この記事は言語実装 Advent Calendar 2020 3日目の記事です。前回は sisshiki1969 さんの「ruruby: RustでつくっているRuby」、次回は yharaさんの「Shiika進捗」です。
趣旨
LLVM を使って小さな言語を実装してみます。
方針としては、最小限の機能の言語から出発して動くものを少しづつ大きくしていきます。ゴールは LLVM 公式のチュートリアルである Kaleidoscope の序盤相当の部分で、次のプログラムが動くことを目標とします。
def fib(n)
if n < 3
then 1
else fib(n-1) + fib(n-2);
fib(10) #=> 55
想定する読者
- LLVM や LLVM IR がどういうものか何となく知っている
- Haskell がなんとなく分かる
ただしコードにはコメントを入れて、LLVM IR や Haskell に慣れていない方でも意味がつかめるようにしたいと思います。
環境
- LLVM 9.0
- stack 2.5.1
ubuntu 20.04 で動作を確認しています。
ステップ1: 整数1個を返す
まずは与えられた整数を1個返すだけ、という小さすぎる言語から始めます。
なお、このスタイルは植山類さんの「低レイヤを知りたい人のためのCコンパイラ作成入門」https://www.sigbus.info/compilerbook そのものです。このやり方はとても分かりやすいので、LLVM を理解するためにこのスタイルでやってみたいと思ったのがそもそもの動機です。
今回育てていく言語に nanoscope という名前をつけることにします。いまの時点での機能はこうです。
「ソースコードとして整数の文字列を与えると、それを終了コードとして返す」
まずはターゲットである LLVM IR の実例をみてみましょう。たとえば42を終了コードとするプログラムの LLVM IR は次のとおりです。
define i32 @main() { ;; mainは32ビット整数を返す関数であり
ret i32 42 ;; その本体では32ビット整数として 42 を返す
}
LLVM IR はアセンブリっぽくはあるのですがなかなか高級で、関数の概念があります。 define で32ビット整数を返す関数 main を定義し、その本体では ret で 42 を返しています。上の 42 の部分を入力に応じて変えたものさえ出力できれば、それで nanoscope コンパイラーのできあがりです。(正確には nanoscope から LLVM IR へのコンパイラーです)
では最初のコンパイラーを作りましょう。
module Main where
main = do
-- 標準入力から1行を読んで n に入れる
n <- getContents
-- 上記の 42.ll の ret 部分に n を差し込んだものを表示する
putStrLn $ "define i32 @main() {\n ret i32 " ++ n ++ "\n}"
いろいろ書いてありますが、Haskell をふだん使われない方でもコメントを見ていただければ雰囲気は分かると思います。標準入力に与えられた文字を ret i32 の次に埋め込んでいます。
これに入力として 42 を与えて実行し、結果を lli に渡してみましょう。lli は LLVM ツール群の1つで、LLVM IR を解釈して実行するものです。
% echo 42 | runghc nano.hs | lli
% echo $?
42
echo $? は前のプロセスの終了コードを表示します。たしかに 42 です。最初のコンパイラーができました。
ステップ2: llvm-hs-pure を使って書き直す
この先、nanoscope を大きくしていくわけですが、いまのように文字列を直接つなげる方式のコード生成はいつか破綻します。もうちょっと構造化した方式に変えておきましょう。そのためのライブラリーとして llvm-hs-pure というものがありますので、それで置き換えてみます。
{-# LANGUAGE OverloadedStrings #-}
module Main where
import Data.Text.Internal.Lazy
import Data.Functor.Identity
import qualified Data.Text.IO as T
import qualified Data.Text.Lazy.IO as LT
import LLVM.Pretty
import LLVM.AST hiding (function, value)
import LLVM.AST.Type as AST
import LLVM.IRBuilder.Module
import LLVM.IRBuilder.Monad
import LLVM.IRBuilder.Instruction
import LLVM.IRBuilder.Constant
main :: IO ()
main = do
n <- read <$> getLine -- 標準入力から1行を読んで整数として解釈する
LT.putStrLn $ ppllvm $ -- LLVM IRをテキスト表現として表示する
buildModule "main" $ do
function "main" [] i32 $ \[] ->
ret (int32 n)
import 部分のせいで長くなりましたが、重要なのは main 以下だけです。これを LLVM IR と見比べると、なんとなくやっていることが想像できると思います。
define i32 @main() {
ret i32 42
}
Haskell のコードの方にコメントを入れてみましょう。
buildModule "main" $ do -- main モジュールを組み立てて、
function "main" [] i32 $ \[] -> -- main 関数を定義。引数は空で、返り値は 32ビット整数
ret (int32 n) -- 32ビット整数として入力 n を返す
LLVM IR にわりとそのまま対応してます。llvm-hs-pure の API がうまく作られているんだと思います。
これまで明示的には出てきませんでしたが、LLVM IR には最上位にモジュールという概念があり、そのなかに関数がいくつか含まれるという考え方になっています。そこでまず main モジュールを組み立てています。
以後ではコードの本質的な部分のみを掲載します。完全なプログラムはこの記事の末尾をご覧ください。
ステップ3: 足し算をする
つぎは二つの数の足し算をしましょう。ソースコードとして例えば "12+34" を渡すと 46 を返すようにします。
12 + 34 を計算して結果を返す LLVM IR は次のとおりです。
define i32 @main() {
%a = add i32 12, 34 ;; 12 + 34 をして a に入れる
ret i32 %a ;; a の値を返す
}
新しく add というのが出てきました。add 命令によって 12 + 34 の結果を %a レジスターに格納して、その内容をそのまま ret に渡して返しています。
LLVM はレジスターとメモリーがある計算モデルです。ただしレジスターは無限にあり、その代わり再代入はできません。
上の LLVM IR を llvm-hs-pure で書き直すとこうなります。
function "main" [] i32 $ \[] ->
a <- add (int32 12) (int32 34) -- 12 + 34 をして a に入れる
ret a -- a を返す
LLVM IR とだいたいそのまま対応しています。これをふまえて、好きな2つの数の足し算をできるようにしたコンパイラーを作りましょう。
main = do
-- "12+34" のような入力から整数2つを取り出して n, m とする
[n, m] <- map read . (split '+') <$> getContents
LT.putStrLn $
ppllvm $ buildModule "main" $ do
function "main" [] i32 $ \[] ->
a <- add (int32 n) (int32 m)
ret a
12+34 を実行してみます。
% echo "12+34" | stack run | lli; echo $?
46
正しく 46 が返りました。
ステップ4: 任意の個数の足し算と引き算をする
足し算と引き算が好きなだけできるようにしましょう。たとえば 12 + 34 - 5 + 6 を計算して結果を返す LLVM IR は次のとおりです。
define i32 @main() {
%a = add i32 12, 34 ;; 12 + 34 をして a にいれる
%b = sub i32 %a, 5 ;; a - 5 をして b にいれる
%c = add i32 %b, 6 ;; b + 6 をして c にいれる
ret i32 %c ;; c を返す
}
だいたい想像どおりだと思います。新しくでてきたのは sub で、引き算をします。
入力となる文字列は "12 + 34 - 7 - 5" のように空白を許すものとします。そろそろ複雑になってきたので、ちゃんと構文解析をして、抽象構文木をつくり、コード生成する方針にしましょう。
まずは抽象構文木のデータ構造です。
data Expr = -- 式
ExprAdd Expr Expr -- 式 + 式
| ExprSub Expr Expr -- 式 - 式
| ExprInt Integer -- 式の中身が整数一個
式しかありません。ExprAdd Expr Expr のようにあるのは 式 + 式 を表します。
つづいて構文解析です。
ops :: [[Operator Parser Expr]]
ops =
[[ InfixL (ExprAdd <$ (symbol '+')) -- 足し算は左結合で、区切り文字は +
, InfixL (ExprSub <$ (symbol '-')) ]] -- 引き算も同様
expr :: Parser Expr
expr = makeExprParser (ExprInt <$> L.decimal) ops -- 式を構文解析する
いろいろ書いてありますが、Megaparsec というライブラリーの使い方の話なのであまり気にしなくても大丈夫です。演算子は左結合なのか右結合なのか、優先順位はどうなのか、といったことが書かれています。
これをふまえて、いよいよ LLVM IRのコード生成をしてみましょう。
compile :: (MonadIRBuilder m) => Expr -> m Operand
-- 整数 n をコンパイルした結果は
compile (ExprInt n) = pure $ int32 n -- int32 n である
-- e1 + e2 をコンパイルした結果は
compile (ExprAdd e1 e2) = do
e1' <- compile e1 -- e1 をコンパイルし
e2' <- compile e2 -- e2 をコンパイルし
add e1' e2' -- それらを add したものである
compile (ExprSub e1 e2) = do
e1' <- compile e1
e2' <- compile e2
sub e1' e2'
足し算や引き算を再帰的にコンパイルしているところは少し不思議ですが、それでも次のように理解できます。
-- e1 + e2 をコンパイルするためには、
compile (ExprAdd e1 e2) = do
-- まず e1 の計算結果が e1' レジスターに入るようなコンパイル結果を生成し、
e1' <- compile e1
-- e2 についても同様にし、
e2' <- compile e2
-- e1' レジスターと e2' レジスターの値を足す
add e1' e2'
e1 は複雑な式になりえますが、そのコンパイルで作られた複雑な IR列 を e1' だと考えてしまうと、それを最後の add の引数に取る部分が理解できなくなります。e1' は、e1 の計算結果が最終的に収められているレジスター(一般にはオペランド)だと考えると理解しやすいです。
この compile を使って main 関数の後半を置き換えれば、このステップでのコンパイラーはできあがりです。
main :: IO ()
main = do
str <- getContents -- 標準入力を読んで
let ast = parseExpr str -- 抽象構文木をつくり
LT.putStrLn $ -- 以下のLLVM IR を出力する
ppllvm $ buildModule "main" $ do -- main モジュールのなかに
function "main" [] i32 $ \[] -> do -- main 関数があり、
opr <- compile ast -- 式をコンパイルして
ret opr -- その結果を返す
計算をためしてみましょう。
% echo "3 + 4 - 2 - 1" | stack run | lli; echo $?
4
ちゃんと動きました。
ステップ5: 掛け算、割り算とカッコを追加する
つぎに掛け算、割り算とカッコが使えるようにしましょう。つまり、(1 + 2) * 3 / 4 が計算できるようにします。
まずは抽象構文木に掛け算と割り算を表す構造を追加します。
data Expr =
...
| ExprMul Expr Expr -- 式 * 式
| ExprDiv Expr Expr -- 式 / 式
つづいて割り算、掛け算、カッコがパースできるようにします。
ops :: [[Operator Parser Expr]]
ops =
[
[ InfixL (ExprMul <$ (symbol "*")) -- 掛け算は左結合で、文字は *
, InfixL (ExprDiv <$ (symbol "/")) ],-- 割り算も同様
[ InfixL (ExprAdd <$ (symbol "+")) -- 足し算は左結合で、文字は +
, InfixL (ExprSub <$ (symbol "-")) ] -- 引き算も同様
] -- この表で先に出てくる方(つまり*と/)のほうが優先順位が高い
expr :: Parser Expr -- 式とは
expr = makeExprParser term ops -- 項 term と演算子 ops を組み合わせたもの
term :: Parser Expr -- 項とは
term = ExprInt <$> L.decimal -- 整数単体か
<|> parens expr -- カッコに囲まれた式
parens :: Parser a -> Parser a -- カッコに囲まれた とは
parens = between (symbol "(") (symbol ")") -- '('と')'の間にあること
ops では、*や/のほうが+や-より先に現れています。Megaparsec では、これは前者のほうが優先順位が高いという意味になります。
続いてコンパイルです。掛け算と割り算は LLVM IR では mul と sdiv のようになります。llvm-hs-pure でもそのまま mul と sdiv で表せますので、足し算のときと同様に追加するだけです。
compile (ExprMul e1 e2) = do
e1' <- compile e1
e2' <- compile e2
mul e1' e2'
compile (ExprDiv e1 e2) = do
e1' <- compile e1
e2' <- compile e2
sdiv e1' e2'
なお sdiv は符号付きの割り算です。符号なしの udiv もあります。ここまでを実行してみましょう。
% echo "(1+2)*3/4" | stack run | lli; echo $?
2
ただしく計算できています。ここまででいわゆる電卓ができました。
なお、本来は 0 除算のことを考えないといけません。もっというとパースを含めた様々な場面でのエラーも考えないといけません。が、簡単のためそれらはまったく無視することにします。
ステップ6: 変数への代入と参照を追加する
だんだんプログラミング言語っぽくしていきます。まずは変数を使えるようにしましょう。変数への代入と、値の参照ができるようにします。ただし再代入はできません。想定する言語はこんなです。
a = 10;
b = 20;
a + b;
これを実行すると 30 が返るようにします。急にプログラミング言語っぽくないですか。
なお、本来の Kaleidoscope にはこのような機能や構文はありません。四則演算のつぎは急に関数になります。ただそれだと1段が大きすぎると感じたので、このステップを設けています。
まずは抽象構文木に変数への代入と変数の値の参照を追加しましょう。
data Expr =
...
| Assign Expr Expr -- 式1が表す変数に式2を代入する
| Var String -- 変数名を表す
単純にするため、代入も式にします。たとえば a = 10 は Assign (Var "a") (ExprInt 10) になります。
次は読み取りと構文解析です。
ops :: [[Operator Parser Expr]]
ops =
[
[ InfixL (ExprMul <$ (symbol "*"))
, InfixL (ExprDiv <$ (symbol "/")) ],
[ InfixL (ExprAdd <$ (symbol "+"))
, InfixL (ExprSub <$ (symbol "-")) ],
[ InfixR (Assign <$ (symbol "=")) ], -- "式1 = 式2" を Assign 式1 式2 とする
]
上で追加したのは = を含む行だけです。= の優先順位を最低にしたので、a = b + 1 を a = (b + 1) と書かずに済みます。
term :: Parser Expr
term = ExprInt <$> num
<|> parens expr
<|> Var <$> identifier -- 変数名を見つけたら Var にくるむ
identifier は英文字で始まり英数字が続く文字列です。それを変数名として認識し、変数名を表す Var にくるみます。
それから複数の行を読めるようにしましょう。
exprs :: Parser [Expr] -- 行の区切りは ';'
exprs = expr `sepEndBy` (symbol ";")
sepEndBy は、なにかを区切りとする並びをリストとして返します。いまの場合は 式;式;式; を式のリストにします。
つぎはコンパイルです。変数名と値のペアを、環境と呼ばれる辞書に入れて管理するようにします。詳細はコメントに書いておきました。
-- 変数名と値の対応(環境)を辞書に入れておく
type Env = M.Map String Operand
-- 環境を使ってコンパイルするように変更する
compile :: (MonadIRBuilder m) => Expr -> StateT Env m Operand
...
compile (Assign (Var v) e) = do -- 変数名 v = 式 e のコンパイルは、
e' <- compile e -- まず e をコンパイルする
env <- get -- つぎに環境をとってきて
let env' = M.insert v e' env -- v と e' の対応を追加したものを
put env' -- 新しい環境とする
pure e' -- e' の値が全体の結果
compile (Var v) = do -- 変数名 v のコンパイルは、
env <- get -- 環境に
let opr = case M.lookup v env of -- v に対応する値があれば
Just x -> x -- それを使う。なければエラー。
Nothing -> error $ "variable " ++ v ++ " not found"
pure opr
-- 複数の式をコンパイルするときは、前から順にコンパイルする
compile :: (MonadIRBuilder m) => [Expr] -> StateT Env m Operand
compile [e] = compile e
compile (e:es) = do
compile e
compile es
ここまでを実行してみましょう。
% echo "a=10; b=20; a+b;" | stack run | lli; echo $?
30
ちゃんと計算できています。変数が使えるようになりました。
ステップ7: if を追加する
次は if を使えるようにしましょう。if は値を返す式とします。たとえば
if 1 < 2 then 3 else 4
の場合、1 < 2 は真なので、式全体としての値は 3 になるようにします。
まずはデータ構造からです。ifを表す構造と、条件式を追加します。
data Expr =
...
| ExprIf Expr Expr Expr -- if 条件式 then式 else式
| ExprLT Expr Expr -- 式 < 式
パーサーについては、演算子として < と、ifの構文を追加します。
ops =
[
[ InfixL (ExprMul <$ (symbol "*"))
, InfixL (ExprDiv <$ (symbol "/")) ],
[ InfixL (ExprAdd <$ (symbol "+"))
, InfixL (ExprSub <$ (symbol "-")) ],
+ [ InfixL (ExprLT <$ (symbol "<")) ],
[ InfixL (Assign <$ (symbol "=")) ]
]
term :: Parser Expr
term = ExprInt <$> lexeme L.decimal
<|> parens expr
+ <|> exprIf
<|> Var <$> lexeme identifier
> については追加せずさぼります。また、項として if式を読み取るための exprIf を追加しています。定義は次のとおり。
exprIf :: Parser Expr
exprIf = do
symbol "if" -- まず "if" を読み
condExpr <- expr -- 次に現れる式を条件式とする
symbol "then" -- "then" を読み
thenExpr <- expr -- 次の式を then式 とする
symbol "else" -- "else" も同様
elseExpr <- expr
pure $ ExprIf condExpr thenExpr elseExpr -- 全体を ExprIf でくるむ
さて、ifのコンパイルをする前にまずは if に対応するLLVM IR を見てみましょう。if 1 < 2 then 3 else 4 に相当する LLVM IR は例えばこんなふうです。
define i32 @main() {
cond:
%1 = icmp slt i32 1, 2 ;; 1 < 2 を計算して
br i1 %1, label %then, label %else ;; 真なら then へ。偽なら else へ
then:
br label %end ;; なにもせず end へ
else:
br label %end ;; なにもせず end へ
end:
%2 = phi i32 [3, %then], [4, %else] ;; then から来たら 3 を、else からなら 4 を、
ret i32 %2 ;; 値として返す
}
新しい要素が4つほど出てきました。順に説明します。
cond: のようにあるのはラベルです。好きな名前をつけることができます。処理を分岐させるときの飛び先の名前として使うことができます。
比較演算 < に相当する icmp slt は、整数どうしを符号つきで比較します。
br label は、好きな場所に無条件で分岐(branch)する命令です。いっぽう br i1 a, label b, label c は、1ビットの値 a が 1 なら b へ、0 なら c へ分岐します。
最後は phi です。これは処理がどこから来たかによって値を変える不思議な関数です。この場合、then部分 から来たら 3 を、else部分から来たら 4 を返します。
これを踏まえて任意の if 式 then 式 else 式 は次のようにコンパイルできます。
compileExpr (ExprIf condExpr thenExpr elseExpr) = mdo
cond <- compileExpr condExpr -- %0 = icmp slt i32 1, 2
condBr cond ifThen ifElse -- br i1 %0, label %then, label %else
-- then:
ifThen <- block `named` "then" -- then:
oprThen <- compileExpr thenExpr -- then 部分の式を計算する
br ifEnd -- br label %end
enfOfThen <- currentBlock -- 現在のブロックを enfOfThen とする
-- else:
ifElse <- block `named` "else" -- else:
oprElse <- compileExpr elseExpr -- else 部分の式を計算する
br ifEnd -- br label %end
endOfElse <- currentBlock -- 現在のブロックを enfOfElse とする
-- end:
ifEnd <- block `named` "end" -- end:
-- phi
phi [(oprThen, enfOfThen), (oprElse, endOfElse)] -- phi
上の if.ll と比較すると、ほぼ一対一で対応しています。対応する LLVM IR をコメントに入れておきました。
block `named` "then" は、then という名前をラベルとして持つベーシックブロックを作ります。ベーシックブロックとは、命令の列であって最後にだけ分岐命令を持つものです。if.ll では then 部分が単純すぎたので何もせずに end に飛んでいましたが、一般の場合ではちゃんと then 部分を計算してから end に飛びます。そして phi によって、 then から来た場合のみ then で計算した値を使うようにします。else も同様です。
then のブロックを定義し終わったところで改めて現在のブロックを endOfThen とし、最後の phi では ifThenブロック ではなく endOfThenブロックから来たかどうかを見ています。ここが重要です。なぜわざわざそんなことをするかを理解するために、まずは単純な if の図を見てみましょう。
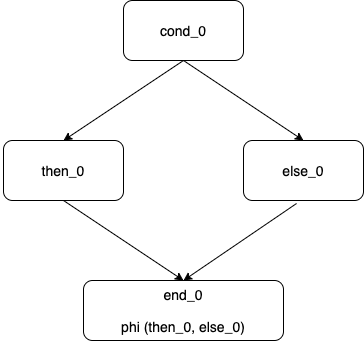
この図で、四角はベーシックブロックを、その中の文字はラベルを表します。矢印は分岐命令によるジャンプを表しています。ラベル名が重複しないよう、末尾には cond_0 のように数字が自動的につきます。最後の end_0 ブロックで、phi が分岐元として想定しているのは then_0 と else_0 であることを覚えていてください。
ここで、then_0 の中身がふたたび if だったときを考えてみましょう。その場合の分岐の図は以下のようになります。
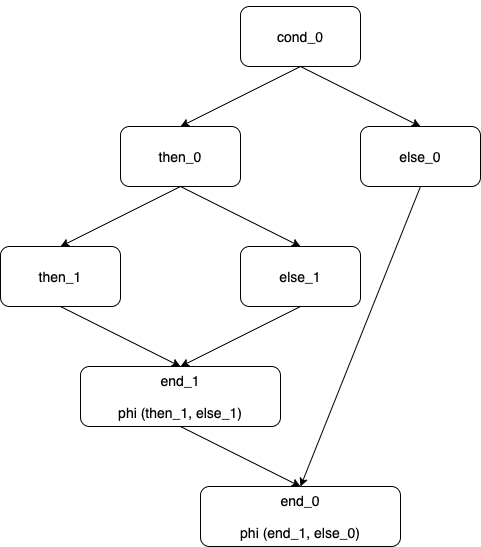
末尾の end_0 ブロックを見てください。ここへの分岐元のブロックはもはや then_0 と else_0 ではありません。 end_1 と else_0 です。つまり一般には end_0 への分岐元をあらかじめ then_0 と else_0 に決め打ちすることはできません。
ではどうすればいいかですが、上の図でいう end_1 はよく考えると「else_0 を定義する直前に定義されたブロック」ですから、まさにそれを取得して phi に渡せばいいのです。それが次の行の意味です。
endOfThen <- currentBlock -- 現在のブロックを endOfThen とする
else_0 の側も別のベーシックブロックが挟まる可能性がありますので、同様の処理が入っています。ではここまでを実行しましょう。
% echo "if 1 < 2 then 3 else 4" | stack run | lli; echo $?
3
ちゃんと if が計算できました。
ステップ8: 関数定義と呼び出しを追加する
いよいよ関数を定義して呼び出せるようにしましょう。このステップが最後です。これさえできればフィボナッチ数列も計算もできるようになります。
まず関数の定義と呼び出しの構文を定めましょう。
# 関数定義の例
def add(x y) x + y
# 呼び出しの例
add(1,2)
def で関数の定義を始め、仮引数は空白で区切ります。本体には、式が1つだけ書けます。一方で呼び出す際は引数をカンマで区切ります。Kaleidoscope と同じです。
まずは関数の定義と呼び出しを表す抽象構文木のノードを定義しましょう。
data Expr =
...
| Fun String [String] Expr -- 関数定義: 名前 [仮引数] 本体
| FunCall String [Expr] -- 関数呼び出し: 名前 [引数]
上で定義した構文を素直に構造に表したものです。続いてパースしましょう。
funDef :: Parser Expr
funDef = do
symbol "def"
funName <- identifier
symbol "("
params <- many identifier
symbol ")"
body <- expr
pure $ Fun funName params body
funCall :: Parser Expr
funCall = do
name <- identifier
symbol "("
args <- expr `sepBy` (symbol ",")
symbol ")"
pure $ FunCall name args
def で始まり、名前があり、カッコが続き、といった具合です。
で、いよいよコンパイルですが、まずは最終的な LLVM IR を見ないと話が始まりません。関数の定義と呼び出しを行う次のような nano プログラム、
def add(x y) x + y;
add(1,2);
に相当する LLVM IR を見てみましょう。
define i32 @add(i32 %x, i32 %y) {
%1 = add i32 %x, %y
ret i32 %1
}
define i32 @main() {
%1 = call i32 @add(i32 1, i32 2)
ret i32 %1
}
add 関数の定義は、 main を定義する方法とまったく同じですね。いっぽう main から add を呼び出すときは call を使っています。call i32 @add(i32 1, i32 2) は、32ビット整数を返す関数 add を、引数を1と2にして呼ぶということです。
これを踏まえて、関数の定義と呼び出しのコンパイルは次のようになります。まずは比較的簡単な呼び出しのほうから。
compileExpr (FunCall funName exprs) = do
env <- get -- 環境を取り出して
oprs <- mapM compileExpr exprs -- 引数を順にコンパイルする
let f = case M.lookup funName env of -- 環境から関数を探して
Just funOperand -> funOperand -- あればそれを使う。なければエラー
Nothing -> error $ "function " ++ funName ++ " not found"
call f (zip oprs (repeat [])) -- 引数の計算結果をもとに関数を呼ぶ
環境になぜか関数があることになってますが、これは今からやる関数の定義の際に登録するものです。ではいよいよ関数を定義してみましょう。
compileExpr (Fun funName paramNames funBody) = do
env <- get
-- 返り値の型が i32 で、引数の型が (i32, ...) であるような関数の型
let typ = FunctionType i32 (replicate (length paramNames) i32) False
-- そんな関数へのポインターの型
ptrTyp = AST.PointerType typ (AddrSpace 0)
-- 関数名と、関数へのポインターを組にした参照
ref = AST.GlobalReference ptrTyp (fromString funName)
-- 関数名と関数への参照の対応を環境に追加する
env' = M.insert funName (ConstantOperand ref) env
put env'
function (fromString funName) (zip (repeat i32) (map fromString paramNames)) i32 $ \oprs -> do
-- "仮引数と実引数の対応"を、環境に追加する
let newEnv = foldr (\(k,v) env -> M.insert k v env) env' (zip paramNames oprs)
-- 新しい環境で本体をコンパイルする
opr <- evalStateT (compileExpr funBody) newEnv
ret opr
if then else のコンパイルと同じくらい文字が詰まってますね。しかし大まかには次のようなことをしています。
- 環境に、関数名と関数への参照を登録する
-
functionで、関数名と型と本体を定義する。 - 本体では、"仮引数と実引数の対応"を、関数を定義する時点の環境に追加してからコンパイルする
では実行してみましょう。
% echo "def add(x y) x + y; add(10,20)" | stack run | lli; echo $?
30
ちゃんと動いてますね。Kaleidoscope チュートリアルの冒頭にあるフィボナッチ関数はどうでしょうか。
% echo "def fib(n) if n < 2 then 1 else fib(n-1) + fib(n-2); fib(10)" | stack run | lli; echo $?
55
正しく動きました。
まとめ
最小限の機能しかないコンパイラーからはじめて、少しづつ機能を追加する方法でフィボナッチ数列が計算できるところまで育てました。やっぱりこのやりかたは自分にとってはとても分かりやすいです。そのうえで自分がつまずいたところはなるべく詳しく書きました。
今回のコードは以下にあります。
たとえばステップ4を実行するときは次のようにしてください。
% git clone https://github.com/mitsuchi/nanoscope.git
% git checkout step4 -b step4
% make test
手元に LLVM や haskell がないという方には Dockerfile を用意しましたので、
% make docker-build
% make docker-run
(以下コンテナで)
# git checkout step4
# make test
のようにコンテナ上で実行できます。よければ試してみてください。
なお、本家の Kaleidoscope はこの先で文字を出したりマンデルブロ集合を表示したり、JIT で実行させたりします。それについてはべつの記事として書いてみたいと思います。
これを進めながら「プログラミング言語処理系が好きな人の集まり」という Slack チャンネルに進捗を報告したのですが、反応をもらえるのが嬉しかったです。みなさんもぜひご参加ください。
参考文献
LLVM の Kaleidoscope チュートリアル (OCaml版が簡潔で読みやすかったです)
https://llvm.org/docs/tutorial/OCamlLangImpl1.html
「低レイヤを知りたい人のためのCコンパイラ作成入門」
https://www.sigbus.info/compilerbook
Haskell+LLVM構成で作る自作コンパイラ
https://qiita.com/toru0408/items/6bedee118ba08ea2c0b2
こわくないLLVM入門!
https://qiita.com/Anko_9801/items/df4475fecbddd0d91ccc