。
以上です。
【2025/5/24追記】
- GPTQモデルをvLLMは扱うことができますが、現在のバージョンではマルチGPUでは動かないとのことです。この記事ではマルチGPUを前提としたdocker-compose.ymlを提示しています。ご注意ください。
- vLLM 0.8.5 系の AWQ 実装は “MoE + TP>1” をまだサポートしていないとのことで、上記構成では今の所Qwen3-30B-A3B-AWQを動かす手段はなさそうです。GPTQの方は1つ目の方の理由で動きません。