なぜこれが必要?
- 非同期呼び出しでLambdaを起動した場合は、Lambda自体の機能で別のLambdaを起動できる
- しかし、同期呼び出しの場合そういうのがなさそうなので別のサービスを組み合わせる必要がある
やること
-
エラー監視したいLambdaに紐づくCloudwatchのログを開いて、Lambdaサブスクリプションフィルターを作成するをクリック

-
設定項目をいい感じに設定して作成する
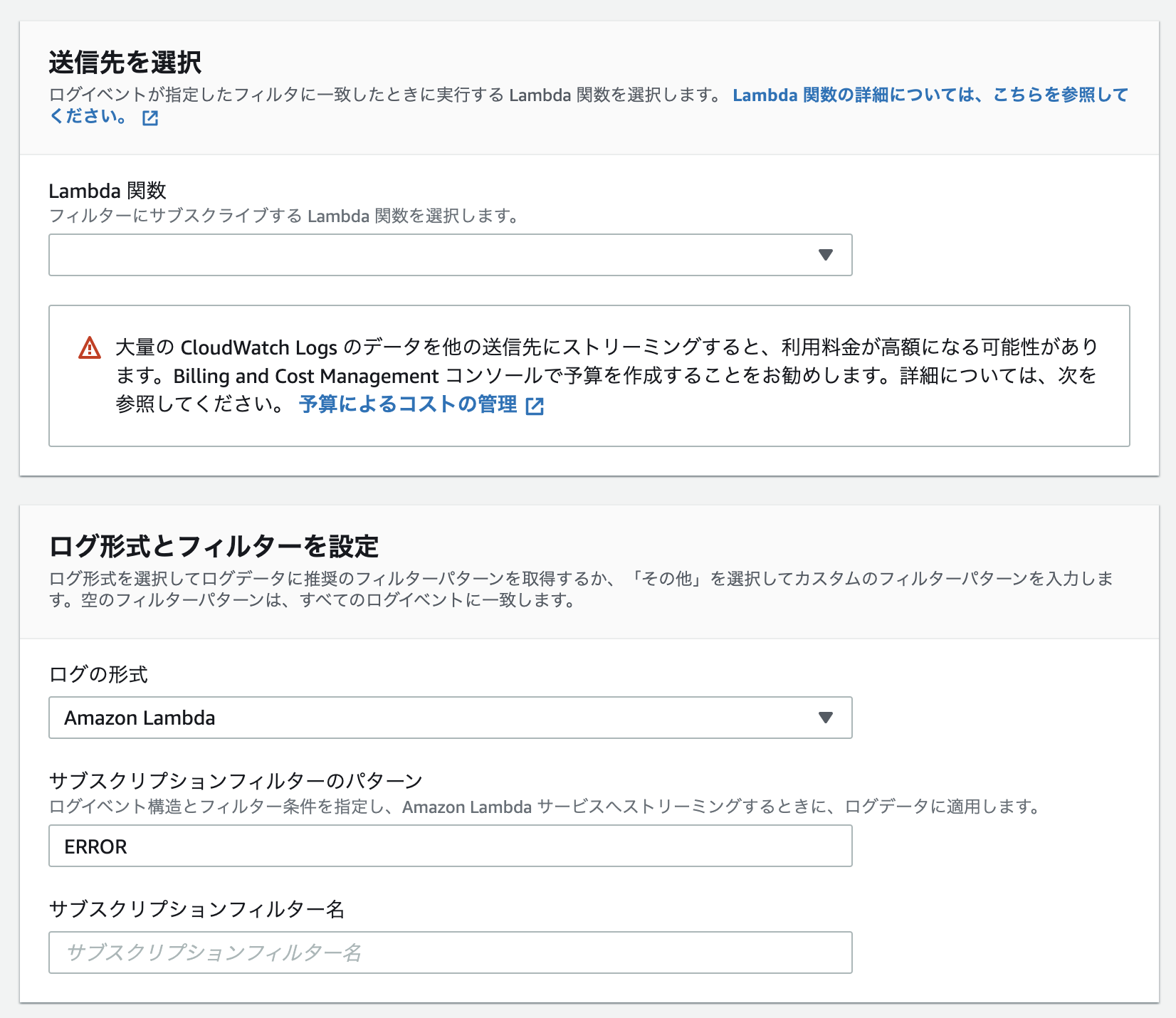
-
↑の設定でセットした「Lambda関数」に下記のような内容を入れてデプロイ
実装例.py
import base64
import datetime
import gzip
import json
from urllib.parse import quote_plus
JST = datetime.timezone(datetime.timedelta(hours=9), "JST")
def lambda_handler(event, context):
# print(event)
# event["awslogs"]["data"])にデータが入っている
# ログをgzip -> base64でエンコード されているのでデコードする
b64decoded = base64.b64decode(event["awslogs"]["data"])
gzip_decomporesed = gzip.decompress(b64decoded)
gzip_decomporesed_str = gzip_decomporesed.decode("utf-8")
data_parsed = json.loads(gzip_decomporesed_str)
# quote_plusを二回叩いている理由は参考記事を参照
# /も対象にしたいので、quoteではなくquote_plusを使った方が楽
# quote_plusだと%が残っちゃうので、cloudwatch logsのURLに合わせて% -> $に置き換え
log_group = quote_plus(quote_plus(data_parsed["logGroup"])).replace("%", "$")
log_stream = quote_plus(quote_plus(data_parsed["logStream"])).replace("%", "$")
# cloudwatch logsでフィルターを使いたい場合の記述例
# こっちは一回置き換えでいい感じの文字列になるっぽい?
# pattern = quote_plus("?filterPattern=ERROR").replace("%", "$")
pattern = ""
log_url = f"https://ap-northeast-1.console.aws.amazon.com/cloudwatch/home?region=ap-northeast-1#logsV2:log-groups/log-group/{log_group}/log-events/{log_stream}{pattern}"
error_events = [
{
"message": log_event["message"],
"errorAt": datetime.datetime.fromtimestamp(
log_event["timestamp"] / 1000, tz=JST
).strftime("%Y-%m-%d %H:%M:%S"),
}
for log_event in data_parsed["logEvents"]
]
# 必要ならこの辺で何かしらの通知なりなんなりを呼ぶ
body = {"logUrl": log_url, "errorEvents": error_events}
# print(body)
return {"statusCode": 200, "body": body}
参考記事