evernoteの全文を抽出する必要がありその時に使った方法を公開します。
EvernoteAPIを使えばできそうですが、それほどのことでないので面倒ですよね。
そこで、全ノートをhtml形式で出力してBeautifulSoupでスクレイピングする方法を紹介していきます。
Evernoteの全ノートをhtml形式で出力する
まず、Command + Aで全ノートを選択します。そこからノートをエクスポートします。
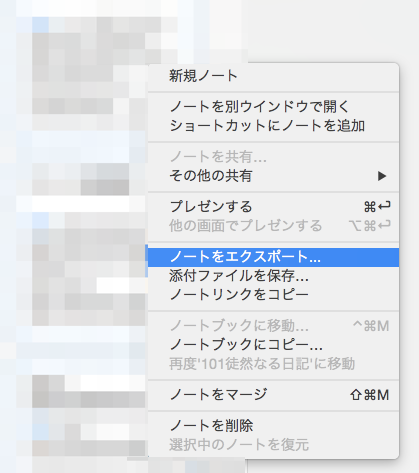
出力する形式はhtmlを選択してください。
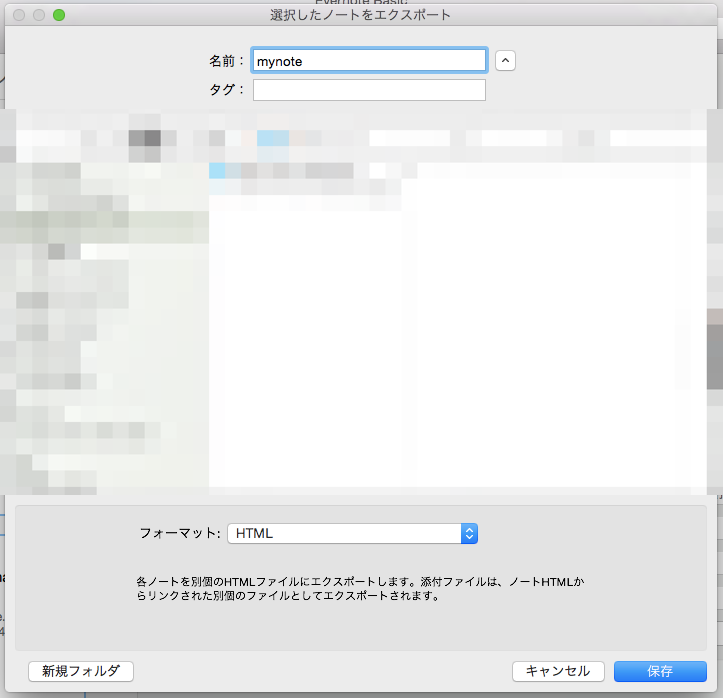
今回はこれをmynoteとしてデスクトップに保存します。
mynoteのindex.htmlには出力したファイル全てのノートの目次になっていて、各htmlファイルへのリンクがあるのでそれを利用します。
手順としては
- index.htmlから出力するノートのurlを抽出する。
- url先からテキストを抽出する。
- それをSQLiteに保存する。
というものです。
BeautifulSoupを使ってスクレイピングする
そもそもスクレイピングとはwebサイトから特定の情報を抽出したりする行為です。
先ほどスクレイプしたファイルはwebサイトではないですがhtml形式なのでスクレイプすることができます。
スクレイピングできるpythonのモジュールはいくつかありますが今回はBeautifulSoupというものを使っていきます。
pipでBeautifulSoupでインストールしましょう。
$ pip install beautifulsoup4
BeatifulSoupは基本的に以下のように使うことになります。
import urllib2
from bs4 import BeautifulSoup
html = urllib2.urlopen("http://~ ~ ~")
soup = BeautifulSoup(html)
scrape = soup.find_all("a")
詳しくは公式ドキュメントをご覧ください。
http://www.crummy.com/software/BeautifulSoup/bs4/doc/
今回使うのはsoup.get_text()とsoup.find_all("a")とsoup.get("href")のみです。
SQLAlchemyを使ってデータベースに保存する
SQLAlchemyとはORマッパーと言って、SQLで記述しなくてもデータベースとやりとりができる便利なやつです。
インストールはpipで行いましょう。
$ pip install sqlalchemy
Evernoteの文章を抽出する
準備は出来たのでスクレイピングしていきます。
まずはノートのurlを指定したらその文章のみを抽出して返す関数をつくります。
def scrape_evernote(url):
note_url = "file:///(ノートのディレクトリ)" + url.encode('utf-8')
html = urllib2.urlopen(note_url)
soup = BeautifulSoup(html)
all_items = soup.get_text()
return "".join(all_items)
最初の3行でBeautifulSoupオブジェクトを生成します。
all_items = soup.get_text()でurl先の全文を取得します。
そのあとの部分は、get_text()で取得できる文字は一文字づつ配列に入っているので配列全てを結合させて文字列にしています。
抽出したテキストをSQLiteに保存する
次に抽出したテキストをSQLiteに保存する関数を作ります。
def scrape_and_save2sql():
Base = sqlalchemy.ext.declarative.declarative_base()
class Evernote(Base):
__tablename__ = 'mynote'
id = sqlalchemy.Column(sqlalchemy.Integer, primary_key=True)
title = sqlalchemy.Column(sqlalchemy.String)
note = sqlalchemy.Column(sqlalchemy.String)
db_url = "sqlite+pysqlite:///evernote.sqlite3"
engine = sqlalchemy.create_engine(db_url, echo=True)
Base.metadata.create_all(engine)
# セッションを作成
Session = sqlalchemy.orm.sessionmaker(bind=engine)
session = Session()
#indexから全ノートのurlを取得する
index_url = "file:///(ノートのディレクトリ)/index.html"
index_html = urllib2.urlopen(index_url)
index_soup = BeautifulSoup(index_html)
all_url = index_soup.find_all("a")
for note_url in all_url:
title = note_url.get_text()
note = scrape_evernote(note_url.get("href"))
evernote = Evernote(title=title, note=note)
session.add(evernote)
session.commit()
初めにBaseを作ります。
そのあと、ノートのモデルを作成します。
class Evernote(Base):
__tablename__ = 'mynote'
id = sqlalchemy.Column(sqlalchemy.Integer, primary_key=True)
title = sqlalchemy.Column(sqlalchemy.String)
note = sqlalchemy.Column(sqlalchemy.String)
今回はシンプルにノートのタイトルと内容だけ保存します。
SQLiteの保存場所とセッションを作成します。
あとはindex.htmlから各ノートのタイトルとurlを取得します。
index.htmlの各ノートへのリンクは
<a href="ノートのurl">ノートのタイトル</a>
という構成になっているのでindex_soup.find_all("a")で全部のaタグを取得します。
各タグはそれぞれ配列で格納しているので、取り出してaタグからリンク先のurlとタイトルを取得します。
そのurlから先ほど作ったscrape_evernote()を使ってテキストを抽出します。
最後にコミットしてSQLiteに保存します。
これで抽出は完了です。
SQLiteで出力ではなくて例えばtxtデータに出力したい場合は
def scrape_and_save2txt():
file = open('evernote_text.txt', 'w')
#indexから全ノートのurlを取得する
index_url = "file:///(ノートのディレクトリ)/index.html"
index_html = urllib2.urlopen(index_url)
index_soup = BeautifulSoup(index_html)
all_url = index_soup.find_all("a")
for note_url in all_url:
title = note_url.get_text()
file.write(title)
note = scrape_evernote(note_url.get("href"))
file.write(note)
file.close()
とすれば可能です。
もちろんcsv形式の出力も出来ます。
まとめ
初めの方にも書きましたが大まかの手順は
- evernoteから文章を抽出したいノートをhtml形式で出力する。
- index.htmlから出力するノートのurlを抽出する。
- url先からテキストを抽出する。
- それをSQLiteに保存する。
となっています。
今回は文章のみとなりましたが、画像もノート内のタイトルと同じ名前のフォルダがありそこに保存されています。
これをうまく使えばevernote内の画像を全て抽出することも可能だと思います。