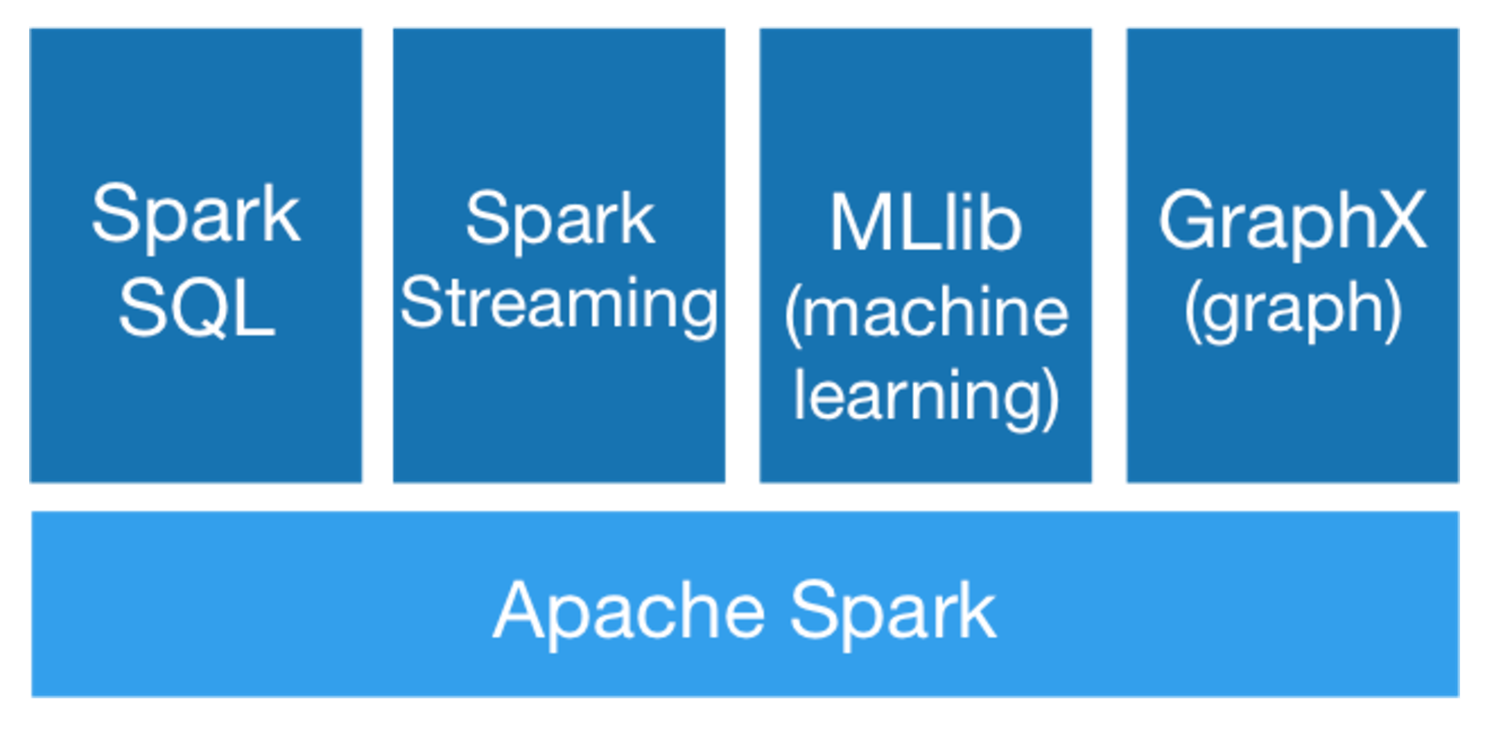
Sparkとは
ライトニング高速クラスタコンピューティング。
バッチ処理を大規模分散するライブラリ。分散処理を良しなにやってくれる。
SQL使える。ストリーミングデータ使える。機械学習使える。グラフ理論使える。ディープラーニング載せれる。これらがメモリを駆使して高速にクラスタ分散してくれる。
試した環境
- mac
- python2.7.12
- spark-1.6.2-bin-hadoop2.6
Sparkのインストール
JDKのインストール
sudo apt-get install -y openjdk-8-jdk
brew cask install java
mavenのインストール
sudo apt install maven
brew install maven
Sparkのインストール
/usr/local/spark を SPARK_HOME とする。任意のバージョンを選択。
http://ftp.riken.jp/net/apache/spark/
wget http://ftp.riken.jp/net/apache/spark/spark-1.6.2/spark-1.6.2-bin-hadoop2.6.tgz
$ tar zxvf spark-1.6.2-bin-hadoop2.6.tgz
$ sudo mv spark-1.6.2-bin-hadoop2.6 /usr/local/
$ sudo ln -s /usr/local/spark-1.6.2-bin-hadoop2.6 /usr/local/spark
.bashrc に以下を追記
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin
brew install apache-spark
spark-shell実行
$ spark-shell --master local[*]
(中略)
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.6.1
/_/
Using Scala version 2.10.5 (OpenJDK 64-Bit Server VM, Java 1.8.0_91)
Type in expressions to have them evaluated.
Type :help for more information.
(中略)
scala> val textFile = sc.textFile("/usr/local/spark/README.md")
textFile: org.apache.spark.rdd.RDD[String] = /usr/local/spark/README.md MapPartitionsRDD[1] at textFile at <console>:27
scala> val wordCounts = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b)
wordCounts: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[4] at reduceByKey at <console>:29
scala> wordCounts.collect()
res0: Array[(String, Int)] = Array((package,1), (For,2), (Programs,1), (processing.,1), ...(中略)..., (>>>,1), (programming,1), (T...
scala>
コンソールで動くか確認。
pythonで使う場合は
./bin/pyspark
jupyterでpysparkを動かしたい場合
.bashrc に以下を追記
# spark
export SPARK_HOME=/usr/local/spark/spark-1.6.2-bin-hadoop2.6
export PATH=$PATH:$SPARK_HOME/bin
# jupyter spark
export PYSPARK_PYTHON=$PYENV_ROOT/shims/python #環境に合わせてパスを合わせること
export PYSPARK_DRIVER_PYTHON=$PYENV_ROOT/shims/jupyter
export PYSPARK_DRIVER_PYTHON_OPTS="notebook"
source .bashrc
pyspark
pysparkコマンドの実行でjupyterが立ち上がる。sparkのRDDを掴んでくれないようなエラーが出る場合は、カーネル再起動などすると直った。
分散データセット(RDD)
並列化されたコレクション
並列実行が可能になる。
val data = Array(1, 2, 3, 4, 5)
val distData = sc.parallelize(data)
List<Integer> data = Arrays.asList(1, 2, 3, 4, 5);
JavaRDD<Integer> distData = sc.parallelize(data);
data = [1, 2, 3, 4, 5]
distData = sc.parallelize(data)
外部データ・セット
val distFile = sc.textFile("data.txt")
distFile: org.apache.spark.rdd.RDD[String] = data.txt
JavaRDD<String> distFile = sc.textFile("data.txt");
distFile = sc.textFile("data.txt")
RDD操作
基本
textFileでデータを取得し、rddに乗せる
mapで変換
reduceで集計
val lines = sc.textFile("data.txt")
val lineLengths = lines.map(s => s.length)
val totalLength = lineLengths.reduce((a, b) => a + b)
JavaRDD<String> lines = sc.textFile("data.txt");
JavaRDD<Integer> lineLengths = lines.map(s -> s.length());
int totalLength = lineLengths.reduce((a, b) -> a + b);
lines = sc.textFile("data.txt")
lineLengths = lines.map(lambda s: len(s))
totalLength = lineLengths.reduce(lambda a, b: a + b)
スパークする関数の受け渡し
object MyFunctions {
def func1(s: String): String = { ... }
}
myRdd.map(MyFunctions.func1)
JavaRDD<String> lines = sc.textFile("data.txt");
JavaRDD<Integer> lineLengths = lines.map(new Function<String, Integer>() {
public Integer call(String s) { return s.length(); }
});
int totalLength = lineLengths.reduce(new Function2<Integer, Integer, Integer>() {
public Integer call(Integer a, Integer b) { return a + b; }
});
"""MyScript.py"""
if __name__ == "__main__":
def myFunc(s):
words = s.split(" ")
return len(words)
sc = SparkContext(...)
sc.textFile("file.txt").map(myFunc)
クロージャを理解する
例
var counter = 0
var rdd = sc.parallelize(data)
// Wrong: Don't do this!!
rdd.foreach(x => counter += x)
println("Counter value: " + counter)
int counter = 0;
JavaRDD<Integer> rdd = sc.parallelize(data);
// Wrong: Don't do this!!
rdd.foreach(x -> counter += x);
println("Counter value: " + counter);
counter = 0
rdd = sc.parallelize(data)
# Wrong: Don't do this!!
def increment_counter(x):
global counter
counter += x
rdd.foreach(increment_counter)
print("Counter value: ", counter)
Key-Valueペアの操作
val lines = sc.textFile("data.txt")
val pairs = lines.map(s => (s, 1))
val counts = pairs.reduceByKey((a, b) => a + b)
JavaRDD<String> lines = sc.textFile("data.txt");
JavaPairRDD<String, Integer> pairs = lines.mapToPair(s -> new Tuple2(s, 1));
JavaPairRDD<String, Integer> counts = pairs.reduceByKey((a, b) -> a + b);
lines = sc.textFile("data.txt")
pairs = lines.map(lambda s: (s, 1))
counts = pairs.reduceByKey(lambda a, b: a + b)
変換
| 変換 | 意味 |
|---|---|
| map(func) | ソースの各要素を関数funcで渡すことによって形成された新しい分散データセットに変換。 |
| filter(func) | funcがtrueを返すソースの要素を選択して新しいデータセットを返します。 |
| flatMap(func) | mapと似ていますが、各入力項目は0個以上の出力項目にマッピングできます(funcは単一の項目ではなくSeqを返す必要があります)。 |
| mapPartitions(func) | マップに似ていますが、RDDの各パーティション(ブロック)で個別に実行されるため、タイプTのRDDで実行する場合、funcはIterator => Iterator でなければなりません。 |
| mapPartitionsWithIndex(func) | mapPartitionsに似ていますが、funcにはパーティションのインデックスを表す整数値が与えられます。したがって、タイプTのRDDで実行する場合、funcは(Int、Iterator )=> Iterator の型でなければなりません。 |
| sample(withReplacement, fraction, seed) | 指定された乱数ジェネレータシードを使用して、置換の有無にかかわらずデータの小数部分をサンプリングします。 |
| union(otherDataset) | ソースデータセット内の要素と引数の和集合を含む新しいデータセットを返します。 |
| intersection(otherDataset) | ソースデータセット内の要素と引数の共通部分を含む新しいRDDを返します。 |
| distinct([numTasks])) | ソースデータセットの異なる要素を含む新しいデータセットを返します。 |
| groupByKey([numTasks]) | (K、V)の組のデータセットで呼び出されると、(K、Iterable )組のデータセットを返します。 注意:reduceByKeyまたはaggregateByKeyを使用すると、キーごとに集計(合計や平均など)を実行するためにグループ化する場合、パフォーマンスが大幅に向上します。 注意:デフォルトでは、出力の並列度は親RDDのパーティション数によって異なります。オプションのnumTasks引数を渡して、異なる数のタスクを設定することができます。 |
| reduceByKey(func, [numTasks]) | (K、V)の組のデータセットで呼び出されると、各キーの値が(V、V)=>型の指定されたreduce関数funcを使用して集計される(K、V) V. groupByKeyと同様に、reduceタスクの数はオプションの第2引数を介して設定できます。 |
| aggregateByKey(zeroValue)(seqOp, combOp, [numTasks]) | (K、V)ペアのデータセットで呼び出されると、(K、U)ペアのデータセットが返されます。ここで、各キーの値は、指定された結合関数と中立の「ゼロ」値を使用して集計されます。不必要な割り当てを回避しながら、入力値タイプとは異なる集計値タイプを許可します。 groupByKeyと同様に、reduceタスクの数はオプションの第2引数で設定可能です。 |
| sortByKey([ascending], [numTasks]) | KがOrderedを実装する(K、V)ペアのデータセットで呼び出された場合、ブール昇順引数で指定されているように、昇順または降順のキーでソートされた(K、V)ペアのデータセットを返します。 |
| join(otherDataset, [numTasks]) | (K、V)および(K、W)型のデータセットで呼び出されると、各キーのすべての要素のペアを含む(K、(V、W))のペアのデータセットを返します。外部結合は、leftOuterJoin、rightOuterJoin、およびfullOuterJoinによってサポートされています。 |
| cogroup(otherDataset, [numTasks]) | (K、(Iterable 、Iterable ))タプルのデータセットを返します。この操作はgroupWithとも呼ばれます。 |
| cartesian(otherDataset) | 型Tと型Uのデータセットに対して呼び出されると、(T、U)のペア(要素のすべてのペア)のデータセットを返します。 |
| pipe(command, [envVars]) | RDDの各パーティションをシェルコマンド(例: Perlまたはbashスクリプト。 RDD要素はプロセスのstdinに書き込まれ、stdoutに出力される行はRDDとして返されます。 |
| coalesce(numPartitions) | RDD内のパーティション数をnumPartitionsに減らします。大規模なデータセットをフィルタリングした後、より効率的に操作を実行するのに便利です。 |
| repartition(numPartitions) | RDD内のデータをランダムに再シャッフルして、より多くのパーティションまたはより少ないパーティションを作成し、それらのパーティション間でバランスを取ってください。これにより、ネットワーク上のすべてのデータが常にシャッフルされます。 |
| repartitionAndSortWithinPartitions(partitioner) | 指定されたパーティショナーに従ってRDDを再パーティション化し、それぞれの結果のパーティション内で、キーでレコードをソートします。これは、再分割を呼び出すよりも効率的で、ソートをシャッフル機構にプッシュすることができるので、各パーティション内でソートする方が効率的です。 |
アクション
| アクション | 意味 |
|---|---|
| reduce(func) | 関数func(2つの引数をとり、1つを返す)を使用してデータセットの要素を集計します。関数は、並列に正しく計算できるように、可換性と連想性を持つ必要があります。 |
| collect() | ドライバプログラムで、データセットのすべての要素を配列として返します。これは通常、データの十分に小さなサブセットを返すフィルタやその他の操作の後に便利です。 |
| count() | データセット内の要素の数を返します。 |
| first() | データセットの最初の要素を返します(take(1)と同様)。 |
| take(n) | データセットの最初のn個の要素を含む配列を返します。 |
| takeSample(withReplacement, num, [seed]) | 置換の有無にかかわらず、乱数ジェネレータシードを事前に指定して、データセットのnum要素のランダムサンプルを含む配列を返します。 |
| takeOrdered(n, [ordering]) | 自然順序またはカスタムコンパレータのいずれかを使用して、RDDの最初のn要素を返します。 |
| saveAsTextFile(path) | データファイルの要素を、ローカルファイルシステム、HDFS、またはその他のHadoopでサポートされているファイルシステムの特定のディレクトリに、テキストファイル(またはテキストファイルのセット)として記述します。 Sparkは各要素のtoStringを呼び出してファイル内のテキスト行に変換します。 |
| saveAsSequenceFile(path) | |
| (Java and Scala) | データファイルの要素を、ローカルファイルシステム、HDFS、またはその他のHadoopでサポートされているファイルシステムの指定されたパスにHadoop SequenceFileとして書き込みます。これは、HadoopのWritableインターフェイスを実装するキーと値のペアのRDDで利用できます。 Scalaでは、暗黙的にWritableに変換可能な型でも使用できます(SparkはInt、Double、Stringなどの基本型の変換を含みます)。 |
| saveAsObjectFile(path) | |
| (Java and Scala) | Javaシリアル化を使用して、データセットの要素を簡単な形式で記述します.Javaシリアル化は、SparkContext.objectFile()を使用してロードできます。 |
| countByKey() | タイプ(K、V)のRDDでのみ利用可能です。 (K、Int)のペアのハッシュマップを各キーのカウントで返します。 |
| foreach(func) | データセットの各要素に対して関数funcを実行します。これは通常、アキュムレータの更新や外部ストレージシステムとの相互作用などの副作用に対して行われます。 注意:foreach()の外部でAccumulators以外の変数を変更すると、未定義の動作が発生する可能性があります。詳細については、「クロージャの理解」を参照してください。 |
まずは動かしてみる(python編)
海外の競技で使われたものが凄くわかりやすかったのでForkしてきました。
Jupyterなので上から順番に実行するのみ。
ソースはこちら
https://github.com/miyamotok0105/spark-py-notebooks
目次
RDDの作成
ファイルの読み込みと並列化について
RDDの基礎
map, filter, collectについて
RDDのサンプリング
RDDサンプリング方法を説明。
RDDセット操作
いくつかのRDD擬似セット操作の簡単な紹介。
RDD上のデータ集約
RDDアクション reduce, fold, aggregateについて 。
キーと値のペアRDDの操作
データを集約して探索するためのキーと値のペアの扱い方。
MLlib:基本統計と探索的データ解析
ローカルベクトルタイプ、Exploratory Data Analysisおよびモデル選択のためのMLlibの基本統計を紹介するノートブック。
MLlib:ロジスティック回帰
MLlibにおけるネットワーク攻撃のラベル付けされたポイントとロジスティック回帰の分類。相関行列と仮説検定を用いたモデル選択手法の応用。
MLlib:デシジョンツリー
ツリーベースの方法の使用、およびモデルと機能の選択の説明に役立つ方法。
Spark SQL:データ分析のための構造化処理
このノートブックでは、ネットワークインタラクションのデータセットに対してスキーマが推論されます。それに基づいて、SparkのSQL DataFrame抽象化を使用して、より構造化された探索的データ分析を実行します。
MLlib(KMeans)でクラスタリング
アイリスデータのクラスタリング処理。
主な内容
RDDの作成
data_file = "./kddcup.data_10_percent.gz"
# 一般的な作成
raw_data = sc.textFile(data_file)
# 並列化作成
raw_data = sc.parallelize(data_file)
RDDの基礎
# フィルタ変換
normal_raw_data = raw_data.filter(lambda x: 'normal.' in x)
# マップ変換
csv_data = raw_data.map(lambda x: x.split(","))
RDDのサンプリング
乱数ジェネレータシードを事前に指定して、データセットのnum要素のランダムサンプルを含む配列を返します。
raw_data_sample = raw_data.takeSample(False, 400000, 1234)
RDDの操作を設定する
normal_raw_data = raw_data.filter(lambda x: "normal." in x)
# 減算
attack_raw_data = raw_data.subtract(normal_raw_data)
# デカルト積(直積集合)
product = protocols.cartesian(services).collect()
print "There are {} combinations of protocol X service".format(len(product))
Mlib 協調フィルタリングによるレコメンデーション
協調フィルタリングとは
ユーザとアイテムのマトリックスを用いた顧客への商品のレコメンデーションです。このマトリックスより、ユーザの相関を分析し、類似したユーザはお互いが購入している商品買うという仮定に基づきレコメンデーションする仕組みといえます。参考

内容ベースと協調フィルタリング
協調フィルタリング
- ユーザの行動を元にレコメンド
内容ベース(コンテンツベース)フィルタリング
- アイテムの特徴ベクトルで類似度ソートしてレコメンド
内容ベースと協調フィルタリングの長所と短所

レコメンドモジュールの読み込み
from pyspark.mllib.recommendation import ALS, MatrixFactorizationModel, Rating
レコメンデーションの作成
model = ALS.train(ratings, rank, numIterations)
予測
predictions_all = model.predictAll(sc.parallelize(f_XY)).map(lambda r: ((r[0], r[1]), limitter(r[2]) ))
Sparkによる実践データ解析 ――大規模データのための機械学習事例集
ソースのダウンロード。完全にScala。そしてこの本はかなりScala色が強い。
Spark知ってる前提で書いてる。
https://github.com/sryza/aas.git
git checkout 1st-edition
2章 音楽のレコメンドとAudioscrobblerデータセット
データを取得
wget http://www.iro.umontreal.ca/~lisa/datasets/profiledata_06-May-2005.tar.gz
tar xzvf profiledata_06-May-2005.tar.gz
結果
profiledata_06-May-2005/
profiledata_06-May-2005/artist_data.txt
profiledata_06-May-2005/README.txt
profiledata_06-May-2005/user_artist_data.txt
profiledata_06-May-2005/artist_alias.txt
プラスα
深層学習フレームワークがSparkに乗ってる例
BigDL(torch base)
https://github.com/intel-analytics/BigDL
TensorFlow
https://github.com/yahoo/TensorFlowOnSpark
keras
https://github.com/maxpumperla/elephas
## 全部入りdocker https://github.com/jupyter/docker-stacks/tree/master/all-spark-notebook dockerについてわかりやすい資料 https://www.slideshare.net/ShinichiroOhhara/docker2017
Jupyterをリモートから呼びたい場合
確かにこれで動くが。permmisionとかでエラー出てて困ったけど、そもそも必要なフォルダーとかファイルが足りてないのでエラーが出てた気がする。Sparkか何かのエラーログを見て何か追加した覚えがある。
Sparkプログラムガイド
Mastering Apache Spark 2
Scalaキーワード
Scalaではリストが大事
Caseクラスを使う
イミュータブルなプログラム
協調フィルタリング
http://en.wikipedia.org/wiki/Collaborative_filtering
http://d.hatena.ne.jp/EulerDijkstra/20130407/1365349866
https://www.slideshare.net/hoxo_m/ss-53305070
awsでクラスタするときのセットアップ