1. はじめに
- 業務で使っているサーバ(RHEL8)が、時々CPU100%に張り付いてしまうことがあり、やむをえずOS再起動で復旧させている。
- 事象発生時にカーネルクラッシュダンプ(以降はダンプと表記)を取得すれば、原因調査の一助となるかと思い、まずはダンプの取得手順を確認する。
2. やったこと
- 外部から「診断割込み」を受信した際に、ダンプを生成してからOS再起動するようにRHEL8サーバを設定する。
- AWSコマンドで対象サーバに「診断割込み」を送信し、ダンプが生成された上でOS再起動されることを確認する。
- 作成されたダンプの中身を簡単に確認してみる。
3. 構成図
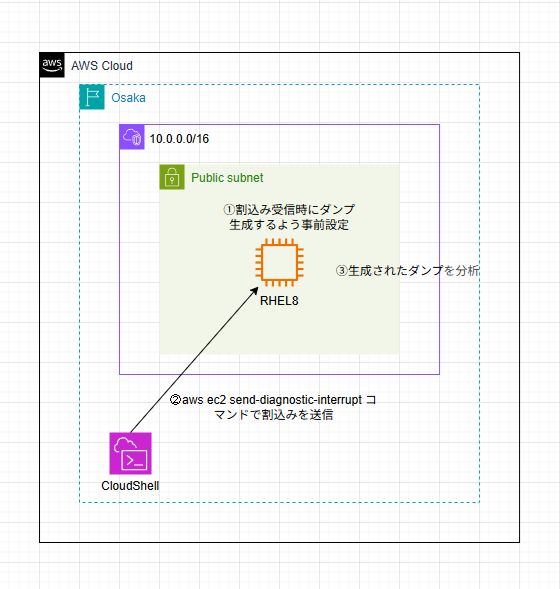
4. 予習
主に以下のサイトを見て、大まかな仕組みや必要なツールを確認した。
-
- RHEL7でのダンプの取得手順の説明。やや古い内容はあるが概ねこれで雰囲気が分かる。
-
How to troubleshoot kernel crashes, hangs, or reboots with kdump on Red Hat Enterprise Linux
- RHEL各バージョンでのダンプの取得手順の説明。
-
診断割り込みを送信して到達不能の Amazon EC2 インスタンスをデバッグする
- AWS環境内のサーバに対し、AWSコマンドで「診断割込み」を送信する手順。
-
- 取得したダンプの解析方法。ここは難しいのでさわりだけ、、
結果として、以下の段取りが必要と理解した。
- ダンプを取得するための前提条件として、kdumpがインストールされ、かつ適切に動作している必要がある。
- 「診断割込み」を受信した時にkdumpによるダンプ生成が発動するように、/etc/sysctl.confに設定が追加されている必要がある。
- aws ec2 send-diagnostic-interrupt コマンドを用いて、外部から「診断割込み」を送信することができる。
- crashコマンドなど各種ツールをインストールして、生成されたダンプを分析することができる。
5. 手順
5.1 事前準備
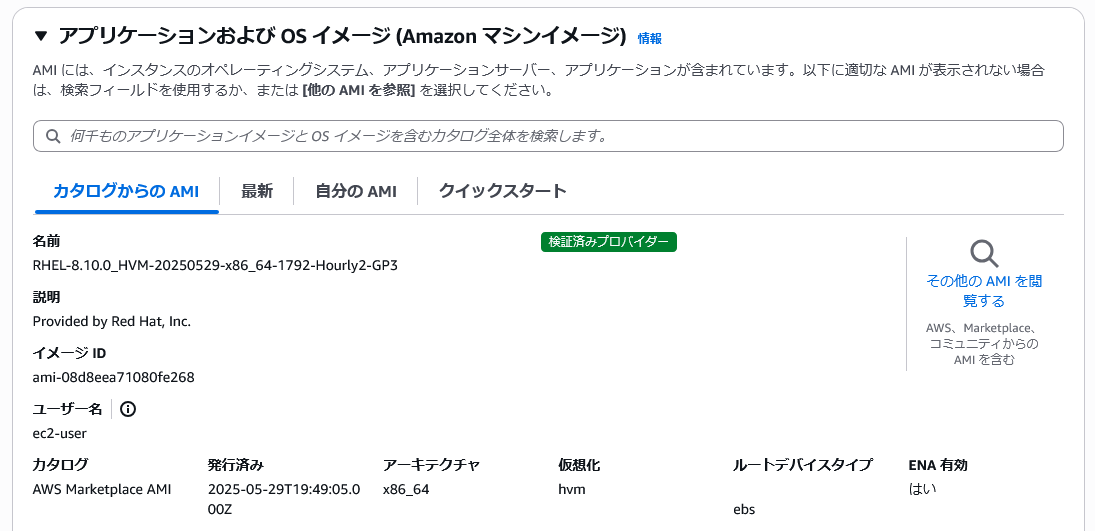
- テスト用のEC2インスタンス(RHEL8)を作成する。
- AMI: 以下のもの
- サイズ: t3.medium (2vcpu, 4GB mem)

5.2 kdump の状態確認
- ダンプを取得するには、kdumpがインストールされ、動作している必要がある。今回使用したRHEL8のAMIでは、追加の設定は不要で、kdumpの準備が整った状態になっていた。
[ec2-user@ip-10-0-0-153 ~]$ sudo systemctl status kdump
● kdump.service - Crash recovery kernel arming
Loaded: loaded (/usr/lib/systemd/system/kdump.service; enabled; vendor preset: enabled)
Active: active (exited) since Tue 2025-10-07 04:36:11 UTC; 35min ago
Process: 1075 ExecStart=/usr/bin/kdumpctl start (code=exited, status=0/SUCCESS)
Main PID: 1075 (code=exited, status=0/SUCCESS)
5.3 ダンプのテスト取得
- まずはOS内でのテストコマンドにより、ダンプ取得ができることを確認する。「echo c > /proc/sysrq-trigger」は、即座にカーネルパニックを発生させ、システムをクラッシュさせるコマンド。
[ec2-user@ip-10-0-0-153 ~]$ sudo su -
[root@ip-10-0-0-153 ~]# echo c > /proc/sysrq-trigger
- コマンド実行後、ダンプ生成とOS再起動が行われる。sshで再接続後、/var/crash に、ダンプ(vmcore)および付属ファイルが生成されていることを確認する。
[ec2-user@ip-10-0-0-153 crash]$ pwd
/var/crash
[ec2-user@ip-10-0-0-153 crash]$ ls
127.0.0.1-2025-10-07-05:23:24
[ec2-user@ip-10-0-0-153 crash]$ ls 127.0.0.1-2025-10-07-05\:23\:24/
kexec-dmesg.log vmcore vmcore-dmesg.txt
5.4 「診断割込み」受信時にダンプ生成が動作するように設定
- 前項ではコマンド実行でダンプ生成を発生させたが、CPU100%のハング時はコマンド実行ができないため、「診断割込み」受信時にダンプ生成が発生するように追加設定を行う。
- /etc/sysctl.conf (デフォルトでは中身はコメント行のみ)に以下の行を追加する。(nmi: Non-Maskable Interrput(割込み)を受けた際にカーネルパニックするような設定)
/etc/sysctl.conf
kernel.unknown_nmi_panic = 1
kernel.panic_on_io_nmi = 1
kernel.panic_on_unrecovered_nmi = 1
- 設定内容を反映させる。
[ec2-user@ip-10-0-0-153 etc]$ sudo sysctl -p
5.5 「診断割込み」トリガによるダンプ生成
- 一応、CPU高負荷状態でもダンプが取れることを確認するため、yesコマンドx2でCPU使用率を上げておく。
[ec2-user@ip-10-0-0-153 ~]$ yes > /dev/null &
[1] 1659
[ec2-user@ip-10-0-0-153 ~]$ yes > /dev/null &
[2] 1660
[ec2-user@ip-10-0-0-153 ~]$ top
top - 06:49:28 up 40 min, 2 users, load average: 0.88, 0.47, 0.29
Tasks: 99 total, 3 running, 96 sleeping, 0 stopped, 0 zombie
%Cpu(s): 32.9 us, 66.9 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.2 hi, 0.0 si, 0.0 st
MiB Mem : 3586.1 total, 3254.6 free, 133.1 used, 198.4 buff/cache
MiB Swap: 0.0 total, 0.0 free, 0.0 used. 3233.5 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1659 ec2-user 20 0 7396 856 784 R 100.0 0.0 0:26.10 yes
1660 ec2-user 20 0 7396 840 768 R 100.0 0.0 0:24.58 yes
- CloudShell (EC2関連の権限があるユーザ) から、診断割込みコマンドを実行する。5.3項のテストコマンド実行時と同様に、/var/crashにダンプが生成され、OS再起動が行われる。
~ $ aws ec2 send-diagnostic-interrupt --instance-id i-xxxxxxxxxxxxxxxx
- 参考まで、前項の/etc/sysctl.confの設定変更をせずに、awsコマンドで「診断割込み」を送信した場合、ターミナルに以下(割込み信号が来ていること)が表示されるが、ダンプ生成やOS再起動は発生しない。
Message from syslogd@ip-10-0-0-153 at Oct 7 05:32:50 ...
kernel:Uhhuh. NMI received for unknown reason 00 on CPU 0.
Message from syslogd@ip-10-0-0-153 at Oct 7 05:32:50 ...
kernel:Do you have a strange power saving mode enabled?
Message from syslogd@ip-10-0-0-153 at Oct 7 05:32:50 ...
kernel:Dazed and confused, but trying to continue
5.6 ダンプの分析
- 生成されたダンプを自分で分析できればベストだが、正直かなり難しそう。実際にはサポートに調査依頼などを行うとして、今回は分析環境を準備し、一応ダンプが開けるところまでを実施してみる。
- 「カーネルクラッシュダンプの解析方法」を見ながら、できるところまで行う。
- ダンプを生成しているRHEL8サーバ上で、そのまま分析作業も行う。
5.6.1 分析環境の準備
- ダンプを開いて中身を見るにはいろいろツールを整える必要があり、以下順番にインストール、設定を行う。
- stringsコマンドを用いるため、binutilsパッケージを追加する。
[ec2-user@ip-10-0-0-153 ~]$ sudo dnf install binutils
- ダンプ(vmcore)のあるディレクトリに移動し、stringsコマンドで対象のダンプが生成されたサーバのカーネルバージョンを特定する。
[ec2-user@ip-10-0-0-153 127.0.0.1-2025-10-07-06:59:54]$ pwd
/var/crash/127.0.0.1-2025-10-07-06:59:54
[ec2-user@ip-10-0-0-153 127.0.0.1-2025-10-07-06:59:54]$ ls
kexec-dmesg.log vmcore vmcore-dmesg.txt
[ec2-user@ip-10-0-0-153 127.0.0.1-2025-10-07-06:59:54]$ sudo strings vmcore |head
KDUMP
Linux
ip-10-0-0-153.ap-northeast-3.compute.internal
4.18.0-553.54.1.el8_10.x86_64
#1 SMP Sat May 17 16:41:33 EDT 2025
x86_64
(none)
CORE
CORE
VMCOREINFO
- 該当のカーネルバージョンを指定して debug-info をインストールする。
[ec2-user@ip-10-0-0-153 ~]$ sudo dnf debuginfo-install kernel-4.18.0-553.54.1.el8_10
- crashコマンドをインストールする。
[ec2-user@ip-10-0-0-153 ~]$ sudo dnf install crash
5.6.2 ダンプを開いてみる
- 今回はダンプを開いて簡単なコマンドを実行するのみ(奥が深そう、、)。
- debuginfoの場所と、ダンプ(vmcore)を指定して、crashコマンドを実行する。ダンプ生成時のサーバの情報が表示される。
[ec2-user@ip-10-0-0-153 127.0.0.1-2025-10-07-06:59:54]$ sudo crash /usr/lib/debug/usr/lib/modules/4.18.0-553.54.1.el8_10.x86_64/vmlinux vmcore
crash 8.0.4-2.el8
Copyright (C) 2002-2022 Red Hat, Inc.
Copyright (C) 2004, 2005, 2006, 2010 IBM Corporation
Copyright (C) 1999-2006 Hewlett-Packard Co
Copyright (C) 2005, 2006, 2011, 2012 Fujitsu Limited
Copyright (C) 2006, 2007 VA Linux Systems Japan K.K.
Copyright (C) 2005, 2011, 2020-2022 NEC Corporation
Copyright (C) 1999, 2002, 2007 Silicon Graphics, Inc.
Copyright (C) 1999, 2000, 2001, 2002 Mission Critical Linux, Inc.
Copyright (C) 2015, 2021 VMware, Inc.
This program is free software, covered by the GNU General Public License,
and you are welcome to change it and/or distribute copies of it under
certain conditions. Enter "help copying" to see the conditions.
This program has absolutely no warranty. Enter "help warranty" for details.
GNU gdb (GDB) 10.2
Copyright (C) 2021 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law.
Type "show copying" and "show warranty" for details.
This GDB was configured as "x86_64-pc-linux-gnu".
Type "show configuration" for configuration details.
Find the GDB manual and other documentation resources online at:
<http://www.gnu.org/software/gdb/documentation/>.
For help, type "help".
Type "apropos word" to search for commands related to "word"...
KERNEL: /usr/lib/debug/usr/lib/modules/4.18.0-553.54.1.el8_10.x86_64/vmlinux
DUMPFILE: vmcore [PARTIAL DUMP]
CPUS: 2
DATE: Tue Oct 7 06:59:49 UTC 2025
UPTIME: 00:50:38
LOAD AVERAGE: 2.03, 1.85, 1.16
TASKS: 115
NODENAME: ip-10-0-0-153.ap-northeast-3.compute.internal
RELEASE: 4.18.0-553.54.1.el8_10.x86_64
VERSION: #1 SMP Sat May 17 16:41:33 EDT 2025
MACHINE: x86_64 (2500 Mhz)
MEMORY: 3.9 GB
PANIC: "Kernel panic - not syncing: NMI: Not continuing"
PID: 1660
COMMAND: "yes"
TASK: ffff8f5701e14000 [THREAD_INFO: ffff8f5701e14000]
CPU: 0
STATE: TASK_RUNNING (PANIC)
crash>
- log コマンドで、ダンプ生成までの経緯(NMIを受信してカーネルパニックしたこと)が確認できる。
crash> log
~省略~
[ 3.206408] systemd[1]: Starting Journal Service...
[ 3.556726] input: PC Speaker as /devices/platform/pcspkr/input/input5
[ 3.566707] piix4_smbus 0000:00:01.3: SMBus base address uninitialized - upgrade BIOS or use force_addr=0xaddr
[ 3.585897] parport_pc 00:03: reported by Plug and Play ACPI
[ 3.670121] RAPL PMU: API unit is 2^-32 Joules, 0 fixed counters, 10737418240 ms ovfl timer
[ 3.703417] ppdev: user-space parallel port driver
[ 6.202118] IPv6: ADDRCONF(NETDEV_UP): eth0: link is not ready
[ 6.205256] IPv6: ADDRCONF(NETDEV_UP): eth0: link is not ready
[ 6.217210] IPv6: ADDRCONF(NETDEV_UP): eth0: link is not ready
[ 6.223232] IPv6: ADDRCONF(NETDEV_UP): eth0: link is not ready
[ 6.880033] IPv6: ADDRCONF(NETDEV_CHANGE): eth0: link becomes ready
[ 3037.931404] Uhhuh. NMI received for unknown reason 00 on CPU 0.
[ 3037.931406] Do you have a strange power saving mode enabled?
[ 3037.931407] Kernel panic - not syncing: NMI: Not continuing
[ 3037.931408] CPU: 0 PID: 1660 Comm: yes Kdump: loaded Not tainted 4.18.0-553.54.1.el8_10.x86_64 #1
[ 3037.931409] Hardware name: Amazon EC2 t3.medium/, BIOS 1.0 10/16/2017
[ 3037.931410] Call Trace:
[ 3037.931410] <NMI>
[ 3037.931411] dump_stack+0x41/0x60
[ 3037.931411] panic+0xe7/0x2ac
[ 3037.931412] ? printk+0x58/0x73
[ 3037.931413] nmi_panic.cold.11+0xc/0xc
[ 3037.931413] unknown_nmi_error.cold.12+0x47/0x55
~省略~
- ps コマンドで、ダンプが生成された時点のプロセス(yesがCPUを使用中など)が確認できる。
crash> ps
PID PPID CPU TASK ST %MEM VSZ RSS COMM
0 0 0 ffffffffbd418840 RU 0.0 0 0 [swapper/0]
0 0 1 ffff8f5700c6c000 RU 0.0 0 0 [swapper/1]
1 0 1 ffff8f5700bc8000 IN 0.3 175092 13412 systemd
2 0 0 ffff8f5700be0000 IN 0.0 0 0 [kthreadd]
~省略~
1646 2 0 ffff8f5703758000 ID 0.0 0 0 [kworker/0:2]
1658 2 1 ffff8f5700ca4000 ID 0.0 0 0 [kworker/1:2]
> 1659 1494 1 ffff8f570767c000 RU 0.0 7396 1780 yes
> 1660 1494 0 ffff8f5701e14000 RU 0.0 7396 1980 yes
1668 2 1 ffff8f5711de4000 ID 0.0 0 0 [kworker/1:1]
1741 2 1 ffff8f570331c000 ID 0.0 0 0 [kworker/1:0]
1742 2 0 ffff8f570341c000 ID 0.0 0 0 [kworker/0:0]
1743 2 0 ffff8f5701ed0000 ID 0.0 0 0 [kworker/0:1]
6. 所感
- とりあえずダンプ生成の仕込み方が分かった。早く実際の不具合事象発生時(CPU100%張り付き時)にダンプ取得し、分析してみたいので、不具合が再発するのが少し待ち遠しい。