AWS DASの勉強で初めてGlueを触ったのでメモ
Parquet形式とは
Apache Parquet や ORC は、データを高速に取得できるように最適化された、AWS 分析アプリケーションで使用されている、列指向ストレージ形式です。
列指向ストレージ形式には以下の特性があるため、Athena での使用に適しています。
列のデータ型に合わせて選択された圧縮アルゴリズムによる列ごとの圧縮で、Amazon S3 のストレージ領域を節約し、ディスク容量とクエリの処理中における I/O を削減します。
Parquet および ORC での述語プッシュダウンにより、Athena クエリが必要なブロックのみを取得できるようになり、クエリパフォーマンスが向上します。Athena クエリがデータから特定の列値を取得すると、データブロック述語からの統計 (最大値や最小値など) を使用して、そのブロックを読み取るかスキップするかを判断します。
Parquet および ORC でのデータの分割により、Athena がデータの読み取りを複数のリーダーに分割して、クエリ処理時における並列化を向上させることが可能になります。
ざっくりまとめると以下のメリットがあリます。
・select id from ~のような列を指定したクエリが効率良く実行可能。
・列のデータ型に合わせて列ごとに圧縮するので、色々なデータ型を含む行指向と比較して保存の圧縮効率が良い。
上記から、分析用途ならparquetなど列指向のファイルに変換した方が都合が良いということでした。
parquetへの変換
以下の流れでparquetファイルを作成します。
- 変換元となるサンプルcsvをS3に格納
- csv→parquet変換用のGlueJobを作成
- Job実行
変換元となるサンプルcsvをS3に格納
以下のサイトで10万行のサンプルデータを生成します。
https://tm-webtools.com/Tools/TestData
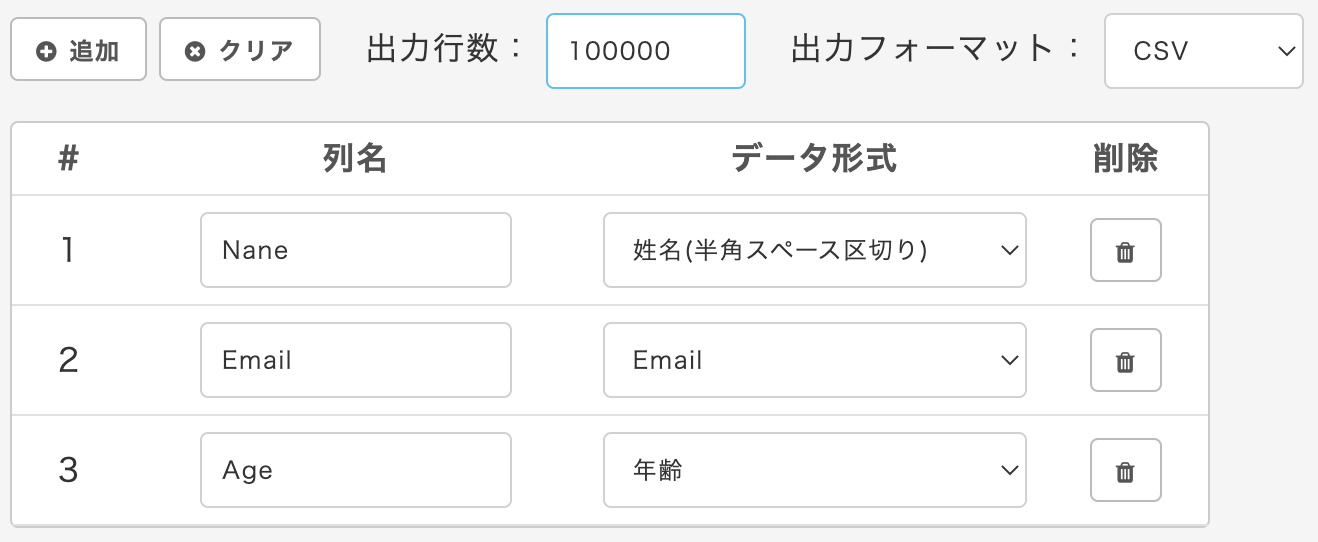
このサンプルデータはS3に格納しておきます。
csv→parquet変換用のGlueを作成
Glue画面の[Data Integration and ETL] - [Jobs]からGlueジョブを作成していきます。
ジョブ全体像
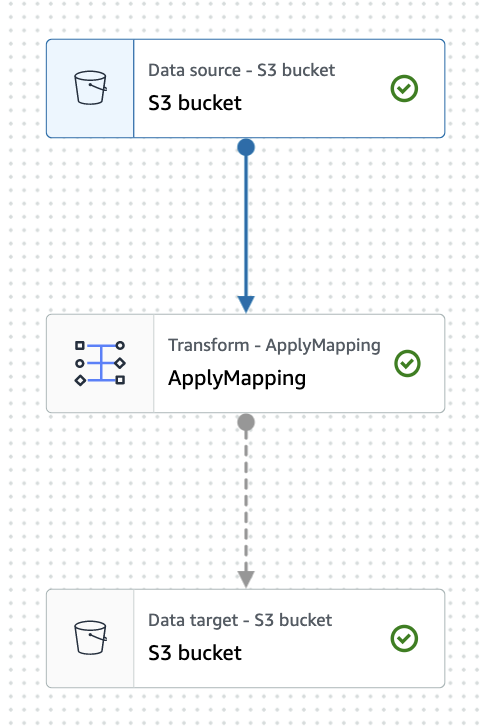
Data source
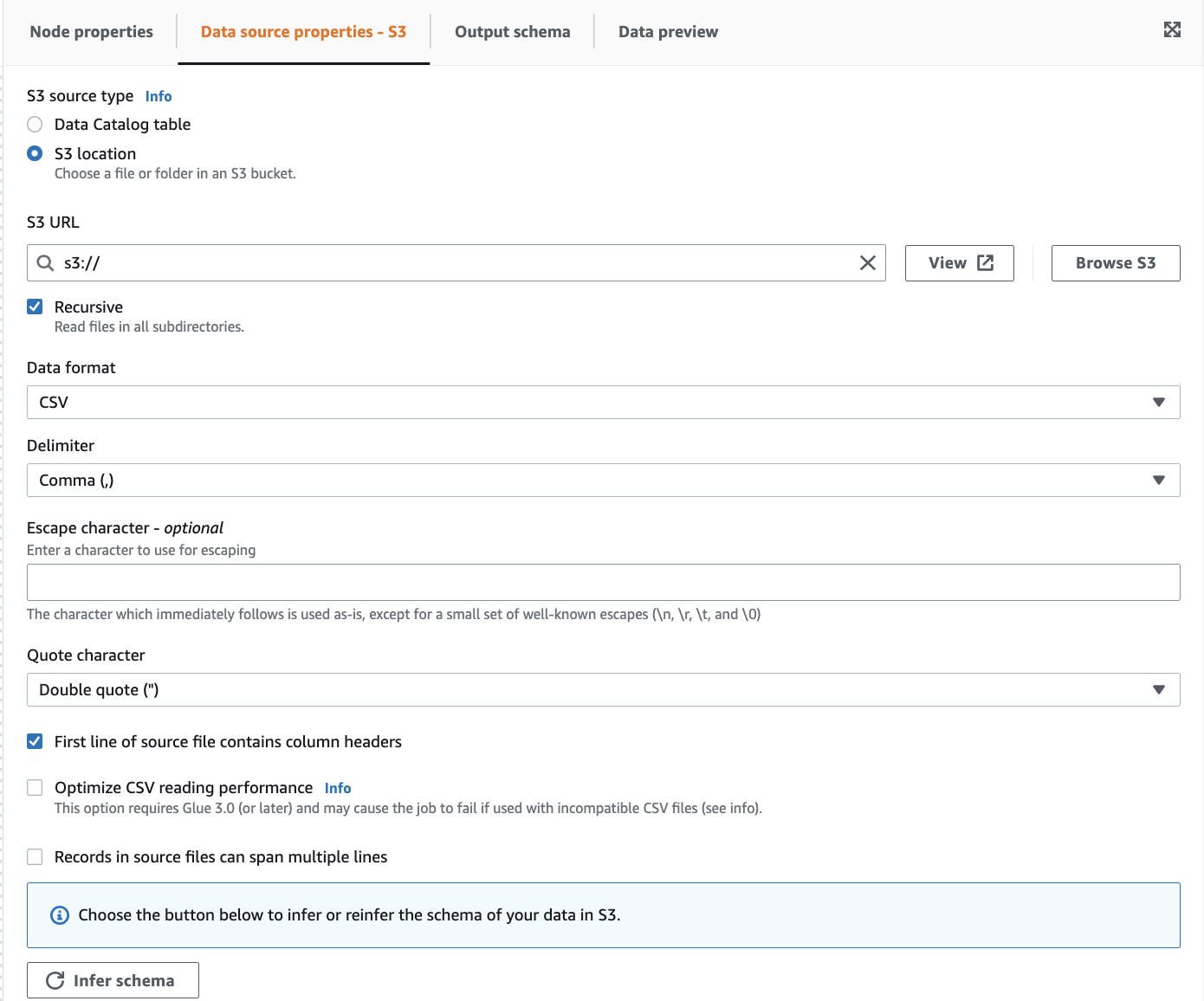
サンプルファイルにヘッダー行が入っている為、First line of source file contains column headersにチェックを入れます。
Data previewを開くと、CSVの中身が表示されます。
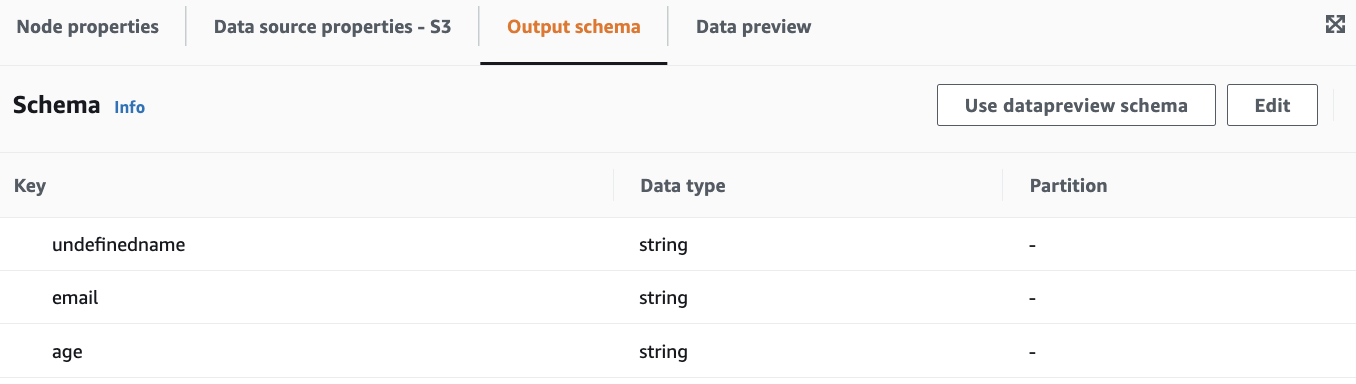
理由は分かっていないですが、nameがundefinednameになっていました。。
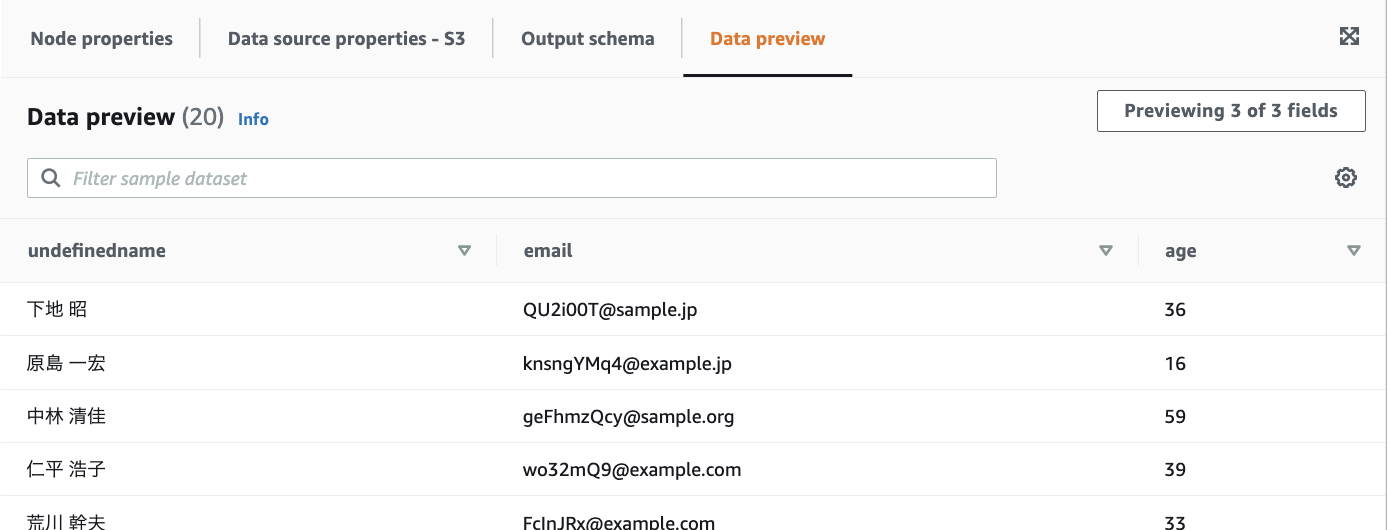
Output schemaのEditから修正出来そうでしたが、後続のTransformで対応します。
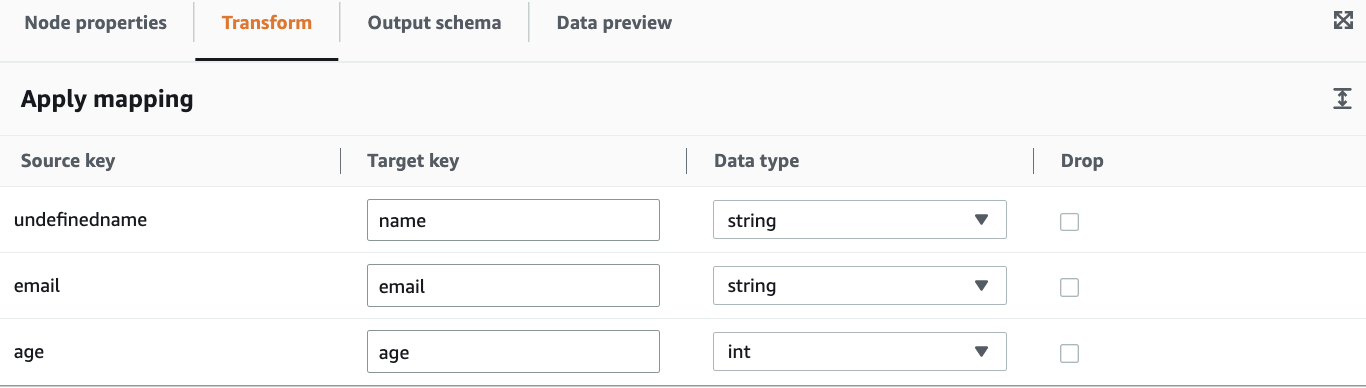
Transform
以下を変更しました。
・undefinednameをnameへ変更
・ageをint型へ変更
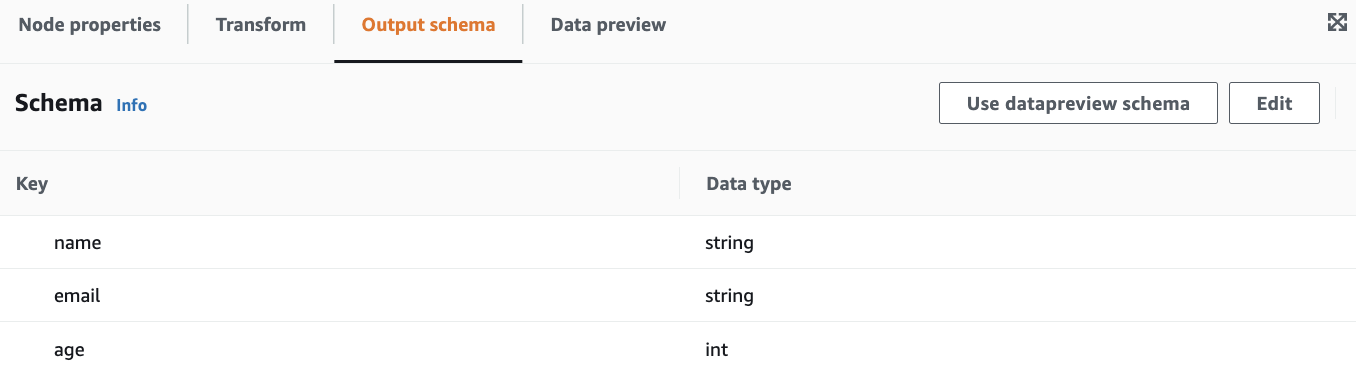
Output schemaは想定通りです。
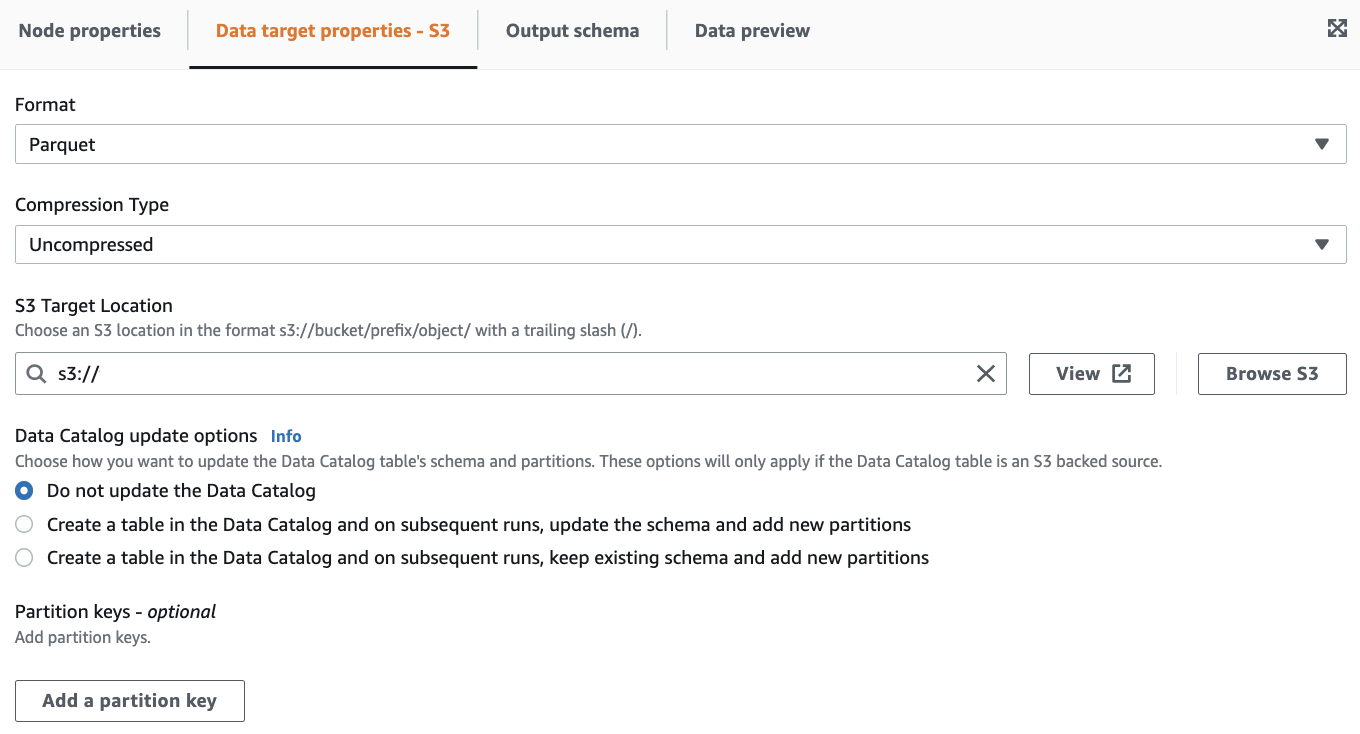
Data target
ここで出力形式にParquetを選択します。
テストなので圧縮・データカタログは無しとしました。
隠していますがS3バケットに出力するようにしています。
Data Previewが表示されませんでしたが、とりあえず先に進みます。
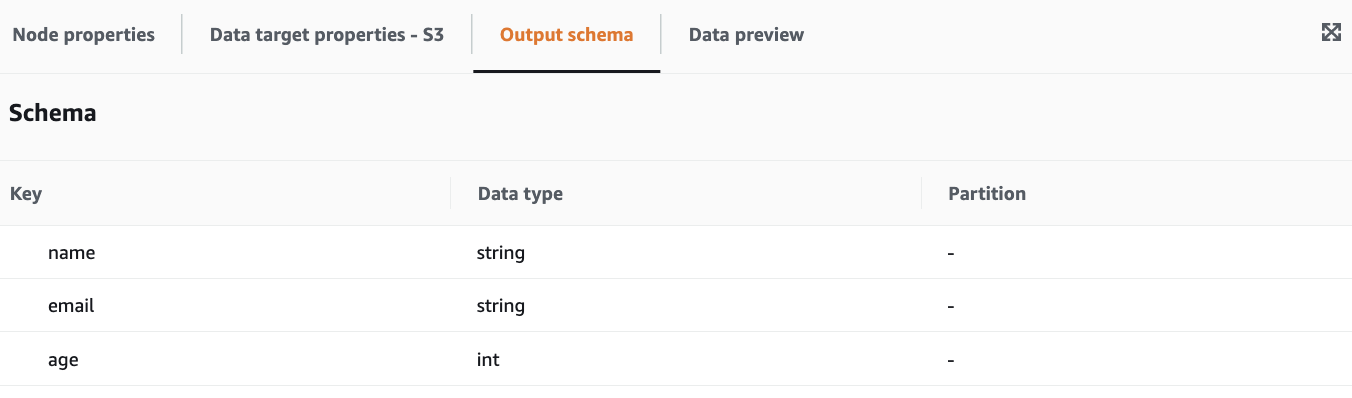
Output schemaは想定通りです。
ここまででJob設定は完了です。
Glue実行
作成したJob画面右上のRunから実行します。
Jobの状況はRunsタブから確認が可能です。
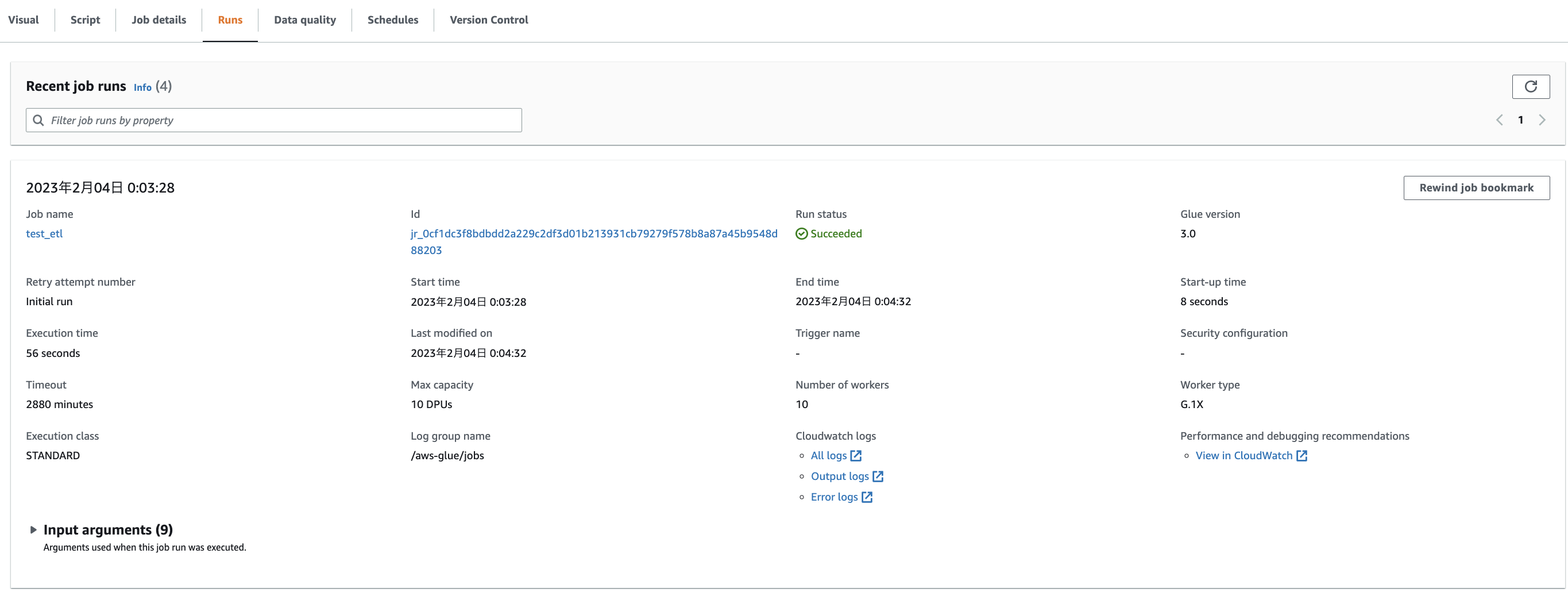
Job成功後、出力先に設定したS3にparquetファイルが出力されていました。

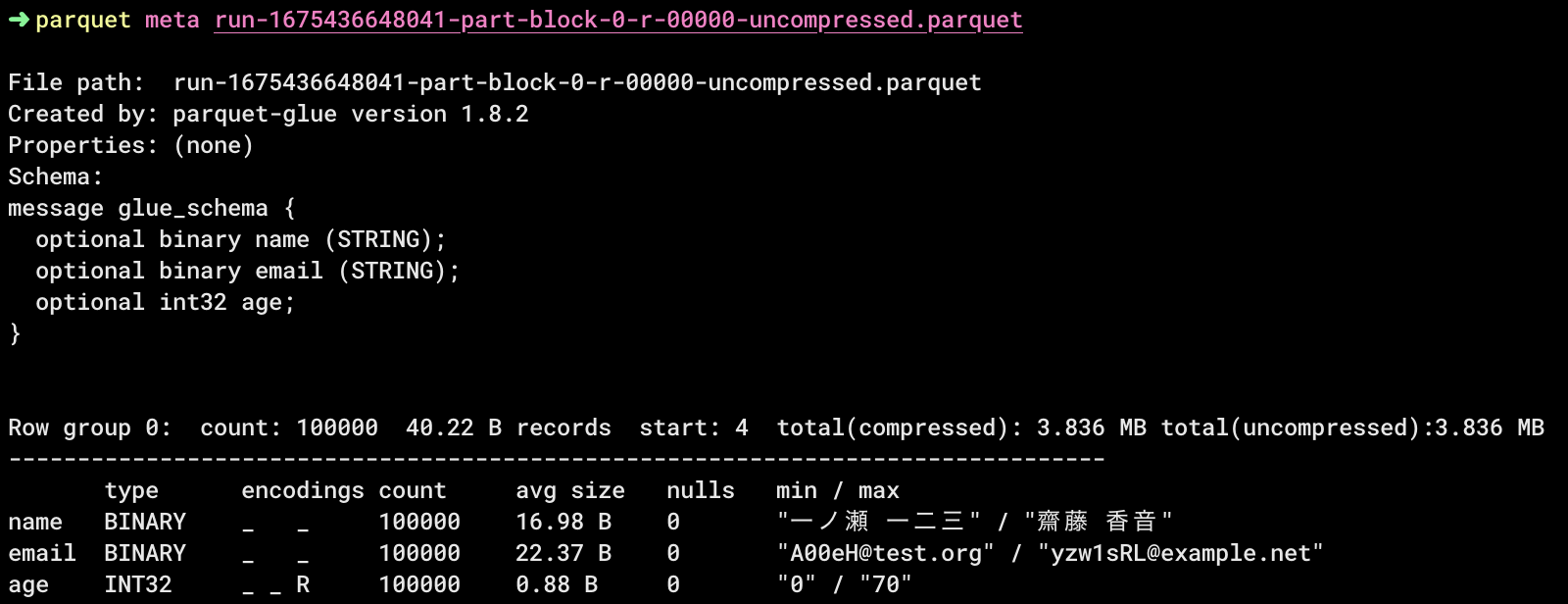
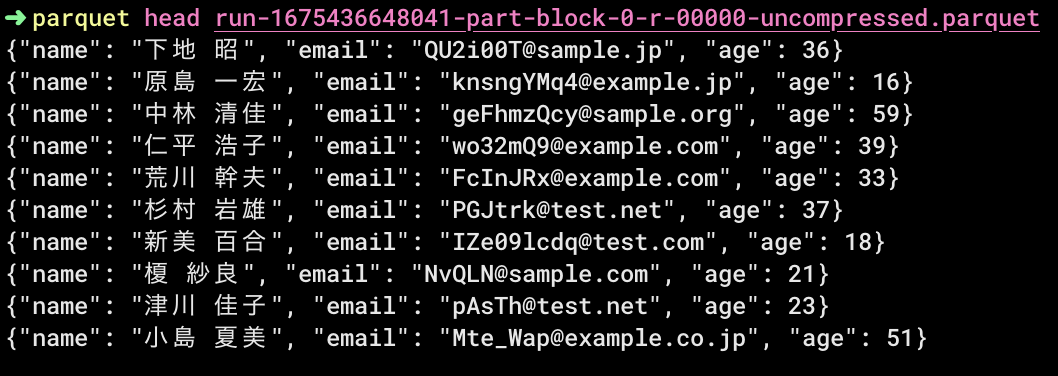
最後にファイルの中身を見てみます。
このままS3 Selectを使用しても良いのですが、料金を気にしたくないのでローカルで参照します。
調べたところVSCodeの拡張機能かCLIが気軽に使えそうで、今回はCLIにしました。
いくつかコマンドを打ったところ。
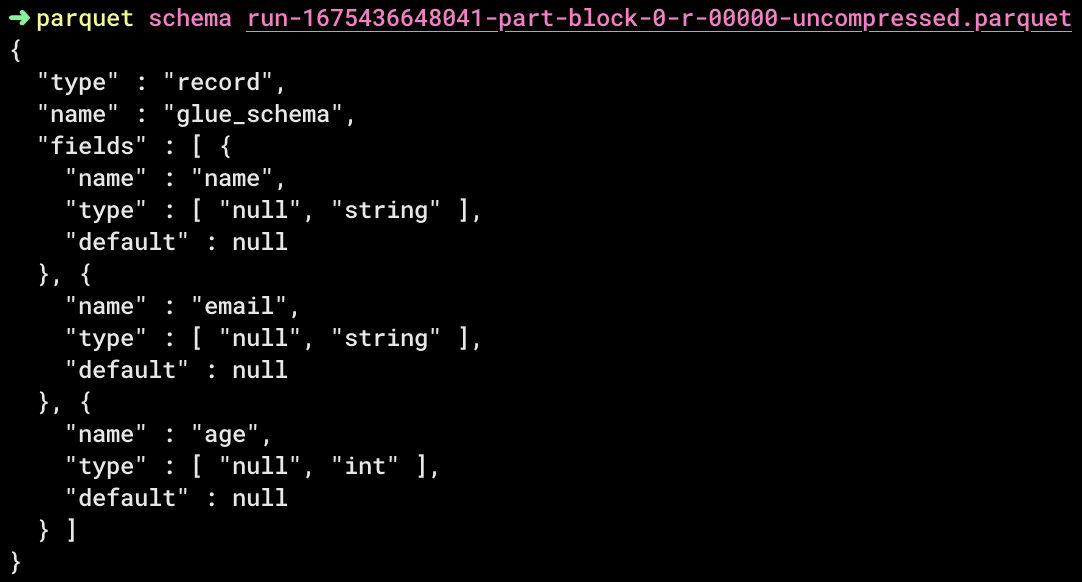
一旦スルーしてしまった箇所もありますが、ひとまずやりたいことは出来ました。
metaコマンドでカラムごとにmin/max値が表示されるのが面白かったです。
参考記事
parquet-cliのインストール・使用方法
https://kakakakakku.hatenablog.com/entry/2022/12/12/094113