この記事はKaggleが提供している講座(Courses)の「Intro to Machine Learning」のLesson1について解説します。英語が弱くて機械学習のことよく知らない!!という人向けの記事です。
英語もしくは機械学習のどちらか一方が分かる人にとっては勉強になると思いますので、原著をオススメします。
こちら原著です
英語も機械学習も分かる人には、原著もこの記事も読む必要はないかと思います。
Kaggleの講座(Courses)について
Kaggleはデータ分析のコンペ(競争)を行っている企業です。サイトへはこちらを押してください 。
Kaggleはコンペだけではなく、「Courses」と呼ばれる講座&チュートリアルも無料で提供しています(英語で書かれています)。内容は、Pythonやディープラーニングなど様々あります。サイトへはこちらを押してください。
トップページから入るには、トップページの左側にCoursesがありますので、そこをクリックしてください。

KaggleのNotebookについて
Kaggleは環境構築が不要でコードが書けるNotebookというものを提供しています。この解説記事でもコードを書きますが、全てNotebookで動作させています。Notebookを使う利点は、環境構築が不要なこと以外に、コンペのデータがすでに入っていてわざわざダウンロードする必要がないということがあります。
・Notebookの使い方
参加したいコンペのページにいきます。参加したいコンペは上に載せた写真の「Courses」の並びの上から2つ目にある「Compete」からコンペを選べます。今回はメルボルンの住宅価格予測のコンペに出るとします。こちらを押していただくと、次のような画面が出ますので「New Notebook」を押してください。

そこにコードを書けば出力されるようになっています。
動画でも説明しました。動画はこちらです。
機械学習入門(Intro to Machine Learning)
今回は「Corses」の「Intro to Machine Learning」の解説します。この講座はこれからKaggleや機械学習をはじめようという人向けのものです。
Lesson1〜Lesson7 + Bonus Lesson(2つ)あります。
<目次>
Lesson1 モデルはどのようにして機能するのか
Lesson2 データ理解の基礎
Lesson3 はじめての機械学習モデル
Lesson4 モデルの検証
Lesson5 未学習と過学習
Lesson6 ランダムフォレスト
Lesson7 機械学習のコンペをはじめよう
Bonus Lessons
・AutoML(自動化された機械学習)の入門
・Titanicコンペをはじめてみよう
この記事ではLesson1を解説します。1つの記事に1Lessonということでいきたいと思います。
<Lesson1>モデルはどのようにして機能するのか
・機械学習モデルへの招待
このレッスンでは、機械学習のモデルがどのように動くのか、そしてどのように使われるかということの概要を解説しています。
まず機械学習モデルがどのように使えるかの例として、家の価格予測というものがあります。過去の家のデータ(家の面積、駅からの距離など)と価格のセットを機械学習することで、将来の不動産の価格を予測するということです。このように過去のパターンから未来を予測するというのは、人間もやっているかもしれません。人間だと「直感」と呼ばれたりしますが、その「直感」に当たる部分が機械学習のモデルになっているというイメージです。
機械学習のモデルにはたくさんの種類がありますが、今回は決定木という最もシンプルなものについて解説していきます。決定木はシンプルですが、他の素晴らしいモデルの基礎だったりします。
図で見ていきましょう。下の図はKaggleの講座で実際に使われているものです。

家の価格予測を考えているのですが、この決定木は家の中にベットが2個より多いかどうかという基準のみで予測するという最もシンプルな決定木です。上の四角の中には「家にベッドが2個より多くありますか?」という質問があり、左はNoのとき(つまりベッドが2個以下の家)の価格予測($178000)、右はYesの時(つまりベッドが2個より多い家)の価格予測($18800)となっています。2つのカテゴリーの予測価格は、それぞれのカテゴリーに属する家の価格の平均です。
この決定木は深さが1で判断基準がベットの数だけという風にシンプルでおそらく精度は高くないでしょう。木を深くすることで、多くの判断基準を用いて価格を予測することができます。
この決定木を作るためにデータは2つの使われ方をしています。
・どのように家をカテゴリー分けするかを決めるため(今回は家のベッド数で分類)
・カテゴリーごとの予測価格はどうするかを決めるため(今回はそれぞれのカテゴリーに含まれる家の価格の平均)
このようにモデル(決定木)にデータを当てはめる段階を「モデルのトレーニング」と言ったりします。モデルのトレーニングのために使われるデータをトレーニングデータと言います。モデルをトレーニングし終えたあと、未知のデータ(不動産のデータ)をモデルに入力することで予測した値(不動産価格)が出力されることになります。未知のデータとは、トレーニングの時に使わなかったデータのことです。家の価格予測の例では、価格予測したい家のデータということになります。
・決定木の精度の向上
先ほどの決定木は、家のベッド数のみで家の価格を予測したわけですが、それでは精度が低いと思います。なぜなら、家の価格を決めるのにもっと重要な基準があるからです。例えば、家の敷地面積、家の立地などです。ということで、もう一つ基準を加えたのが以下のKaggle公式講座にある図(決定木)です。
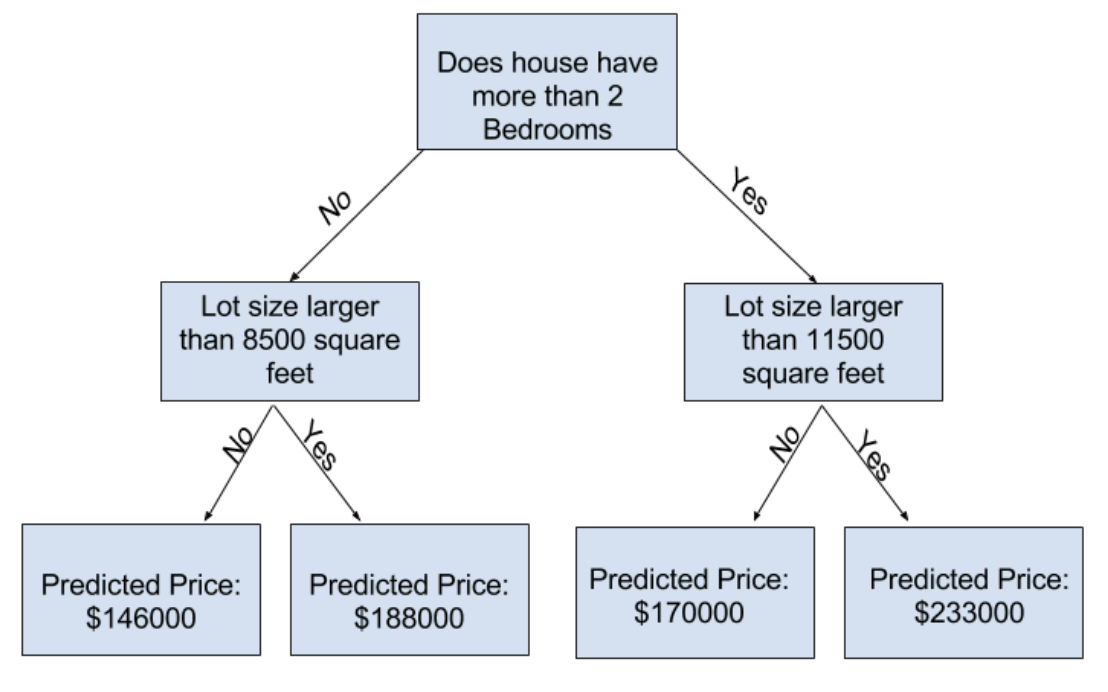
この決定木のはじめの判断基準は先ほどと同様にベッド数で2つのカテゴリーに分けています。先ほどと違うのはもう1つ判断基準があるということです。もう1つ判断基準は、家の敷地面積です。具体的には、ベッド数が2個以下のカテゴリーに対しては、敷地面積が8500㎡より大きいか(Yes)そうでないか(No)という基準になっており、ベッドが2個より多いカテゴリーに対しては、敷地面積が11500㎡より大きいか(Yes)そうでないか(No)という基準になっています。
住宅のデータ(ベッド数・敷地面積)と照らしながら、この決定木をたどることで住宅価格を予測することができます。
機械学習によるデータ分析で行うことは、決定木を使うとするならば、どの基準でカテゴリー分けするのか、カテゴリー分けした結果の予測価格はいくらにするのかなどをデータから決めることです。そのためには、データの理解や扱い方を知る必要があります。それを次のLesson2で学ぶことになります。
では頑張っていきましょう。
Lesson2はこちらになります。