対象読者
- LLVMを勉強し始めたけど何からして良いのかわからない方
- アセンブリがちょっとわかる
目標
- LLVMの基本的な文法がわかるようになる
環境
- Mac Mojave 10.14.6
- LLVM 8.0.0
- clang 8.0.0 (trunk 348837)
LLVMってなに...?
LLVMは一言で言えば、プログラミング言語を作成する為の基盤です。プログラミング言語はコンパイラによってバイナリに変換され実行することができます。それを言い換えれば、自分が考えたプログラミング言語のコンパイラを作ることで自作プログラミング言語を作れます。
そして、コンパイラは通常フロントエンド、ミドルエンド、バックエンドに分けられ、各プロセスで様々な処理をしています。特にミドルエンド、バックエンドでは中間言語や各アーキテクチャに対するたくさんの最適化を施さなければなりません。この最適化を預けてフロントエンドだけを考えればコンパイラが作れるというものがLLVMです。LLVMは強力な型システムや厳密な制約を持っていて、これにより高度な最適化技術は実現します。更にLLVMはJITを作る事ができます。JITは通常実装するのが大変ですが、LLVMを使えば楽に実装できます。更に更に他の言語でコンパイルされたLLVMの言語とリンクする事ができます。だから自分で作った言語でC言語の関数を使うことができます!
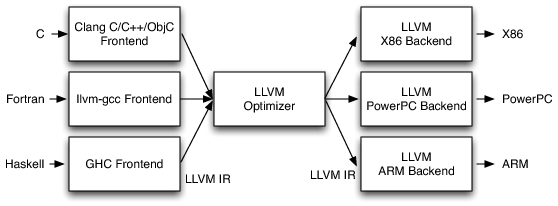
とりあえずやってみよう!
Hello, world!
エディタを開いて下のC言語のソースコードを書いてください。Hello worldを出力して終了するプログラムです。
# include <stdio.h>
int main(int argc, char **argv) {
printf("Hello, world!\n");
return 0;
}
このファイルと同じ階層で下のコマンドを打ってください。
$ clang -S -emit-llvm -O3 helloworld.c
するとhelloworld.llというLLVMの言語で書かれたファイルが出てきます。そしてこれをllcというLLVMの言語からアセンブリのコンパイラを使い、コンパイルして実行してみます...
$ llc helloworld.ll
$ clang helloworld.s -o helloworld
$ ./helloworld
Hello, world!
実行できました!
では、このhelloworld.llを開いてみると...
; ModuleID = 'helloworld.c'
source_filename = "helloworld.c"
target datalayout = "e-m:o-i64:64-f80:128-n8:16:32:64-S128"
target triple = "x86_64-apple-macosx10.14.0"
@str = private unnamed_addr constant [14 x i8] c"Hello, world!\00", align 1
; Function Attrs: nounwind ssp uwtable
define i32 @main(i32 %argc, i8** nocapture readnone %argv) local_unnamed_addr #0 {
entry:
%puts = tail call i32 @puts(i8* getelementptr inbounds ([14 x i8], [14 x i8]* @str, i64 0, i64 0))
ret i32 0
}
; Function Attrs: nounwind
declare i32 @puts(i8* nocapture readonly) local_unnamed_addr #1
attributes #0 = { nounwind ssp uwtable "correctly-rounded-divide-sqrt-fp-math"="false" "disable-tail-calls"="false" "less-precise-fpmad"="false" "min-legal-vector-width"="0" "no-frame-pointer-elim"="true" "no-frame-pointer-elim-non-leaf" "no-infs-fp-math"="false" "no-jump-tables"="false" "no-nans-fp-math"="false" "no-signed-zeros-fp-math"="false" "no-trapping-math"="false" "stack-protector-buffer-size"="8" "target-cpu"="penryn" "target-features"="+cx16,+fxsr,+mmx,+sahf,+sse,+sse2,+sse3,+sse4.1,+ssse3,+x87" "unsafe-fp-math"="false" "use-soft-float"="false" }
attributes #1 = { nounwind }
!llvm.module.flags = !{!0, !1}
!llvm.ident = !{!2}
!0 = !{i32 1, !"wchar_size", i32 4}
!1 = !{i32 7, !"PIC Level", i32 2}
!2 = !{!"clang version 8.0.0 (trunk 348837)"}
ウギャア!!何これ、でかい...実行に重要な部分だけを取り出してみます。
@str = private unnamed_addr constant [14 x i8] c"Hello, world!\00", align 1
define i32 @main(i32 %argc, i8** %argv) {
entry:
%puts = tail call i32 @puts(i8* getelementptr inbounds ([14 x i8], [14 x i8]* @str, i64 0, i64 0))
ret i32 0
}
declare i32 @puts(i8* nocapture readonly) local_unnamed_addr #1
これでだいぶスッキリしました!これがLLVMの言語、LLVM IRというものです。
...と言われても全然さっぱりなので何が書かれているのか一つ一つ理解します。
以下の順で紹介します。
; 3. 文字列定義
@str = private unnamed_addr constant [14 x i8] c"Hello, world!\00", align 1
; 1. 関数定義
define i32 @main(i32 %argc, i8** %argv) {
; 2. ラベル
entry:
; 3. 関数呼び出し、4. GetElementPtr
%puts = tail call i32 @puts(i8* getelementptr inbounds ([14 x i8], [14 x i8]* @str, i64 0, i64 0))
; 3. 関数から値を返す
ret i32 0
}
; 3. 外部関数の宣言
declare i32 @puts(i8* nocapture readonly) local_unnamed_addr #1
関数定義
define i32 @main(i32 %argc, i8** %argv) {
...
}
ここでは関数定義をしています。関数は他言語と同様に引数を用いて処理し、値を返します。引数は型、前置記号%/@、変数名の順に書きます。
まず型についてです。
LLVM IRの型は主に下記のようなものがあります。
- 整数型 (ex. i32, i64)
- i32は32bitの整数型というようにiの右にビット幅を指定します。ビット幅は任意に(1から2^23-1(約800万)まで)指定できます。
- 浮動小数点型
- 32bit浮動小数点型はfloat, 64bit浮動小数点型はdoubleとします。こちらはf32などとは表現しません。
- ポインタ型
- C言語と同じように*を付けてポインタと同じ働きをします。
- aggregateな型
- aggregateとは集合体という意味で配列,ベクター,構造体などをそれぞれ[サイズx型], <サイズx型>, {型, 型, ...}と書きます。
- 他にはvoid型、関数型、ラベル型、トークン型、Metadata型があります。
またLLVM IRでは真偽値や文字は整数型を使って表現します。例えば、charは8ビットの型なのでi8、14文字の文字列の配列は[14 x i8]、boolはi1です。
ちなみにLLVMにはunsigned intは存在しません。じゃどうやって使うんだよ!となりますが、演算するときにunsignedですと指定する事で解決しています。なぜ存在しないのかはLLVM Type System Changesを参照してください。
@, %はそれぞれグローバル, ローカルという意味をもち、変数や関数の前置記号として必ず付けます。
ラベル・コメント
entry:
; もふもふ
ラベル名: と書くとラベルが付けられます。ラベルはアセンブリと同じように他のアドレスからジャンプ命令でラベルのアドレスへジャンプしてそのアドレスから処理する事が出来ます。
また、頭文字に';'があるとコメントされます。その行は実行されません。
文字列、関数呼び出し
@str = private unnamed_addr constant [14 x i8] c"Hello, world!\00", align 1
...
%puts = tail call i32 @puts(i8* getelementptr inbounds ([14 x i8], [14 x i8]* @str, i64 0, i64 0))
...
declare i32 @puts(i8* nocapture readonly) local_unnamed_addr #1
文字列やそれに関する関数について解説していきます。最初に@strはサイズ14のi8の配列でグローバル変数として定義しています。i8はcharだからchar[14]と同じです。
その後、call命令で@puts関数、C言語でのprintf関数を呼び出しています。関数呼び出しは"call 型 @/%関数名(引数)"と書きます。tailは末尾呼び出し最適化をする時に使います。末尾呼び出し最適化は本筋とは関係ないので、ここでは解説しません。
そしてputs関数の引数のi8* getelementptr inbounds ([14 x i8], [14 x i8]* @str, i64 0, i64 0)に注目して頂きたいのですが、これはGetElementPtr(GEP)と呼ばれるものです。
これはよく誤解されたりするため公式の専用の解説ページまであります。GEPについて、すぐ後で詳しく解説します。
そして後にcall命令で関数宣言される@puts関数がこのアドレスを引数として呼び出しています。
そして最後にret命令で関数が返って終わります。
GetElementPtr(GEP)
GEPは配列や構造体などのsubelementのアドレスを計算します。
下の公式サイトの例を参考にしてgetelementptrを解説します。
struct munger_struct {
int f1;
int f2;
};
void munge(struct munger_struct *P) {
P[0].f1 = P[1].f1 + P[2].f2;
}
...
munger_struct Array[3];
...
munge(Array);
これをclangでコンパイルしてmunger_structとmunge関数を見てみます。
%struct.munger_struct = type { i32, i32 }
void %munge(%struct.munger_struct* %P) {
entry:
%tmp = getelementptr %struct.munger_struct, %struct.munger_struct* %P, i32 1, i32 0
%tmp = load i32* %tmp
%tmp6 = getelementptr %struct.munger_struct, %struct.munger_struct* %P, i32 2, i32 1
%tmp7 = load i32* %tmp6
%tmp8 = add i32 %tmp7, %tmp
%tmp9 = getelementptr %struct.munger_struct, %struct.munger_struct* %P, i32 0, i32 0
store i32 %tmp8, i32* %tmp9
ret void
}
getelementptrはある変数のアドレスを計算するもので、3つ以上のオペランドから構成されています。
getelementptr <1st_op>, <2nd_op>, <3rd_op>*
それぞれ
1つ目: 元の型
2つ目: ベースとなるアドレス
3つ目以降: 配列や構造体などのインデックス
となっています。
上のLLVM IRとC言語を対応してみてみると...
LLVM IR
%tmp9 = getelementptr %struct.munger_struct, %struct.munger_struct* %P, i32 0, i32 0
%tmp = getelementptr %struct.munger_struct, %struct.munger_struct* %P, i32 1, i32 0
%tmp6 = getelementptr %struct.munger_struct, %struct.munger_struct* %P, i32 2, i32 1
C言語
tmp9 = &P[0].f1
tmp = &P[1].f1
tmp6 = &P[2].f2
というようになります。また、それぞれ型の情報とインデックスから計算出来ます。例えば、i32の配列であれば32 * インデックス数をベースのアドレスに足してアドレスを計算します。すると
%puts = tail call i32 @puts(i8* getelementptr inbounds ([14 x i8], [14 x i8]* @str, i64 0, i64 0))
これはC言語で書くと&str[0][0]で、strの開始アドレスに指定されていると分かります。ちなみにこのinboundsというパラメータは配列などに範囲外のアドレスを指定してない事を示しています。
if文のLLVM IRを理解してみる
次はこのプログラムをLLVM IRで理解します。
int branch(int cond) {
int i = -1;
if (cond == 0) {
i = 0;
}else{
i = 1;
}
return i;
}
最適化無しでコンパイルします。
define i32 @branch(i32 %cond) {
entry:
%cond.addr = alloca i32, align 4
%i = alloca i32, align 4
store i32 %cond, i32* %cond.addr, align 4
store i32 -1, i32* %i, align 4
%0 = load i32, i32* %cond.addr, align 4
%cmp = icmp eq i32 %0, 0
br i1 %cmp, label %if.then, label %if.else
if.then: ; preds = %entry
store i32 0, i32* %i, align 4
br label %if.end
if.else: ; preds = %entry
store i32 1, i32* %i, align 4
br label %if.end
if.end: ; preds = %if.else, %if.then
%1 = load i32, i32* %i, align 4
ret i32 %1
}
条件分岐、ジャンプ
条件分岐はicmp, fcmp命令、ラベルへジャンプする際はbr命令を使います。
icmp命令は"icmp 比較方法 比較する二つの値"の順に書き、比較してtrue, falseを返します。icmpは整数同士で比較でき、それと対応してfcmpは小数同士で比較できます。
br命令は"br label %/@ ラベル名"としてラベルにジャンプする、または"br 条件, 真のときジャンプするラベル, 偽のときジャンプするラベル"と書きます。
変数のための命令
alloca, store, load命令は変数を扱う為に使います。
%<ptr> = alloca <type> (, align <alignment>)
store <type> <value>, <ptr_type> %<ptr>
%val = load <type>, <ptr_type> %<ptr>
alloca命令はtypeのbit幅分メモリ確保し、そのアドレスを返します。
store命令はアドレスのメモリへ値を書き込みます。
load命令はアドレスから読み込む時に使います。
alignはアラインメントを指定し、指定しなければ最初に省略したところにあるデータレイアウトを参照して、アラインメントを決定します。
その他
最初に省略したものは上下に2つあります。まず上では
; ModuleID = 'helloworld.c'
source_filename = "helloworld.c"
target datalayout = "e-m:o-i64:64-f80:128-n8:16:32:64-S128"
target triple = "x86_64-apple-macosx10.14.0"
1~2行目はソースコード名。これは特に問題ないですね。3行目はデータレイアウト、これは型別のアラインメントやエンディアンなどを定義しています。4行目はtarget-tripleというものでアーキテクチャやOSなどの情報が載っています。もちろんここは環境によって異なります。
次に下ではこのように書いてありました。
attributes #0 = { nounwind ssp uwtable "correctly-rounded-divide-sqrt-fp-math"="false" "disable-tail-calls"="false" "less-precise-fpmad"="false" "min-legal-vector-width"="0" "no-frame-pointer-elim"="true" "no-frame-pointer-elim-non-leaf" "no-infs-fp-math"="false" "no-jump-tables"="false" "no-nans-fp-math"="false" "no-signed-zeros-fp-math"="false" "no-trapping-math"="false" "stack-protector-buffer-size"="8" "target-cpu"="penryn" "target-features"="+cx16,+fxsr,+mmx,+sahf,+sse,+sse2,+sse3,+sse4.1,+ssse3,+x87" "unsafe-fp-math"="false" "use-soft-float"="false" }
attributes #1 = { nounwind }
!llvm.module.flags = !{!0, !1}
!llvm.ident = !{!2}
!0 = !{i32 1, !"wchar_size", i32 4}
!1 = !{i32 7, !"PIC Level", i32 2}
!2 = !{!"clang version 8.0.0 (trunk 348837)"}
1~2行目は属性です。属性は変数や関数に埋め込んでコンパイルの設定や動的なエラーを起こす事などが出来ます。前置記号として'#'を使います。例えばnounwindは関数が例外を発生させない事、sspはcanaryを生成する事を示しています。
4~9行目はmetadataです。metadataはソースコードに埋め込んでデバッグ情報や言語固有の最適化で使います。前置記号として'!'を使います。
LLVM IRでの大まかな区分
最後にLLVM IRを生成するライブラリによく出てくる単語について紹介します。
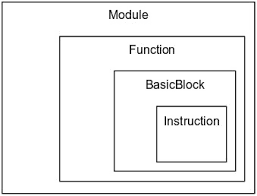
LLVM IRではModule, Funciton, BasicBlock, Instruction の4段階の区分があります。
それぞれは曖昧ですが用途が決まっています。
- Module はソースコードなどの大きな枠組でそれらでリンクが出来るもの。Funcion を複数持つ。
- Function はLLVM IR内での関数でCの関数と同じ。BasicBlock を複数持つ。
- BasicBlock はラベルごとで分けられる小さな枠組。Instruction を複数持つ。
- Instruction はLLVM IR内での1つの命令。
これから
これくらいの知識でも調べながら大体の機能(ループや構造体、タプル、オブジェクト指向など)が実装出来ると思います。とりあえず、一通り簡単な言語を作ってみると良いと思います。簡単にLLVM IRを出力してくれるライブラリはC++のllvmやRustのllvm_sysやinkwellがあります。他人のコードや公式リファレンスを読みつつ、分からないところがあればGoogleに投げればLLVM Doxygenがあるので進められます。
参考文献
公式ドキュメント
- 公式リファレンス
-
公式チュートリアル
- KaleidoScopeです。BasicBlockの扱いがよく書かれてあります。
-
LLVM Doxygen
- 基本的にここを頼りに言語を作っていく感じです。自動的に生成されたページなので新しい機能も載ってます。
書籍
-
きつねさんでもわかるLLVM
- LLVMの情報と言語処理系の解説、最適な作り方がとても詳しく載っていました。(バージョンが少し違っていて上手く動かない部分もあります)
記事
-
编译器架构的王者LLVM
- KaleidoScopeよりも詳しく分かりやすく書かれています。
-
LLVM 6.0 で作るフロントエンドの道しるべ
- きつねさんでもわかるLLVMやKaleidoScopeのバージョンと今のバージョンで違っていて躓いていた時に助けになりました。