概要
最近業務でもCline / RooCodeの試験導入を始めたが、MCP(Model Context Protocol)を正しく利用することで開発体験が更に向上できそうと感じた。そもそもMCPって何?というレベルなので調査のついでにメモしておく。
個人向けの備忘なので、チラシ裏レベルのことしか書いてませんが他の誰かにも参考になれば幸いです。
MCPとは
MCPはAnthropicが2024/11月に公開したオープンソースの規格らしい。
アナウンスと同時に仕様と主要言語(TypeScript、Python、Java、Kotlin)のSDKが公開されている。
MCPは、アプリケーションがLLMにコンテキストを提供する方法を標準化するオープンプロトコルだ。MCPはAIアプリケーションのUSB-Cポートのようなものだと考えてほしい。USB-Cがデバイスを様々な周辺機器やアクセサリーに接続するための標準化された方法を提供するように、MCPはAIモデルを様々なデータソースやツールに接続するための標準化された方法を提供します。
上記は参考元の翻訳の引用。
肝心の内容は、LLMからデータソースを接続する部分の規格を統一したものらしい。
さまざまなデータリポジトリやサービスとAIアシスタントを統一的な方法で接続する仕組みを提供しており、
分かりやすいメタファーとしてLLMのUSB-Cポートのようなものと表現されていた。
コンポーネント
以下は公式から引用した図
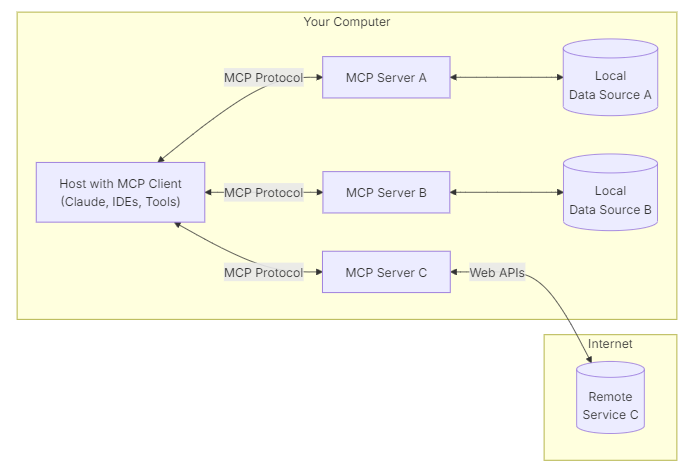
主要なコンポーネントは以下
- MCPホスト、MCPクライアント:
IDE、ClaudeデスクトップなどMCPを介してデータにアクセスするホストとそのホストで稼働するクライアントプロセス - MCPサーバ:
MCPクライアントと通信するサーバ。クライアントとの通信はMPCプロトコルを介して行う - ローカルデータソース、リモートサービス:
MCPサーバーが安全にアクセスできる、コンピュータのファイル、 データベース、サービスもしくはインターネット上で利用可能な外部システム(APIなど)。
RAGとの違いは?
参考
どちらもLLMに外部の情報を取り込んで回答する仕組みだが、担うレイヤーが違いそう。
RAGが「情報を取ってくる」役割なら、MCPは「情報を取ってきて整理・統合し、モデルの動きをコントロールする」より高度なレイヤーを担ってそう。
RAG
シンプルに情報を「検索して貼り付ける」手法。
ユーザーが質問すると、その都度関連する文書やデータベースを検索して、得られた情報をLLMへのプロンプトに追加する。毎回検索結果を詰め込むため、情報が多すぎたり不要な情報が混ざったりするとLLMから期待した回答が得られないかもしれない。
つまり、追加された情報をモデルがそのまま処理するため、文脈や情報の整理はAI任せになりがち。
MCP
LLMと外部情報をつなぐ「情報統合のための仕組み(プロトコル)」。
対話中にLLM自身が直接外部ツールを呼び出してリアルタイムに情報を取得したり、状況に応じて再度データを取りに行ったりなど「行動」を取れるようにしている。
また、得た情報はラベル付けしてレイヤー化しているらしい。
(「必ず参照すべき情報」「参考程度でよい情報」など)
結果、モデルが文脈を理解しやすくなり、より精度の高い応答や一貫した行動が可能になる。
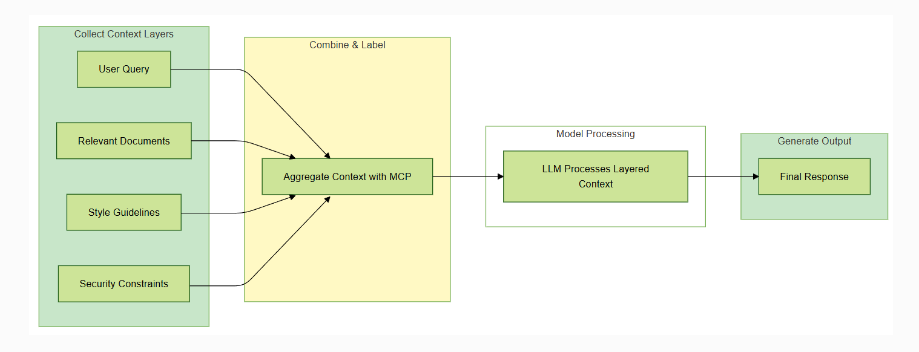
図:上記の参考から引用
実際の利用イメージ
軽く調べた感じ、現状は以下のシーンで利用できそう
- Claudeデスクトップから利用する
- Clien/RooCodeから利用する
Claudeデスクトップから利用する
上記はClaudeデスクトップからローカルのファイルシステムにアクセスするために、MCPサーバを作成するチュートリアル。
ClaudeデスクトップにはMCP Clientは組み込まれているっぽいので、MCP Serverの設定を行えば、プロンプトの実行時に自動的にMCP Serverの情報が反映されるようになる(はず)
Clien/RooCodeから利用する
上記が参考になりました。
ClienでMCPを有効にした場合のみ、システムプロンプトにはMCP関連の説明が追加されるらしい。
その際、使用できるMCPのサーバーやそのサーバーで使えるリソースとツールなどがプロンプトに追加される。
マーケットプレイスとして豊富なMCPサーバが利用できる。
まとめ
なんとなく概念は理解できたので、実際に使ってみたいと思う。
次回はそのあたりが記載できれば