Amazon Bedrock Knowledge base と Agent
自社で開発・運用している動画配信サービス「hod」のデータを使って、番組情報を教えてもらうチャットボットを構築してみます
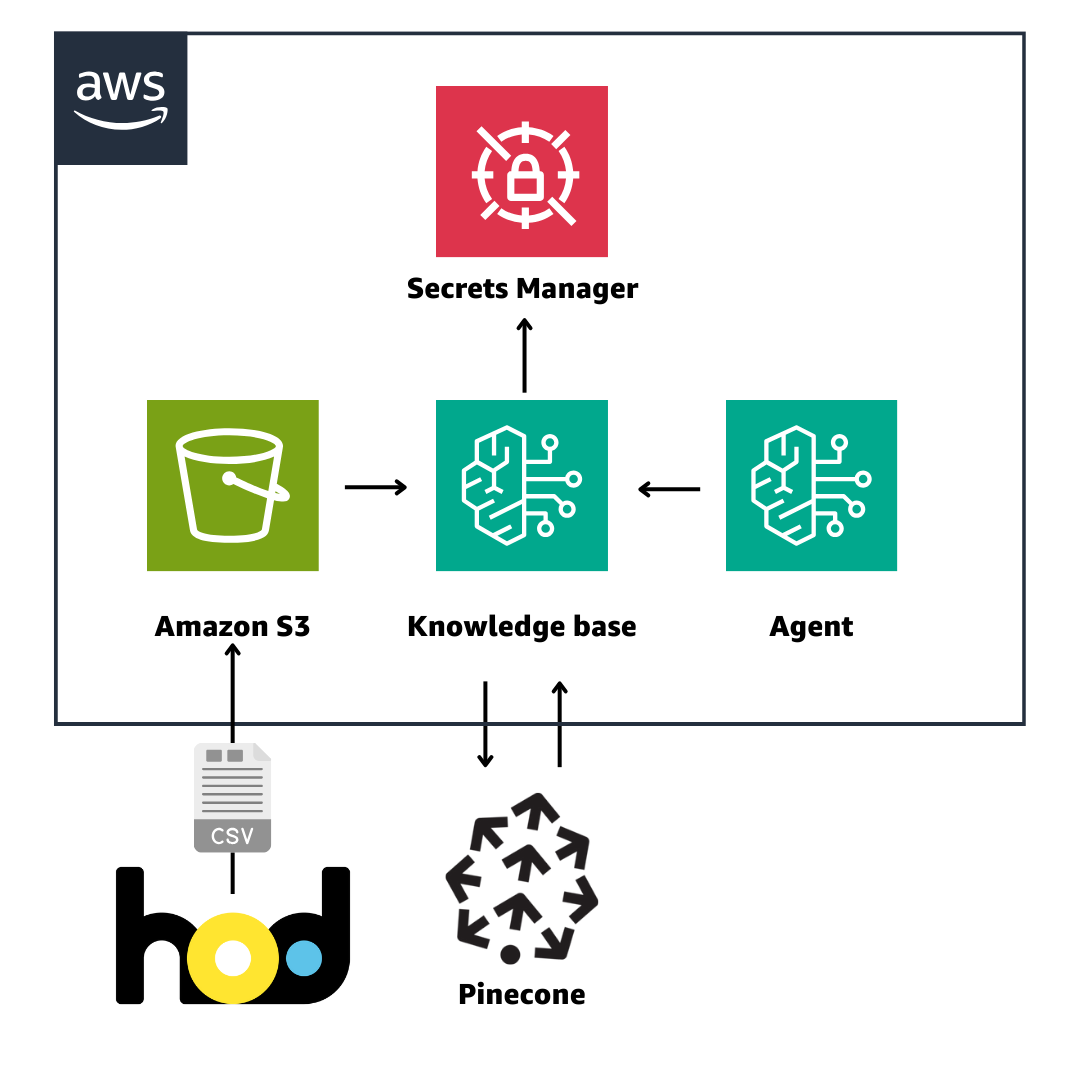
Amazon Bedrock の新機能としてGAした Knowledge Base と Agent を使っていきます。
使用する追加データとしては、HTBが開発・運用している動画配信サービス「hod」の番組マスタデータの一部をcsvにしたものを使ってみたいと思います。
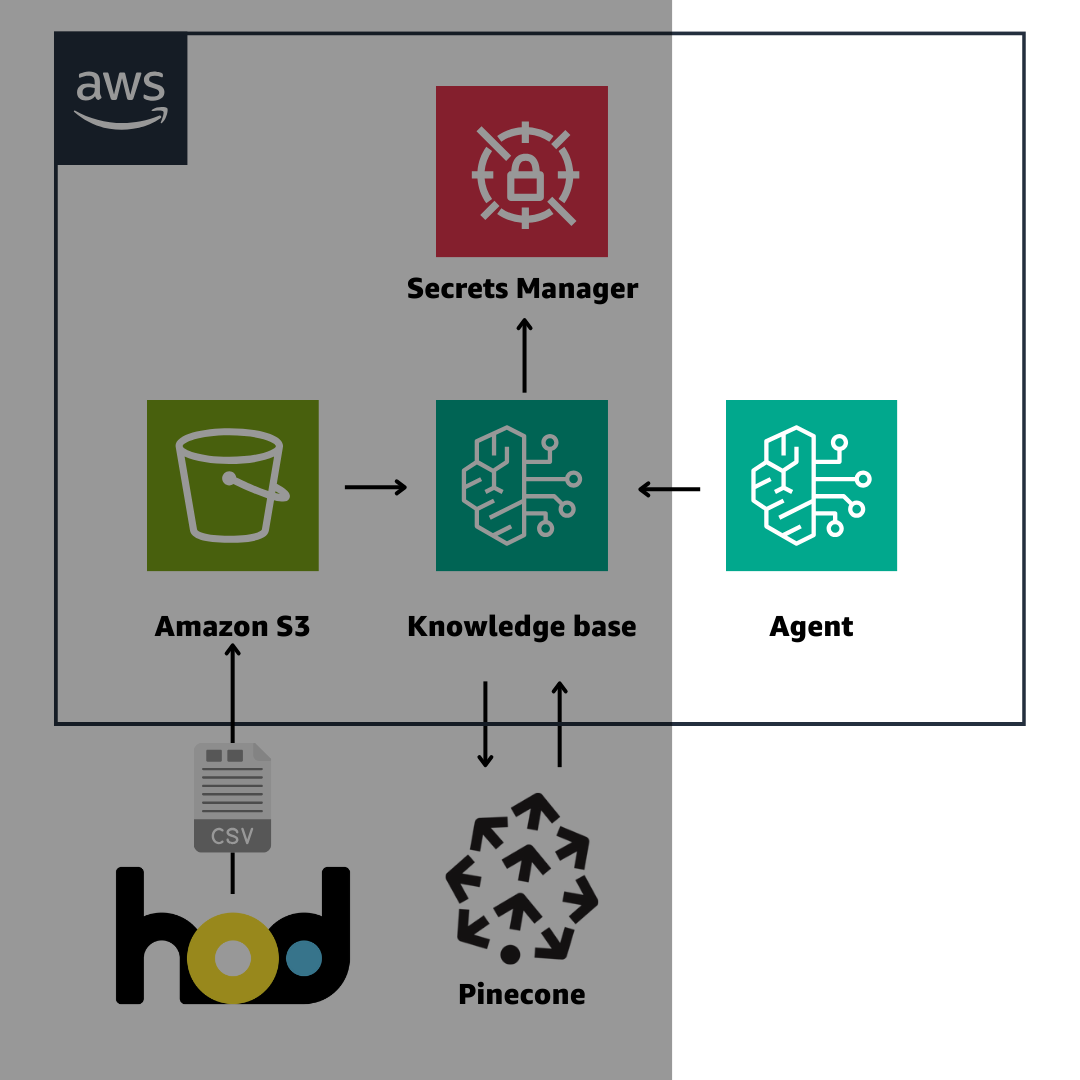
(Bedrock の周辺機能をアーキテクチャ図に落とし込むときどうもしっくりこない。。笑)
Vector Store として Pinecone を採用して、Knowledge base で RAG を構築する
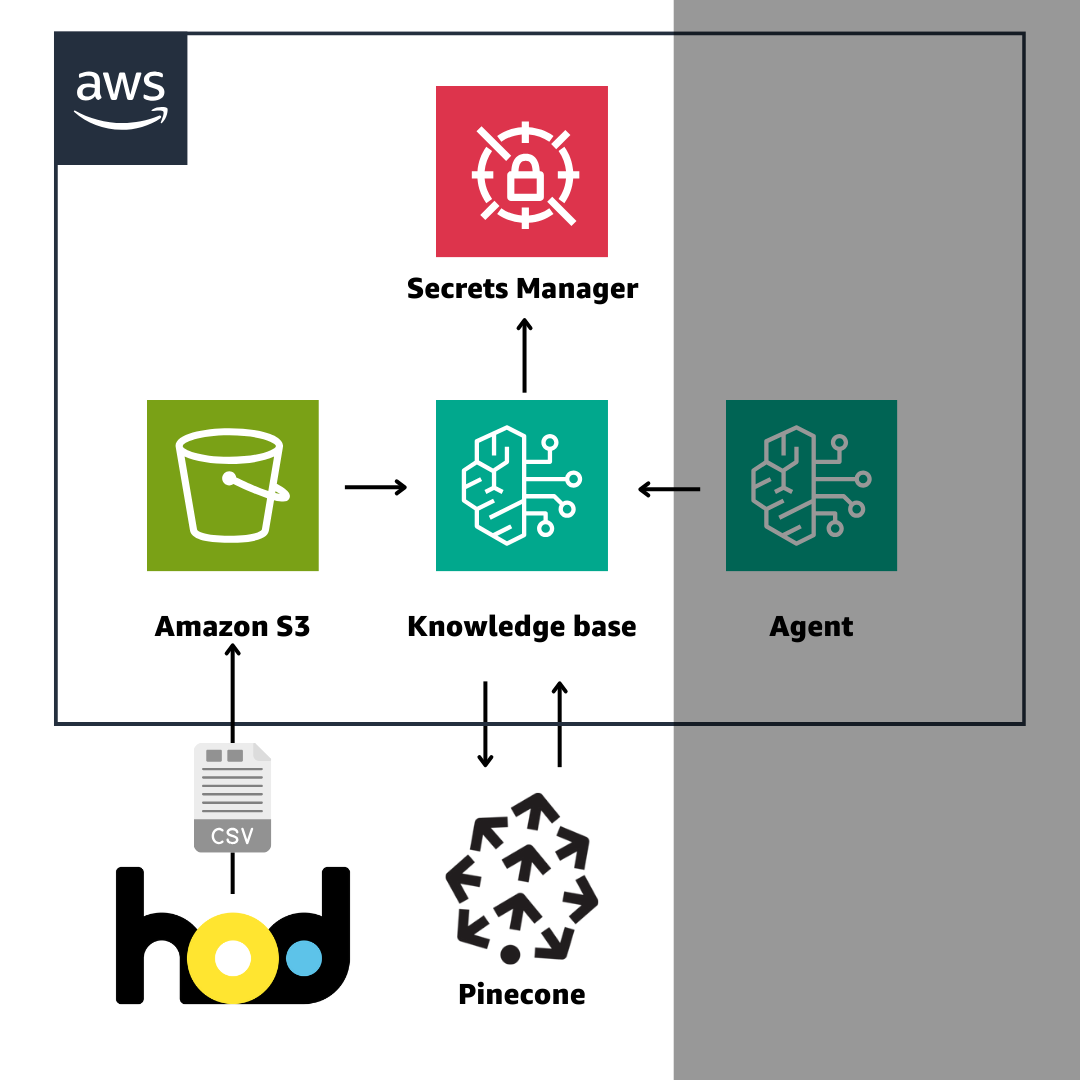
Knowledge base は S3 にあるデータを Vector Store に格納して
RAG(Retrieval-Augmented Generation)を簡単に実現するサービスです
Vector Store としては、デフォルトで OpenSearch あたりが使われますがが、外部サービスを指定することも可能です。
OpenSearch は私にはちょっと難しくて扱いきれないので、
今回は無料で始めることができる Pinecone を使ってみたいと思います。
(re:Invent の EXPO にも出展されていましたね。)
そして、その手順について、Pinecone のブログが見つかりましたので、これに習って進めていきたいと思います。
Pinecone の準備
アカウントを作成すると、クレジットカードの登録なしで、Starter Plan から、Vector Store を使用することができます。
まずは、セットアップを終わらせて、
Indexを作成していきます。
その際、Dimensions を指定する必要があるのですが、1536 とします。
後に S3 においた CSVデータを Bedrcok が ここにVectorデータとして格納してくれるのですが
この時使用することになる Amazon Titan Embeddings G1 - Text v1.2 がアウトプットする Vector の Dimensions が 1536 であるため、これに合わせます。Metric は cosine を指定します。
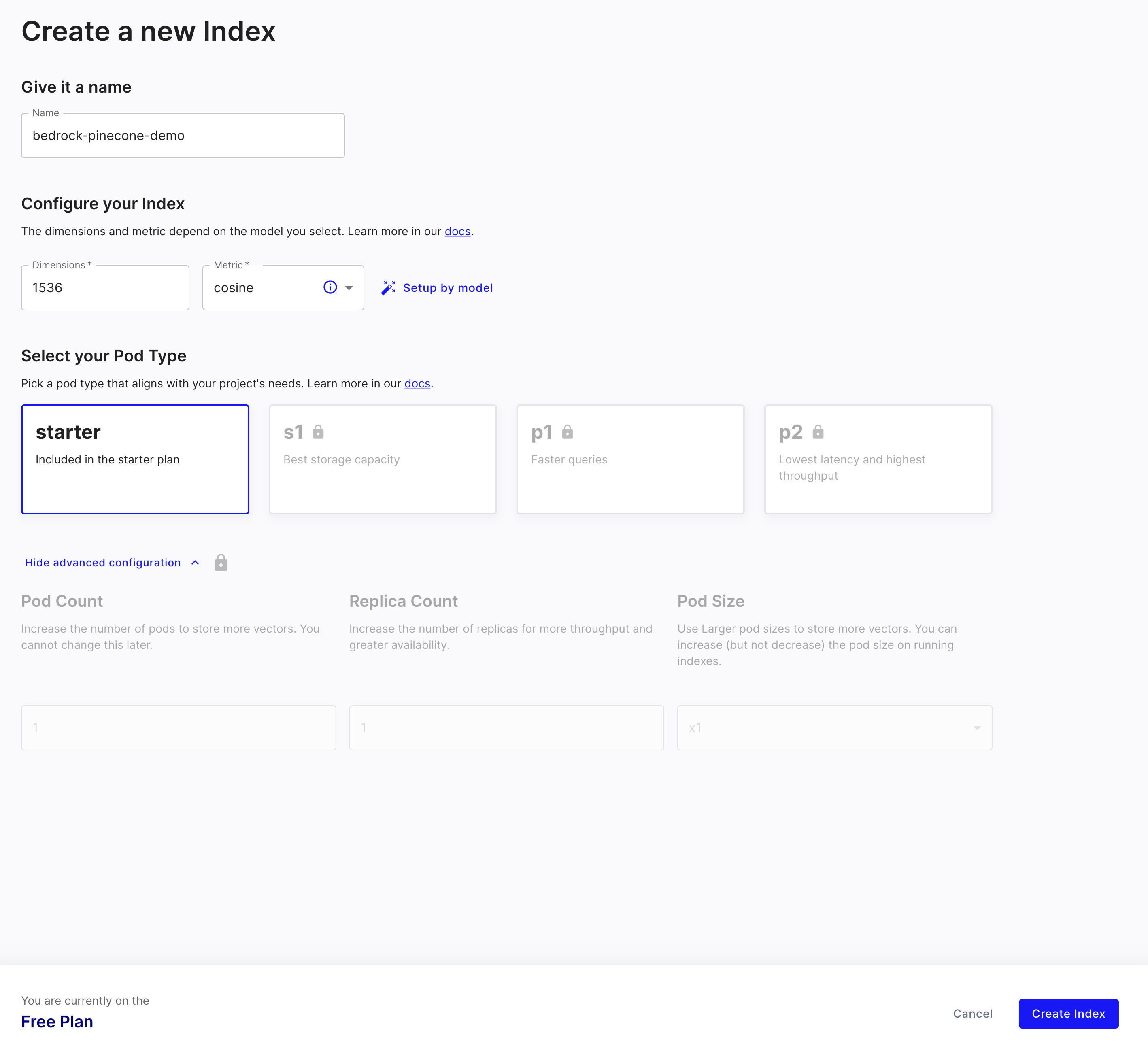
Free Plan なのを確認して Index を作成します。
しばらくすると、出来上がります。以下の情報を Bedrcok 側に渡す必要があるので、確認しておきます
- Index の HOST のアドレス(https://〜)
- API Keys の Value (default のものをそのまま使います)
Bedrock の準備
AWS コンソールから Bedrock の Knowledge base を作成します。
左側メニューの Orchestration のなかに入っています。
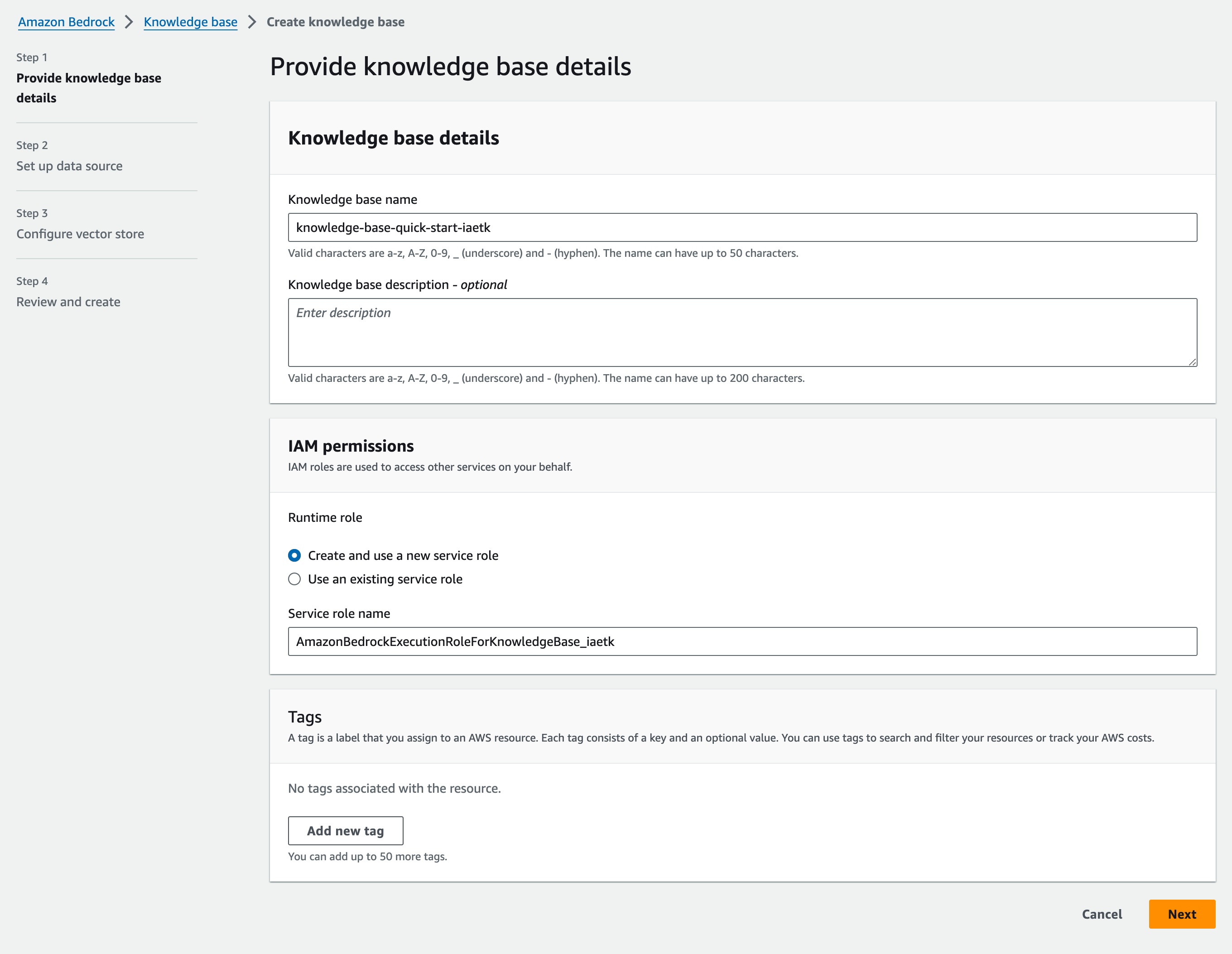
Step 1: Provide details
名前を適当につけつつ、IAM も新しく作成して次へ
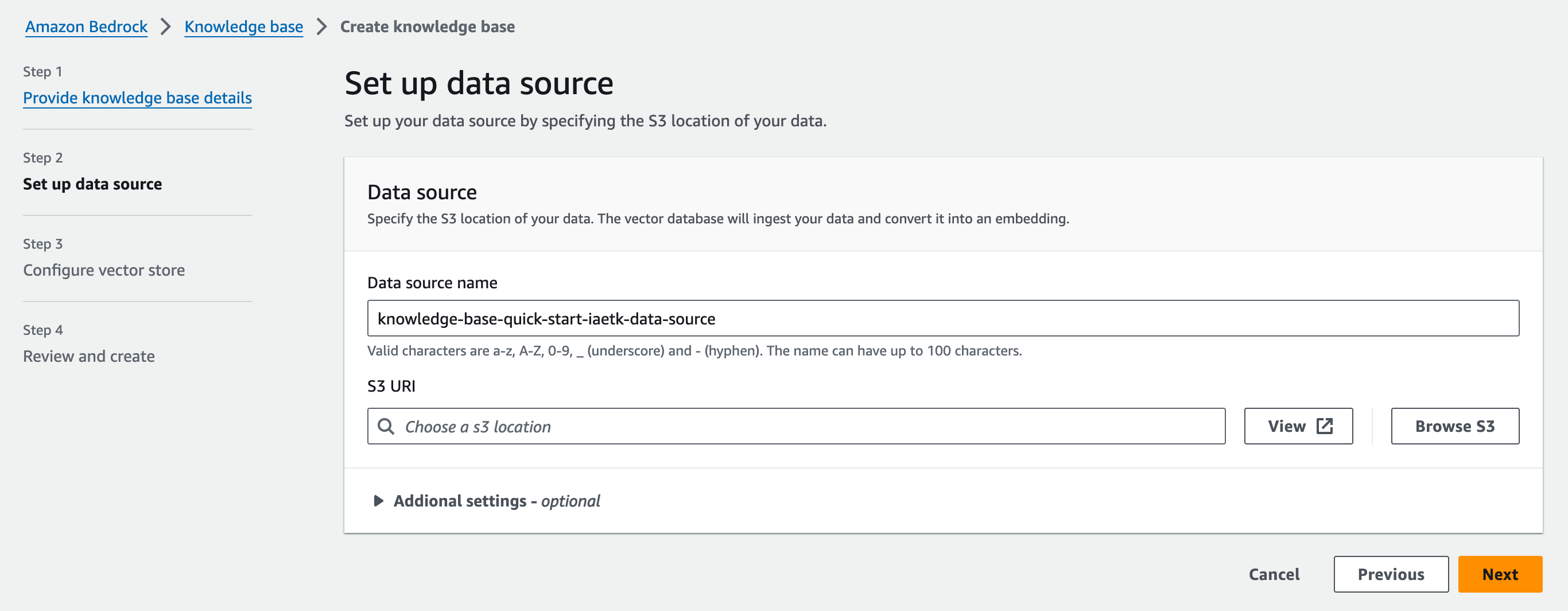
Step 2: Set up data source
同じリージョンの S3 Bucket を選択します。
(手順省略)
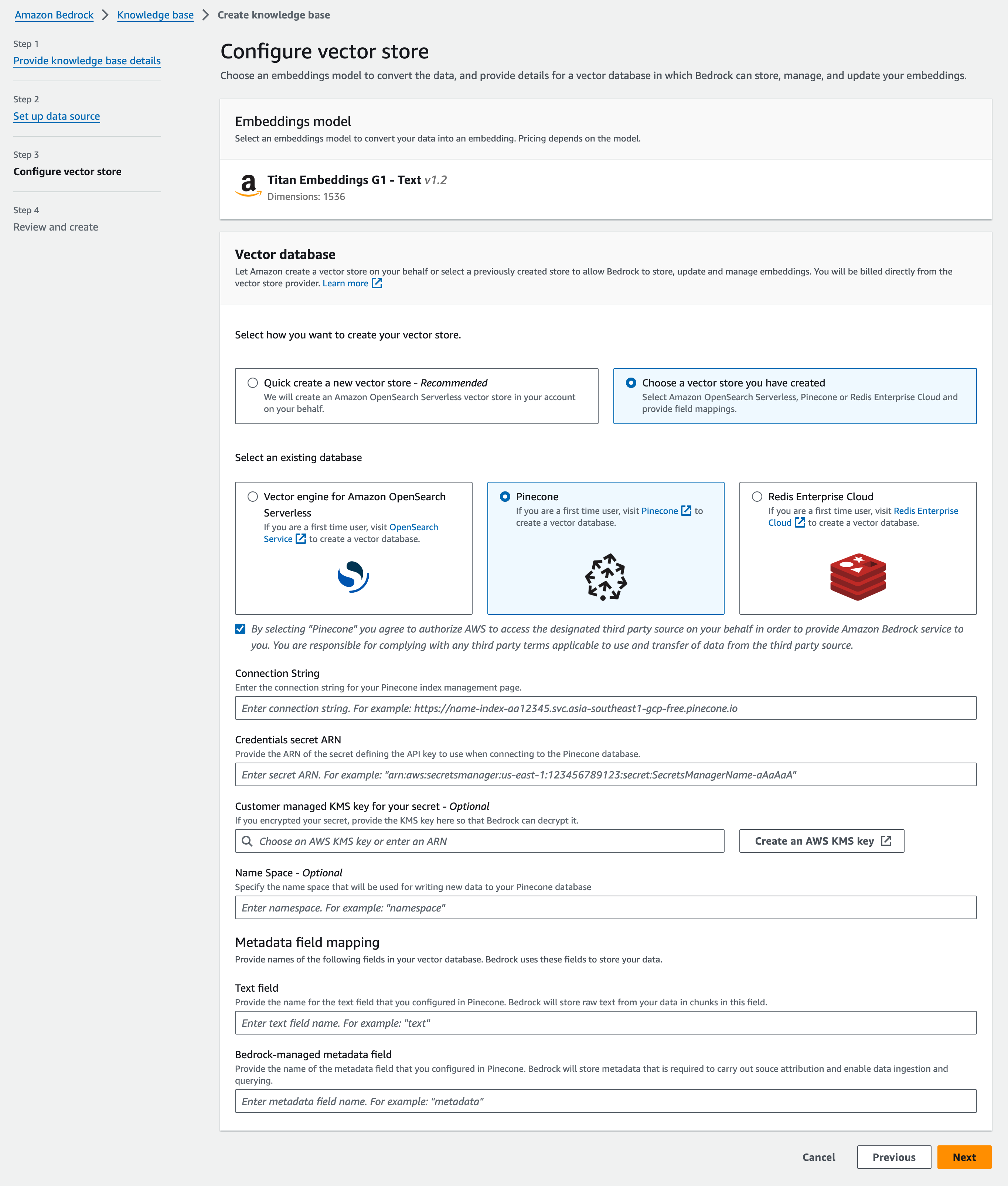
Step 3: Configure vector store
Embeddings Model として、先述したAmazon Titan Embeddings G1 - Text v1.2が出てきました。
別のVector Store を選択して、Pinecone を選択します。
(この時、下の同意ボタンのチェックを入れる必要があります)
Pinecone の Index の HOST の URL を Connection String に入力。
API Key は Secrets Manager に格納して、そのARN を入力します(手順省略)
Text は番組データが入るので、program-info
Metadata はそのまま metadataを入力してみます
Step 4: Review and create
作成します。しばらく待ちます。
指定した、S3 Bucket に Vector 化したいデータを入れます。
今回は2000件ほど入っているhodの番組メタデータをCSVにしたものを特に掃除をすることもなくそのまま入れてみます。
S3にCSVをアップロードできたら、Data source の Sync ボタンをクリックします。

Syncing がクルクルして、しばらく時間がかかります。
この時 Amazon Titan Embeddings G1 - Text v1.2 が csvを Vector にして Pinecone に格納してくれているはずです。
Status が Ready になったら完了です
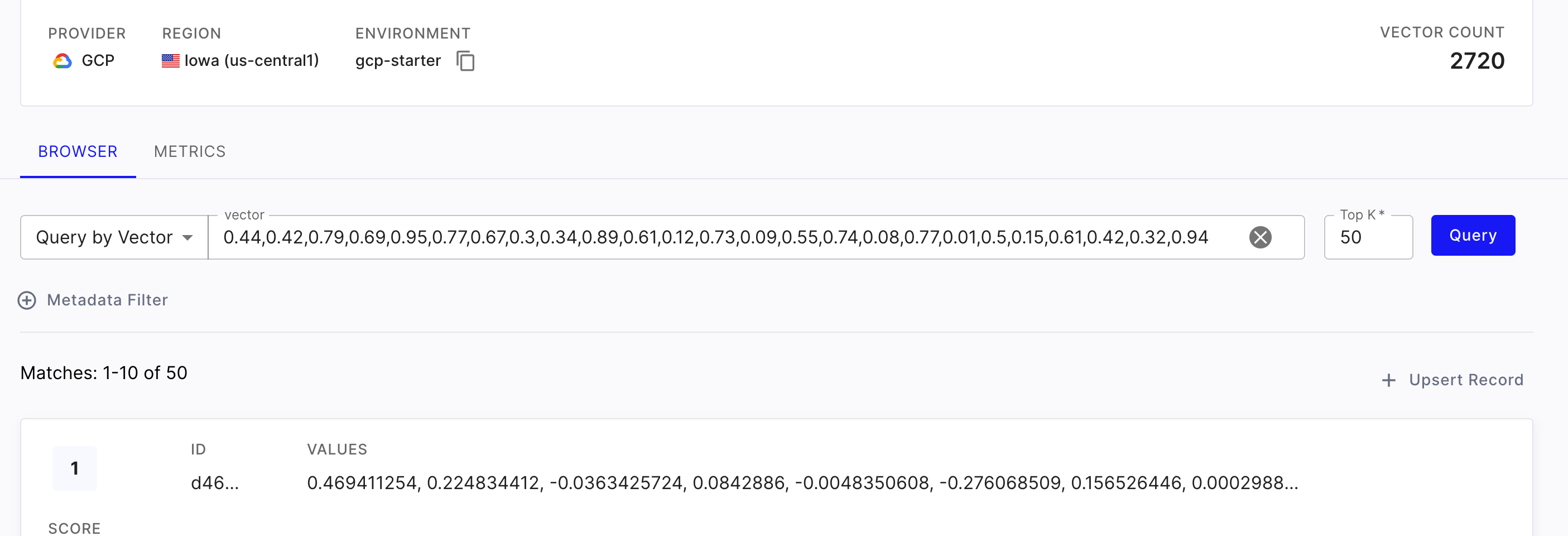
Pinecone 側で確認
Pinecone 側にちゃんとデータが入っていそうです!
Knowledge base まとめ
これで、準備完了です。
S3データおいて、ぽちぽちするだけで、Vector Store に自社のデータを置くことができちゃいました!
Bedrock すごい。Pinecone すごい。
Agent for Amazon Bedrock
Agent の構築
次に、Agent から、今回作成した Knowledge base を使用してみましょう
Step 1: Provide Agent detail
名前を入力して、その他は、そのまま次へ
Step 2: Select model
モデルを選択します。
Anthropic の Cloude V2 を尽かします。
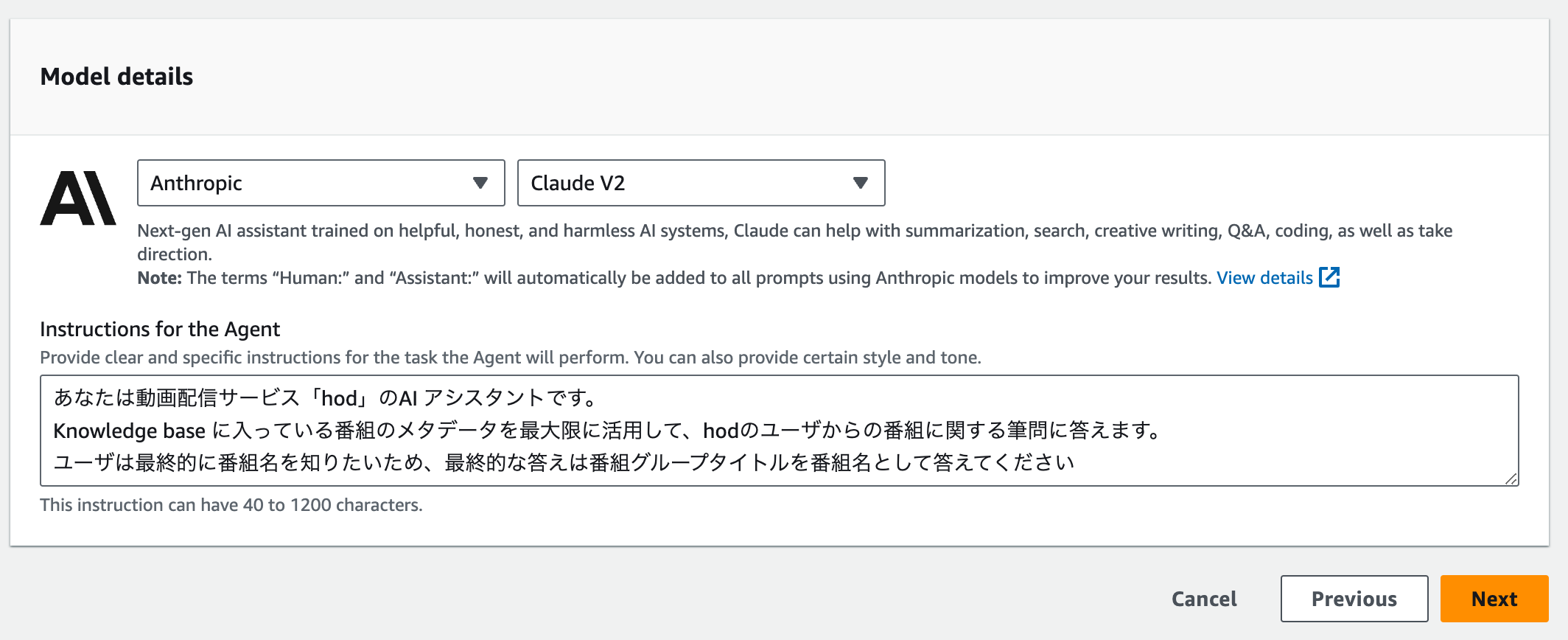
エージェントへの指示を記入します。
あなたは動画配信サービス「hod」のAI アシスタントです。
Knowledge base に入っている番組のメタデータを最大限に活用して、hodのユーザからの番組に関する筆問に答えます。
ユーザは最終的に番組名を知りたいため、最終的な答えは番組グループタイトルを番組名として答えてください
Step 3: Add Action groups
オプションなので飛ばします
Step 4: Add Knowledge base
先ほど作成した Knowledge base を選択して、Agentに対しての説明を入力します。
どんな感じで描くと良いのかは、ちゃんとわかっていませんが、データの説明を簡単にしてみました。
動画配信サービスhodで配信している番組情報が入っています。出演者や概要説明から、どんな番組なのかを知ることができます
Step 5: Review and create
確認して次へ。
動作確認
これで、作成すると、テキストチャットが試せるようになります。
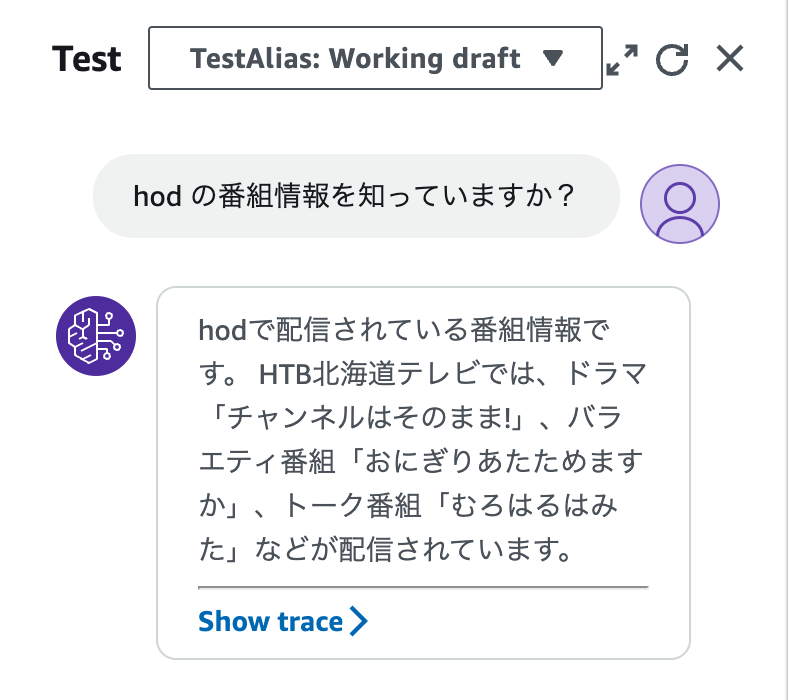
番組内容についても聞いてみます
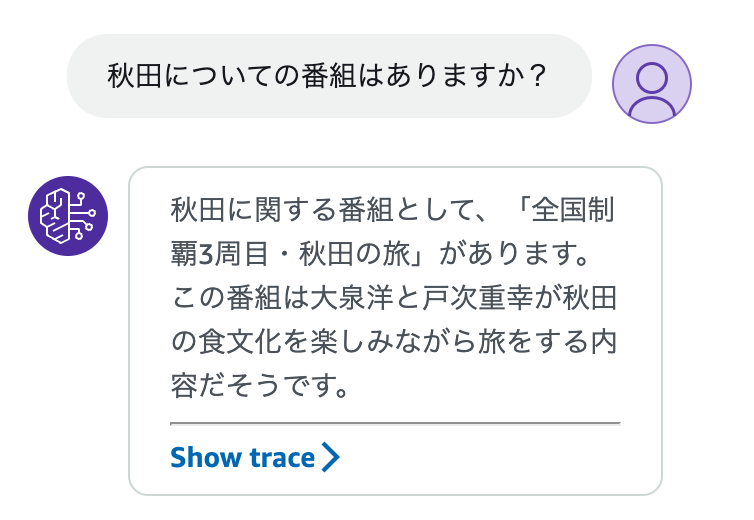
いい感じ
まとめ
ということで、Amazon Bedrock の Knowledge base と Agent を使って、RAG を試してみました。
本当に簡単に実装できてびっくりです。
動画配信サービスでの、検索機能はメタデータが大きいので、なかなか最適な状態で提供するのが難しくて悩んでいるのですが、
このような形での提供はありかもしれません。
サービスの昨日として追加するのはまだハードルがありそうでが、試してみるまでのハードルがこんなに低いとはびっくりです
リリースできるように検討してみたいと思います。
以上