DLP EDM用のサンプルデータ作成と運用
ゼットスケーラーの水本です。プロフェッショナルサービスのコンサルタントをしています
DLPの持つメリットと組織の目的とをうまくソリューション化できればということで、この記事はZscaler Advent Calendar 2025の15日目向けに作成しました
ZscalerのDLP(Data Loss Prevention)機能におけるEDM(Exact Data Match)用のサンプルデータの作成と運用方法について解説します。
EDMは、データ漏洩防止の精度を飛躍的に向上させる機能です。では、なぜサンプルデータの作成が重要なのか、そして日本語特有のデータ形式にどう対応すればよいのか、具体的なステップを以下に展開していきます。
クライアント情報やプロジェクトデータなど、企業にとって重要な情報を多層的かつリアルタイムで保護するために、EDMをどのように活用できるかを解説しつつ、データ生成の具体的な技法も紹介します。
1. DLPのサンプルデータの必要性
DLPポリシーを効果的に設定するには、適切な「サンプルデータ」の準備が不可欠です。その理由は以下の通りです:
-
精度向上のための基盤
DLPルールの精度は、サンプルデータに依存します。不適切な元データのアップロードでは誤検知が増加し、本来守るべき情報が漏洩するリスクがあります。 -
実環境に即した設定
実環境で運用されるデータ構造に基づき、DLPやEDMがどのように動作するかを検証する必要があります。社内の顧客情報や社員データを模したサンプルはそのまま本番運用に応用が可能です。出力元のシステムからはCSVでセキュリティで保護するカスタムデータを構造化し、Indextoolでデータをインデックス化し、ハッシュのみをZscalerに送信する形式となります。 -
誤検知・漏洩防止
Zscalerでカスタムデータのマッチング準備をルール化し、DLP ブロック ポリシーによるデータ損失の防止を設計します。パターンマッチングに基づく誤検知を減らし、真に価値あるデータを守るため、正確なデータ作成およびインポートが求められます。EDMの場合は要件にあった氏名、SSNやクレジットカード番号等、条件に合わなければ通知しないように定義します。
2. 特に必要な日本語サンプルデータの調整と拡張
日本市場特有のDLP要件に対応するには、日本語と英語のデータ特性に注目する必要があります。特に以下のようなポイントを押さえたデータカスタマイズが重要です:
-
多様なデータの組み合わせ
氏名では、日本語と英語表記の両方(例:「鈴木 太郎」「Taro Suzuki」)を対応させるケースもあります。また、フリガナ(ひらがなまたはカタカナ)を付与することで、より多角的なデータ検出が可能です。 -
データ形式の統一
データごとにフォーマットを統一しておく必要があります。例えば、「郵便番号」なら必ず「123-4567」、「MyNumber」なら「1234-5678-9102」のようにルールを設定します。 -
チェックデジットの利用
マイナンバーやクレジットカード番号の生成には、チェックデジット(末尾の検証番号)の活用が重要です。これにより、実在する形式を模したサンプルデータが構築できます。 -
データの拡張
データ規模を拡大する時には、重複データを避けつつ、業務環境の検証に必要な数値を満たせるよう調整します。
3. データフォーマットへの対応
DLP EDMのインポートでは、特定のフォーマットに基づくデータが必要です。適切な形式でデータを用意していない場合、エラーが発生しやすいため注意が必要です。
主要なフォーマットと注意点
-
CSV形式
- カラムごとにデータを整理(例:「姓」「名」「フリガナ」「住所」「連絡先」など)。
- エンコーディングはUTF-8(日本語文字列への対応)。
- 必須情報が抜けていないことを確認。
- 重複データを削除して一意性を確保。
-
Excel形式
- マクロや計算式なしの静的ファイルを推奨。
- グラフィカルにデータを確認するために有用。

4. Pythonライブラリでのテキストデータ生成 (生成AI活用)
膨大なサンプルデータを手動で作成するのは現実的ではありません。そこでPythonや生成AIを活用し、効率的かつ正確なデータを生成する方法を紹介します。
下記のコード例では、以下の内容に対応したデータを生成します:
- 日本語姓名(漢字・ひらがな・カタカナのフリガナ含む)
- 英語表記名
- 郵便番号、住所
- マイナンバーやクレジットカード番号(チェックデジット付き)
import csv
import random
def generate_sample_data(num_records, output_csv):
"""
Generate Japanese sample data including names, addresses, MyNumber (with checksum),
credit card numbers, and birthdates, and save to a CSV file.
"""
headers = ["ID", "LastName", "FirstName", "Furigana", "EnglishName",
"Address", "Zip", "MyNumber", "CreditCard", "Birthdate"]
def generate_mynumber():
"""Generate MyNumber with checksum."""
numbers = [random.randint(0, 9) for _ in range(11)]
weights = [2, 3, 4, 5, 6, 7, 2, 3, 4, 5, 6]
checksum = sum(a * b for a, b in zip(reversed(numbers), weights)) % 11
check_digit = (11 - checksum) if checksum < 10 else 0
numbers.append(check_digit)
return "".join(map(str, numbers))
def generate_credit_card():
"""Generate a valid credit card number."""
numbers = [random.randint(0, 9) for _ in range(15)]
checksum = sum(int(digit) if i % 2 == 0 else sum(divmod(2 * int(digit), 10))
for i, digit in enumerate(reversed(numbers)))
check_digit = (10 - (checksum % 10)) % 10
return "".join(map(str, numbers + [check_digit]))
with open(output_csv, mode='w', encoding='utf-8-sig', newline="") as file:
writer = csv.writer(file)
writer.writerow(headers)
for i in range(num_records):
last_name = random.choice(["鈴木", "佐藤", "高橋"])
first_name = random.choice(["太郎", "花子", "次郎"])
furigana = f"{last_name} {first_name}".replace(" ", "")
english_name = f"Taro {last_name}"
address = f"東京都港区赤坂{random.randint(1, 30)}-{random.randint(1, 100)}"
zip_code = f"{random.randint(100, 999)}-{random.randint(1000, 9999)}"
my_number = generate_mynumber()
credit_card = generate_credit_card()
birthdate = f"{random.randint(1970, 2000)}-{random.randint(1,12):02d}-{random.randint(1,28):02d}"
writer.writerow([f"ID{i+1}", last_name, first_name, furigana, english_name,
address, zip_code, my_number, credit_card, birthdate])
# ファイル出力の例
generate_sample_data(1000, "sample_data.csv")
このコードは、1000件のランダムデータを「sample_data.csv」に出力します。
上記のような条件を加え、コードを生成してみてください。コード自体は生成されたため、元データのバリエーションは少ないのでまずは適宜配列データの要素を追加してみて、徐々に外出しして見てください。
もちろん件数などの規模やカスタマイズ性を問わなければいくつかのダミーデータ生成用のツールが公開されているので、こうしたもの活用も検討いただいても良いです。
5. Indextoolでのインポート
作成したDLP用データは、Zscalerが提供するIndextoolを使用してインポートします。
インポートの手順
-
CSVデータの準備
作成したデータのフォーマットに間違いがないか確認します。 -
Indextoolのインストールとセットアップ
ZIA管理画面よりIndextoolをダウンロードしてセットアップ。

-
インポートの実行
概略ですが以下の手順で、作成したCSVをDLPエンジンにインポートします:- Indextoolを開き、Zscalerのクラウドとの接続設定を完了。
- 作成した「sample_data.csv」をインポートして追加。
- データのプレビューでエラーがないことを確認。
- データをインポートし、成功を確認。
ここから上記以降の手順として必要な、DLPエンジン、ExpressionsとサブExpression、EDMの誤検出防止、DLPエンジンとEDMの統合的運用、そしてインラインDLPについてふれていきます。
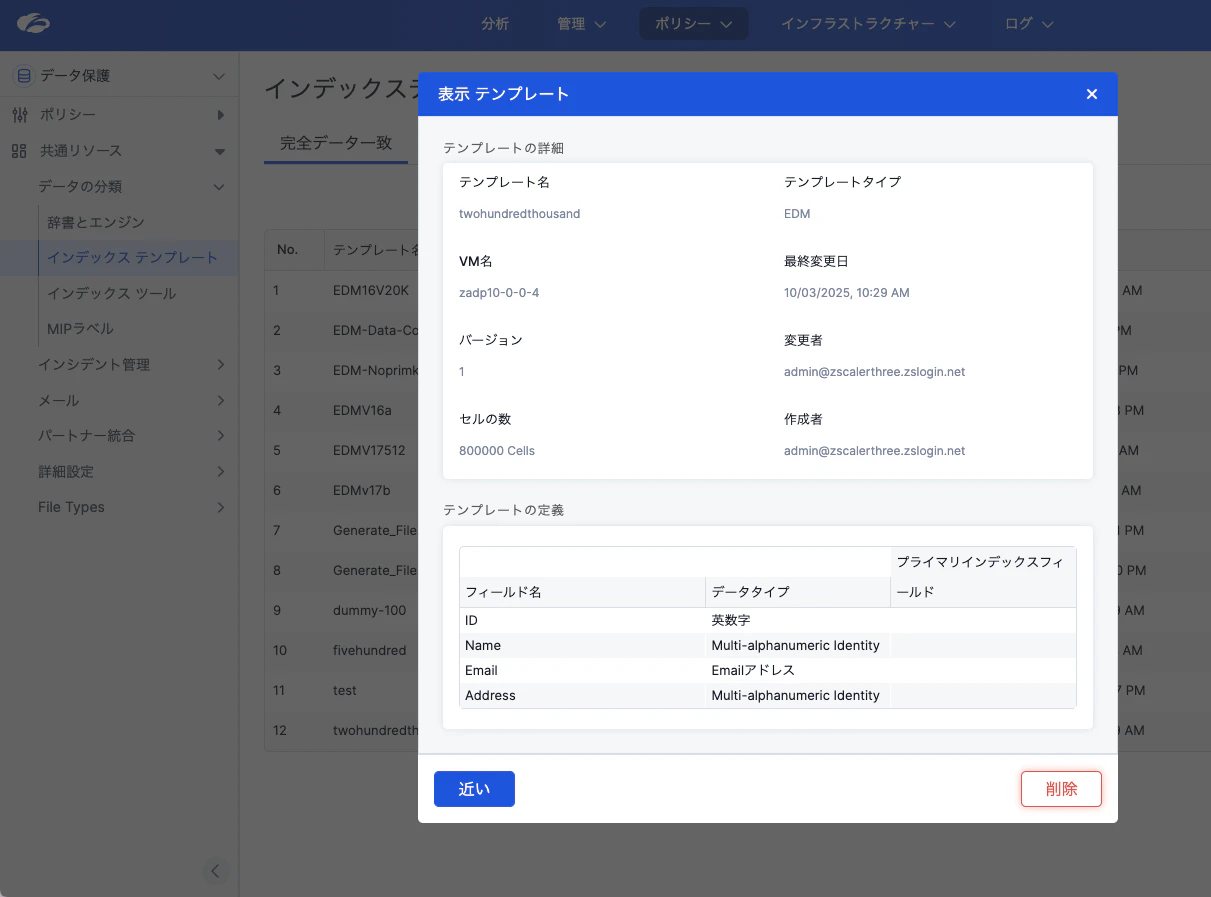
6. DLPエンジンとは?
ZscalerのDLPエンジンは、情報漏洩防止を可能にする中核的な機能です。データをリアルタイム、もしくはオフラインで詳細に解析し、機密情報の漏洩を防止するための強力なツールと言えます。
DLPエンジンの特長
-
スキャン性能の高さ
- 最大400MBのファイルを解析可能。
- 最大5レベルの圧縮ファイルをスキャンし、隠されたデータを発見。
-
カスタムDLPルールの設定
- 数10件のカスタムDLPエンジンを設定可能。各エンジンに1000件もの条件を登録して運用管理ができます。
-
ロジックの柔軟性
- AND/OR/AND NOTなど、論理演算子を活用して高度なカスタムルールを作成。
- 拡張可能なパターンとロジック構成が可能。重視すべきカラムの1件から、組み合わせで検知される条件を組み合わせ可能です。
7. ExpressionsとサブExpressionの活用
DLPエンジンを効果的に運用するためには、ExpressionsとサブExpressionを駆使することで、複雑なルールを適切に運用する論理的な基盤を作成する必要があります。
Expressionsの基本構成
-
All(すべて)
指定した条件が「すべて」満たされる場合にマッチング。 -
Any(いずれか)
条件のいずれかが一致する場合にマッチング。 -
Exclude(除外)
条件を除外してマッチする場合にアクションを実施。
サブExpressionの活用
複数の条件をグループ化したサブExpressionによって、さらに精密なスキャンが可能です。たとえば、次のような複合条件を作成できます:
例: 次の条件で一致するデータを検出する
- 氏名 + 住所 + マイナンバー
- 電話番号 + クレジットカード番号
DLPエンジンがペイロード全体をチェックし、所定のパターン(例えばマイナンバー)と複合条件(住所と紐づけ)に基づいて精確に一致を判定します。
8. EDM(Exact Data Match)による誤検知の低減
DLP運用において頻繁に問題となるのが誤検知です。EDMを用いることで、こうした課題を効果的に解決できます。
誤検知を減少させる方法
-
正確なデータマッチング
EDMでは、事前に登録されたデータリスト(顧客リストなど)に完全一致するデータだけを処理対象とします。曖昧検索(部分一致など)で生じる誤検知を抑えることで、より信頼性の高いスキャンを実現します。 -
価値の高いデータの保護
- PCI DSSやPII、HIPAAなどの規制対象に準拠した機密データを検出。
- 必要なSSNやクレジットカード番号のみを対象とするとともに、不必要なデータは対象外にします。
-
例
例えば、EDMを使った設定により以下のようなルールが適用可能になります:- 社員番号123456、取引先ID、顧客情報が漏洩すれば即座にアクション。
- 条件に合わない外部の一般的なデータについては通知を抑制。
コラム:Pythonでのサンプルデータ生成の高度な工夫
目的
多くのDLPおよびEDMの運用では、データ検出精度の向上と検証が求められます。そのためには、次のような要件を満たすサンプルデータを作成することが重要です:
-
Index用のCSVファイルとDLP検知テスト用のExcelファイルを分けて出力する。
- CSVはEDMのインポート用に最適化し、Excelを検知結果の視覚的な確認やレポート用に分けて活用します。
- パディング用のフィールドを作成することで、データ出力時のファイルサイズを調節可能にします。
- クレジットカード番号やマイナンバー生成でチェックデジットを考慮し、現実的なデータ形式を忠実に再現します。
以下では、これらの要件を満たすPythonコードの例をご紹介します。
なお、Excelの最大出力の件数は約100万行なのでカラムと行数でファイルサイズを調整します。
テキストデータ生成・Excel/CSVファイルへの分離出力
以下のコードでは、各レコードに必要な日本語氏名、英語氏名、郵便番号、住所、クレジットカード番号、マイナンバー(チェックデジット付き)を生成し、DLP用のCSVとテスト用のExcelに分けて保存します。
主な機能
- パディングフィールドで出力サイズを動的に調整。
- チェックデジット生成で信頼性の高いクレジットカード番号やマイナンバーを作成。
- ファイル分離出力:Index Import用のCSVとテスト用Excelに同時出力。
サンプルコード:データ生成とファイル分離出力
import csv
import random
import xlsxwriter
import string
def generate_sample_data(num_records, output_csv, output_excel):
"""
Generate Japanese sample data with padding for DLP and EDM, and save into CSV for indexing
and Excel for testing.
"""
headers = ["ID", "LastName", "FirstName", "Furigana", "EnglishName",
"Address", "Zip", "MyNumber", "CreditCard", "Birthdate", "Padding"]
def generate_mynumber():
"""Generate MyNumber with checksum."""
numbers = [random.randint(0, 9) for _ in range(11)]
weights = [2, 3, 4, 5, 6, 7, 2, 3, 4, 5, 6]
checksum = sum(a * b for a, b in zip(reversed(numbers), weights)) % 11
check_digit = (11 - checksum) if checksum < 10 else 0
numbers.append(check_digit)
return "".join(map(str, numbers))
def generate_credit_card():
"""Generate a valid credit card number."""
numbers = [random.randint(0, 9) for _ in range(15)]
checksum = sum(int(digit) if i % 2 == 0 else sum(divmod(2 * int(digit), 10))
for i, digit in enumerate(reversed(numbers)))
check_digit = (10 - (checksum % 10)) % 10
return "".join(map(str, numbers + [check_digit]))
def generate_padding(size_kb):
"""Generate a padding field to adjust file size."""
padding_size = size_kb * 1024 # Convert KB to bytes
random_text = ''.join(random.choices(string.ascii_letters + string.digits, k=padding_size))
return random_text
# Create CSV for indexing
with open(output_csv, mode="w", encoding="utf-8-sig", newline="") as csvfile:
writer = csv.writer(csvfile)
writer.writerow(headers[:-1]) # Exclude padding in CSV
# Generate the data
data = []
for i in range(num_records):
last_name = random.choice(["鈴木", "佐藤", "高橋"])
first_name = random.choice(["太郎", "花子", "次郎"])
furigana = f"{last_name}{first_name}"
english_name = f"{first_name} {last_name}"
address = f"東京都港区赤坂{random.randint(1, 50)}-{random.randint(1, 999)}"
zip_code = f"{random.randint(100, 999)}-{random.randint(1000, 9999)}"
my_number = generate_mynumber()
credit_card = generate_credit_card()
birthdate = f"{random.randint(1970, 2000)}-{random.randint(1,12):02d}-{random.randint(1,28):02d}"
padding = generate_padding(2) # Padding set to 2KB
row = [f"ID{i+1}", last_name, first_name, furigana, english_name, address, zip_code, my_number, credit_card, birthdate, padding]
data.append(row)
writer.writerow(row[:-1]) # Exclude padding field for CSV
# Create Excel for testing
workbook = xlsxwriter.Workbook(output_excel)
worksheet = workbook.add_worksheet()
for col, header in enumerate(headers):
worksheet.write(0, col, header)
for row_idx, row in enumerate(data, start=1):
worksheet.write_row(row_idx, 0, row)
workbook.close()
# Usage example
generate_sample_data(
num_records=1000,
output_csv="sample_index_data.csv",
output_excel="sample_test_data.xlsx"
)
コードのポイント
-
Index用CSVとExcelの分離
- CSVには重要なデータのみを簡潔に記載(パディングなし)。
- Excelテスト用ファイルにはパディングの追加情報も付与し、データの検証や表示に適する構造を作成。
-
パディングフィールドのサイズ調整
-
generate_padding(2)で2KBのランダムな文字列を追加することで、各レコードのサイズと出力ファイル全体のサイズを調整可能。
-
-
チェックデジットの考慮
- マイナンバーとクレジットカード番号の作成において、チェックデジットアルゴリズムを用いることで、形式的に正しいデータを生成。
-
ファイルサイズの最適な管理
- ファイルの出力内容やデータ量を制御し、必要に応じてファイルサイズの増減をテスト運用で模倣可能。
このように、サンプルデータ生成においても、目的に応じたファイル分離や現実的なデータ作成の工夫を取り入れることで、DLPやEDMの効率的な実運用を強力に支援します。実際の運用で本コードを活用し、データ漏洩防止設定やポリシー構築の精度向上に役立ててください!
9. DLPエンジンとEDMを組み合わせる方法
DLPエンジンとEDMは、組み合わせることでより高度なセキュリティの実現が可能です。これにより、高速かつ高精度なデータ保護が実現し、機密データの漏洩リスクをさらに低減できます。
DLPエンジンとEDMの連携運用
-
パターンマッチングの強化
DLPエンジンで全般的な検出条件を設定し、スキャンする範囲を広げます。一方、EDMを特定の重要データのみに適用することで、運用負荷を軽減できます。 -
条件ごとに異なる反応設定
- EDMのデータリストに一致するものは即時ブロック。
- 通常のDLPエンジンによって検出された場合、アラートのみに留めるなど。
-
具体例:
- DLPエンジンで「クレジットカード番号」に一致するパターンを広く設定。
- EDMによる顧客リスト(具体的な顧客番号とカード番号)一致がさらに正確なブロックを実現。
10. インラインDLPの運用で得られるメリット
インラインDLPは、単なるデータスキャンを超えたリアルタイム対策を提供します。
主な利点
-
リアルタイムな漏洩防止:
検知した瞬間、データ転送を阻止してリスクを回避。 -
業務効率の向上:
無駄なアラートを排除することで、運用コストを削減。 -
スケーラブルなパフォーマンス:
クラウド内で情報をスキャン・保護し、高速なアクセスを提供。
インラインDLPの運用例
- リモートワーク環境におけるデータ共有時の監視。
- クライアント向けレポート作成時の情報漏洩のリアルタイム防止。
- SaaSプラットフォームを利用したファイル共有の保護。
11. インラインDLPの運用で得られるメリットと高度な拡張
ZscalerのインラインDLP機能は、リアルタイムでのデータ漏洩防止対応を可能にすると同時に、拡張性と高度な自動化を組み合わせることで、エンタープライズレベルのデータ保護を一層強化します。本項目では、インラインDLPの利用によるメリットを、さらに具体的で実践的な例を交えながら解説します。
1. リアルタイムのデータ保護
インラインDLPは、ブランドや顧客の情報流出が企業評判やコンプライアンスに与える影響を最小限に抑えるために重要です。
-
リアルタイムでの漏洩防止:
送信データの転送中にスキャンし、機密データの送信を検知した場合は即座に転送をブロック。ユーザーアクティビティに合わせた即応可能なセキュリティ対応を実現します。
2. クラウドデータの保護
ZscalerのインラインDLPだけではなく、クラウド上のデータをスキャン監視しデータ保護のトラフィックとデータを監査する機能が利用できます。これにより、データ保護対象となったデータも的確に保護することが可能です。
-
具体例:
社内使用のサービス(例:Google Drive)から未承認のサービス(例:個人用アカウントが設定されたOneDrive)へのデータを保護し、漏洩を未然に防ぎます。
3. 「Cloud to Cloud」やIncident Receiverを活用した証跡データの保存と監視
ZscalerのCloud to Cloudの監査やIncident Receiver機能を利用することで、DLPが検出したインシデントに関する証跡データを効率的に管理できます。
この機能を使用することで、データ漏洩リスクへの対応時間を短縮するだけでなく、運用チームの負担を軽減できます。
-
利点:
- 検知されたインシデントデータをリアルタイムで受信し、セキュリティイベントを一元管理。
- 記録された証跡データを基に、エスカレーションや対応プロセスが簡易化。
- ログやインシデント情報がデータ保護の根幹資料として活用可能。
-
拡張可能な保存先:
インスデントIDとInsight log転送先のSplunkやQRadarなどのSIEMツールと連携することで、情報を統合的に監視しつつ、外部要件にも対応。
4. 監査メールや通知機能
監査メールや通知を活用することで、管理者やセキュリティチームに即座にアラートを提供します。
これにより、進行中のデータ漏洩試行や新たな潜在リスクに、迅速に対処するための体制を整えることができます。
通知例
-
アラートの条件:
- クレジットカード番号(PCI DSS準拠)を含むファイルの送信試行。
- 社外ドメインへのPII(個人情報)送信が検出された場合。
- EDMによる完全一致データ検知時。
-
通知される項目:
- 検知されたデータの種類(例:マイナンバー、顧客ID)。
- 検知された条件(例:DLPルール名、転送元、宛先)。
- 推奨アクション(例:アラートをユーザに自動転送、詳細ログの確認)。
ワークフローとしてのDLPのメール通知記事内で説明したようにフローを構築し組織全体や外部への連携のため共有化することでセキュリティ教育も行えます。
5. Workflow Automationによるデータ保護ワークフローのシステム化
インシデント処理を効率化するため、ZscalerではWorkflow Automationの導入が推奨されています。これにより、セキュリティイベントへの対応を自動化し、手動作業を最小限に抑えることが可能になります。
具体的な自動化シナリオ
-
データ侵害時の通知フロー自動化:
- DLPルールに基づいてインシデントが検知された際、自動で該当部門にメール通知を送信。
- SLAを指定し、未対応のアラートをダッシュボード上で可視化。
-
証跡データのレポート作成:
- SIEMやデータ保管ソリューションと連携し、定期的に生成されるレポートを外部コンプライアンス機関に提供。
-
自動エスカレーションの設定:
- 深刻度の高いイベント(例:大量データ流出検知)を自動で上長やCISOに通知。
-
サービス間の連携】:
- Teams、ServiceNowなどのIDPやITSMツールと連携し、発生した問題への対応を一連のフローとして管理。
利点
- 手動の監視や操作負担を軽減し、セキュリティチームの時間を他の重要なプロジェクトにフォーカスさせることが可能。
- リアルタイムでの統合モニタリングが可能になり、迅速な意思決定をサポートします。
6. EDM with Primary Key と EDM with no Primary Key の比較
DLPポリシーやEDMの使用では、プロジェクトや要件に応じて「Primary Keyの有無」を選択できます。以下は、それぞれの特性を簡単にまとめたものです:
EDM with Primary Key
-
使用ケース:
情報の一意性が重要な場合や、マッチング精度を最大限高めたい場合に利用されます。 -
主な仕様:
- テンプレートに1つ以上の「主キー」カラムを定義する必要がある。
- 対応可能な最大データ量: 最大50億セル。
- セカンダリデータ(住所や電話番号など)を主キーと紐づけることで、精度高くデータを特定。
EDM with no Primary Key
-
使用ケース:
簡易的なデータセットを用いた基本的なデータマッチングの場面に活用されます。 -
主な仕様:
- 主キーを省略できるため、単純化されたデータセットで迅速に運用。
- 対応可能な最大データ量: 最大10億セル。
インラインDLPのさらなる可能性
ZscalerのインラインDLPとEDM機能はクラウドネイティブの監視、警告、そして即応性を提供し、企業の重要データの保護を次世代レベルに引き上げます。Cloud to Cloud統合やWorkflow Automationの採用により、セキュリティ体制を一層強化し、コンプライアンスとデータ漏洩リスク管理を最前線で達成できます。
ぜひこれらの機能を実際の運用で活かして、セキュリティの質を向上させてください!
EDMとインラインDLPを導入する際の考慮ポイント
ZscalerのEDM(Exact Data Match)とインラインDLPは、データ保護における不可欠な手段であり、企業のセキュリティを次世代レベルに引き上げるための基盤となる機能です。しかしながら、その効果を最大限に引き出すためには、データ規模やハードウェア、運用要件を慎重に考慮する必要があります。以下に、EDMやIndextoolのサイジングと考慮すべき要素をまとめました。
1. データサイズではなくレコード数基準での設計
EDM/IDMはペタバイト規模のデータについても処理可能ですが、パフォーマンスはデータサイズではなく、データセット内のレコード数に依存します。そのため、以下のポイントを確認することが重要です:
-
3億件以上のレコードの場合:
VMware ESX/ESXiを基盤とした4 CPU、64GB RAM、1TBディスクのハードウェアリソースが推奨されます。 -
大規模データセットの最適な処理:
Indextoolは大容量データでも効率的に処理しますが、ハードウェア構成がZscalerが提示する要件を満たしていることが必要です。これにより、その性能を最大限に引き出すことが可能となります。
2. 運用時の注意点とメンテナンス
EDM/Indextoolの運用には特定の技術的な管理が必要です:
-
主キー未設定のエラー対応:
主キーが未登録の場合、Indextoolが "Error: --columnkey has no key columns defined" というエラーを返す可能性があります。この場合、sudo zadp restartコマンドを実行して問題を解決する必要があります。 -
大規模データ環境の考慮:
インポートやインデックス処理ではハードウェアリソースが重要です。最適なパフォーマンスのために、必要なCPU、RAM、ディスク容量を確保してください。
3. 拡張機能との統合
インラインDLPやEDMは、監査とログ管理の成果を最大化するための他のシステムとシームレスに統合できます。
-
SIEM連携:
Splunk、QRadar、LogRhythmなどのプラットフォームと大規模インシデント管理を可能にします。 -
Cloud to Cloudデータ保護:
SaaS間トラフィック分析(例:Google Drive間やMicrosoft 365間)をリアルタイムで保護し、完全なデータセキュリティを維持します。 -
Workflow Automation:
自動通知やエスカレーション設定により、セキュリティ運用を一元管理します。
4. 最適化とシステム評価の重要性
EDMやインラインDLPの導入後も、継続的な監視やチューニングが非常に重要です。
- 大量データを扱う場合には、パフォーマンスのボトルネックを定期的に評価し、リソースの増強が必要かどうかを確認してください。
- ハードウェア構成やテンプレート設定を見直すことで、さらなる効率が期待できます。
ZscalerのEDMとインラインDLPをフル活用することで、セキュリティ課題に適合した柔軟なデータ保護機能を実現できます。大規模データセットへの対応も含め、企業特有のニーズに対応する高度な運用をぜひ設計してください!
まとめ
ZscalerのDLPエンジンとEDM機能は、企業の重要データをリアルタイムで高精度に保護するための非常に有効な手段です。サンプルデータの作成からポリシー運用、インライン対策のメリットまでを体系的に学ぶことで、より効果的なセキュリティ運用が可能になります。
次回のAdvent Calendarでは、DLPワークフローのシミュレーションと運用最適化ロジックについてさらに深掘りしていきたいと考えてます。それではまたお会いしましょう!