こんな人に
題名通り、スーパーエンジニアではないけどとりあえずTensorFlow kerasを使ってSubclassing APIで機械学習モデルを構築したい!という人のための記事です。TensorFlowのチュートリアルサイトを開くと、機械学習初心者向けとしてSequential APIが、そしてエキスパート向けとしてFunctional APIとSubclassing APIが紹介されていて、なんとなく身構えてしまいますよね、、。今回は、TensorFlowや機械学習の基本は知っているけどエキスパートではない私が、優秀な先輩に教えていただいたSubclassing APIの「お作法」を、できるだけシンプルに紹介させて頂きたいと思います。逆に言うと、それぞれのレイヤーの働きや文法の深い意味などは解説していないので、そこは大目に見ていただけると有り難いです😂
そもそもどんな時にどのAPIを使うべきなのか?
こちらのTensorFlow Blogがわかりやすくまとめていくれていたので日本語に訳して載せてみます。それぞれのAPIの利点と欠点も詳しく書いてあったので、興味がある方はこの記事を読んでみてください!
Sequential APIまたはFunctional APIが向いているパターン
- 記述の容易さを重視している
- 構築しようとしているモデルがあまり複雑ではない
- モデル構築を、レゴブロックを組み立てるようなイメージでレイヤーからなるグラフとして捉えることが好き
Subclassing APIが向いているパターン
- モデルのカスタムしやすさ(柔軟性など)を重視している
- オブジェクト指向が好きなPython/Numpy開発者
個人的には、慣れてしまえば意外とSubclassing APIがスッキリしていて読みやすい気がします。あと、Pytorchの書き方に慣れている方にも向いているのではないかと思います。
本題
今回は試しに、TensorFlow Tutorialに載っているDCGANのGeneratorを、Subclassing APIを使って書き換えていきたいと思います。Sequential APIで書かれたコードとモデルのアーキテクチャはこんな感じです。
def make_generator_model():
model = tf.keras.Sequential()
model.add(layers.Dense(7*7*256, use_bias=False, input_shape=(100,)))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Reshape((7, 7, 256)))
assert model.output_shape == (None, 7, 7, 256) # Note: None is the batch size
model.add(layers.Conv2DTranspose(128, (5, 5), strides=(1, 1), padding='same', use_bias=False))
assert model.output_shape == (None, 7, 7, 128)
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Conv2DTranspose(64, (5, 5), strides=(2, 2), padding='same', use_bias=False))
assert model.output_shape == (None, 14, 14, 64)
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Conv2DTranspose(1, (5, 5), strides=(2, 2), padding='same', use_bias=False, activation='tanh'))
assert model.output_shape == (None, 28, 28, 1)
return model
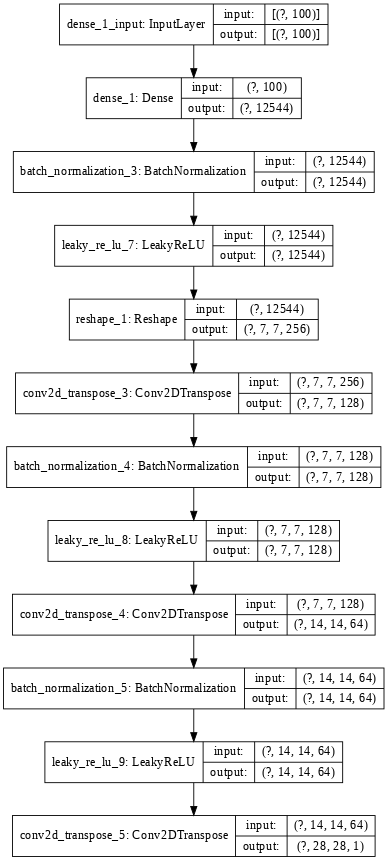
それでは早速書いてみましょう。
STEP1: まずはクラスを作る
import tensorflow as tf
class Generator(tf.keras.Model):
# class 自分で作るクラス名(tf.keras.Model)
まずはclassの定義をします。今回はクラス名をGeneratorにしています。クラス名の1文字目は、慣習として大文字にするのが主流のようです。クラス名の横にある(tf.keras.Model)はtf.keras.Modelを継承するということなのですが、とりあえずモデル構築でクラスを作るときは毎回これを書きます。
STEP2: クラスの下に必ず作る関数2つ
import tensorflow as tf
class Generator(tf.keras.Model):
def __init__(self):
def call(self, x):
クラスの下に毎回作る必要がある関数が2つあります。1つ目がinit関数で、引数として必ず(self)を持ちます。2つ目の関数はcall関数で、pytorchでいうforward関数のようなものです。call関数では毎回、(self, x)を引数として持ちます。ちなみにxはインプットのことです。
今後のイメージとしては、init関数に今回のモデル構築にあたって必要な材料を列挙して、call関数で列挙した材料を使う順番に並べていく感じです。
STEP3: init関数に使う材料を列挙
import tensorflow as tf
class Generator(tf.keras.Model):
def __init__(self):
super(Generator, self).__init__()
self.dense = tf.keras.layers.Dense(7*7*256, use_bias=False, input_shape=(100,))
self.norm1 = tf.keras.layers.BatchNormalization()
self.norm2 = tf.keras.layers.BatchNormalization()
self.norm3 = tf.keras.layers.BatchNormalization()
self.act1 = tf.keras.layers.LeakyReLU()
self.act2 = tf.keras.layers.LeakyReLU()
self.act3 = tf.keras.layers.LeakyReLU()
self.reshape = tf.keras.layers.Reshape((7,7,256))
self.conv1 = tf.keras.layers.Conv2DTranspose(128, (5, 5), strides=(1, 1), padding='same', use_bias=False)
self.conv2 = tf.keras.layers.Conv2DTranspose(64, (5, 5), strides=(2, 2), padding='same', use_bias=False)
self.conv3 = tf.keras.layers.Conv2DTranspose(1, (5, 5), strides=(2, 2), padding='same', use_bias=False, activation='tanh')
def call(self, x):
init関数を作ったら、1行目に毎回super(自分が属しているクラス名, self).__init__()を記述します。そしてその下に列挙されているのが、今回のGeneratorモデルで使うレイヤーの定義です。レイヤーの定義で覚えておくべきポイントは以下の通りです(他にもあれば随時補足していきます)。
- 常に
self.レイヤー名でレイヤーを作る(self.denseなど) - レイヤー名は慣習として小文字を使うことが多い(self.Denseではなくself.dense)
- 同じ動作をするレイヤーが複数回必要になる場合は、毎回違う名前で定義する(今回でいうself.norm1, self.norm2など)
- レイヤーに引数がある場合は、レイヤーを定義する時点で渡しておく
- Generatorに持たせたい引数がある場合は、init関数の引数として渡しておく。(例えば、
input_shapeという引数をGeneratorに持たせる場合は、def __init__(self, input_shape):となる)
STEP4: init関数で定義したレイヤーを、call関数で使う順番に並べる
import tensorflow as tf
class Generator(tf.keras.Model):
def __init__(self):
super(Generator, self).__init__()
self.dense = tf.keras.layers.Dense(7*7*256, use_bias=False, input_shape=(100,))
self.norm1 = tf.keras.layers.BatchNormalization()
self.norm2 = tf.keras.layers.BatchNormalization()
self.norm3 = tf.keras.layers.BatchNormalization()
self.act1 = tf.keras.layers.LeakyReLU()
self.act2 = tf.keras.layers.LeakyReLU()
self.act3 = tf.keras.layers.LeakyReLU()
self.reshape = tf.keras.layers.Reshape((7,7,256))
self.conv1 = tf.keras.layers.Conv2DTranspose(128, (5, 5), strides=(1, 1), padding='same', use_bias=False)
self.conv2 = tf.keras.layers.Conv2DTranspose(64, (5, 5), strides=(2, 2), padding='same', use_bias=False)
self.conv3 = tf.keras.layers.Conv2DTranspose(1, (5, 5), strides=(2, 2), padding='same', use_bias=False, activation='tanh')
def call(self, x):
out = self.dense(x)
out = self.norm1(out)
out = self.act1(out)
out = self.reshape(out)
out = self.conv1(out)
out = self.norm2(out)
out = self.act2(out)
out = self.conv2(out)
out = self.norm3(out)
out = self.act3(out)
out = self.conv3(out)
return out
call関数では、実際に行われる処理を記述します。ここでのポイントは以下の通りです。
- インプット
xを最初のレイヤーの引数として渡す - 常に
out =(resultなど名前はなんでもOK)と統一することで、実験的にあるレイヤーを消したり順番を入れ替えたりする際に、コードそのものを書き換える必要がなくて便利(例えば、self.norm3を消したいときは、out = self.norm3(out)をコメントアウトするだけで良い) - for文やif文もここで使うことができる
- 最後に
return outで構築したモデルGenerator()を返す
おわりに✌🏻
最後まで読んでいただきありがとうございます。「エキスパート向け」のSubclassing APIも意外とそんなに複雑ではない気がするので、是非使ってみて下さい!(訂正などあれば教えていただけると有り難いです。)