こんにちは、もっちゃんと申します。
自然言語をアプリケーションで利用できると、ユーザビリティをより向上させることができる可能性があると思っています。アプリケーションの使い方にとらわれず、普段よく使っている自然言語でアプリが利用できるからですね。
ということで本エントリーでは自然言語処理(NLP/NLU)の機能を提供するMicrosoft AzureのLUIS(Language Understanding)というサービスがどのようなものかを理解していきたいと思います。
Microsoft AzureのLUISとは?

Language Understanding (LUIS) は、カスタムの機械学習インテリジェンスをユーザーの自然言語での会話テキストに適用して、全体の意味を予測し、関連性のある詳細な情報を引き出す、クラウドベースの会話型 AI サービスです。 LUIS には、カスタム ポータル、API、および SDK クライアント ライブラリを介してアクセスできます。
いわゆる専門知識が無い開発者でも機械学習の機能を使うことができるAI系のサービスで、自然言語を扱う機能をアプリケーションに搭載することができるサービスです。会話型ボット (チャットボット) や音声アシスタントなどが実現できるでしょうか。かなり多くの言語に対応しているのも嬉しいところです、もちろん日本語も対応しています。(今のところ無料でも利用できそうですね)
機能的には主には下記ができると思えば良いかと思います。
- 文章分類
- ユーザが送ってきた文字列情報から特定のデータを抽出
使うにあたって理解しておきたいことピックアップ
LUISの使い方ですが、基本的には公式のドキュメントに利用の流れが記載されています。
おおまかな利用の流れは下記な感じですね。
- LUIS専用ポータル画面でこれから作業するための作業スペース(新しいアプリ)を新規作成
- Intent, Entity(学習データ)を作成
- トレーニング(機械学習モデル作成)を実施
- テストを実行(機械学習モデルの動作確認)
- 発行(外部のアプリ内などで利用ができる状態)
使い方の詳細は次の記事で行うので、ここでは重要だけどあまり馴染みが無さそうなポイントについてピンポイントに見ていこうと思います。(個人的な解釈が含まれますのであらかじめご了承ください)
Intent(インテント)について
まずIntentですが、公式ドキュメントには下記のように記載されています。
意図(Intent)は、ユーザーが実行しようとしているタスクまたはアクションを表します。 これは、フライトの予約や請求書の支払いなど、ユーザーの入力で表現される目的または目標です。 LUIS では、発話全体が意図として分類されますが、発話の一部はエンティティとして抽出されます
上記の説明はちょっと分かりにくいかもしれませんが、要するにLUISは文章の分類機能を提供するので、Intentは文章を分類する際のラベルの役割を担っています。
例)
あいさつIntent
- おはよう
- おはようございます
- おっはよー
- こんにちは
- さようなら
...(たくさんあるので以下省略)
注文Intent
- Mサイズのピザを3個ください
- ピザを2個ください中ぐらいのサイズのやつ
...(たくさんあるので以下省略)
そのため上記のようにIntentの内容は設定していきます。
すると、下記のような形でユーザの発言がどのIntentに分類されるのか判定できるようになるといった具合です。
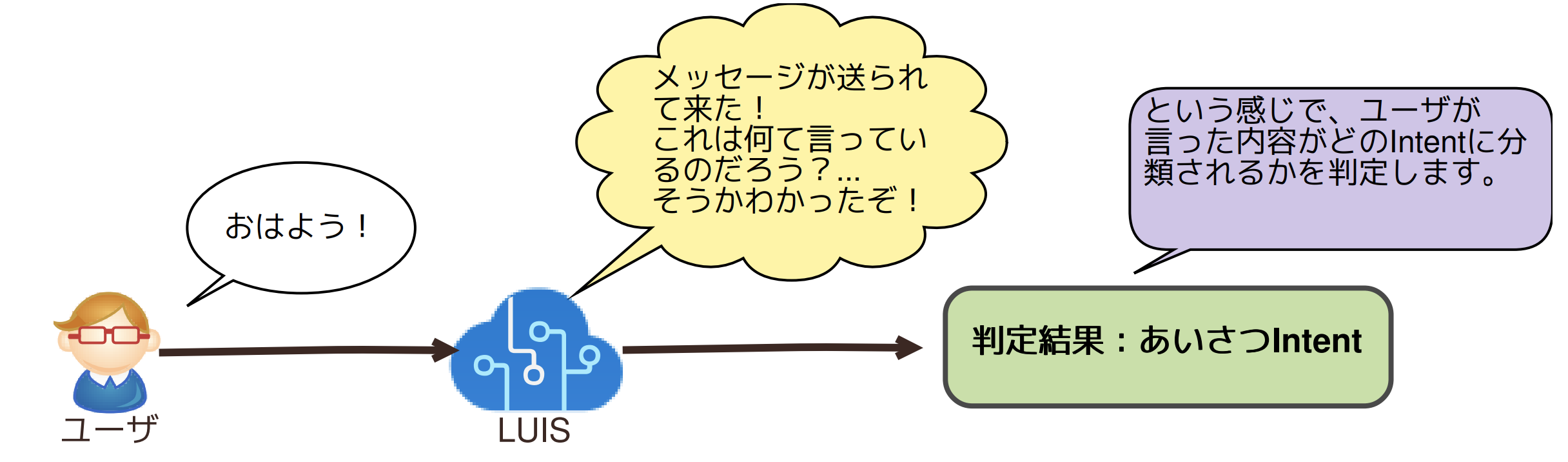
ただし、上記のIntentの設定で少し垣間見えていますが、あいさつの言い方だけでも多くのパターンがあり(自然言語はフリーフォーマットなので...)、単純なルールベース(if文的な)の方法で判定を行うのは厳しいことが伺えると思います。そこでLUISのような機械学習によるアプローチが必要なんですね!
これでユーザが発したものが自然言語であってもシステム側で理解できる(判定できる)ので、アプリケーションの方で次のアクションを実施することが可能になるということになります。
(余計に分かりにくいかもしれないですが、こういうイメージです。)
 上記のようなイメージです。単純なルールベースによる分類では無いということが言いたいです。(上記の画像は[コチラ](https://techcommunity.microsoft.com/t5/azure-ai/how-bert-is-integrated-into-azure-automated-machine-learning/ba-p/1194657)から引用させていただきました。もっとドンピシャの画像が見つかったら差し替えます!)Entity(エンティティ)について
次にEntityについてですが、公式のドキュメントには下記のように記載されており
エンティティは、意図を達成または識別するために使用される情報を説明する発話内の単語です。 エンティティが複雑であり、モデルを使って特定の部分を識別できるようにする場合は、モデルをサブエンティティに分割できます。 たとえば、モデルを使って住所を予測するだけでなく、番地、市区町村、都道府県、郵便番号のサブエンティティも予測することができます。 エンティティは、モデルの特徴としても使用できます。 LUIS アプリからの応答には、予測された意図とすべてのエンティティの両方が含まれます。
発話内の単語の部分で動作するとのことで、文書分類の特徴量として活用されると説明されているようですが、もう1つ大きな役割として発話の文章情報から特定のデータを抽出するというのがあると思っています。
これはユーザが発した文章情報の中から取得したい情報が部分的にある場合があるかと思います。例えば下記のようにユーザから注文系の発言があった場合...
例)
Mサイズのピザを3個ください
↑ユーザの発言の中から、サイズの情報(Mサイズ)と商品名(ピザ)、枚数(3個)の情報が欲しいですよね
先ほどの例で言うと、分類結果としては『注文Intent』の判定が出るわけですが、Intent情報が分かるだけではこの注文のやり取りは成立しません。このユーザの注文情報の中から、サイズの情報(Mサイズ)と商品名(ピザ)、枚数(3個)の情報も抽出したいですよね。そういった機能もEntityでは提供されます。
LUISでは現在、下記のEntityの種類が用意されています。
| エンティティの種類 | 簡単な説明 |
|---|---|---|
| 機械学習済みエンティティ | ラベル付けされた例に基づいてエンティティを抽出。 |
| リスト エンティティ | 固定かつ限定された関連単語セットとそのシノニム。 (例)飴、アメ、キャンディ |
| 正規表現エンティティ | 正規表現パターンに基づいてエンティティを抽出。 (例)[0-9]{6} |
| Pattern.any エンティティ | 同じ意味合いの単語の出現位置のパターンによるエンティティ抽出。{} []などを使用。 (例)Was {BookTitle} written by an American this year[?] |
| 事前構築済みのエンティティ | numberエンティティなど他多数。 |
| 事前構築済みのドメイン エンティティ | よく使いそうな会話のシナリオに基づき設定済みのIntent,Entityが用意されている。 |
上記のうち『機械学習済みエンティティ』がちょっと分かりにくいかもしれないのでもう少し見て行きましょう。
機械学習済みエンティティとは?
ここからは実際の画面を見ながら理解を深めていきましょう。公式のチュートリアルの一部を実施しながら見ていきます。
ちなみに、チュートリアルはピザの注文をするケースを題材にしています。
それでは必要な作業を順番に実施していきます。まずは、最上位のエンティティ(親エンティティ)を作成します。ここではOrderという名前で作成します。(Machinee learnedのラジオボックスを選択するのを忘れずに、これが機械学習済みエンティティを利用するモードになるため)
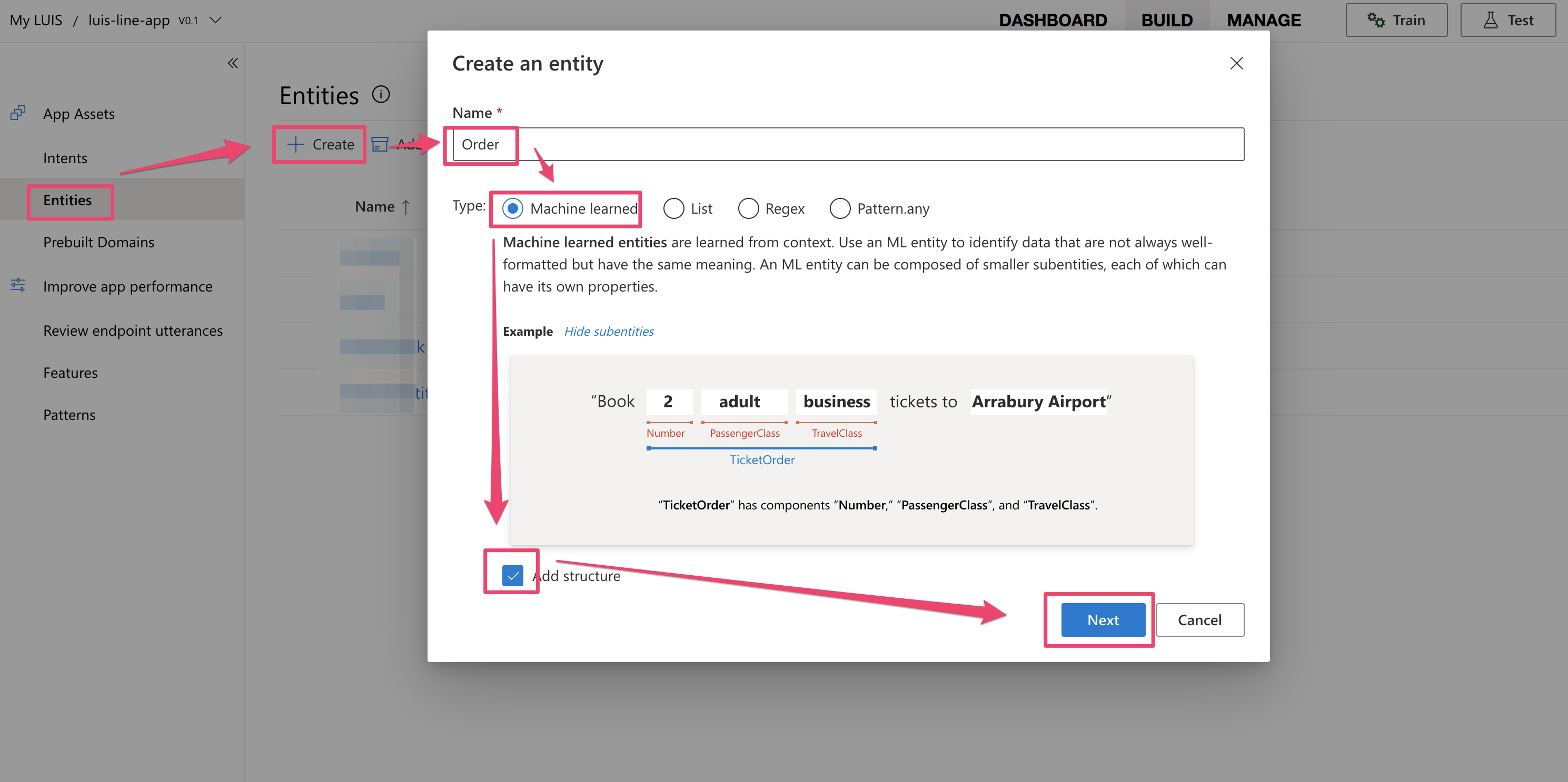
そして次に、サブエンティティ(子エンティティ)を作成します。下記のようにOrderエンティティの中にSizeとQuantityの子エンティティを作成するイメージです。これは実際の注文を思い浮かべていただくと注文(Order)という行為はサイズ(Size)や数量(Quantity)といったいくつかの重要な子要素の情報も含めて構成されてるかと思います。そのため、LUISではこういった構造体に対応をしているんですね。(ここの作成手順は公式のチュートリアルのこの辺りを参照ください)
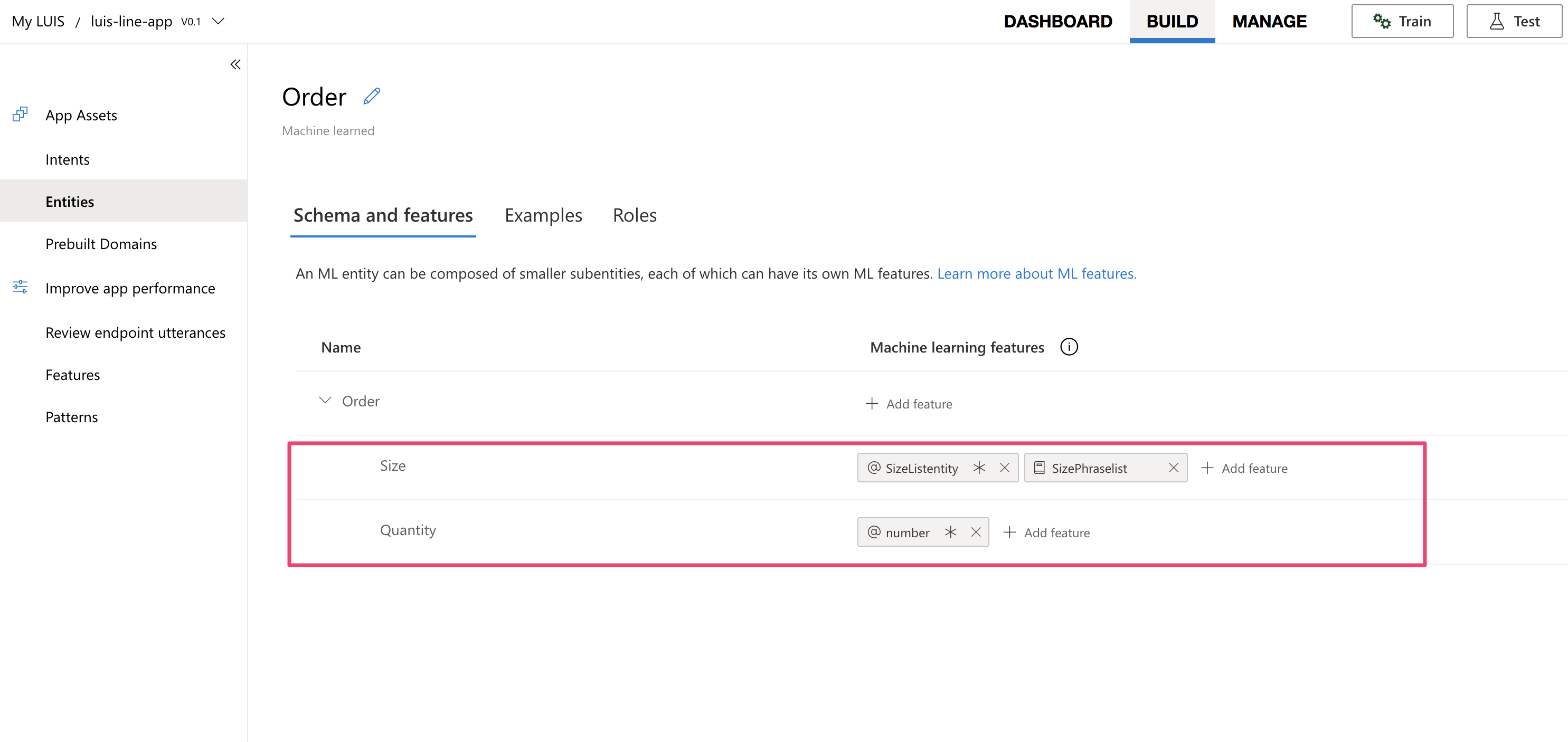
ここまででエンティティの方の準備は整いましたので、次にIntentの作成に移っていきます。
ここではOrderPizzaという名前でIntentを作成し、サンプルの発話を入力していきます。まずは下記のように小さいピザくださいを入力してみましょう。
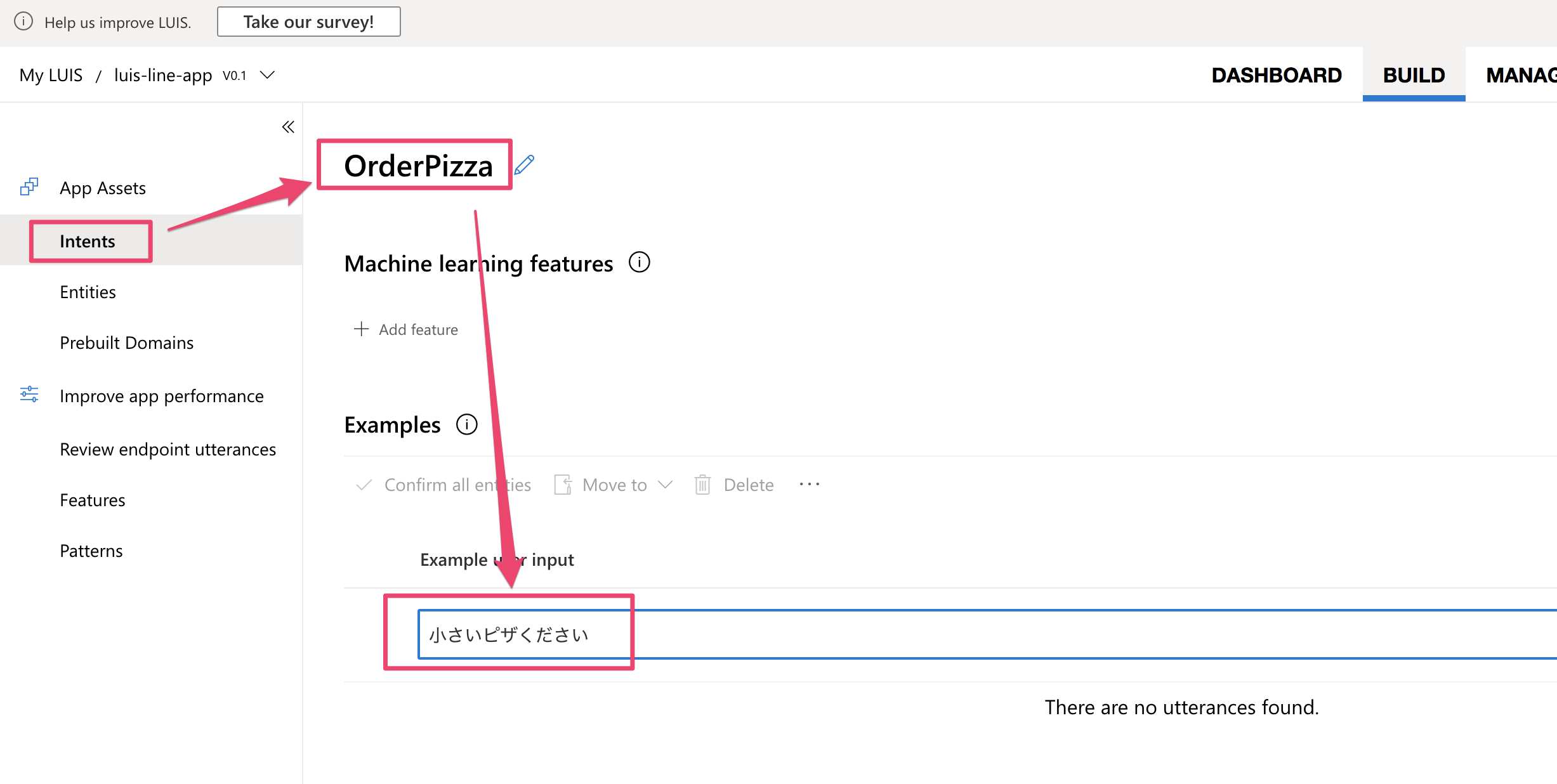
次に下記のように、先ほど作成したエンティティを使ってサンプル発話の文にラベル付けを行います。
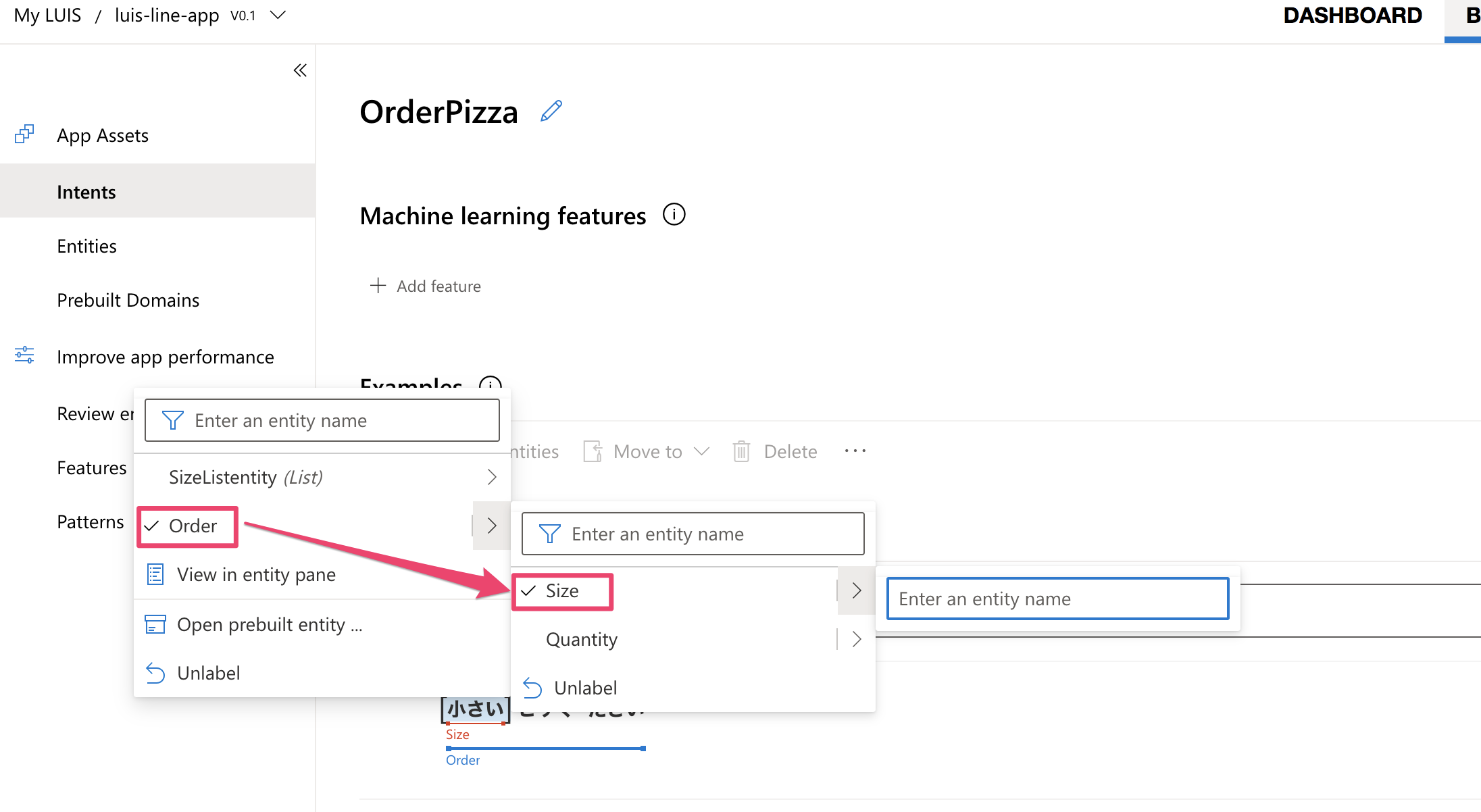
ラベル付けした後はTrainボタンを押すのを忘れないようにしてください。
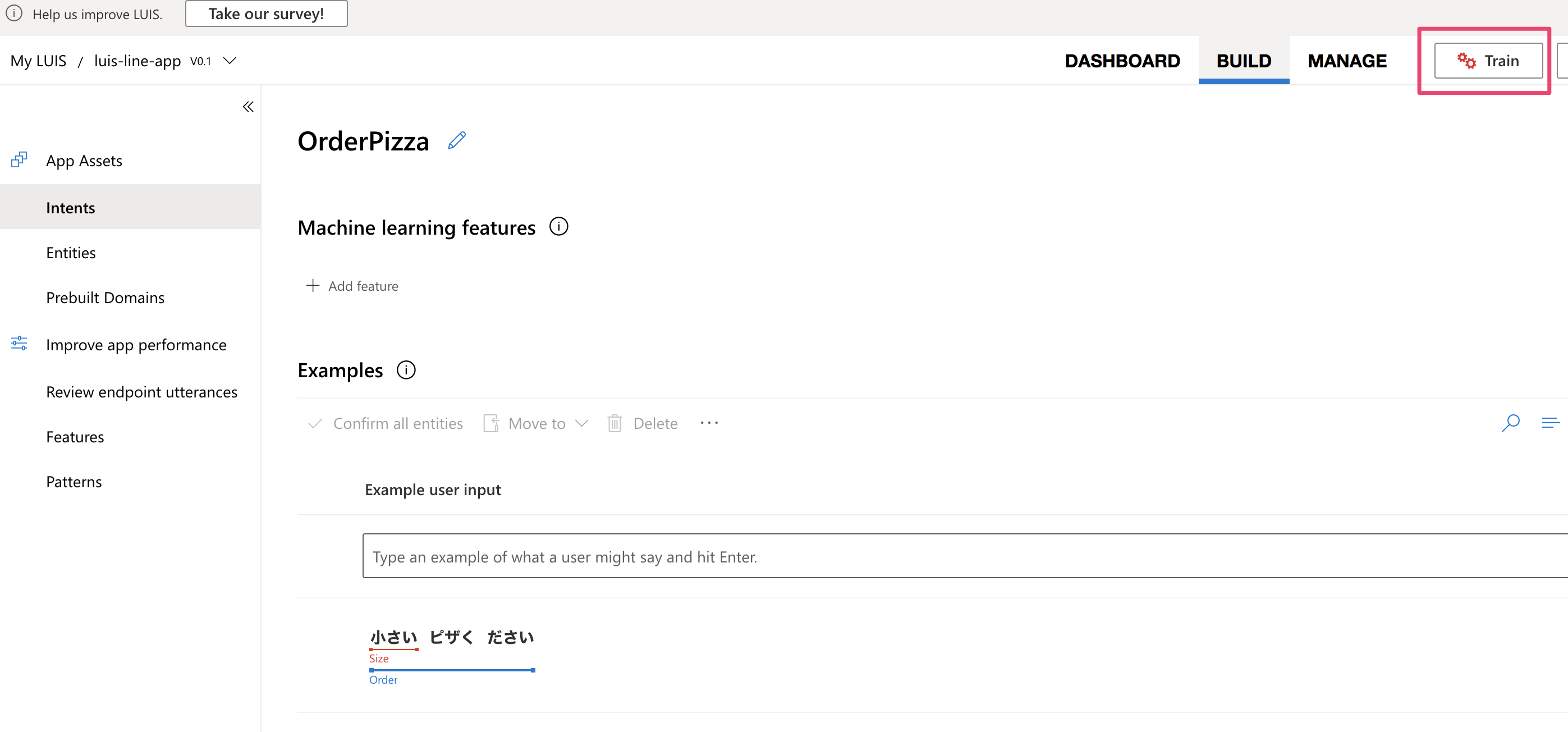
すると次に別のサンプル発話を入力した際に、これまでのサンプル発話のラベルを付けてTrain(機械学習の学習・トレーニング)してきた結果に基づいて、予測でラベル付けを自動で行うようになります。自動ラベル付けが間違ってなければ右にあるチェックマークを押して確定させます。(自動ラベル付けが間違っていた場合は、先ほど手動でラベル付けしたやり方で修正してあげます)

こうして、自動ラベル付けがどんどん正確に賢くなっていくという流れですね!まさに機械学習を活用したエンティティという感じです!
(他にも解説が必要なところがありましたら、追加していきたいと思います!)
まとめ
本来自然言語を扱う際には、前処理など多くの事をコードで処理していきますが、このLUISを使うと直感的に作業ができて分かりやすく、かつある程度裏側でよくやるような処理もやってくれていて楽ができそうです。また機械学習の作業工程は、高い精度を目指して何度も同じサイクルを回すため、このように作業やデータを管理してくれる仕組みがあると非常に繰り返しの作業も負荷が下がると思います。
次回は実際に使う事を目的に記事を書いていこうと思います。お楽しみに!
参考
- https://azure.microsoft.com/en-us/overview/ai-platform
- https://docs.microsoft.com/ja-jp/azure/cognitive-services/luis/
- https://docs.microsoft.com/ja-jp/azure/cognitive-services/luis/what-is-luis#application-development-life-cycle
- https://docs.microsoft.com/ja-jp/azure/cognitive-services/luis/whats-new
- https://docs.microsoft.com/ja-jp/azure/cognitive-services/luis/troubleshooting
- https://docs.microsoft.com/ja-jp/azure/cognitive-services/luis/luis-concept-app-iteration
- https://docs.microsoft.com/ja-jp/azure/cognitive-services/luis/luis-concept-best-practices
- https://docs.microsoft.com/ja-jp/azure/cognitive-services/luis/luis-how-plan-your-app