はじめに
以前、同名のタイトルで投稿してからずいぶんと日数が経過し、少し熟れてきたので再度投稿してみます。
追記
2017/12/22に以下の記事を作成したので、あわせてご参照下さい。
TensorFlowで電力使用量予測 with Keras
データ収集
電力需要
まずは東京電力のサイトから電力需要のデータをダウンロードします。
http://www.tepco.co.jp/forecast/html/images/juyo-2016.csv
※2017/1/14現在、2016/4/1〜2016/12/31の一時間毎のデータをダウンロードできました。
また、URLを変更すると2014年のデータも入手できました。
http://www.tepco.co.jp/forecast/html/images/juyo-2014.csv
※2017/1/14現在、2015年のデータはからっぽでデータが入っていませんでした。
ダウンロードしたデータは日付、時刻、電力実績のCSVとなっています。
ちなみに以下のコマンドで取得することもできそうです。
$ curl -O http://www.tepco.co.jp/forecast/html/images/juyo-2014.csv
$ curl -O http://www.tepco.co.jp/forecast/html/images/juyo-2016.csv
気温
前回同様に、気象庁から過去の気象データをダウンロードします。
地点は「東京」、項目は「時別値」「気温」、期間は2013/12/31〜2015/1/1と2015/12/31〜2017/1/1とし、data-2014.csv、data-2016.csvという名前で保存します。
ここで、少し長めの期間を選択しているのは、後で期間を絞って取り込むためです。
ダウンロードしたデータは日時、気温、品質情報、均質番号というデータの入ったCSVです。
ちなみにこれは普通にサイトからダウンロードするのが早そうです。
データ読込
ライブラリ
import pandas as pd
import numpy as np
import datetime as dt
import math
電力需要
まず、2014年の電力データを読み込みます。
filename = "juyo-2014.csv"
# 文字コードがシフトJISで、不要な行を飛ばして読み込む
df = pd.read_csv(filename,encoding="SHIFT-JIS",skiprows=2)
# 列名を変換
df.columns = ["DATE","TIME","KW"]
# 日付と時間のデータが分かれているので、一つにつなげて日時型に変換し、インデックスに指定
df.index = df.index.map(lambda x: dt.datetime.strptime(df.loc[x].DATE + " " + df.loc[x].TIME,"%Y/%m/%d %H:%M"))
# 月データの取得
df["MONTH"] = df.index.month
# 曜日データの取得
df["WEEK"] = df.index.weekday
# 時間データの取得
df["HOUR"] = df.index.hour
df_kw = df
気温
次に、2014年の気温データを読み込みます。
filename = "data-2014.csv"
# 文字コードがシフトJISで、不要な行を飛ばし、必要な2列のみ取得
df = pd.read_csv(filename,encoding="SHIFT-JIS",skiprows=4)[[0,1]]
# 列名を変換
df.columns = ["DATE","TEMP"]
# 日時データを日時型に変換してインデックスに指定
df.index = df.index.map(lambda x: dt.datetime.strptime(df.loc[x].DATE,"%Y/%m/%d %H:%M:%S"))
df_temp = df
電力需要と気温のデータを結合
d1 = df_kw.index.min()
d2 = df_kw.index.max()
df_kw["TEMP"] = df_temp.ix[d1:d2].TEMP
データの加工
機械学習に用いる入力データと出力データを取得します。
予測するのは電力需要なので、出力はKW列、入力はMONTH、WEEK、HOUR、TEMP列とします。
# 入力に使用するデータ列の指定
X_cols = ["MONTH","WEEK","HOUR","TEMP"]
# 出力に使用するデータ列の指定
y_cols = ["KW"]
# 入力・出力データの取得
X = df_kw[X_cols].as_matrix().astype('float')
y = df_kw[y_cols].as_matrix().astype('int').flatten()
学習データと検証データに分割します。
from sklearn import cross_validation
X_train, X_test, y_train, y_test = cross_validation.train_test_split(X, y, test_size=.1, random_state=42)
入力データを正規化します。
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
学習
回帰モデルで学習します。
from sklearn.ensemble import RandomForestRegressor
model = RandomForestRegressor()
model.fit(X_train, y_train)
予測
分割したテストデータを使ってスコアを計算します。
print(model.score(X_test,y_test))
スコアは「0.91601162513664502」でした(^-^)
予測結果の確認
予測結果と実データをグラフ化し、確認してみます。
# 予測結果
result = model.predict(X_test)
# データフレームに変換
df_result = pd.DataFrame({
"y_test":y_test,
"result":result
})
# グラフライブラリ
%matplotlib inline
import matplotlib
import matplotlib.pyplot as plt
# グラフ描画
df_result.plot(figsize=(15, 3))
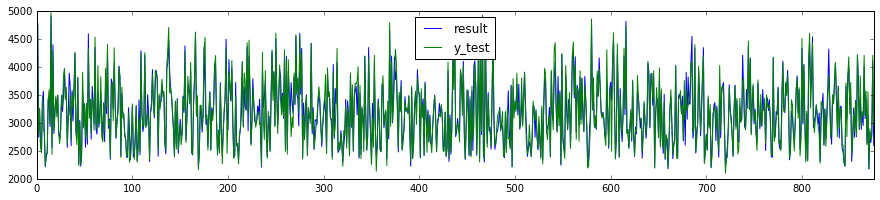
当たってるようなんだけど、どうなのかいまいちよくわからない。
データ数を減らして再確認。
# グラフ描画
df_result[:20].plot(figsize=(15, 3))
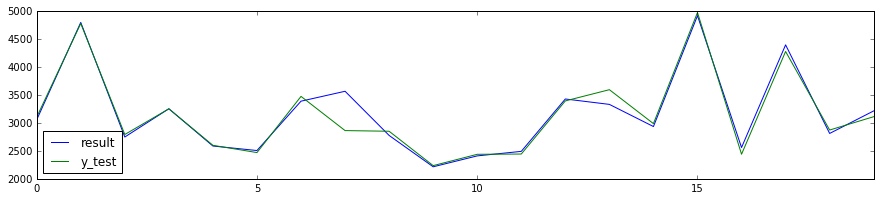
いい感じじゃないですか!
2016年のデータを使って予測
データ読込
2014年のデータと同じ手順で2016年のデータを読み込みます。
# 電力需要
filename = "juyo-2016.csv"
df = pd.read_csv(filename,encoding="SHIFT-JIS",skiprows=2)
df.columns = ["DATE","TIME","KW"]
df.index = df.index.map(lambda x: dt.datetime.strptime(df.loc[x].DATE + " " + df.loc[x].TIME,"%Y/%m/%d %H:%M"))
df["MONTH"] = df.index.month
df["WEEK"] = df.index.weekday
df["HOUR"] = df.index.hour
# 4月分に限定して利用
df_kw = df[df.index.month == 4]
# 気温
filename = "data-2016.csv"
df = pd.read_csv(filename,encoding="SHIFT-JIS",skiprows=4)[[0,1]]
df.columns = ["DATE","TEMP"]
df.index = df.index.map(lambda x: dt.datetime.strptime(df.loc[x].DATE,"%Y/%m/%d %H:%M:%S"))
df_temp = df
# データ結合
d1 = df_kw.index.min()
d2 = df_kw.index.max()
df_kw["TEMP"] = df_temp.ix[d1:d2].TEMP
データ加工
# 入力・出力データの取得
X = df_kw[X_cols].as_matrix().astype('float')
y = df_kw[y_cols].as_matrix().astype('int').flatten()
X_test = scaler.transform(X)
y_test = y
予測
2014年のデータで学習したモデルを使用して予測し、スコアを計算します。
model.score(X_test,y_test)
結果は、少し落ちて「0.82435418225963963」でした。
予測結果の確認
# 予測結果
result = model.predict(X_test)
# データフレームに変換
df_result = pd.DataFrame({
"y_test":y_test,
"result":result
})
# グラフ描画
df_result.plot(figsize=(15, 3))
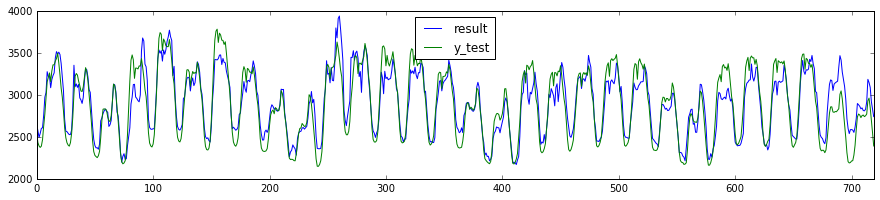
もう少し工夫が必要ですね(-_-;)