こんにちは。
昨日は線形回帰の代表的なモデルである通常最小二乗法(OLS)について述べました。
今回はRidge回帰とLasso回帰について書こうと思います。
準備
線形モデルによる回帰とは文字通り、線形関数を用いて目的変数を予測するものです。
そして目的変数は以下の式で表せるのでした。
y' = w_1x_1 + w_2x_2 + \dots + w_mx_m (x_1, x_2, \dots, x_m:説明変数, y': 予測値, w_1,w_2, \dots, w_m : 回帰係数)
切片も加えた形で書くと、
y' = w_0x_0 + w_1x_1 + w_2x_2 + \dots + w_mx_m (w_0, 切片: x_0 = 1)
ベクトルで書くと、
y' = {\bf x^T}{\bf w}
xのベクトル(説明変数)は一つだけ時とは限らないので、xは行列の形になります。
つまり、
\left(
\begin{array}{cccc}
y_{1} \\
y_{2} \\
y_{3} \\
\vdots \\
y_{n}
\end{array}
\right)
= \left(
\begin{array}{cccc}
1 & x_{11} & x_{21} & \ldots & x_{m1} \\
1 & x_{12} & x_{22} & \ldots & x_{m2} \\
\vdots & \vdots & \vdots & \ddots & \vdots \\
1 & x_{1n} & x_{2n} & \ldots & x_{mn}
\end{array}
\right)
\left(
\begin{array}{cccc}
w_{1} \\
w_{2} \\
w_{3} \\
\vdots \\
w_{m}
\end{array}
\right)
\\
y = {\bf Xw} \dots (1)
最小二乗法
L = \sum_{i=1}^{n}(y_i - y'_i)^2
この損失(誤差)関数Lを最小化させるようにパラメータを決定する。
細かい説明は省きますが、この式を変形と(1)の式を使うと
L = (y - {\bf Xw})^{T}(y - {\bf Xw})
と書ける。
これが最小二乗法です。
しかしこの式ならば、wのパラメータが大きくなる事で、過学習を起こしやすくなります。
このLに正規化項を加えたものが下記で説明するRidgeとLasso回帰です。
式で書くと
L = (y - {\bf Xw})^{T}(y - {\bf Xw}) + a \times (L_pノルム)
aはハイパラメータと呼ばれ、正規化の強さをコントロールするためのスカラです。
つまり、大きければ大きいほど正規化を強くすることが出来ます。けど強すぎると適合不足を起こすので注意は必要です。
ここで
L1ノルムの場合は、Lasso回帰
L2ノルムの場合は、Ridge回帰です。
ほう、面白いですな。
L1ノルムとL2ノルムについては,こちらで
簡単にいうと
L1ノルムはマンハッタン距離と呼ばれ、ベクトル成分同士の差の絶対値の和となる。
L2ノルムはユークリッド距離と呼ばれ、ベクトル成分同士の差の2乗和の平方根となる。
Ridge(リッジ)回帰
リッジ回帰は線形モデルによる回帰の1つです。
リッジ回帰は上記でも述べたの通り、正規化が平方根であるため、パラメータwの各成分を全体的に滑らかにする事ができる。
理由は、
ルートの中では、大きい数字を0に近づける方が最小化されやすいから。
数式で書くならば、
L = (y - {\bf Xw})^{T}(y - {\bf Xw}) + a ||{\bf w}||_2^2
Lasso(ラッソ)回帰
ラッソ回帰も線形モデルによる回帰の一つ。
ラッソ回帰の正則化項の部分は単なる絶対値の和であるため、いくつかの変数は0になる事が多い。
数式で書くならば、
L = \frac{1}{2}(y - {\bf Xw})^{T}(y - {\bf Xw}) + a ||{\bf w}||_1
まとめ
数学って、本当に難しいですよね。僕も所々?があります。
でも一番伝えたい所は、
ラッソ回帰とリッジ回帰の違いはL1ノルムとL2ノルムの違いである事です。
L1ノルムとL2ノルムを押さえれば、それぞれの回帰の特徴が見えてくると思います。
まだまだ勉強不足ですが、頑張ります・・・。
追記(サンプルコード)
from sklearn.linear_model import Ridge
from sklearn.linear_model import Lasso
from sklearn.model_selection import train_test_split
import mglearn
import numpy as np
import matplotlib.pyplot as plt
X, y = mglearn.datasets.make_wave(n_samples=40)
x_for_graph = np.linspace(-3, 3, 100)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
ridge = Ridge().fit(X_train, y_train)
lasso = Lasso().fit(X_train, y_train)
fig, ax = plt.subplots()
ax.scatter(X_train, y_train, marker='o')
ax.plot(x_for_graph, ridge.coef_ * x_for_graph + ridge.intercept_, label='Ridge')
ax.plot(x_for_graph, lasso.coef_ * x_for_graph + lasso.intercept_, label='Lasso')
ax.legend(loc='best')
print("Training set score for Ridge: {:.2f}".format(ridge.score(X_train, y_train)))
print("test set score: {:.2f}".format(ridge.score(X_test, y_test)))
print("Training set score for Lasso: {:.2f}".format(lasso.score(X_train, y_train)))
print("test set score: {:.2f}".format(lasso.score(X_test, y_test)))
plt.show()
結果
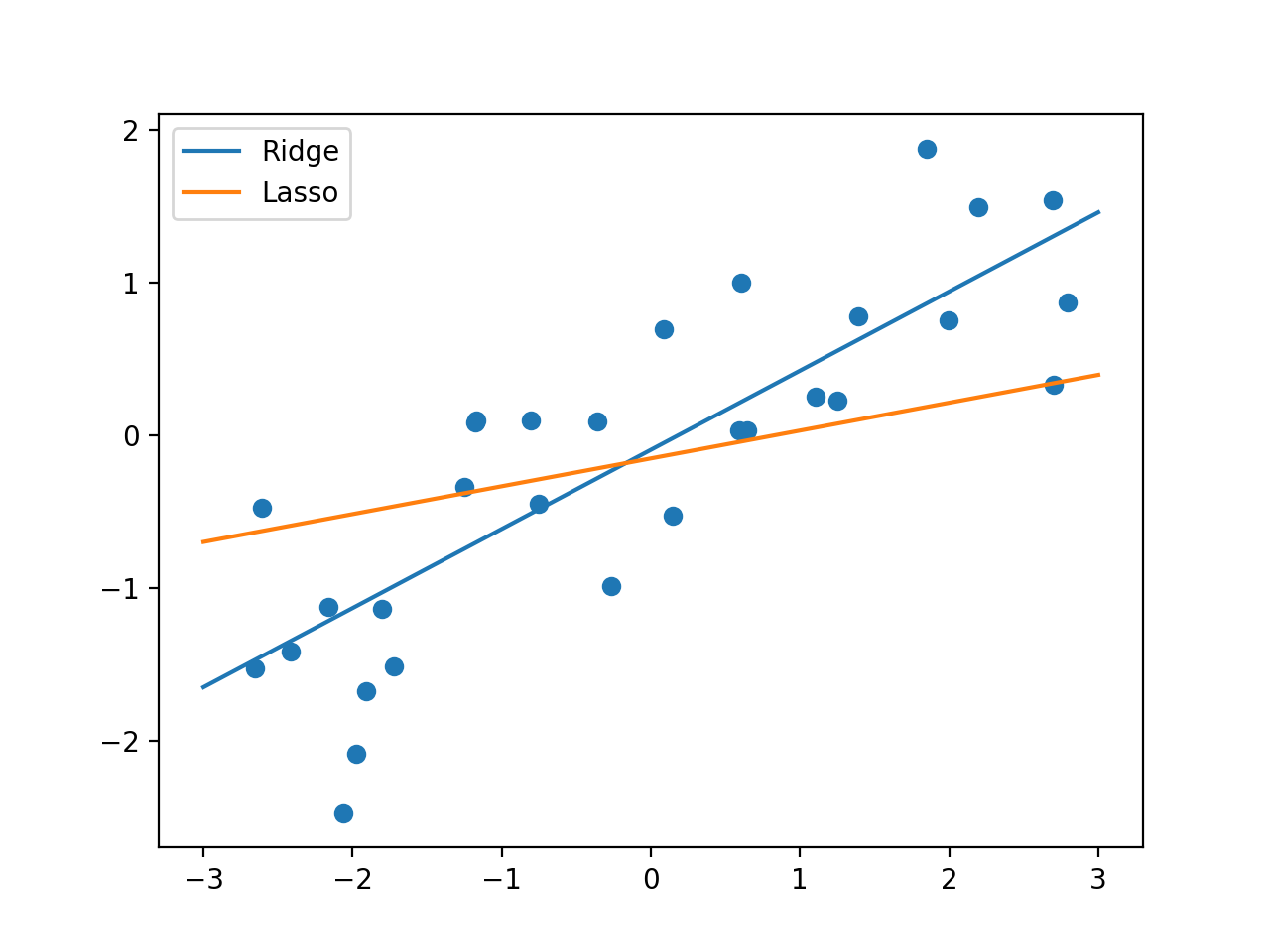
Training set score for Ridge: 0.69
test set score: 0.64
Training set score for Lasso: 0.40
test set score: 0.55
データの変数が少なすぎますね。。。笑