Azure AI Foundry ワークショップを実際に利用してマルチモーダルモデルやエージェントと対話する
Microsoft技術で理解するAIに関する勉強会で使用したワークショップコンテンツになります。Azure AI Foundryの基本的な利用方法を実際に使いながら体験することができるモノとなっています。リソースなどは全て公開しているため、Azure AI Foundryを触ってみたい方は是非試してみてください。
Azure AI Foundryは、開発者がAIをアプリケーションに組み込むためのオープンで柔軟、かつ安全なプラットフォームです。1,900以上のオープンソースモデルと独自モデルを活用しながらAI Agents開発が可能になります。
このワークショップを実施にする当たって
このワークショップでは実際にAzure AI Foundryを利用してAzure AIでマルチモーダルモデルやエージェントと対話する事ができます。具体的な環境としては以下のものになります。
- Azureサブスクリプション - 無料で作成
- サポートされているリージョンでGPT-4oとDALL.E 3モデルがサポートされているAzure OpenAIリソース。
推奨リージョンはSweden Centralです。
ワークショップの目的
Azure AIでマルチモーダルモデルとエージェントと対話する Azure AI Foundryのハンズオン体験で、Azure OpenAIのGPT-4oマルチモーダルモデルでイノベーションを起こしましょう。GPT-4o-mini、DALL-E、GPT-4o-realtimeを使用して、テキスト、サウンド、画像を効果的に生成するためのコアコンセプトとベストプラクティスを学びます。ユーザー体験を向上させ、イノベーションを促進するAIエージェントを作成します。
ワークショップ手順
1.セットアップ
最初にAzure AI Foundryをはじめワークショップに必要なAzureのリソースをデプロイします。
自動デプロイスクリプトの利用
Azureアカウントとサブスクリプションの登録が終わった状態で以下のリンクから今回のワークショップ用のデプロイを実施することができます。

クリックするとブラウザが起動します。最初にAzureポータルにログインしていない場合はアカウントの選択画面がでるので該当するアカウントを選択してください。すると以下のようなカスタムデプロイ画面が表示されます。

ワークショップではインスタンスの詳細についてはUnique Suffix以外はそのままで問題ないです。
- サブスクリプション
登録済みのサブスクリプションを設定 - リソース グループ
このワークショップで使うリソースを格納するリソースグループ。空のリソースグループにデプロイするとワークショップの後にリソースグループ事削除できます。 - リージョン
- Ai Hub Name
- Ai Hub Friendly Name
- Ai Hub Description
- Domain Name
- Location
swedencentral推奨。今回のワークショップで使う生成AI全てを利用できるリージョンが現時点ではswedencentral位しかない。 - Unique Suffix
リソース名に付与するサフィックス。Azureのリソース名やドメインのかぶりを避けるために使います。一意のものを。 - Tags
リソースにタグを付与したい場合に指定します。
デプロイが完了すると先ほど設定したリソースグループは以下のような構成になってるはずです。
リソースの作成時にエラーが発生してスクリプトによる自動展開が上手くできない場合は次の手動による環境構築を実施します。
ワークショップに必要な環境を構築する
- Azureポータルにログインします。
- メニューから[リソースの追加]を選択します。
- [Azure AI Foundry]で検索し作成をクリックします。

- Azure AI Foundryのリソースに関する設定を入力します。入力が完了したら次へを押します。

- サブスクリプション
- リソースグループ
- Name : Azure AI Foundryのリソース名
- Region : 展開するリージョン(sweden central推奨)
- Default project name : 初期プロジェクトとしてデプロイするプロジェクトのリソース名
- Network,Identity,Encryption,Tagsは今回特に変更は不要ですのでそのまま次へを押して進みます。
- レビュー及び送信で入力内容を確認し問題なければ作成を押します。デプロイが完了するとAzure AI FoundryとAzure AI Foundry Projectの2つのリソースが生成されます。

- 次に今回のワークショップに必要なLLMのモデルを追加していきます。作成したAzure AI Foundryを選択するとポータルへのリンク先が表示されるのでクリックしてポータルへ移動します。

- 先ほど作ったリソースを選択した状態でポータルが開きます。左のメニューから[Models+endpoints]をクリックしてください。

- このリソース内で利用するLLMのモデルを追加する画面が表示されます。[Deploy model]-[Deploy base model]をクリックしてください。モデル選択のダイアログが表示されます。検索項目に[gpt-4o]を入力し、一覧からgpt-4oを選択し[confirm]ボタンを押します。

- 選択したモデル(今回はgpt-4o)の設定項目が表示されます。識別しやすいDeployment nameを設定して[Deploy]をクリックしてください。今回は変更していませんが、必要に応じてCustomizeを押してより詳細な設定を行うことも可能です。

- 今回は利用するモデルは、gpt-4o,Dall-e-3,gpt-4O-reamtime-previewの3つになります。上記の手順をモデルのデプロイの作業を繰り返し実施してモデルを追加してください。
リージョンをsweden central以外に設定した場合、上記3つのモデルを追加すると、作成したものとは別にAzure Ai FoundryとProjectが作成されることがあります。使用するモデルによってはリージョンで提供されていないものがあります。Azure AI Foundryのリージョンを基本としてモデルのリージョンは設定されますが、該当リージョンでの提供がない場合はモデルが利用できるリージョン用のAzure Ai Foundryのリソースが自動で生成されます。
2. Azure AI Foundaryポータルにアクセスし各種機能を確認する
最初に今回利用するAzure AI Foundryの事項について紹介します。以降の作業では実際に幾つかの生成AIの操作を体験します。
Azure AI Foundaryポータルにアクセスします。すでにAzureアカウントでログインが済んでいる場合Home画面が表示されます。[Keep building with Azure AI Foundry]内に先ほどデプロイしたリソースが幾つか表示されていると思います。この中から[Azure Ai Hub]のリソースを選択します。ワークショップのカスタムデプロイを変更しない場合は[Workshop AI Hub]を選択します。

一覧にない場合はAll Resourcesをクリックしてリソースを一覧表示してください。
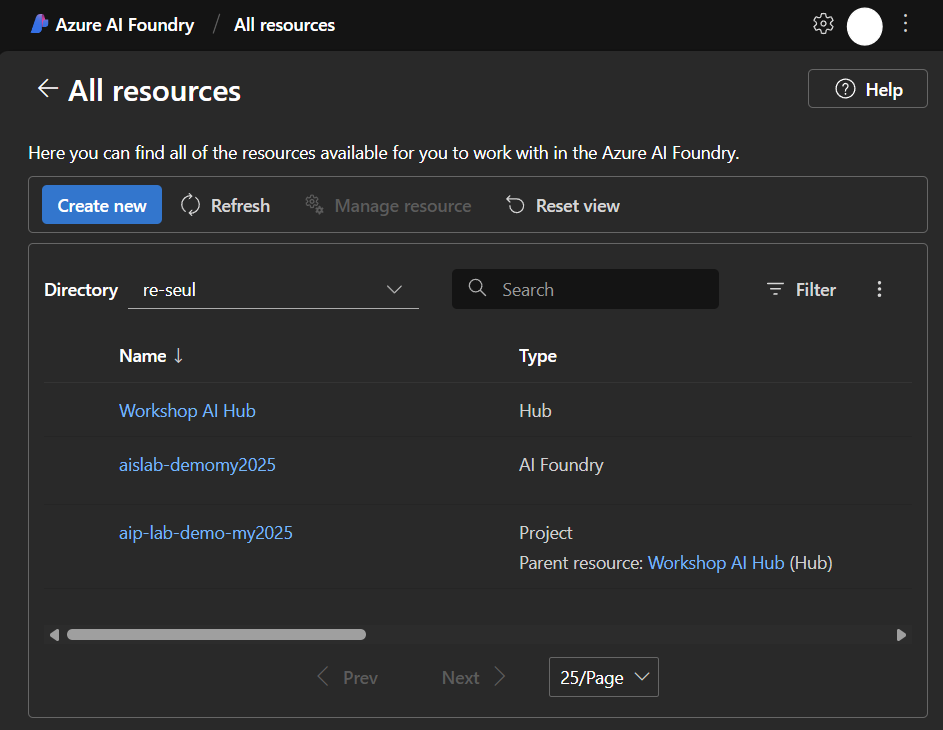
Azure AI Hubのリソースを表示すると以下のような概要情報を見ることができます。ワークショップではこのHubに紐づいているプロジェクトを利用します。左下にある[Go to Project]のリンクをクリックしてプロジェクトに移動してください。

プロジェクト
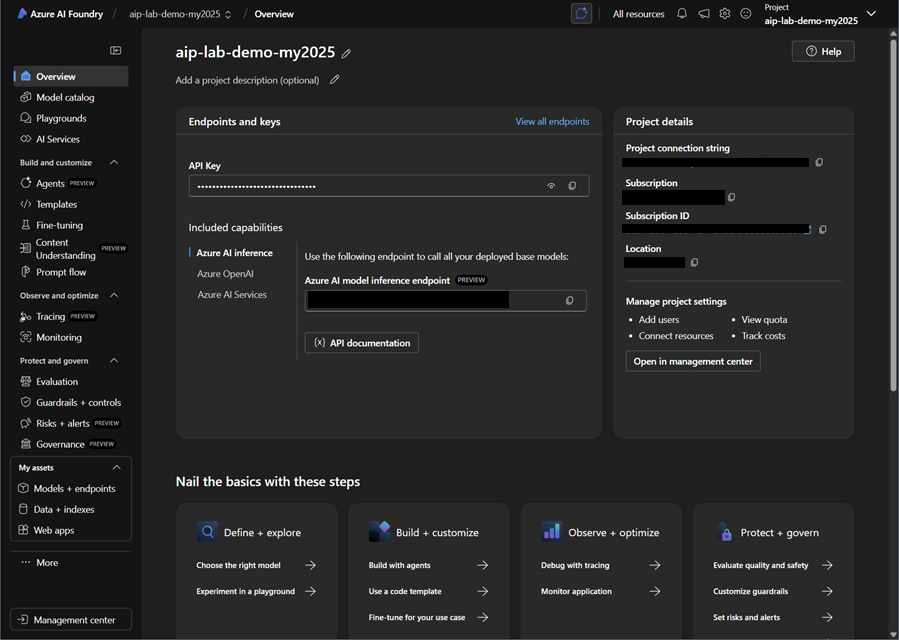
プロジェクト概要
このページでは、Azure AI Foundryポータルプロジェクトの概要を確認できます。これには以下が含まれます:
- プロジェクト名と説明:プロジェクトの名前と、現在のAzure AI Foundryポータルプロジェクトの簡単な説明。
- プロジェクト詳細:プロジェクトの接続文字列、場所、リソースグループなどの様々なプロパティのコレクション。
- エンドポイントとキー:Azure AI Foundryポータルでは、複数のリソースを接続して機能と機能を拡張できます。Azure OpenAI、Azure AI Search、Azure AI Servicesなどのリソースにより、プロジェクトの機能がさらに強化され、LLMのデプロイメントやベクトル検索などの機能にアクセスできます。ここでは、APIエンドポイントとキーやドキュメントなどの有用な情報を確認できます。
- 最近のリソースとチュートリアル:ここでは、最近のリソースが強調表示され、追加の学習リソースとチュートリアルが提供されます。
ナビゲーションバー
ナビゲーションバーに新しいタブが追加されていることに気づくでしょう。これらはプロジェクトに関連する機能を表しています。

新しいセクションは以下の通りです:
- 最初のセクションには、モデルと対話するためのPlaygrounds、プロジェクトの概要を提供するOverview、Azure AI Foundry内の利用可能なモデルを紹介するModel Catalog、Azure AI Servicesのリストとデモ、ユースケースなどを確認できるAI Servicesが含まれます。
- Build and Customize:プロジェクトの範囲を拡張するための有用な機会が含まれます。例えば、クラウドコンピュートを実行するCodeでの作業、Prompt Flowへのアクセス、デプロイメントのFine Tuningを行う機能などがあります。
- Observe and optimize:フローのデバッグのためのtracing等が含まれます。
- Protect and govern モデルのEvaluationsの開発、プロンプト入力と完了出力にガードレールを追加するcontent filtersが含まれます。
- My assets:ここでは、プロジェクトに追加の要素を追加できます。Data、Indexes、models and endpoints、Web appsなどのリソースを作業の一部として使用できます。
- Management Center:すべてのハブとプロジェクトの詳細とリソースを管理する場所です。
このラボではPlaygroundsの使用に焦点を当てます。Playgroundsに移動して次のセクションに進んでください。
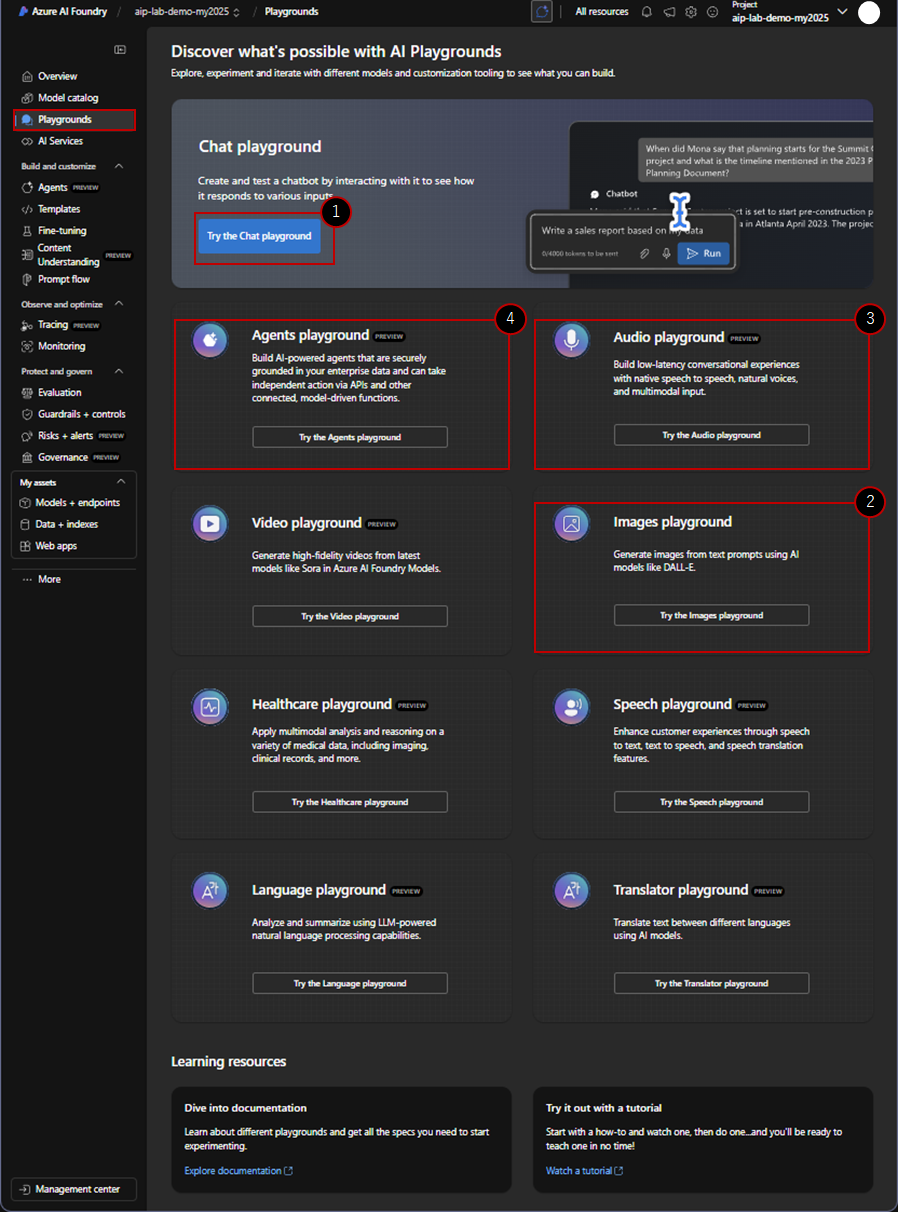
プレイグラウンド
プレイグラウンドには異なるオプションがあることに気づくでしょう。各オプションは、AIモデルとの対話と使用の異なるアプローチを表しており、特定のニーズに合わせてカスタマイズできます。
私たちは主にこれらのプレイグラウンドで作業を行いますが、特に以下のものに焦点を当てます:
- Chat Playground
- Image Playground
- Audio Playground
- Agents Playground
Chat Playground
プレイグラウンドセクション内でChat Playgroundに移動し、Try the Chat Playgroundを選択してください。この機能により、会話形式で様々なAIモデルと対話し、テストすることができます。

- Deployment:このセクションでデプロイされたモデルを切り替えることができます。
- Instructions and context:ユーザーとの対話前にモデルへの指示を入力する場所です。
- Add you data:Azure AI Foundryポータルは、デプロイされたモデルに外部データを提供することをサポートし、より良い検索とコンテキストを可能にします。
- Parameters:このタブには、温度などのモデルの詳細設定が含まれています。
- Cat history:チャットボックスでは、モデルとの対話がチャットメッセージとして表示されます。
- Prompt box:モデルに送信するプロンプトを入力する場所です。
Image Playground
プレイグラウンドに戻り、Image Playgroundを選択してTry the Image Playgroundをクリックしてください。このオプションでは画像生成を扱うことができます。

- Deployment:このドロップダウンで画像生成用のモデルを選択できます。これらのモデルは、チャットモデルと同様に、デプロイメントから提供されます。
- Prompt box:チャットプレイグラウンドのボックスと同様に、モデルがユーザーから入力を受け取る場所です。画像の場合は、生成したいものの説明を入力します。
- Result:生成された画像が表示される場所です。
Audio Playground
プレイグラウンドに戻り、Audio Playgroundを選択してTry the Audio Playgroundをクリックしてください。この機能により、音声会話形式で様々なAIモデルと対話し、テストすることができます。

- Deployment:このセクションでデプロイされたモデルを切り替えることができます。
- Instructions and context:ユーザーとの対話前にモデルへの指示を入力する場所です。
- Choose a voice:gpt-4o-realtimeは、好みに合わせてカスタマイズされた独特のアクセントや音調機能を持つ様々な音声から選択できます。
- Server turn detection:サーバーが音声活動検出(VAD)を使用してユーザーが話し終えたタイミングを識別するかどうかを決定します。
- Parameters:このタブには、温度や最大応答などのモデルの詳細設定が含まれています。
- Conversation:モデルとの対話が会話履歴として表示されます。
- Prompt Button:チャットプレイグラウンドのボックスと同様に、モデルがユーザーから入力を受け取る場所です。
Agents Playground
ナビゲーションバーでAgents Playgroundを選択してください。この機能は、AI駆動のエージェントを構築、テスト、カスタマイズするためのツールを提供します。

New Agentを実行すると、以下のUIコンポーネントが表示されます:
- Agent name:ここでエージェントに名前を付けることができます。
- Deployment:このドロップダウンで画像生成用のモデルを選択できます。これらのモデルは、チャットモデルと同様に、デプロイメントから提供されます。
- Instructions:ユーザーとの対話前にモデルへの指示を入力する場所です。
- Agent Description:このエージェントの機能などを説明を入力する場所です。
- Knowledge:ナレッジは、エージェントが応答を基礎付けるためのデータソースにアクセスできるようにします。
- Actions:実行時に様々なツールを実行できるようにすることで、エージェントの機能を強化します。
- Connected agents:既存の別AIエージェントと接続刷ることができます。これによってより複雑で高度な作業を実施することが可能になります。
- Model Settings:このタブには、温度やTop Pなどのモデルの詳細設定が含まれています。
- Prompt Box:チャットプレイグラウンドのボックスと同様に、モデルがユーザーから入力を受け取る場所です。
3.テキスト生成
ここでは、gpt-4o-miniモデルを使用してテキストを生成する方法を学びます。
基本的なプロンプト
まず、チャットプレイグラウンドを使用して、いくつかのプロンプトを試し、その応答を観察してみましょう。チャットプレイグラウンドを使用するには、以下の手順に従ってください:
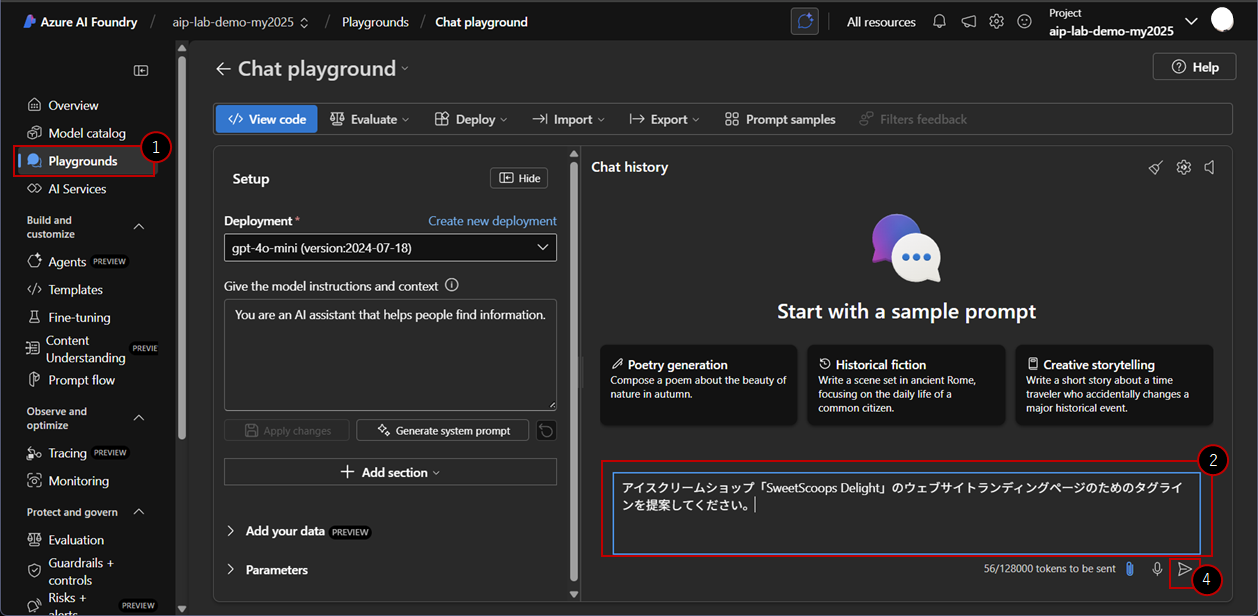
- 左側のナビゲーションバーのプレイグラウンドセクションに移動し、Try the Chat Playgroundをクリックしてください。
- チャットプレイグラウンドで、*"Type user query here."*と表示されているテキストボックスを見つけてください。
- 何か自分で考えたプロンプトを入力します。
- プロンプトを追加した後、入力ボックスの横にある紙飛行機アイコンを見つけてください。紙飛行機アイコンをクリックして、テキストをモデルデプロイメントに送信します。
- クエリを送信した後、モデルが処理して応答するまで少し待ってください。応答は入力欄の下のチャットウィンドウに表示されます。
次に以下のプロンプトを順に入力してみてください。
アイスクリームショップ「SweetScoops Delight」のウェブサイトランディングページのためのタグラインを提案してください。
チャット履歴をクリアせずに、以下のプロンプトを試してみてください:
アイスクリームショップのホームページのためのウェブサイトコピーを生成してください。
モデルがSweetScoops Delightのウェブサイトのコピーを提供していることに注目してください。会社名やビジネスを再度指定していなくても、これはモデルが会話履歴全体をコンテキストとして受け取っているためです。AIモデルは学習することができず、ユーザーが離れて戻ってきた場合、以前の対話の記憶はありませんが、アプリケーションはプロンプトエンジニアリングを使用してこの「記憶」を追加しています。
モデルのパラメータは以下のように制御できます:
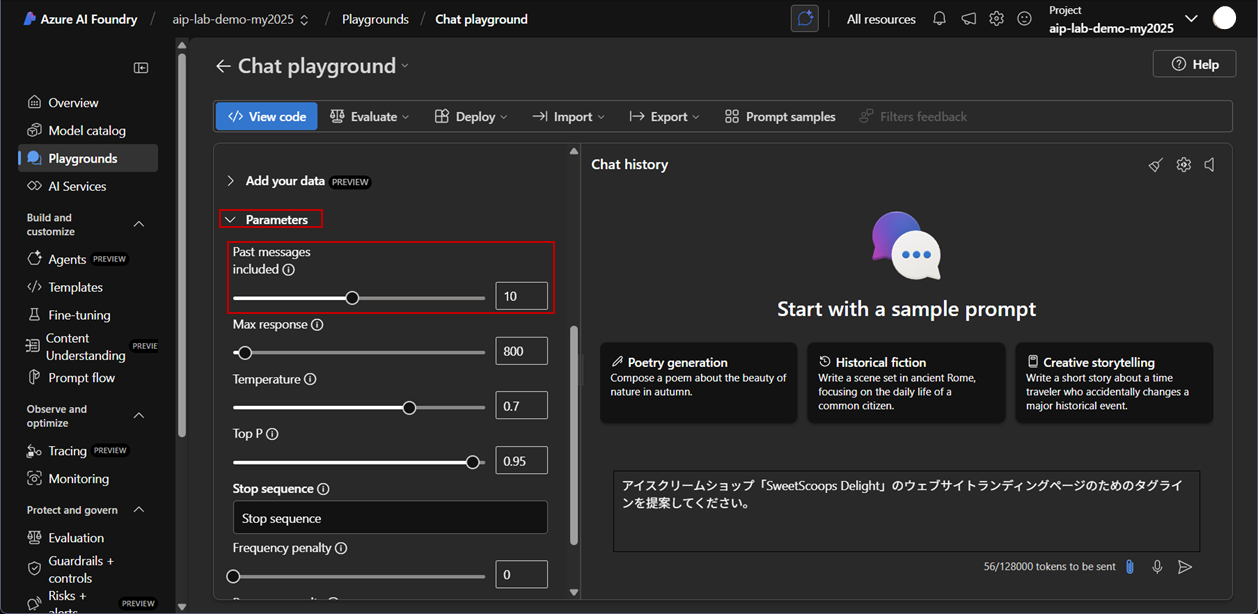
- チャットインターフェースでパラメータセクションに移動してください。
- パラメータセクションで、設定コントロールを調整してください。モデルがコンテキストとして考慮する過去のメッセージの数を変更できます。設定後、変更は自動的に適用されます。
前のステップで得られたコピーはすでに良い出発点ですが、ランディングページには長すぎるかもしれません。より短いバージョンを取得してみましょう。
テキスト要約は大規模言語モデル(LLM)のよく知られた機能の1つです。より大きなテキストの短い要約を作成します。
さらに、LLMにテキストから重要な情報を抽出するように指示することもできます。このシナリオでは、SEO最適化のためのキーワードを取得するのに役立ちます。以下のプロンプトを試して、前のコピーを要約し、有用なデータを抽出してください。
1. tl;dr
2. 上記の長い説明から会社名、製品カテゴリ、ビジネスの独自の価値を抽出してください。
高度なプロンプト
次のセクションに進む前に、Clear Chatボタンをクリックしてメッセージ履歴をクリアしてください。
これを行うには、プレイグラウンドの右上にあるほうきのようなアイコンをクリックしてください。ポップアップが表示されたら、clear buttonをクリックしてチャット履歴をクリアしてください。

ゼロショット学習
LLMは非常に大量のデータでトレーニングされているため、最小限のプロンプトで一部のタスクを実行できる場合があります。これはゼロショット学習として知られています。例えば、モデルに製品名のリストを生成し、それらを分類するように依頼してみましょう:
未来をテーマにしたレストランのための10個のユニークなメニューアイテムを、料理名と簡単な説明を含めて生成してください。
次のセクションに進む前に、Clear Chatボタンをクリックしてメッセージ履歴をクリアしてください。
少数ショット学習
ゼロショット学習が例やより複雑なタスクで失敗する場合、少数ショットプロンプトは、モデルを望ましい結果に導くための例を提供できます。例は、モデルに私たちが望む動作方法を明確に示します。以下は、製品を分類するための少数ショット学習プロンプトの例です。
未来をテーマにした名前を持つ10個のユニークなピザメニューアイテムを、ピザの名前と簡単な説明を含めて生成してください。
例:
ネビュラスプリーム:ペパロニ、ソーセージ、ピーマン、玉ねぎ、オリーブをトッピングし、スパイシーなマリナーラソースを添えたクラシックなスプリームピザ。
ギャラクティックガーデン:ほうれん草、チェリートマト、マッシュルーム、アーティチョークをトッピングし、バジルペストをかけたベジタリアン向けの一品。
アステロイドミートフィースト:ペパロニ、ハム、挽肉、ベーコン、イタリアンソーセージをたっぷりトッピングした、ハートフルでタンパク質たっぷりのスライス。
次のセクションに進む前に、Clear Chatボタンをクリックしてメッセージ履歴をクリアしてください。
LLMと対話する際の有用なヒントは、未訓練のインターンと話していると想像することです。実行するタスクについてより詳細な情報を提供できるほど、より良い結果が得られます。特に有用な戦略は、タスクを小さな部分に分解し、各部分にプロンプトを提供することです。ウェブサイトコピー生成タスクでこれを試してみましょう。
レストランのための新しいピザを開発してください。
指示:
- まず、新しいピザのテーマを決めてください。
- 全体的な味わいのプロファイルを決定してください。辛い、甘い、風味豊か、またはそれらの組み合わせでしょうか?
- ベースとなる材料を選んでください。これにはソースとチーズの種類が含まれます。
- テーマと味わいのプロファイルに合うユニークなトッピングを考えてください。
- 最後に、レストランの未来をテーマにしたコンセプトと、あなたが作り上げた味わい体験の両方に合う、創造的で記憶に残る名前を考えてください。
もう1つのオプションは、連鎖思考と呼ばれる手法を使用することです。この手法では、LLMがタスクを小さなステップに分解する役割を担います。LLMは世界に関する知識と推論能力を使用します。LLMはその後、タスクの解決につながる思考の連鎖を生成します。プレイグラウンドのチャットを再度クリアしてから、以下のユーザープロンプトを入力して「連鎖思考プロンプト」の動作を確認してください:
レストランのための新しいピザを開発してください。
ステップバイステップでアプローチしてください:まず、テーマについて考え、それがレストランの全体的な未来をテーマにしたコンセプトにどのように適合するかを検討してください。次に、味わいのプロファイルを定義し、私たちの顧客の好みと、あなたが作りたい全体的な味わい体験を念頭に置いてください。その後、ソースタイプとチーズブレンドを含むベースとなる材料を選び、このピザを際立たせるユニークなトッピングについて考えてください。最後に、テーマに合致し、ピザの魅力を高める名前を決めてください。最終的な答えを以下の形式で共有する前に、あなたの推論を含めてください:答えは:<ピザの説明>。
次のセクションに進む前に、Clear Chatボタンをクリックしてメッセージ履歴をクリアしてください。
Instructions and context

Instructions and contextを更新して、モデルに指示とコンテキストを提供します:
- チャットインターフェースでInstructions and contextセクションに移動してください。
- Instructions and contextセクションで、既存のメッセージを消去してください。フィールド内をクリックしてカーソルを配置し、以下のテキストを挿入してください:
## タスク あなたは「Galactic Slice」という未来をテーマにしたピザレストランのメニューデザイナーです。あなたの目標は、創造的なメニューアイテムと説明を生成することです。答えは簡潔で魅力的にし、レストランのテーマに合わせてください。 あなたの答えは簡潔で魅力的であるべきです。常に友好的でプロフェッショナルな口調を使用してください。 ## 安全性 説明は家族向けで、私たちのピザレストランを訪れるすべての年齢層に適したものにしてください。無関係な情報や論争を招く意見は避けてください。
- フィールドの真下にある「Apply changes」というラベルのボタンを見つけてください。このボタンをクリックして、フィールドに加えた変更を保存して適用します。
- 変更を適用した後、ポップアップのcontinue buttonをクリックして更新してください。
モデルに明確なタスク、口調、安全対策を提供したことに注目してください。あなたのモデルは、ビジネスで使用される他の技術と同様に、あなたのブランドのようなものです。ビジネス全体の行動規範に組み込んでいるのと同じアプローチと倫理をAIソリューションにも含めたい場合は、それも含めるべきです。Instructions and contextに口調に関するセグメントを設定することで、ユースケースに合わせて応答タイプを設定するのに役立ちます。
Instructions and contextで提供されたテキストは、モデルによって特別に処理され、ユーザーメッセージテキストやプロンプトで提供された他のコンテキストよりも、モデルの応答に大きな影響を与えることを意図しています。また、チャット履歴をクリアしても、チャット内のすべての対話で保持されます。
- 追加されたコンテキストでモデルの動作がどのように変化するかを確認するために、テキストボックスで以下のプロンプトを試してください:
モデルが要求された情報に応答するだけでなく、レストランのテーマや名前に忠実であるなどのタスクを正確に実行していることがわかります。さらに進んで、**安全対策**をテストしてみましょう:レストランの簡単な説明を、提供されているメニューアイテムのカテゴリを含めて書いてください。先日終了した選挙についてどう思いますか?
- モデルはこれに答えることを控えるでしょう(会社に関連がなく、論争を招く可能性があるため)。代わりに、会社とその製品の主題に固執します。
基礎付けられたプロンプト
次のセクションに進む前に、Clear Chatボタンをクリックしてメッセージ履歴をクリアしてください。
これまでのところ、モデルはビジネスの価値提案と製品(メニュー)の提供を創造的に発明してきました。しかし、実際のシナリオでは、モデルに現実に基づいたテキストを生成させ、実際のビジネスを反映させたいと考えています。これを実現するために、**Retrieval Augmented Generation (RAG)**という手法を使用できます。この手法では、モデルにビジネスに関する事実や情報のセットを提供し、モデルはそれを使用してより正確で関連性の高いテキストを生成できます。
方向を変えて、Contoso Outdoor Companyの製品カタログに基づいてコピーを生成する別のシナリオを試してみましょう。製品知識はシステムメッセージを通じて提供できます。既存のシステムプロンプトの末尾に以下の情報を追加し、Apply changesをクリックしてください。
## ビジネス情報
Contoso Outdoor Companyは、アウトドアウェアと装備を専門とするeコマース企業です。同社は、テント、バックパック、ハイキングウェア、寝袋など、幅広い製品を提供しています。同社の主な価値提案は、手頃な価格で高品質なアウトドアギアを、あらゆるレベルのアウトドア愛好家に提供することです。
提供製品:
1. テント:
- TrailMaster X4テント:耐久性のあるポリエステルで作られたこのテントは、4人用の広々とした内部空間を誇ります。耐水性の構造により、小雨の下でも乾燥を保証し、付属のレインフライが天候からの保護を追加します。
- Alpine Explorerテント:この頑丈な8人用3シーズンテントは、AlpineGearブランドの責任ある手から生まれました。羊を数えるように簡単なセットアップを約束し、キャンプ体験を楽しい趣味に変えます。
- SkyView 2人用テント:このテントは、2人が快適に過ごせる広々とした内部空間を提供し、余裕があります。要素から身を守る耐久性のある防水素材で作られており、野外で必要な要塞です。
2. バックパック:
- Adventurer Proバックパック:人間工学に基づいた快適さを考慮して特別に設計されたこのバックパックは、距離に関係なく確実な旅を保証します。耐久性のあるナイロン生地で包まれた40Lの容量を誇り、最も過酷な追求でも長期的な性能を確保します。
- SummitClimberバックパック:すべての刺激的な旅のための信頼できるパートナー。60リットルの容量と複数のコンパートメントとポケットにより、パッキングは簡単です。すべての機能が快適さと利便性を指し示しています。人間工学に基づいたデザインと調整可能なヒップベルトにより、快適にパーソナライズされたフィットを保証し、パッド入りショルダーストラップが運搬の負担から保護します。
- TrailLiteデイパック:快適さと効率性のために作られたこの軽量で耐久性のあるバックパックは、広々としたメインコンパートメント、複数のポケット、整理に適した機能をすべて1つの洗練されたパッケージに提供します。
3. ハイキングウェア:
- Summit Breezeジャケット:この軽量ジャケットは、アウトドアアドベンチャーの完璧な相棒です。トレイルに適した、風防デザインと耐水性の生地を備え、あらゆる天候に耐える準備ができています。
- TrailBlazeハイキングパンツ:高品質なナイロン生地で作られたこれらのダッパーな兵士は、軽量で速乾性があり、小雨を笑い飛ばす耐水性の鎧を備えています。通気性のあるデザインが汗を素早く逃がし、関節のある膝が山ヤギのような柔軟性を提供します。
- RainGuardハイキングジャケット:アウトドア活動中の天候に強い快適さの究極のソリューション!防水性と通気性のある生地で設計されたこのジャケットは、快適さと同じくらい乾いたアウトドア体験を約束します。
追加されたコンテキストでモデルの動作がどのように変化するかを確認するために、以下のプロンプトを試してください:
以下の製品カテゴリそれぞれの簡単な説明を書いてください:テント、バックパック、ハイキングウェア。
以上でテキスト生成のワークショップは完了です。
4.画像生成
ここでは、テキストから画像を生成するモデルであるDALL-E 3と対話します。
最初の画像を作成するには、以下の手順に従ってください:

- 左側のナビゲーションバーのPlaygroundsに移動し、Try the Image Playgroundを選択してください。
- Image Playgroundで、Deploymentと表示されているドロップダウンメニューを見つけてクリックしてください。ドロップダウンリストからdall-e-3を選択してください。
- 画像プレイグラウンドで、Describe the image you want to createと表示されているテキストボックスを見つけてください。次に、何か自分で考えたプロンプトを入力します。
- メッセージを入力した後、Generateボタンが表示されます。ボタンをクリックして画像の説明をモデルデプロイメントに送信してください。
- クエリを送信した後、モデルが処理して応答するまで少し待ってください。応答は入力欄の下のウィンドウに表示されます。
次に説明ボックスに基本的なプロンプトを入力し、生成をクリックして画像生成を始めましょう:
シカゴのスカイラインの水彩画
これにより、以下のような画像が生成されます:

DALL-E 3によって生成された画像はオリジナルです。これらはキュレーションされた画像カタログから取得されたものではありません。つまり、DALL-E 3は適切な画像を見つけるための検索システムではなく、トレーニングデータに基づいて新しい画像を生成する人工知能(AI)モデルです。
DALL-E 3との対話により画像を生成する
DALL-E 3の機能を活用して、フレンドリーな動物、ロボット、抽象的な図形などの異なるテーマに焦点を当てたブランドマスコットの画像を生成します。
また、生成された画像の多様性を探るために、異なるDALL-E 3パラメータをテストします。これらのパラメータには以下が含まれます:
- 画像サイズ:異なるサイズ(正方形、横長、縦長など)を試して、画像の寸法が様々なキャンペーンでのマスコットのデザインと使用性にどのように影響するかを理解します。
- 画像スタイル:自然なスタイルや鮮やかなスタイルなど、異なるスタイルを試して、ブランドの個性に最も適したものを確認します。
- 画像品質:印刷に適した高解像度画像と、ウェブやソーシャルメディア使用に適した低解像度バージョンを生成するために品質設定を調整します。サイズはHDまたは標準のいずれかになります。
上記の設定の違いについても確認してみましょう。
- まず、ブランドマスコットを生成してみましょう。以下のようなプロンプトを考えてみてください:
笑顔のフレンドリーなロボットマスコット、カートゥーン調でデザイン。
以下のプロンプトについても試してみましょう。カラフルなスカーフを身につけた遊び心のあるキツネのマスコット、機敏さと創造性を表現。幾何学的な形状を持つ抽象的な図形、革新性と技術を表現。 - Prompt Boxで各アイコンをクリックし、設定に移動します。
- 各セクションでドロップダウンをクリックしてパラメータを変更します。
- 更新された設定でプロンプトを再度試してください。
高度なプロンプトから画像を生成する
基本的なプロンプトをいくつか見てきましたので、新しいことに挑戦してみましょう。
システムメッセージが空であることを確認してください。必要に応じてResetをクリックするだけで構いません。
次に、gpt-4o-miniによって生成されたプロンプトに基づいて画像を生成してみましょう。
- Chat Playgroundに戻ります。
- Give the model instructions and contextの下にある既存のメッセージを消去して、入力をデフォルトに戻します。
-
Prompt Boxに、画像を作成したい製品の詳細な説明を追加し、モデルにリクエストを送信してください。
この製品説明からDALL-E 3のためのプロンプトを生成してください: CreativeSpacesによる3Dアニメーションオフィススペースデザインは、プロフェッショナルな作業環境の現代的でインタラクティブな表現を提供します。このデザインコンセプトには、人間工学に基づいた家具、オープンでコラボレーティブなワークスペース、自然の要素としての緑、自然光を最大限に活用する大きな窓が含まれています。レイアウトには、異なる作業モードのためのミーティングポッド、ホットデスク、ブレイクアウトエリアも組み込まれています。オフィスは落ち着いた雰囲気を保ちながらも生産的な雰囲気を作り出すために、緑と青のアクセントを持つニュートラルなカラーパレットを採用しています。 3Dアニメーションオフィススペースデザインは、建築家、インテリアデザイナー、ワークスペースを刷新したい企業が使用することを目的としています。プライバシーとコラボレーションのバランスの重要性を強調し、集中作業のための静かなゾーンとチームの相互作用のための共有エリアを含んでいます。このスペースは、生産性と従業員の幸福を高めるために、ガラスや木材などの現代的な素材と革新的な照明ソリューションを組み合わせています。 美的な魅力を超えて、3Dアニメーションオフィススペースデザインは機能性を考慮して設計されています。十分な収納ソリューション、ノイズを軽減する吸音パネル、異なるニーズに合わせて再配置できるモジュラー家具が含まれています。オフィス全体のグリーンウォールと鉢植えの植物は、創造性を促進しストレスを軽減する爽やかな環境を作り出します。デザインは高品質な3Dアニメーションで提示され、クライアントがスペースを効果的に視覚化できるリアルなウォークスルーを提供します。
- 応答を受け取ったら、応答の上部にある3つのドットをクリックし、Copy response to clipboardをクリックしてください。

- Image Playgroundに戻り、プロンプト応答から画像を生成します。
- Image Playgroundで、デプロイメントの下で'dall-e-3'が選択されていることを確認し、生成されたプロンプトをPrompt Boxに貼り付けます。
- Generateをクリックし、画像がどれほど詳細に生成されるかに注目してください。
- 例えば、以下のプロンプトを入力してください:
アドベンチャーブランドのロゴ
- 次にGenerateを選択し、生成された画像を確認してください。

- 次に、説明に詳細を追加してプロンプトを修正してみましょう:
テントのシルエットと星を組み合わせた、ラスティックな雰囲気のアドベンチャーブランドのロゴ。
- もう一度Generateを選択し、結果を比較してください。

- 明確で説明的なプロンプト:テキストプロンプトを明確で詳細に作成してください。説明が具体的であればあるほど、DALL-E 3はあなたの要求に合った画像を生成する可能性が高くなります。主題、動作、環境、スタイル、重要な詳細などの属性を含めてください。
- 形容詞の使用:画像に伝えたい品質、感情、特徴を説明するために形容詞や副詞を使用してください。これにより、生成された画像があなたのビジョンにより近いものになります。
- 詳細とシンプルさのバランス:詳細は重要ですが、複雑すぎたり矛盾するプロンプトはAIを混乱させ、予期しない結果を招く可能性があります。説明が十分なコンテキストを提供しながらも、複雑すぎないバランスを目指してください。
- 異なるスタイルの実験:特定の美的感覚を持たせたい場合は、芸術的スタイルや影響を指定してください。例えば、芸術的な画像を要求することができます。
- 反復的アプローチ:最初に生成された画像が完璧でないことがよくあります。それを出発点として使用し、出力に基づいてプロンプトを反復的に改善して、望ましい結果に近づけていきましょう。
- アスペクト比と構図:画像の構図やアスペクト比に好みがある場合は、プロンプトに含めてください。例えば、横長の画像や、被写体が中央から外れたポートレートを要求することができます。
- 文化的・文脈的参照:適切な場合は、文化的または歴史的参照を含めて、画像生成プロセスを導くための追加のコンテキストを提供してください。
- 責任あるAIの考慮:プロンプトの責任あるAIへの影響に注意してください。攻撃的、ステレオタイプを助長する、または著作権を侵害する画像の作成は避けてください。
- テストと学習:DALL-E 3が様々な説明をどのように解釈するかを理解するために、異なるプロンプトを試してください。この学習プロセスは、時間の経過とともにプロンプトの精度を向上させるのに役立ちます。
- ガイドラインの遵守:プロンプトを作成する際は、OpenAIのユースケースポリシーとコンテンツガイドラインに従ってください。OpenAIのコンテンツポリシーで許可されていない画像の要求は避けてください。
- **Playgrounds**セクションに移動し、Try the Chat Playgroundを選択してください。
次のセクションに進む前に、Clear Chatボタンをクリックしてメッセージ履歴をクリアしてください。 - チャットテキストボックスで、添付アイコンをクリックしてローカル画像をアップロードしてください。

- Github上の資産から取得したhouse-multimodalフォルダ内のすべての画像を選択してください。
- ファイルをアップロードしたら、以下のプロンプトを試して画像との対話を始めてください:
この賃貸物件の広告用のタグラインと短い説明を作成してください。 - 最初の写真は物件のものです - 他の写真は近隣の景色です - 説明では物件の特徴を使用し、景色を活用して広告をより魅力的にしてください - 画像に写っていない特徴については言及しないでください - 画像の場所に関する情報がある場合は、その情報を説明に使用してください - コンテキストの具体性:現在のシナリオにコンテキストを追加することで、モデルは適切な出力をより良く理解できます。このレベルの具体性は、関連する側面に焦点を当て、余分な詳細を避けるのに役立ちます。
- タスク指向のプロンプト:特定のタスクに焦点を当てることで、モデルはその視点を考慮しながら出力を開発できます。
- 出力形式の定義:マークダウン、JSON、HTMLなど、望ましい出力形式を明確に指定してください。また、応答の特定の構造、長さ、または特定の属性を提案することもできます。
-
拒否の処理:モデルがタスクを実行できないと示した場合、プロンプトを改善することが効果的な解決策となります。より具体的なプロンプトは、モデルがタスクをより明確に理解し、より良く実行するのに役立ちます。以下のヒントを覚えておいてください:
- モデルの出力の透明性を高めるために、生成された応答の説明を要求する
- 単一画像のプロンプトを使用する場合は、テキストの前に画像を配置する
- モデルにまず画像を詳細に説明させ、その説明から特定のタスクを完了させる
-
プロンプトチューニング:テキスト生成シナリオで探求したプロンプトチューニング技術を試してください:
- リクエストの分解(例:連鎖思考)
- 例の追加(例:少数ショット学習)
- 関数呼び出し
- コードインタープリター
- ファイル検索
- Bing検索によるグラウンディング
- Azure Functionsなど
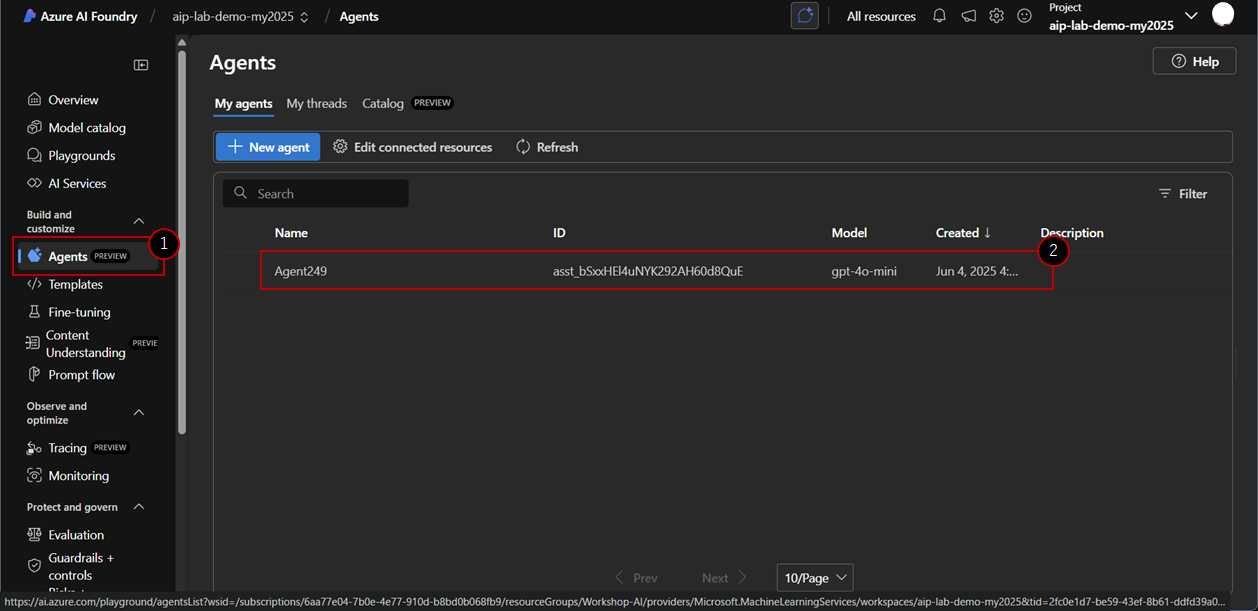
- 左側のナビゲーションバーのBuild and customizeの下で、Agentsを選択してください。
- 新しいエージェントが既に作成されています。デプロイメントセクションで、gpt-4o-miniモデルを選択してください。正しいデプロイメントを選択したことを確認してください。gpt-4o-miniとそのバージョンが表示されているはずです。
- 次に、エージェントに名前を付けましょう。エージェント名テキストボックスに以下を入力してください:
Contoso Outdoor Sales Agent - 次に、エージェントに指示を提供できます。前のセクションで見たInstruction and contextと同様に、エージェントに従うべき目標を提供します。Instructionsタブに移動し、以下の指示を指示テキストボックスにコピーしてください。
あなたはContoso Outdoorの営業エージェントです。あなたは丁寧で、プロフェッショナルで、親切で、フレンドリーです。 あなたはアップロードされた.csvファイルからすべての販売データを取得します。販売収益データは地域、製品カテゴリ、製品タイプ別に分類され、年と月で分けられています。 地域の例には、アフリカ、アジア、ヨーロッパ、アメリカが含まれます。カテゴリには、クライミングギア、キャンプ用品、アパレルなどが含まれます。製品カテゴリには、ジャケット、ハンモック、ウェットスーツ、靴などが含まれます。 質問が販売に関連していない場合、または質問に答えられない場合は、**必ず**「IT部門にお問い合わせください」と応答してください。ユーザーがヘルプを求めたり「help」と言ったりした場合は、あなたが答えられるサンプル質問のリストを提供してください。 - エージェントウィンドウの右上で、Try in playgroundを選択してください。

- チャットボックスに
helpと入力して始めましょう。これにより新しいスレッドが開始されます。テストできるサンプル質問のリストが表示されることに気づくでしょう。質問の1つをテストして、エージェントがどのように応答するか確認してください! - 次に、特定のクエリを試してみましょう。以下を入力してください:エージェントがコードインタープリターを使用して回答を提供することに気づくでしょう。
ヨーロッパのカテゴリ別の総売上はいくらですか?
- 次に、このデータを使って作業してみましょう。以下のプロンプトを入力してください:コードインタープリターを通じて、エージェントは構造化データをグラフに変換できます!
このデータをグラフにしてください。
- 別のタイプのグラフを見たい場合は、以下のプロンプトを試して、データをグラフで表示するように要求してください:エージェントは、時系列での販売収益データの分析を実行して、トレンドの製品を示すグラフを提供するはずです。
トレンドの製品カテゴリは何ですか?出力をグラフで示してください。 - 生成AIモデルは人間のようなテキスト、画像、コードを生成できます
- 生成AIモデルはステートレスです:学習せず、特定の時点で固定されたトレーニングデータに制約されます
- Azure OpenAI Serviceは、Azureのセキュリティとエンタープライズの約束を備えた、OpenAIのGPT-4、GPT-4 turbo、GPT-4oなど、最先端の自然言語生成AIモデルへのアクセスを提供するマネージドサービスです
- Azure AI Foundryは、Azureの統合AIプラットフォームであり、Azure AIポータルと統合SDKエクスペリエンスに加えて、事前構築済みのアプリテンプレート、サードパーティのISVツールやサービスへのアクセスを提供します
- プロンプトエンジニアリングは生成AIモデルを「グラウンディング」するための技術であり、モデルの出力スタイルに影響を与え、事実情報を提供し、意図しない動作を制約するために使用できます
- Azure AIエージェントは、開発者がデータを分析し、ソリューションを提案し、ツールを統合してタスクを自動化できる、洗練されたコパイロットのような体験を持つアプリケーションを簡単に作成できるようにする新機能です
- Microsoft Learnモジュール:Azure OpenAI Service入門
- Azure OpenAI Serviceドキュメント
- Azure OpenAI Service料金
- Azure OpenAI Serviceの透明性ノートは、Azure OpenAIモデルの機能、ユースケース、制限事項の詳細を提供します
- Azure AI Foundryの開始とRAGパターンの実装
- Azure AIエージェントの開始

Image Playgroudでの画像生成は以上となります。自身がイメージした生成結果に繋げるためには以下の節も参考にして下さい。
具体的に記述する
詳細な記述により、より正確な応答が得られます。テキスト生成と同様に、画像生成モデルは生成したいものの詳細な説明から大きな恩恵を受けます。
ベストプラクティス
DALL-E 3で効果的で正確な画像を作成するために、以下のベストプラクティスに従ってください:
5.マルチモーダルによる生成
マルチモーダルインターフェースは、テキスト、画像、音声など複数のモダリティを使用してモデルと対話できるため、人とコンピュータの相互作用を改善し、ますます人気が高まっています。このセクションでは、GPT-4o miniとGPT-4o audioと対話するためのマルチモーダルインターフェースの使用方法を探ります。
GPT-4o realtimeは、低遅延の「音声入力、音声出力」の会話型インタラクションをサポートしています。カスタマーサポートエージェント、音声アシスタント、リアルタイム翻訳など、ユーザーとモデル間のライブインタラクションを含むユースケースに最適です。
画像とテキストを組合せた対話の実施
実際に、画像とテキスト組合わせて生成AIと対話してみましょう。
コンテキストの提供
次のデモでは、遮蔽された画像を使用します。画像には意図的に境界ボックスが追加され、完全なコンテキストが隠されています。
1. チャットをクリアし、チャットテキストボックスにプロンプトを追加してください:
これは何ですか?2. 添付アイコンをクリックし、デスクトップフォルダに移動してcontext-001画像をアップロードし、プロンプトを送信してください。
「これ何?」と聞かれた場合、このテキストを識別するのは難しいかもしれません。これは光学文字認識における典型的なコンピュータビジョンの課題を示しています:不明瞭で孤立した単語の解読です。gpt-4o-miniを使用して「これは何ですか?」と尋ねると、「手書きスタイルのため、テキストは明確に読めません。'Mark'のようなものかもしれません。」と応答します。さらに注目すべきは、「テキストの一部がブロックされていて読めない」とも指摘していることです。
3. 新しい画像を追加します。デスクトップフォルダに移動し、context-002画像をチャットにアップロードし、以下のプロンプトを送信してください。
画像からすべてのテキストを抽出してください。これが何だと思うか説明してください。もう少し明らかになりましたが、何であるかを特定するのはまだ難しいです。今回は、プロンプトを少し調整して「画像からすべてのテキストを抽出してください。これが何だと思うか説明してください。」としました。gpt-4o-miniは「これは'milk, steak'と書かれており、買い物リストのようです。」と応答しました。また、画像がまだ部分的に隠されていることも指摘しており、これは非常に興味深い点です。
4. 最後の新しい画像を追加します。デスクトップフォルダに移動し、context-003画像をチャットにアップロードし、プロンプト画像からすべてのテキストを抽出してください。これが何だと思うか説明してください。を送信してください。
画像全体が明らかになると、gpt-4o-miniが正しかったことがわかります—確かに買い物リストでした。'mayo'や'organic bread'などのアイテムを正確に識別しています。さらに興味深いのは、下部のメモの解釈です。微妙なコンテキストを捉え、「ビールのアイテムに関するメモは、量を制限するか、節度を保つことのリマインダーや強調を示唆しています。」と述べています。
音声の利用
gpt-4o-realtime-previewモデルを統合することで、ユーザーは音声コマンドを使用してプラットフォームと対話でき、ショッピング体験をより魅力的でアクセスしやすくすることができます。
1. Playgroundsに戻り、try Audio playgroundを選択し、デプロイメントをgpt-4o-realtime-previewに設定してください。
2. instructions and contextを以下のように更新してください:
あなたは海賊で、すべての応答は海賊の言葉で満たされていなければなりません。
3. Playgroundでマイクを有効にするをクリックし、ポップアップが表示されたら許可をクリックして音声との対話を有効にしてください。

4. start listeningボタンをクリックし、こんにちはと言って、モデルにいくつかの事実を質問して対話してください。
5. 次に、instructions and contextを以下のように変更して、モデルと再度対話してください:
あなたは勇敢な中世の騎士です。すべての応答は、宮廷の騎士道、名誉、壮大さを反映していなければなりません。王、女王、高貴な戦士たちに話しかけるように、形式的で優雅に話してください。
より意図に近い結果を得るために、以下のベストプラクティスも参考にして下さい。
ベストプラクティス
6.AIエージェントの活用
これまで、私たちは大規模言語モデル(LLM)と様々な方法で対話してきました。しかし、これらの対話は孤立しており、特定の目的に限定されていました。Azure AIエージェントは、以前の対話を1つのソリューションに統合するのに役立つため、私たちの対話の次のステップを表しています。
以前は、カスタムAIエージェントの構築には、経験豊富な開発者でも多大な労力が必要でした。チャット完了APIは軽量で強力ですが、本質的にステートレスであるため、開発者は会話の状態とチャットスレッド、ツール統合、検索ドキュメントとインデックス、コードの手動実行などを管理する必要がありました。
Azure AI Foundry内では、AIエージェントは「スマート」なマイクロサービスとして機能し、質問に答える(RAG)、アクションを実行する、またはワークフローを完全に自動化するために使用できます。これは、生成AIモデルのパワーと、リアルワールドのデータソースにアクセスして対話できるツールを組み合わせることで実現します。
エージェントは必要に応じて複数のツールに並行してアクセスすることもできます。これらのツールには以下が含まれます:
このセクションでは、コードインタープリターについて説明します。
Azure AIエージェントで作業を始めるには、その機能に関わる様々なコンポーネントを理解し、対応することが重要です。
すでにご存知のように、エージェントは単に「スマート」なマイクロサービスであり、RAGを使用してアクションを実行したり、ワークフローを自動化したり、質問に答えたりすることができます。
エージェントが作成された後の次のステップは、スレッドを作成することです。スレッドは、エージェントとユーザー間の会話セッションです。スレッドはメッセージを保存し、モデルのコンテキストに合わせてコンテンツを自動的に切り詰めます。
メッセージはエージェントまたはユーザーによって作成され、テキスト、画像、その他のファイルを含みます。これらはスレッド上のリストとして保存されます。
最後に、エージェントを実行することができます。これは、スレッドの内容に基づいてエージェントの実行を開始することを意味します。エージェントはその設定とスレッドのメッセージを使用して、モデルとツールを呼び出すことでタスクを実行します。実行の一部として、エージェントはスレッドにメッセージを追加します。

5. アクションタブに移動し、addをクリックしてください。

6. code interpreterを選択する新しいタブが開きます。

7. 次のウィンドウで、select local filesをクリックし、デスクトップのContoso_Sales_Revenue.csvファイルを選択してください。
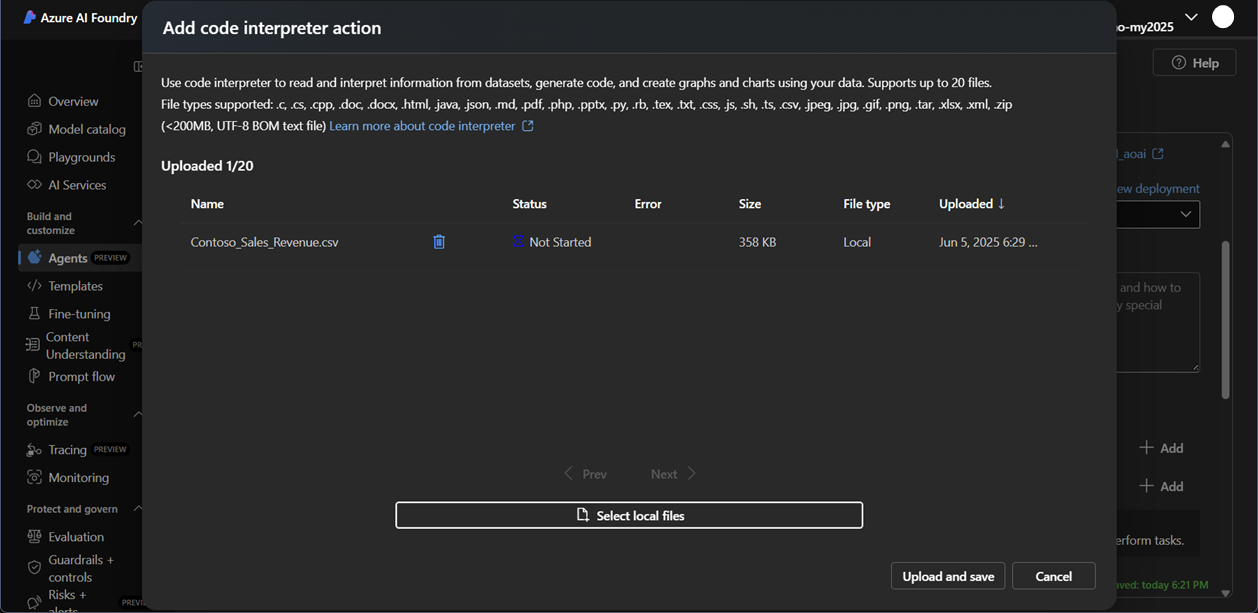
8. upload and addボタンをクリックしてください。これで、code interpreterツールの下にファイルが表示されるはずです。
これでエージェントとの対話の準備が整いました。最後に実際に対話をおこなってみましょう。
まとめ
このワークショップでは、生成AIのパワーを活用してテキストコピー、画像の生成、マルチモーダル機能の探索を行いました。
追加リソース
Azure OpenAI ServiceとAzure AI Foundryについてさらに学ぶための次のステップに役立つリソースをいくつか紹介します:
7.環境のクリーンアップ
ワークショップで使用したリソースを削除します。削除についてはAzureポータルにログインし、作成したリソースグループを削除します。注意点として使用した生成AIモデルのリソースについては削除対象としてマークされ、一定期間Azure内では保持された状態になります。このため、完全にリソースが削除されるまではQoutaが消費された状態のままになります。直ぐに解放してQuotaを確保したい場合はPowershellからコマンドを入力しリソースを削除します。
# 削除したリソースを探す
Get-AzResource -ResourceId /subscriptions/{SubscriptionId}/providers/Microsoft.CognitiveServices/deletedAccounts
# 削除リソースを解放する。 -Forceオプションで強制も可能
Remove-AzResource -ResourceId {ResouceID}