この記事はKaggleが提供している講座(Corses)の「Intro to Machine Learning」のLesson4について解説します。「英語が弱くて機械学習のことよく知らない!!」という人向けの記事です。
英語もしくは機械学習のどちらか一方が分かる人にとっては勉強になると思いますので、原著をオススメします。
こちら原著です
英語も機械学習も分かる人には、原著もこの記事も読む必要はないかと思います。
Lesson3はこちらをクリック
<Lesson4>モデルの検証
データはこちらのコンペのものを使っていきます。
コードはKaggleの環境構築が要らないNotebookで動作させています。
Notebookについてはこちらへ。
Lesson3ではモデルを作りました。今回は、その作ったモデルは良いモデルなのかということを考えます。良いモデルとは、予測の精度が良いモデルのことです。今回は、予測の精度がどれくらい良いのかということを検証する方法について解説していきます。モデルの検証を行うことで、モデルを改善すべきかどうかを考えることができます。
・モデルの検証とは何か?
モデルの検証とは、モデルの予測が現実(正解)とどれだけ近いかを測ることです。それを具体的な数値で出す方法はいくつかありますが、今回は平均絶対誤差(MAE:Mean Absolute Error)を用いていきます。MAEと呼ばれることが多いような気がしますので、今後はMAEとします。
MAEのAE(絶対誤差)の部分は
|現実 - 予測|
となります。
Mは平均(mean)という意味なので、MAEは全てのデータの絶対誤差を平均するということになります。
例えば以下のような現実と予測があったとしましょう。
| 現実 | 予測 | 絶対誤差 |
|---|---|---|
| 1000万円 | 1500万円 | 500 |
| 2000万円 | 1700万円 | 300 |
| 1600万円 | 1700万円 | 200 |
すると、MAEは以下のように計算できます。
それぞれの絶対誤差をとり、それらを平均すると、以下のようになります。
| 1000 - 1500 | = 500\\
| 2000 - 1700 | = 300\\
| 1600 - 1700 | = 100\\
--------------\\
\frac{500 + 300 + 100}{3} = 300
前回のLesson3の最後ではトレーニングデータを用いて予測を行いました。今回はその予測結果と現実のPriceを用いてMAEを求めるということをやっていきます。まずは、前回までのコードを載せておきます。
# データ読み込みと特徴量選択
import pandas as pd
df = pd.read_csv('../input/melbourne-housing-snapshot/melb_data.csv')
y = df.Price
features = ['Rooms', 'Bathroom', 'Landsize', 'Lattitude', 'Longtitude']
X = df[features]
# モデルの学習と予測
from sklearn.tree import DecisionTreeRegressor
model = DecisionTreeRegressor(random_state=1)
model.fit(X, y)
predictions = model.predict(X)
MAEを求めるにはscikit-learnのmean_absolute_errorというクラスをインポートします。
# sklearn.metricsにあるmean_absolute_errorをインポート。
from sklearn.metrics import mean_absolute_error
# y(現実)とpredictions(予測値)の平均絶対誤差をとる。
mean_absolute_error(y, predictions)
出力は以下のようになります。

前回のLesson3でも書きましたが、トレーニングデータで予測を行って検証を行うということは基本的にしてはいけません。
・トレーニングデータで予測・検証を行うことの問題点
なぜ、トレーニングデータで予測・検証を行ってはいけないのでしょうか?その理由について、Kaggleのチュートリアルでは以下のような例を出しています。
日本語訳
巨大な不動産のマーケットにおいて、ドアの色と家の値段には関係がないですよね。しかし、モデルを訓練するためのデータにおいて、緑のドアがついた全ての家がとても高かったとします。モデルの仕事は家の値段を予測するためのパターンを見つけることなので、モデルは「緑のドアがついた家は高い」というパターンを発見し、緑のドアを持つ家の値段は常に高く予測するということになるでしょう。
またこのパターンはトレーニングデータから見つけたので、モデルはトレーニングデータで検証しても正確な値を出しているように見えます。
しかし、新しいデータをモデルが処理する時にこのパターンが通用しないなら、そのモデルは実際使われる時に的外れな値を出すことになるでしょう。
分かりやすい例だと思って日本語訳してみました。トレーニングデータに偏りがあった場合、その偏りを学習してしまうということですね。でも、その偏りが新しいデータには当てはまらない場合、モデルとしての精度が低くなるということです。この問題を解決するための方法の一つとして、モデルをトレーニングする時にいくつかのデータを除外して、その除外したデータで検証するという方法があります。この検証するのに使うデータをバリデーション(検証)データといいます。
なので、モデル構築の前に、持っているデータをトレーニングデータとバリデーションデータに分けるということが必要になります。
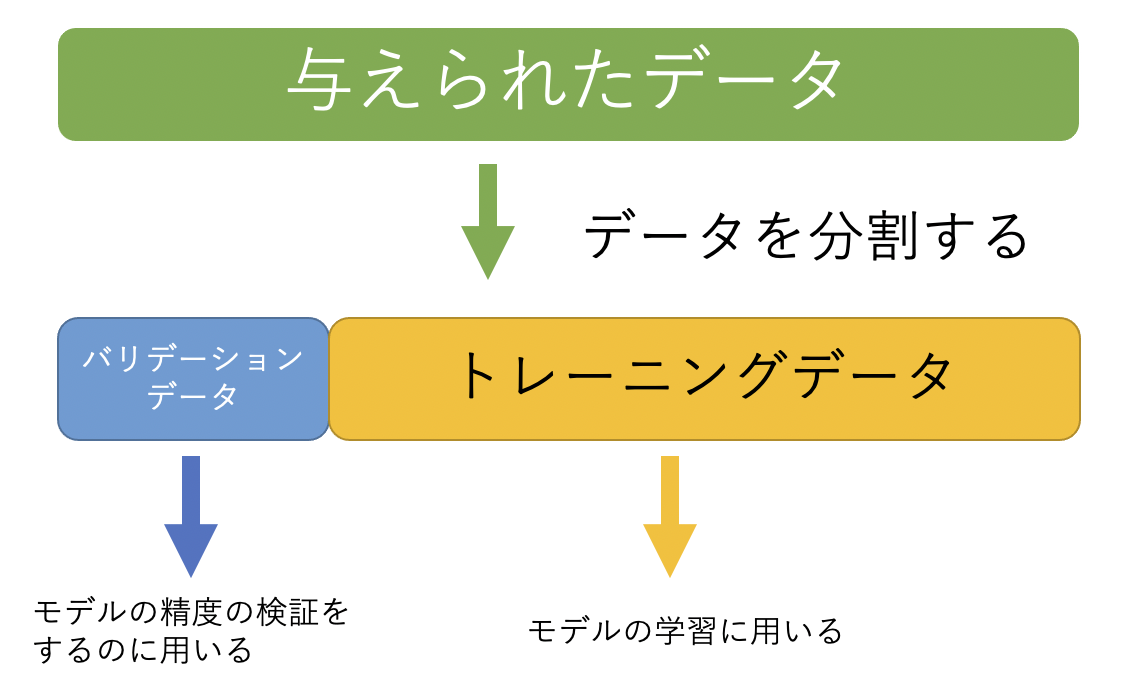
・コーディング!!
scikit-learnのライブラリにはtrain_test_splitという関数があり、それを用いることで、データをトレーニングデータとバリデーションデータに分けることができます。データを分けた後、トレーニングデータでモデルの訓練を行い、訓練済みモデルで予測を行って、予測結果をバリデーションデータで検証します。この流れをコードにしたのが以下になります。
# モデルの分割
from sklearn.model_selection import train_test_split
train_X, val_X, train_y, val_y = train_test_split(X, y, random_state = 0)
# モデルの学習と予測
from sklearn.tree import DecisionTreeRegressor
model = DecisionTreeRegressor(random_state=1)
model.fit(train_X, train_y)
val_predictions = model.predict(val_X)
# モデルの検証
from sklearn.metrics import mean_absolute_error
print(mean_absolute_error(val_predictions, val_y))
これの出力結果が以下のようになります。

先ほど行ったトレーニングデータでの検証結果はこちらです。
トレーニングデータの検証で誤差平均が千ドル程度なのに対して、バリデーションデータの検証で誤差平均が25万ドルになります。全く違いますね!トレーニングデータに当てはまるパターンが他のデータには当てはまらなかったということですね。このような場合があるので、トレーニングデータで検証を行うということはしません。
ということで、今回の内容はモデルの検証でした。特に、データをモデルをトレーニングするためのデータと検証するためのデータに分けましょう!という話ですね。次回は、Lesson5「未学習と過学習」について解説していきます。
頑張っていきましょう!!