はじめに
機械学習のシステム化に際して、データの前処理に要する時間やリソースを考慮し、設計に活かすノウハウが求められています。
本投稿では、自然言語を対象としたデータ前処理の概要と、感情極性分析の実装例であるchABSA-datasetにおけるデータ前処理を題材とした性能検証結果を紹介します。
投稿一覧
- 自然言語処理とその前処理の概要
- 自然言語処理におけるデータ前処理の性能検証 ... 本投稿
本投稿の目次は以下です。
3. 自然言語処理の前処理に必要となるリソースと処理時間の例
ここでは、chABSA-dataset におけるデータ前処理(前編の表2)を実行し、必要となったリソース量や処理時間を検証します。特に、分かち書き処理にて利用するライブラリを Janome から MeCab に変更し、双方のパターンにおけるリソース量や処理時間を比較します。
3.1 検証環境
今回の実験にて使用した仮想マシン(Virtual Machine, VM) の性能を表4 に示します。
表4 検証に利用したVMのスペック
| 項目 | 項目名 |
|---|---|
| OS | Red Hat Enterprise Linux Server 7.7 (Maipo) |
| CPU | Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.5GHz |
| CPUコア数 | 8 |
| ハイパースレッディング | オフ |
| メモリ容量 | 16GB |
| HDD容量 | 160GB |
| HDDシーケンシャルRead | 166MB/s |
| HDDシーケンシャルWrite | 487 MB/s |
| HDDランダムRead(4k,QD32) | 68MB/s |
| HDDランダムWrite(4k, QD32) | 71MB/s |
画像処理で GPU リソースがよく使われる一方、テキストデータ処理においては必須ではありません。そのため、今回の実験では GPU リソースは使用しません。
また、検証で利用したソフトウェアのバージョンを表5に示します。
表5 検証に利用したソフトウェアのバージョン
| ソフトウェア名 | バージョン | 用途 |
|---|---|---|
| Python | 3.7.4 | 実行環境として利用 |
| beautifulsoup4 | 4.9.0 | XML解析に利用 |
| lxml | 4.5.0 | XML解析に利用 |
| Janome | 0.3.10 | 分かち書きに利用 |
| MeCab | 0.996.3 | 分かち書きに利用 |
3.2 実験内容
3.2.1 実験の流れ
前回の投稿の 表2 にて示した chABSA-dataset におけるデータ前処理を正規化まで順次実行し、各処理にて利用する計算機リソース量と処理時間を計測します。ベクトル化処理に関しては、処理内容がモデル実装に大きく依存しており計測結果が別案件で参考になる可能性が低いため、本実験ではベクトル化を測定対象としません。
本実験における計測対象の処理を改めて表6に定義します。これらの処理は、それぞれ独立して逐次的に実行されます。また、各処理内において 2,260 種類の独立した企業データを取り扱いますが、chABSA-dataset の実装上、各企業データは逐次的に処理され、並列には処理されません。
表6 実験対象とする処理
| # | 処理名 | 説明 |
|---|---|---|
| 1 | 業績情報抽出処理 | XBRL解析処理。XBRL形式のデータを解析して、業績データ(HTML形式)を抽出する処理 |
| 2 | 文章抽出処理 | html形式のデータからタグを除去して、日本語の文章のみを抽出する処理 |
| 3 | 分析対象データ抽出処理 | 分かち書き処理と正規化処理を合わせた処理。chABSA-dataset内のコードにて、分析対象の文章ごとに実行されるループ処理内部にて一括して呼び出されており、処理に利用されたリソースを分割して計測することが困難であったことから、2つを合わせた処理を計測対象とする。 |
3.2.2 分かち書きのライブラリ比較
chABSA-dataset では分析データ抽出処理の分かち書き処理部分を、Janome を使って実装しています。本実験では、Janome で実装された分かち書き処理を MeCab での処理に書き直して、必要な処理時間を比較します。
分かち書きの処理を書き直すにあたって、変更点となるのは以下の3点です。
(1) 依存ライブラリ
Janome は辞書内包型Pythonパッケージとして提供されており、pipによるパッケージインストールのみで利用可能となります。MeCabはpipによるPythonパッケージインストールの他、OS毎にMeCabミドルウェア (e.g. rpmパッケージ) の導入が必要です。
(2) コード内での処理(関数)の呼び出し方
import 対象および分かち書き関数の名称等が異なりますが、呼び出し方法自体はライブラリ間でほぼ差がありません。
(3) コード内での I/O データ形式
Janome、MeCab ともに入力は文章を格納した文字列型データですが、出力データ型が異なります。Janome の分かち書き関数の出力は各単語を要素に持つ配列型データである一方、MeCab の分かち書き関数の出力は各単語を半角スペースで区切った文字列型データです。
例えば、文章の文字列データ sentence を入力して、分かち書き結果を tokens に出力するコードを書き換えるとき、コード1からコード2のように書き換えます。
コード1 Janomeを使った分かち書きコードの例
## Janome の利用例
from janome.tokenizer import Tokenizer
...(省略)...
# インスタンス作成
tokenizer = Tokenizer(wakati=True)
# 文章の文字列データ sentence を入力して、分かち書き結果を tokens に出力する
tokens = tokenizer.tokenize(sentence)
# 定義された tokens は 各単語を要素にもつ配列
...(省略)...
コード2 MeCabをつかったコード例
## Mecab の利用例
import MeCab
...(省略)...
# 分かち書きを出力するための MeCab インスタンス
mecab = MeCab.Tagger("-Owakati")
# 文章の文字列データ sentence を入力して、分かち書き結果を tokens に出力する
tokens = mecab.parse(sentence)
# 定義された tokens は 単語が半角スペース区切りされた一つの文字列
# tokens.split(" ") などすると、Janomeの場合と同様の出力
...(省略)...
3.3 実験結果
前編の表2に示したchABSA-dataset のデータ前処理を実行した結果を、図1~図3に示します。
図1は各処理実行にかかった時間を表しており、処理#1~#3の合計実行時間と内訳がわかります。図2は各処理実行時の平均CPU利用率を、図3は各処理実行時の平均メモリ利用量を各処理毎に分けて記載しています。各図において処理#3がJanome実装だった場合と、MeCab実装だった場合に分けて示しています。
図1 処理実行時間
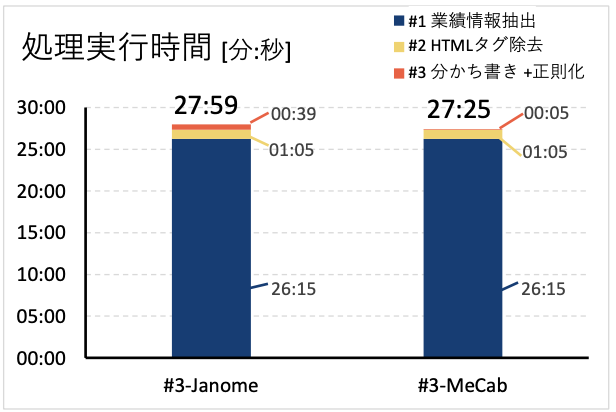
図1からは、処理#3 の実装が Janome, MeCab のどちらのケースであっても、処理#1 が 26 分程度に対してそれ以外の処理#2、#3 をあわせても せいぜい2分程度であり、処理ごとに実行時間の差が大きいことがわかります。時間がかかっている処理#1では、数MBのxbrl形式データファイルを企業毎に読み込んで解析し、業績データの HTML とメタデータを抽出しています。処理#1 で抽出されたデータは、企業毎にせいぜい数十KBのデータ量しかないため、処理#1 とそれ以外で処理時間のオーダが変わるほどの差が出ていると考えられます。
さらに図1からは、分かち書きと正規化を実施する処理#3の中で、分かち書きを Janome で実装する場合に比べて、 MeCab で実装した場合のほうが8倍程度速いこともわかります。これは Janome ライブラリ自体が Python スクリプトである一方で、MeCab が C++ を使って実装されていることが影響しています。
図2 平均CPU利用率
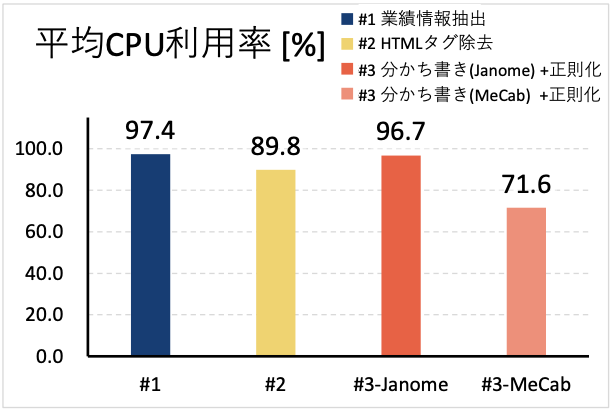
図2からは、処理#1、#2、#3-Janome において CPU利用率が軒並み 90%前後となっている一方で、#3-MeCab は 70%程度となっていることがわかります。この差は、各処理におけるデータ読み込みにかかる時間の比率が影響しています。
例えば、#3-Janome と#3-MeCab を比較すると、図1で示したように#3-MeCab は処理全体で 5 秒程度しかかからないのに対して、#3-Janome では40秒程度かかります。各処理では、同じ入力データをファイルから読み込むのに加えて、内部的に分かち書き用の日本語コーパスファイルの読み込みが発生しています。このファイル読み込みの間は CPU が待ち状態になっているため、CPU 利用率が下がると考えらえます。同様に、処理#1と比べて処理#2のCPU利用率が低いのも、処理時間に対するデータ読み込み時間の比率が影響しています。
図3 平均メモリ利用量
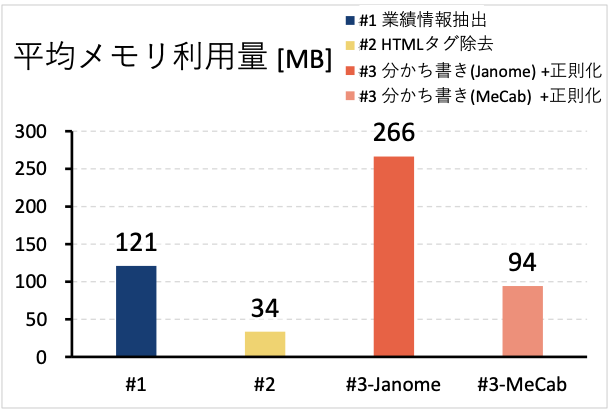
図3 からはまず、各処理間でメモリ利用量に大きなばらつきがあることがわかります。これは主に取り扱っているデータの種類や量に加えて、処理実行時に読み込んでいるライブラリの種類や量の影響だと考えられます。XML の一種である XBRL 形式の生データから業績情報を抽出する処理#1 と、業績データ(XML+HTML)データからタグを除去する処理#2 は、使っているライブラリは似たようなものになりますが、扱っているデータサイズが異なります。処理#1 に入力される各企業の有価証券報告書を表す生データは数 MB 程度の大きさなのに対し、処理#2 の入力データは、業績情報部分だけなので、数~数十KBの大きさとなります。この入力データの大きさの差がプログラム内部でのデータ表現形式、中間データの持ち方、細かい処理内容の差によって大きくなった結果、処理#1 と処理#2 のメモリ利用量の差が数十 MB となったと考えられます。処理#3-Janome と処理#3-MeCab に関しては、利用しているライブラリの実装が大きく異なります。言語については、Janome は純粋に Python 言語で書かれたものであるのに対して、MeCab の内部は C++で書かれたものです。内部的な実装言語の差がメモリ利用量の差に表れていると考えられます。
3.4 実験結果の考察
本投稿では、自然言語処理におけるデータ前処理の一例として chABSA-dataset のデータ前処理を題材として実験を行いました。全ての自然言語処理に対して一般性のある法則とは言えませんが、1事例の実験結果として、下記のような考え方ができることがわかります。
-
前提
- 生データの総量はGBオーダで存在している一方で、そのデータはMBオーダのファイルに分割されている
- 並列処理を実行していない
-
考え方
- ボトルネックとなるリソースは CPU であり、ボトルネックとなる処理は生データの解析である。
- 前処理実行中のメモリ利用量が MB オーダで収まる可能性が高く、処理時間に関する制約が緩いなら大容量メモリが搭載されてる高価なサーバは必要ない。
- 時間の制約が強い場合、サーバのメモリが新たなボトルネックにならない範囲で並列化を実施することで高速化が見込める。
- 分かち書きの処理を Janome で実装されている場合、MeCab で簡単に書き直すことができ、高速化およびメモリ利用量の抑制が見込める。これは、Janome が Python 実装であるのに対して MeCab が C++実装であることに由来する。
- ただし、本投稿で実験したように、前処理全体に占める分かち書きの実行時間の割合が小さく、高速化の効果が大きいのは処理の並列化であるケースがあることに注意する。本投稿における実験では、生データ(有価証券報告書)全体のデータ量 7.9GB に対して、抽出された分かち書き対象データ(業績の章)の量が 3.5MB と少量であったことから、処理時間の大部分を生データ解析が占めていた。一方で、生データと分かち書き対象データの差分が小さいケースでは、分かち書き処理の実行時間がより大きくなり、分かち書き処理の高速化の効果も大きくなると考えられる。
まとめ
- 本投稿では感情極性分析の実装例であるchABSA-datasetにおけるデータ前処理を題材とした性能検証結果とその考察を紹介しました。
- 結果として、処理実行時間のほとんどが生データの解析に費やされていました。これは生データ解析の前後で処理対象のデータサイズがMBオーダからKBオーダまで小さくなることが影響していると考えられます。
また、分かち書き処理をJanomeで実装した場合とMeCabで実装した場合を比較すると、MeCabのほうが実行時間、メモリ消費量がともに小さくなりました。 - 今回のケースのように生データの解析前後でデータサイズが大きく変わるときには、処理対象のデータ量が大きい部分がボトルネックとなる可能性が高いです。メモリが新たなボトルネックにならない範囲で、処理を並列化することで高速化が見込めます。