前回のあらすじ
ちょっとした出来心で始めた株。しかし、新型コロナウイルス感染症が流行するなんて想像もしておらず、ご多分から漏れることなく投資に失敗し、マイホーム購入のためにこれまで一生懸命貯めた貯金がすっからかんになり、自暴自棄になって宍道湖大橋をトボトボと歩いていたら、後ろから「久しぶり。元気か?!」と声をかけられ...
...というのは冗談で、写真から対象を抽出するというテーマの取り組みについて記事の続きを書きます!
ベランダの写真から植物が写っている部分を抽出するために深層学習を使ってみようと思ったらうまくいかなったので、試行錯誤してみた内容をまとめてみる。前編
検討
前編の後、パラメータをいくつか変えてみるも全く効果なく、虚しい時間が流れるばかり...
そんな中、ふと思いついたのが「転移学習」。
学習済モデルの出力を使って、少ないデータから高精度の識別を実現する手法とのこと...
やり方は全然わかんないけど、とりあえずにわか知識で試してみることに!
学習
前編と同じデータを読み込んで、学習済モデルに識別させて、その結果を入力としてニューラルネットワークに学習させてみる。
from glob import glob
import random
X = []
y = []
dirs = ["9*/*.jpg", "0*/*.jpg"]
i = 0
min = 1500
for d in dirs:
files = glob(d)
files = random.sample(files, min if len(files) > min else len(files))
for f in files:
X.append(f)
y.append(i)
i += 1
import pandas as pd
df = pd.DataFrame({"X" : X, "y" : y})
from keras.applications.vgg16 import VGG16, preprocess_input, decode_predictions
# VGG16の学習済モデルを取得
model_VGG16 = VGG16()
import cv2
import numpy as np
from keras.preprocessing import image
X = []
y = []
cnt = 0
for idx in df.index:
f = df.loc[idx, "X"]
l = df.loc[idx, "y"]
print("\r{:05} : [{}] {}".format(cnt, l, f), end="")
i += 1
# 画像の読込
img = image.load_img(f, target_size=model_VGG16.input_shape[1:3])
X.append(image.img_to_array(img))
y.append(l)
cnt += 1
print()
# 前処理
X = np.array(X)
X = preprocess_input(X)
# VGG16による識別
preds = model_VGG16.predict(X)
print('preds.shape: {}'.format(preds.shape)) # preds.shape: (1, 1000)
# 識別結果を入力に設定
X = preds
from sklearn import model_selection
test_size = 0.2
# 学習、検証、テスト用に分割
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=test_size, random_state=42)
X_valid, X_test, y_valid, y_test = model_selection.train_test_split(X_test, y_test, test_size=.5, random_state=42)
from keras.utils.np_utils import to_categorical
y_train = to_categorical(y_train)
y_valid = to_categorical(y_valid)
y_test = to_categorical(y_test)
from keras.layers import Dense
from keras.models import Sequential
# 学習モデルの作成
model = Sequential()
model.add(Dense(64, input_dim=len(X_train[0]), activation='relu'))
model.add(Dense(64, activation='sigmoid'))
model.add(Dense(len(y_train[0]), activation='softmax'))
# コンパイル
model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])
# 学習
history = model.fit(
X_train, y_train, batch_size=25, epochs=60,
verbose=1, shuffle=True,
validation_data=(X_valid, y_valid))
import matplotlib.pyplot as plt
# 汎化制度の評価・表示
score = model.evaluate(X_test, y_test, batch_size=32, verbose=0)
print('validation loss:{0[0]}\nvalidation accuracy:{0[1]}'.format(score))
#acc, val_accのプロット
plt.plot(history.history["accuracy"], label="acc", ls="-", marker="o")
plt.plot(history.history["val_accuracy"], label="val_acc", ls="-", marker="x")
plt.ylabel("accuracy")
plt.xlabel("epoch")
plt.legend(loc="best")
plt.show()
#loss, val_lossのプロット
plt.plot(history.history["loss"], label="loss", ls="-", marker="o")
plt.plot(history.history["val_loss"], label="val_loss", ls="-", marker="x")
plt.ylabel("loss")
plt.xlabel("epoch")
plt.legend(loc="best")
plt.show()
実行!!
validation loss:0.0818712607031756
validation accuracy:0.9797570705413818
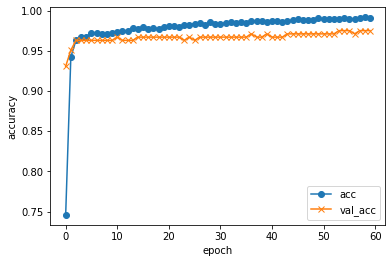
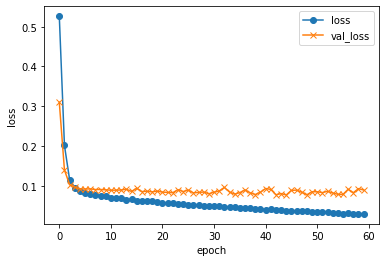
おぉっ!
なんだこれ?!
識別とマーキング
import cv2
import numpy as np
div = 10
cl = (0, 0, 255)
i = 0
# テスト画像一覧の取得
testFiles = glob("test/*.JPG")
testFiles.sort()
for f in testFiles:
print(f.split("/")[-1])
# ファイルの読込
img = cv2.imread(f)
img_output = cv2.imread(f)
#print(img.shape)
h, w, c = img.shape
print(f, h, w, c)
# 短辺の取得と分割サイズの設定
size = h if h < w else w
size = int(size / 10)
print(size)
i = 0
k = 0
while size * (i + 1) < h:
j = 0
while size * (j + 1) < w:
# 分割画像の取得
img_x = img[size*i:size*(i+1), size*j:size*(j+1)]
# VGG16による識別
img_test = cv2.resize(img_x, model_VGG16.input_shape[1:3])
img_test = cv2.cvtColor(img_test, cv2.COLOR_BGR2RGB)
X = np.array([img_test])
X = preprocess_input(X)
preds = model_VGG16.predict(X)
# 識別
pred = model.predict(preds, batch_size=32)
m = np.argmax(pred[0])
# 精度が85%以上で植物と識別された場合
if pred[0][m] > 0.85 and m == 1:
# 植物と識別された場所に赤い四角を描画
cv2.rectangle(img_output, (size*j + 5, size*i + 5), (size*(j+1) - 5, size*(i+1) - 5), cl, thickness=2)
j += 1
k += 1
i += 1
img_output = img_output[0:size*i, 0:size*j]
f_new = "predicted/{}".format(f.split("/")[-1])
cv2.imwrite(f_new, img_output)
print()
実行!!



完璧!!
転移学習ってすごい!...って本来の意味での転移学習とは違ってるかもしれないけど。汗
ちなみに手作業でマーキングしたりしてないですからね〜。笑
さて、次は何をするかな〜。