はじめに
これまでSciKit-learnを使って電力使用量を予測する例を何度か公開してきましたが、今回はChainerを使って似たようなことをするサンプルを作ってみました。
参考記事:
※ 本記事のコードについて、学習に関する部分以外はTensorFlow版と同じです。
環境構築
テスト環境
- MacBook Pro Mid 2012
- Python 3.5.1 with Anaconda 4.1.0
- Chainer 3.2.0
Anacondaのインストール
以下のURLより、自分のPC環境に適合するものをダウンロードしてインストール
Chainerのインストール
以下のコマンドを実行
$ pip install chainer
Jupyterの起動
以下のコマンドを実行
$ jupyter notebook
新しいファイルを作成して、以下のコードを実行
データ取得
電力データ
以下のURLより中国電力にて公開されている電力使用量データをダウンロード
http://www.energia.co.jp/jukyuu/download.html
※2016年度と2017年度のデータを取得
気象データ
中国電力管内にある主要都市として、岡山市と広島市をとりあげることとし、岡山市と広島市の気象データをダウンロード
※ 予測精度を向上させるために、他の主要都市の気温データを追加しても良いと思います
以下のURLより気温データをダウンロード
http://www.data.jma.go.jp/gmd/risk/obsdl/index.php
※1時間おきの気温データを電力データと同じ期間にあわせて取得
データ読込
ライブラリ読込
import pandas as pd
%matplotlib inline
電力データ
df_kw = pd.read_csv("juyo-2016.csv",encoding="Shift_JIS",skiprows=1)
df_kw["MW"] = df_kw["実績(万kW)"] * 10
df_kw["DATETIME"] = df_kw.index.map(lambda _: pd.to_datetime(df_kw.DATE[_] + " " + df_kw.TIME[_]))
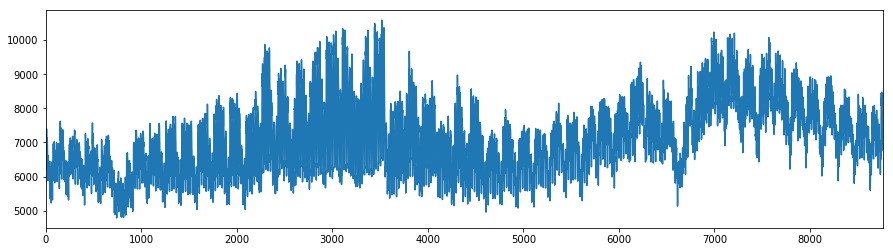
# 可視化
df_kw["MW"].plot(figsize=(15,4))
気象データ
def read_temp(filename):
df_temp = pd.read_csv(filename,encoding="Shift_JIS",skiprows=4)
df_temp.columns = ["DATETIME","TEMP","品質情報","均質番号"]
df_temp.DATETIME = df_temp.DATETIME.map(lambda _: pd.to_datetime(_))
return df_temp
# 岡山
df_temp_okym = read_temp("data_okayama-2016.csv")
df_temp_okym.rename(columns = {'TEMP':'TEMP_okym'}, inplace=True)
# 広島
df_temp_hrsm = read_temp("data_hiroshima-2016.csv")
df_temp_hrsm.rename(columns = {'TEMP':'TEMP_hrsm'}, inplace=True)
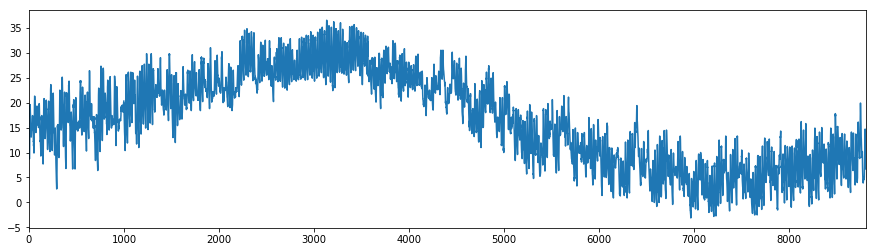
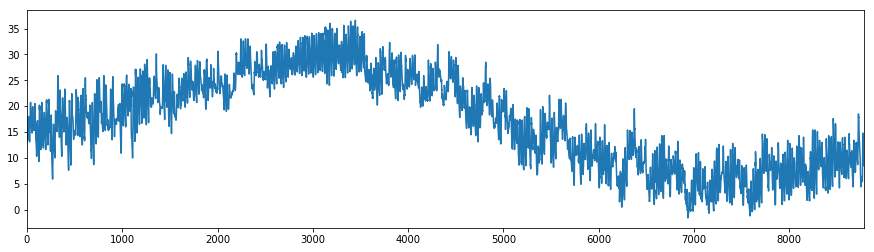
# 可視化
df_temp_okym.TEMP_okym.plot(figsize=(15,4))
df_temp_hrsm.TEMP_hrsm.plot(figsize=(15,4))
[岡山市の気温データ]
[広島市の気温データ]
データ加工
電力と気温のデータを結合
# データの複製
df = df_kw.copy()
# 岡山の気温を結合
df = df.merge(df_temp_okym,how="inner", on="DATETIME")
# 広島の気温を結合
df = df.merge(df_temp_hrsm,how="inner", on="DATETIME")
# 月、週、時間の値を個別に取得
df["MONTH"] = df.DATETIME.map(lambda _: _.month)
df["WEEK"] = df.DATETIME.map(lambda _: _.weekday())
df["HOUR"] = df.DATETIME.map(lambda _: _.hour)
欠損データの削除
# null値の削除
df = df.dropna()
One-hotエンコーディング
cols = ["MONTH","WEEK","HOUR"]
for col in cols:
df = df.join(pd.get_dummies(df[col], prefix=col))
学習
x_cols = ["TEMP_okym","TEMP_hrsm"] + df.columns.tolist()[14:]
X = df[x_cols]
y = df["MW"]
# ラベル付きデータをトレーニングセット (X_train, y_train)とテストセット (X_test,y_test)に分割
from sklearn import model_selection
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=.2, random_state=42)
# 正規化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
# Chainer読込
from chainer import Chain, optimizers, Variable
import chainer.functions as F
import chainer.links as L
# ニューラルネットワークのモデル生成用クラス
class MyChain(Chain):
def __init__(self, n_units=10):
super(MyChain, self).__init__(
l1=L.Linear(len(x_cols), n_units),
l2=L.Linear(n_units, n_units),
l3=L.Linear(n_units, 1))
def __call__(self, x_data, y_data):
x = Variable(x_data.astype(np.float32).reshape(len(x_data),len(x_cols)))
y = Variable(y_data.astype(np.float32).reshape(len(y_data),1))
#print(x)
pred = self.predict(x)
#print(pred)
return F.mean_squared_error(pred, y)
def predict(self, x):
h1 = F.relu(self.l1(x))
h2 = F.relu(self.l2(h1))
h3 = self.l3(h2)
return h3
def get_predata(self, x):
return self.predict(Variable(x.astype(np.float32).reshape(len(x),1))).data
# パラメータ初期化
batchsize = 16
n_epoch = 200
n_units = 10
# モデル生成
model = MyChain(n_units)
optimizer = optimizers.Adam()
optimizer.setup(model)
# 学習
train_losses =[]
test_losses =[]
N = len(X_train)
for epoch in range(1, n_epoch + 1):
perm = np.random.permutation(N)
sum_loss = 0
for i in range(0, N, batchsize):
x_batch = X_train[perm[i:i + batchsize]]
y_batch = y_train[perm[i:i + batchsize]]
model.zerograds()
loss = model(x_batch,y_batch)
sum_loss += loss.data * batchsize
loss.backward()
optimizer.update()
average_loss = sum_loss / N
train_losses.append(average_loss)
loss = model(X_test,y_test)
test_losses.append(loss.data)
# 学習過程を出力
if epoch % 10 == 0:
print("epoch: {}/{} train loss: {} test loss: {}".format(epoch, n_epoch, average_loss, loss.data))
検証
# 予測値の取得
y_pred = model.predict(X_test.astype(np.float32))
# 可視化
pd.DataFrame(np.c_[y_test, y_pred.array], columns=["act","pred"])[:100].reset_index(drop=True).plot(figsize=(15,4))
予測結果との比較グラフは以下のとおり。
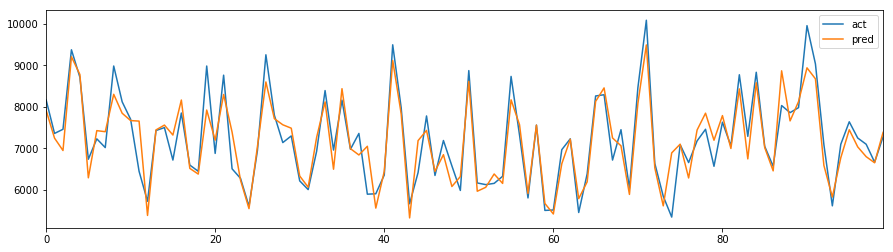
ちなみに、TensorFlow版のグラフはこちら。
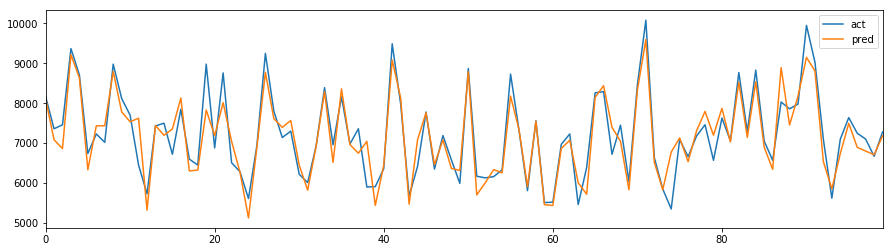
...どちらもそこそこあってそう(^-^)
予測
2017年度データを予測し、確認する。
# 電力データを読込
df_kw = pd.read_csv("juyo-2017.csv",encoding="Shift_JIS",skiprows=1)
# 岡山のデータを読込
df_temp_okym = read_temp("data_okayama-2017.csv")
df_temp_okym.rename(columns = {'TEMP':'TEMP_okym'}, inplace=True)
# 広島のデータを読込
df_temp_hrsm = read_temp("data_hiroshima-2017.csv")
df_temp_hrsm.rename(columns = {'TEMP':'TEMP_hrsm'}, inplace=True)
# データ加工
df_kw.columns = ["DATE","TIME","万kW"]
df_kw["MW"] = df_kw["万kW"] * 10
df_kw["DATETIME"] = df_kw.index.map(lambda _: pd.to_datetime(df_kw.DATE[_] + " " + df_kw.TIME[_]))
# データ結合
df = df_kw.copy()
df = df.merge(df_temp_okym,how="inner", on="DATETIME")
df = df.merge(df_temp_hrsm,how="inner", on="DATETIME")
# 追加データ作成
df["MONTH"] = df.DATETIME.map(lambda _: _.month)
df["WEEK"] = df.DATETIME.map(lambda _: _.weekday())
df["HOUR"] = df.DATETIME.map(lambda _: _.hour)
# 欠損データ削除
df = df.dropna()
# One-hotエンコーディング
cols = ["MONTH","WEEK","HOUR"]
for col in cols:
df = df.join(pd.get_dummies(df[col], prefix=col))
# テストデータの不足分を補完
for col in x_cols[2:]:
if not col in df.columns:
df[col] = 0
# 7月の電力使用量を予測
df_pred = df[df.MONTH==7]
# 予測用データ
X = df_pred[x_cols].as_matrix().astype('float64')
y = df_pred["MW"].as_matrix().astype('int').flatten()
# 正規化
X = scaler.transform(X)
# 予測値の取得
y_pred = model.predict(X.astype(np.float32))
# 可視化
pd.DataFrame(np.c_[y, y_pred.array], columns=["act","pred"]).reset_index(drop=True).plot(figsize=(15,4),ylim=(4000,12000))
予測結果との比較グラフは以下のとおり。
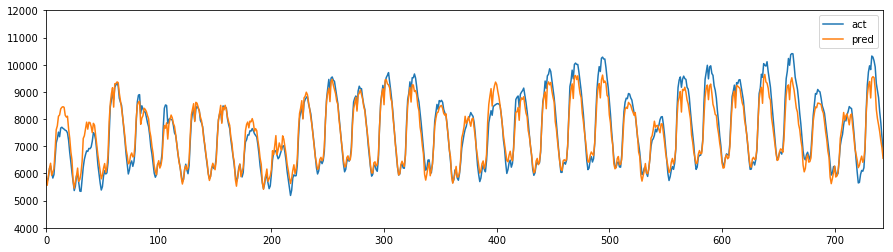
ちなみにTensorFlow版はこちら。
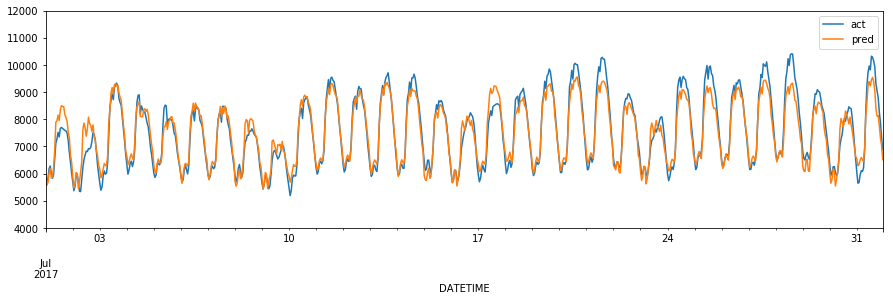
良いかも(^-^)
...学習にかかる時間を計測し、比較してみるともっと良かったかもしれませんね(^_^;)