この記事はKaggleが提供している講座(Corses)の「Intro to Machine Learning」のLesson3について解説します。英語が弱くて機械学習のことよく知らない!!という人向けの記事です。
英語もしくは機械学習のどちらか一方が分かる人にとっては勉強になると思いますので、原著をオススメします。
こちら原著です
英語も機械学習も分かる人には、原著もこの記事も読む必要はないかと思います。
Lesson2はこちらをクリック
<Lesson3>はじめての機械学習モデル
データはこちらのコンペのものを使っていきます。
コードはKaggleの環境構築が要らないNotebookで動作させています。
Notebookについてはこちらへ。
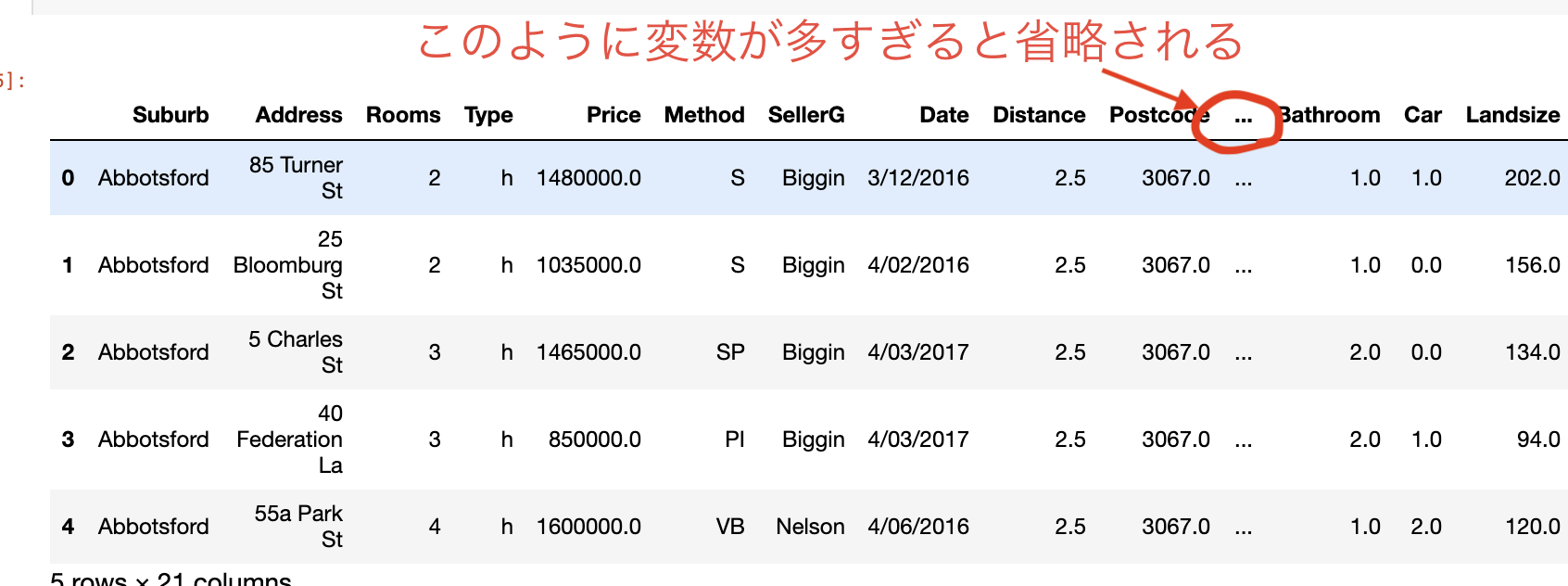
まずは、データを見ていきましょう。データはざっくりこんな感じです。
・モデル構築のための変数選択
Kaggleで使われるデータの変数というのはほとんどの場合、とても多いです。今回用いる住宅価格を予測するためのデータの変数も例外ではありません。実際にみてみましょう。
このようにコードを打つと
import pandas as pd
df = pd.read_csv('../input/melbourne-housing-snapshot/melb_data.csv')
# df.head() このやり方だと上のデータのように変数が多い場合に全ての列が表示されません
df.columns
このような結果が出力されます。

今回のデータセットでは21個の変数(列)があるということになります。
##### 変数選択 まず予測する対象となる変数を選択します。今回でいうと、住宅価格ですね。変数名でいうと、上の出力(Indexで囲まれているリスト)の左から5番目の変数'Price'ですね。予測する対象は基本的に変数yに入れられます。次のコードでPriceの列のデータをyに代入できます。
y = df.Price
そして、予測を行うのに用いる変数を特徴量と呼びます。モデルに特徴量のデータを入力することで、モデルが予測を行えるようになります。今回のデータでいうと例えば、'Address'(住所)、'Rooms'(部屋の数)などが特徴量の候補となります。 特徴量ですが、予測を行う変数(Price)以外の全てとすることもあれば、予測するのに必要だと判断した変数のみをピックアップして特徴量とすることもあります。 Kaggleの講座では、限られた変数のみをピックアップして特徴量としています。特徴量のデータは変数Xに入れられることが多いので、今回もそのようにします。 以上のことをコードにするとこのようになります。
features = ['Rooms', 'Bathroom', 'Landsize', 'Lattitude', 'Longtitude']
X = df[features]
featuresに格納されている文字列が特徴量の列名です。そして、Xにfeaturesに含まれる列のデータが入ります。
列名の意味は以下のようになります。
| 1 | 2 |
|---|---|
| Rooms | 家にある部屋の数 |
| Bathroom | 家にある風呂の数 |
| Landsize | 敷地面積 |
| Lattitude | 緯度 |
| Longtitude | 経度 |
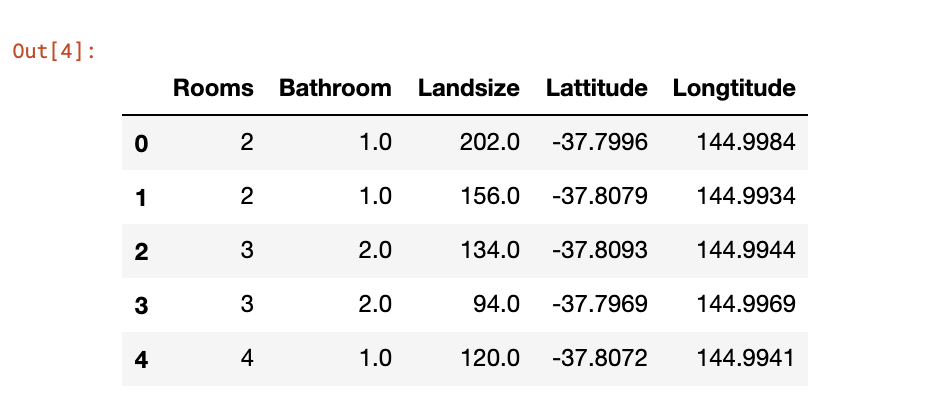
Xを少し見ておきましよう。次のようなコードではじめの5行のみが表示されます。
X.head()
こんな感じで出力されます。
### ・モデル構築 モデル構築はscikit-learn(サイキット・ラーン)というライブラリを用いて行います。scikit-learnは人気のある機械学習ライブラリの一つで、これを使うことで簡単にモデルを構築できます。
モデル構築と活用の4ステップ
1、モデルの定義
どのモデルを用いるのかをここで選択します。さらに、モデルのパラメータについてもここで決めます。モデルというのは、Lesson2でやった決定木などのことです。
2、モデルへトレーニングデータを当てはめる
与えられたデータをモデルに入力することで、データのパターンを捉えます。このステップがモデリングの核となる部分です。「学習」や「訓練」と呼ばれたりします。
3、予測
トレーニングデータになかった未知のデータを学習済みのモデルに入力することで、予測を行います。
4、評価
3で行った予測がどれくらい正確かを数値で出します。
4ステップのうちの1と2をscikit-learnでコードにすると、以下のようになります。
# scikit-learnから決定木のモデルを持ってくる。(sklearn.treeの下にあるDecisionTreeRegressorをインポート)
from sklearn.tree import DecisionTreeRegressor
# modelを決定木とする(1ステップ目)。
model = DecisionTreeRegressor(random_state=1)
# データXとyをmodelに当てはめる(2ステップ目)
model.fit(X, y)
2行目のコードのrandom_state=1ですが、random_stateを指定することで何度実行しても毎回同じ結果が出力されます。今回は1としていますが、どのような値を入れてもモデルの質に影響はありません。
では最後にステップ3の予測を行ってみましょう。普通はこのようなことはしませんが、トレーニングデータXで予測を行ってみます。通常は、トレーニング(ステップ2)で用いなかったデータを利用して予測を行います。 以下のようなコードになります。
predictions = model.predict(X)
print(predictions)
このような出力になります。
 この出力が、モデルが出した住宅価格の予測になります。
この出力が、モデルが出した住宅価格の予測になります。
これで「Lesson3:初めて作る機械学習モデル」は終わります。scikit-learnというライブラリを用いることで、コーディング自体はとても短く書けることが分かると思います。1〜3ステップがそれぞれ1行ずつで書くことができます。 最後にもう一度まとめると
# ステップ1(モデル定義)
model = DecisionTreeRegressor(random_state=1)
# ステップ2(モデルの学習)
model.fit(X, y)
# ステップ3(モデルによる予測)
predictions = model.predict(X)
の3ステップを行いました。次回は「Lesson4:モデルの検証」を行います。具体的にはステップ4の評価をやっていくことになります。
では頑張っていきましょう!!