この記事は、みらい翻訳 Advent Calendar 2020 14日目の記事です。
こんな人向けの話です
- AWS EC2コスト削減したい。商用環境でもspotインスタンスを使ってみたい。
- 最低限のEC2台数(例えば2台)で組まれたAutoScalingグループの冗長構成があり、安易にspotインスタンスを使うとspot枯渇時のサービス断リスクがとても高い
- 限られたインスタンスタイプしか使えず、多くのインスタンスタイプを候補にいれてspot枯渇リスクを分散する事ができない
はじめに
こんにちは、@mitonoです。みらい翻訳でインフラ周りを担当しています。
AWSを普段使いしていると、便利なのは良いけどもっともっと低コストで使いたいなぁという欲が出てきますね。
私の担当しているシステムではEC2のコストが大きく、今回は積極的にEC2のspotインスタンスを使う事でコスト削減を狙ってみようというという話題です。
spotインスタンスを使うにあたってお約束に近い話ですが、spotインスタンスはAWS都合で停止される事が多々あります。これをシステム構成に組み込む場合、いくつか前提がでてきます。
- 該当サーバ上ではステートレスな処理のみ行っている。若しくはステートフルな処理を行っていてもサーバ上でステート管理していない。
- 該当サーバに対するリクエストが多少エラーになっても問題ない。(リクエスト元でリトライを行う、若しくサービスとして少数のエラーであれば発生しても問題がない等。)
要は急なサーバ停止が致命傷になったり、エラー発生時に細やかな運用確認/対応が必要な所にはspotインスタンスは使いにくいという事ですね。spotインスタンスの停止は事前通知の仕組みが幾つかあり、通知を受けて安全に停止する仕組みを作る事ができますが、完全ではないので最悪通知無くいきなり停止する事はありうると考えておいたほうが良いでしょう。
又、spotインスタンスはAWS側設備の余剰分で賄われている事もあり、希望するインスタンスタイプが枯渇して買えない事があるのも大事な考慮ポイントです。
これらの事からspotインスタンスが使いやすいのは
- 何十台以上の規模で分散されており多少のspotインスタンス停止がクリティカルにならない
- インスタンスタイプに拘りや縛りがなく多様なインスタンスタイプをspot候補とする事で、spot枯渇に対するリスクをあまり考えなくて良い
という様な箇所になります。今回はここから一歩踏み込んで、
- 冗長構成としては最低の2台で組まれている
- インスタンスタイプがアプリケーション要件で縛られているので、spot候補にできるインスタンスタイプが少ない。(=spotインスタンス枯渇の影響を受けて冗長構成が保たれないリスクが高い)
という様な所に、積極的にspotインスタンスを使って行けるかもしれない工夫を共有します。
目的と課題
私の担当しているシステムでは、機械翻訳関連の設備としてGPU搭載インスタンス(主にg4系、g3系)を2台の冗長構成で使っている所が多くあります。
通常、この様な最低限の台数で冗長構成として運用されるEC2は、2台ともOndemandインスタンスとして起動し障害に強い構成とした上で、コスト的にはReserved instanceやsaving planを利用して抑えてゆく、という方向性が基本なのかなと思っています。
でもやはり、低コスト化の欲を持ちつつシステムを眺めると、1台で良い所に冗長構成のためだけに2台起動しているのは改善ポイントとして目立つんですよね。。。(もちろん性能分散の観点もありますが)
目的としては
「AutoScalingグループ(以下ASG)によるEC2冗長構成を取りつつ、利用料金をReseved Instanceより更に低下させたい」
です
ただGPU系インスタンスタイプのspotはホントに長期間(数日レベルで)買えない事があるので、2台構成の内1台はOnDemand(Reserved Instance)でサービス提供の担保を行いつつ、1台はspotを使い利用料金の低減を狙います。
spotインスタンスが買えない状態が続いた時にそのまま放置すると、冗長構成が取られず性能的にも1台でサービス提供している事になりますので、この部分へのケアとして以下の課題が出てきます。
- spotインスタンスがどうしても購入できず起動できない時は、これを検知してOnDemandインスタンスを起動して台数補填する。
- OnDemandインスタンスで台数補填され冗長構成の台数が足りている時でも、spotインスタンスの起動試行は続けて、起動に成功した時にはこれを検知し余剰なOnDemandインスタンスを破棄する
構想
ポイントはやはりspotインスタンスの購入状況に応じて自動でOnDemandを追加/削除させる制御部分になります。最初はASGの状況拾ってmixed instanceのOnDemand台数とmax台数を+1したり-1したりするlambdaでも書こうかと思っていたのですが、以下のやり方でよりシンプルに実現できそうに思いました。
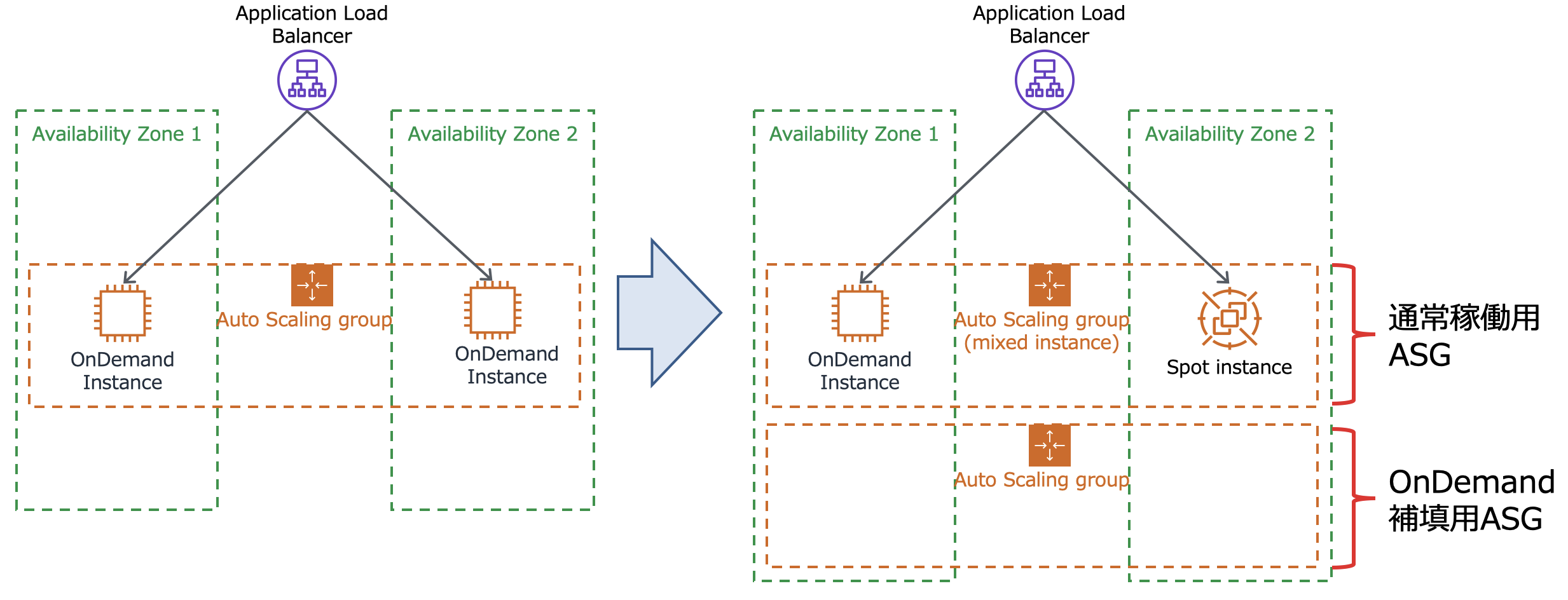
通常ではALB配下に一つのASGで実装する所を、ALB配下に以下の様な2つのASGを実装します
- 通常稼働用 OnDemand x1台 ,spot x1台 計2台で動作するのMixed Instance ASG
- OnDemand補填用 OnDemand 100% 通常0台
spotインスタンスが問題無く買えている場合は上記の形で動作しますが、spotインスタンスが買えない場合にOnDemand補填用のASGが必要な台数起動する様にしたい。
ということで OnDemand補填用ASGには、通常稼働用ASGの台数を用いたステップスケーリングの条件を設定します。
- 通常稼働用ASGの台数(GroupInServiceInstances)が 0以上1未満の時 ondemand補填用の希望台数を2 に設定
- 通常稼働用ASGの台数(GroupInServiceInstances)が 1以上2未満の時 ondemand補填用の希望台数を1 に設定
- 通常稼働用ASGの台数(GroupInServiceInstances)が 2以上時 ondemand補填用の希望台数を0 に設定
という具合です。(今回通常稼働用ASGはOnDemandが必ず1台存在するので、1.のルールは厳密には不要です。)
オートスケール条件の実行についてはCloudWatchアラームを発火させる必要がありますので、常にAlert状態であるアラームを作成します。条件は正直何でも良いのですが、私はなんとなく
- 通常稼働用ASGの台数(GroupInServiceInstances)が0以上である ことを条件としたアラーム
を作っています。常に発火状態なのでピリオド毎にOnDemand補填用ASGのスケール条件が評価されることになります。
このOnDemand補填側のスケール条件により、通常稼働側のASGでspotが買えず1台構成になってる時はOnDemandインスタンスが補填され、spotが買えて通常可動側が2台構成になった時にはOnDemandインスタンスの補填が破棄される、という求めた動作が実現されます。
実装
CloudFormationで以下の様に実装しました。(記事掲載のために必要な所だけ抽出して、一部手で書き換えたCFnテンプレートなので、このまま流せる物ではありません。。。御容赦ください。)
ASG:
Type: 'AWS::AutoScaling::AutoScalingGroup'
Properties:
AutoScalingGroupName: "ASG-MixedInstance"
AvailabilityZones:
- ap-northeast-1a
- ap-northeast-1c
MinSize: 2
MaxSize: 2
DesiredCapacity: 2
MixedInstancesPolicy:
InstancesDistribution:
OnDemandAllocationStrategy: prioritized
OnDemandBaseCapacity: 1
OnDemandPercentageAboveBaseCapacity: 0
SpotInstancePools: 1
LaunchTemplate:
LaunchTemplateSpecification:
LaunchTemplateId: !Ref 'LaunchTemplate'
Version: !GetAtt 'LaunchTemplate.LatestVersionNumber'
Overrides:
- InstanceType: "g4dn.2xlarge"
- InstanceType: "g3s.xlarge"
- InstanceType: "g3.4xlarge"
- InstanceType: "g3.8xlarge"
HealthCheckGracePeriod: '600'
HealthCheckType: ELB
TargetGroupARNs:
- !Ref TargetGroup1
- !Ref TargetGroup2
Cooldown: '300'
VPCZoneIdentifier:
- !Ref 'SubnetA'
- !Ref 'SubnetC'
MetricsCollection:
- Granularity: 1Minute
ASGOnDemand:
Type: 'AWS::AutoScaling::AutoScalingGroup'
Properties:
AutoScalingGroupName: "ASG-OnDemand"
AvailabilityZones:
- ap-northeast-1a
- ap-northeast-1c
MinSize: 0
MaxSize: 2
DesiredCapacity: 0
MixedInstancesPolicy:
InstancesDistribution:
OnDemandAllocationStrategy: prioritized
OnDemandBaseCapacity: 0
OnDemandPercentageAboveBaseCapacity: 100
SpotInstancePools: 1
LaunchTemplate:
LaunchTemplateSpecification:
LaunchTemplateId: !Ref 'LaunchTemplate'
Version: !GetAtt 'LaunchTemplate.LatestVersionNumber'
Overrides:
- InstanceType: "g4dn.2xlarge"
- InstanceType: "g3s.xlarge"
- InstanceType: "g3.4xlarge"
- InstanceType: "g3.8xlarge"
HealthCheckGracePeriod: '600'
HealthCheckType: ELB
TargetGroupARNs:
- !Ref TargetGroup1
- !Ref TargetGroup2
Cooldown: '300'
VPCZoneIdentifier:
- !Ref 'SubnetA'
- !Ref 'SubnetC'
MetricsCollection:
- Granularity: 1Minute
ASGOnDemandStepScalingPolicy:
Type: AWS::AutoScaling::ScalingPolicy
Properties:
AdjustmentType: ExactCapacity
PolicyType: "StepScaling"
AutoScalingGroupName: !Ref ASGOnDemand
MetricAggregationType: "Maximum"
StepAdjustments:
-
MetricIntervalLowerBound: "0"
MetricIntervalUpperBound: "1"
ScalingAdjustment: "2"
-
MetricIntervalLowerBound: "1"
MetricIntervalUpperBound: "2"
ScalingAdjustment: "1"
-
MetricIntervalLowerBound: "2"
ScalingAdjustment: "0"
ASGMissigMinimumCapacityAlarm:
Type: AWS::CloudWatch::Alarm
Properties:
EvaluationPeriods: '3'
Statistic: 'Maximum'
Threshold: '0'
AlarmName: "ASGOnDemandCapacity"
AlarmDescription: '[INFO] 規定台数を下回った場合にOnDemandインスタンスを起動するための物'
Period: '60'
AlarmActions:
- !Ref ASGOnDemandStepScalingPolicy
Namespace: AWS/AutoScaling
Dimensions:
- Name: AutoScalingGroupName
Value: !Ref ASG
ComparisonOperator: GreaterThanOrEqualToThreshold
MetricName: GroupInServiceInstances
実際の動作
とある日の実際の商用環境の様子をお見せします。
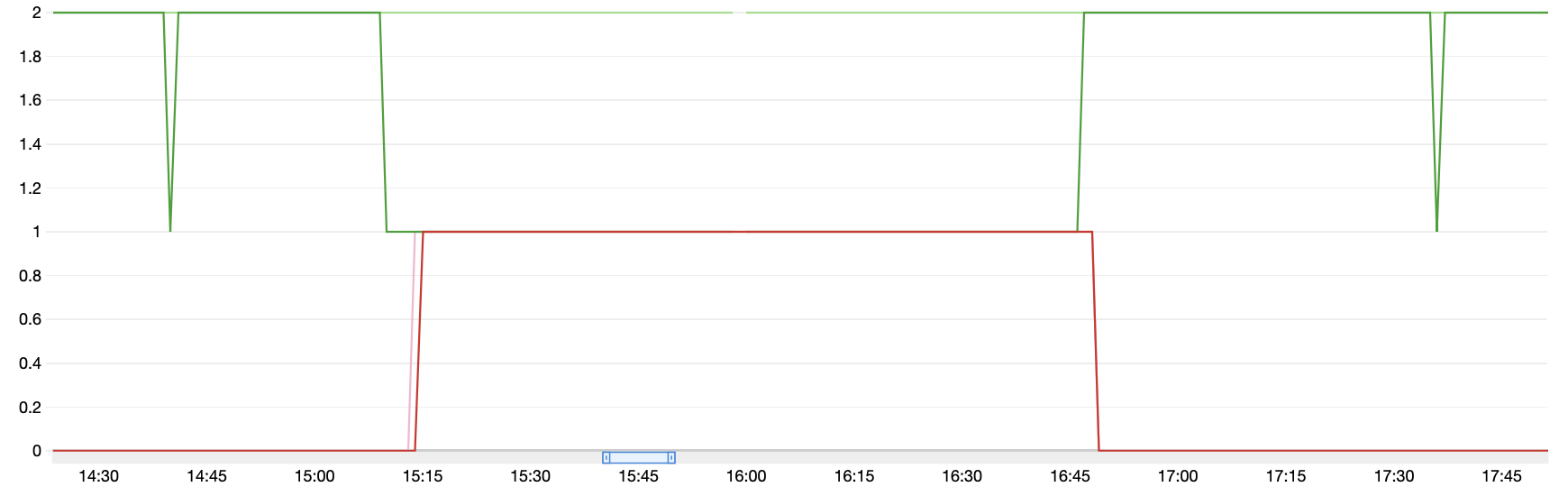
黄緑 … 通常稼働ASGの希望台数(Group Desired Capacity) これは常に2です
緑 … 通常稼働ASGの稼働台数(Group InService Instances)
ピンク … OnDemand補填用ASGの希望台数(Group Desired Capacity)
赤 … OnDemand補填用ASGの稼働台数(Group InService Instances)
緑の線が1になった時(=spotが落とされてその後購入できない時)、ピンクや赤の線が0から1に変わっていますので、冗長構成に足りない台数をOnDemandで補填してくれている事がわかります。
この時は15:15-16:45までの約1時間半、片系運転にならざるを得なかった所を自律的にOnDemandが起動して冗長構成と2台分の性能を維持してくれていた、と考えると大変心強い気がします。
また、グラフの左右にある緑のマイナスのスパイクですが、これはspotインスタンスが落とされたがすぐ次のspotインスタンスが起動できた状態を示しています。この時、OnDemand補填ASG側の動きはありません。地味ですが過敏に反応しないのは嬉しい所です(恐らくアラーム設定の EvaluationPeriods: '3' が効いているのですが、アラーム条件の評価は毎ピリオドで行われているはずなので、もう少し試験して確かめたい所。。)
実際の商用環境ではこんな冗長構成が沢山沢山動作しており、積極的なspot利用とOnDemandでのリカバーを自律で切替えながらサービス提供しています。
実装した効果
この実装を行った結果、コスト的にどの程度下がったのか?という所ですが、あまり具体的な話はできないので、恐縮ですがざっくりと。
2台構成を両方ともreserved instanceにした場合に比べて、この仕組を活用した事で10%以上安く運用できています。
reserved instance x2台構成の金額を (100% + 100%)/2 = 100% とすると
今回の構成の机上計算の期待値は
reserved x1台 + spot x1台の構成なので (100% + 38%)/2 = 69% です
(あくまで、一番軽いインスタンスがspotで買え続けた場合の机上値。38%というのはAWSのEC2料金ページの値で算出しています)
で、実際にここ3ヶ月のデータを取ってみると
reserved x1台 + 「spot1台または補填用OnDemand1台」 の構成で (100% + 75.1%)/2 = 87.6% という結果でした。
「spot1台または補填用OnDemand1台」の部分を1ヶ月単位で見ると、最小で42.2% 最大で99.6%でした。
spotの買えなさ具合では100%超える事がありそうなので、これが頻発する様なら素直に2台ともreserved instanceにした方が良いという事になります。決して手放しで放置せず利用料金を注視しつつ、spotインスタンスの恩恵を受ける感じですね。
(ただ白状すると、reserved instanceの買い忘れが発覚した事があって、この時期と一部被っているので、余計なOnDemand料金が計算に入ってる(=実際はもう少し成績よい)かも。。。オチが弱くてすみません)
さいごに
余談ですが、私が担っているシステムは多くがAWS上で動作しており、この事からAWSの方にいろいろ相談させて頂く機会があります。今回の方式でspotインスタンスを活用して運用している事をお伝えした時に、どこから情報入手されました?とえらく驚かれていた事を覚えています。なんでも今回の方式は、当時AWS社内のblogで海外のAWSエンジニアが、少ない台数を担保する環境でspotインスタンスを使う時のベストプラクティスとして社内公開したばかりの方式だったそうです。
私の方ではコスト低減に悶絶する中で思いついて半年以上前に商用実装した方式である事伝えたのでした。。。
これからも技術やアイディアを駆使して、より良い機能をスピーディーに低コストでお客様に届けられると良いなと思っています。
明日は@okd46 がデータ分析に関する何かを書いてくれるそうです!