この記事は aratana Advent Calendar の8日目の記事です。

Qiita初記事で緊張していますが、
今日は AWSのエラーを取捨選択してSlackに通知する 仕組みについて
ちょびっとお話させて頂ければと思います!
システムではバグやエラーを出来るだけ出ない方が平穏で嬉しいですが、
そういうわけにもいかず...
出てしまったらきちんと管理する必要がありますよね。
また、たくさんあるエラーの内には見る必要のないものも含まれていることも。
見なければいけないエラーだけをきちんと管理したい!
というこでログ監視システムを作成してみました~
開発環境
以下の環境・ツールを使って開発していきました。
ログ監視の仕組み
では、早速ログ監視の仕組みについてご紹介していきます。
設計
ざっくりと下図のような形で設計・開発を進めました。
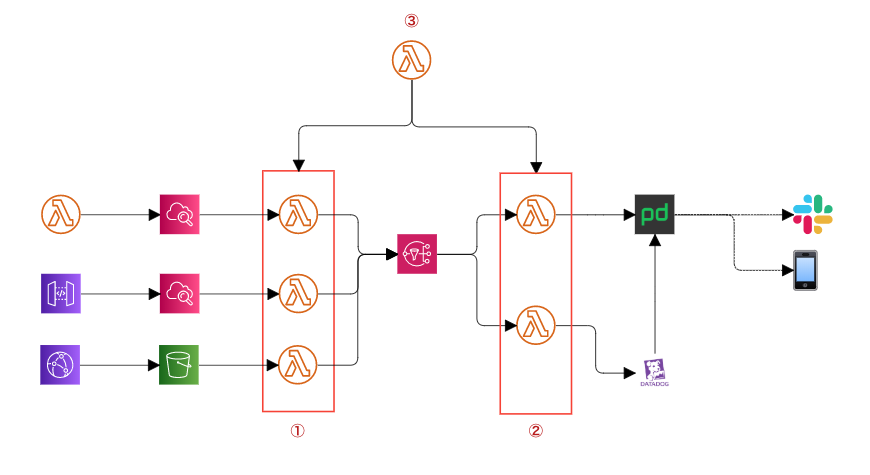
各LambdaやAPIからのログを、ログ監視を行なっているLambda(以降①)でそれぞれ1つのモデルに成型してSNSにつっこみます。
1つのモデルにすることによって、各ツールに送信するLambda(以降②)ではどこからきたログなのか
気にすることなく送信することが出来ます。
つまり、PagerDutyやDataDog以外にも送りたい!ってなった時にとっても便利ってわけです。
※①②を監視するLambda(以降③)は後述します。
取捨選択するには
例えば、PagerDutyに
このエラーは送りたいけどあのエラーは送りたくない、、
タイムアウトエラーだけどこのLambdaは別に見なくてもいい、、
なんてことありますよね。
ログをモデル化し、各項目を簡単に取得できるようにしたことによって、
対象のAWSのステージ、Lambda名やログに含まれるメッセージ等をチェックすることが出来るようになりました。
もちろん複数条件でのチェックも出来るので、複雑なのエラー通知制限も行えます!
今回の実装では、Lambda名ごとにフィルターしたい条件を作成し
PagerDutyに送る/送らないのフラグをモデルに付与してSNSに入れました。
SNS以降ではそのフラグをチェックし送るだけ、と考えることが少なくてすみました。
開発途中で起きた問題
開発してみると普段利用しているだけでは気付かない
AWSのログの多さや制限の多さに驚き戸惑い、壁にぶち当たることも多々...
今回は特に大きかった2つをご紹介します。
無限ループ
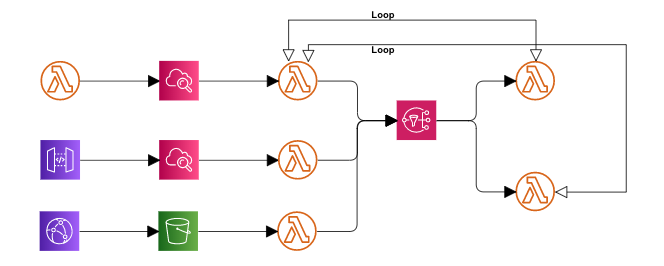
1つ目はLambdaの無限ループ事件です。
Lambdaの実行回数がとてつもないことになりました。
これはCloud Watch Logsのサブスクリプションフィルターのつけ方が原因でした。
(サブスクリプションフィルター:簡単にいうと、誰がそのログを監視するかの設定のこと)
ログ監視Lambdaなわけだから当たり前なんですが、
多数のLambdaのサブスクリプションフィルターには①を設置し、。
①、②のLambdaにはサブスクリプションフィルターを設置してしていませんでした。
しかし、いつの間にか②のサブスクリプションフィルターに①が設置されてしまいこのループが発生してしまいました。。
Lambda名の規則によって自動でサブスクリプションフィルターを付与していたのですが、
開発途中で色々と変更を加える中で、②のhandler名を変更してしまい、
その規則に引っかかっていたのに気付かなかったんですね...
ログによって①が起動しそのログによって②が起動しそのログによって①が起動し、、、
とねずみ算式にLambdaの実行回数が増えてしまいました。
今思い出しても恐ろしいです。反省。
サブスクリプションフィルターは問題が無いか考えながら慎重につけなければなりません。
ログ監視Lambdaのエラー
ログって多分皆さんが思っている10倍ほどは大量に出力されているんですが、
それだけたくさんのログを各ツールに送ろうとすると
「これ以上受け取れないよー」って落ちちゃうことがありました。
エラー通知に失敗していたらそもそもエラーが起こっていることにさえ気付けない。
それってまずくない?
ということで
①と②を監視してくれるLambda③を作成しました。
①②が送信に失敗しエラーが出力されると③がそれを拾ってくれて通知してくれます。
また、②で送信に失敗した内容はS3に残しておくので、
③の通知をみたらS3を確認しにいけばよいわけです。
また、上記のループ事件で発覚したサブスクリプションフィルターも
①②それぞれに③をつけてあげちゃえばループが起きる可能性もなくなりました!
じゃあ③が落ちたらどうするの?って話も出てくるかもしれませんが、
③が監視しているのは①だけなので大量過ぎるログを受け取ることもないので、
現状の稼働状況をみても一旦問題なさそうかなと。
まとめ
開発途中で他にも色々問題が起き、へこたれたこともありましたが、
AWSやシステムの繋げ方を勉強できるとっても良い新卒OJTの成果物となった気がします。
皆さんも楽しく元気にエラーチェック出来ますように~!
おまけ
別システムでもログ監視システムの開発を行っているのですが、1つ良いなと思った機能があったのでついでにご紹介。
上記ではログ監視するLambda①とそれを監視するLambda②を準備しましたが、今回はCloud Watch Metrics, Alarmを利用しました。
- Lambda①でエラーが起きる
- S3にエラー時のログを保存
- 同時にCloud Watch Metricsにデータの送信
- Cloud Watch AlartでMetricsの異常検知
- SNSでSlackに通知
という流れで無駄にLambdaを起動させることもなくとっても簡単に出来ました。
Lambdaのログにカスタムメトリクスを埋め込んで送ることができる
aws-embedded-metricsというライブラリのおかげです。勉強になりました!