この記事では、animeface-characterデータセットを使ってIllustration2VecモデルをFine-tuningし、146種類のキャラクター顔画像を90%以上の精度で分類できるモデルを訓練する手順を追いながら、以下のことを説明します。
Chainerを使って
- データセットオブジェクトを作る方法
- データセットを訓練用・検証用に分割する方法
- 訓練済み重みを持ってきて新しいタスクでFine-tuningする方法
- (おまけ:データセットクラスをフルスクラッチで書く方法)
使用した環境は以下です。
- NVIDIA Pascal TITAN X
- Ubuntu 16.04
- Python 3.6.3
使用したライブラリは以下です。
- Chainer >=2.0.1 (最新の4.1.0でも動作確認済み)
- CuPy >= 1.0.1 (最新の4.1.0でも動作確認済み)
- Pillow 4.0.0
- tqdm 4.14.0
Chainerは後方互換性が
ざっくり内容をまとめると
Chainerに予め用意されていないデータセットを外部から調達して、Chainerで記述されたネットワークの訓練のために用いる方法を具体例をもって示します。基本的な手順はほぼChainer v4: ビギナー向けチュートリアルで説明したCIFAR10データセットクラスを拡張する章と変わりません。
今回は、ターゲットとなるデータと似たドメインのデータセットを用いて予め訓練されたネットワーク重みを初期値として用いる方法を説明します。Caffeの.caffemodelの形で配布されているネットワークをFine-tuningしたい場合、この記事とほぼ同様の手順が適用できると思います。
この記事はもともとJupyter notebookで書いたものをMarkdownに出力したものです。
1. データセットのダウンロード
まずは、データセットをダウンロードしてきます。今回は、Kaggle Grand Masterであらせられるnagadomiさんがこちらで配布されているアニメキャラクターの顔領域サムネイルデータセットを使用します。
%%bash
if [ ! -d animeface-character-dataset ]; then
curl -L -O http://www.nurs.or.jp/~nagadomi/animeface-character-dataset/data/animeface-character-dataset.zip
unzip animeface-character-dataset.zip
rm -rf animeface-character-dataset.zip
fi
使用するライブラリをpipで入れます。cupy-cuda90の部分は、お使いの環境のCUDAバージョンに合わせてcupy-cuda80(CUDA8.0環境向け), cupy-cuda90(CUDA9.0環境向け), cupy-cuda91(CUDA9.1環境向け)から適したものを選択してください。)
%%bash
pip install chainer
pip install cupy-cuda80 # or cupy-cuda90 or cupy-cuda91
pip install Pillow
pip install tqdm
2. 問題設定の確認
今回は、animeface-character-datasetに含まれる様々なキャラクターの顔画像を用いて、未知のキャラクター顔画像が入力された際に、それが既知のクラス一覧の中のどのキャラクターの顔らしいかを出力するようなネットワークを訓練したいと思います。
その際に、ランダムにパラメータを初期化したネットワークを訓練するのではなく、予め似たドメインのデータで訓練済みのモデルをベースに、目的のデータセットでFine-tuningするというやり方をしてみます。
今回学習に用いるデータセットは、以下のような画像を多数含むデータセットで、各キャラクターごとに予めフォルダ分けがされています。なので、今回もオーソドックスな画像分類問題となります。
適当に抜き出したデータサンプル
| 000_hatsune_miku | 002_suzumiya_haruhi | 007_nagato_yuki | 012_asahina_mikuru |
|---|---|---|---|
 |
 |
 |
 |
3. データセットオブジェクトの作成
ここでは、画像分類の問題でよく使われるLabeledImageDatasetというクラスを使ったデータセットオブジェクトの作成方法を示します。まずは、Python標準の機能を使って下準備をします。
初めに画像ファイルへのパス一覧を取得します。画像ファイルは、animeface-character-dataset/thumb以下にキャラクターごとのディレクトリに分けられて入っています。下記のコードでは、フォルダ内にignoreというファイルが入っている場合は、そのフォルダの画像は無視するようにしています。
import os
import glob
from itertools import chain
# 画像フォルダ
IMG_DIR = 'animeface-character-dataset/thumb'
# 各キャラクターごとのフォルダ
dnames = glob.glob('{}/*'.format(IMG_DIR))
# 画像ファイルパス一覧
fnames = [glob.glob('{}/*.png'.format(d)) for d in dnames
if not os.path.exists('{}/ignore'.format(d))]
fnames = list(chain.from_iterable(fnames))
次に、画像ファイルパスのうち画像が含まれるディレクトリ名の部分がキャラクター名を表しているので、それを使って各画像にキャラクターごとに一意になるようなIDを作ります。
# それぞれにフォルダ名から一意なIDを付与
labels = [os.path.basename(os.path.dirname(fn)) for fn in fnames]
dnames = [os.path.basename(d) for d in dnames
if not os.path.exists('{}/ignore'.format(d))]
labels = [dnames.index(l) for l in labels]
では、ベースとなるデータセットオブジェクトを作ります。やり方は簡単で、ファイルパスとそのラベルが並んだタプルのリストをLabeledImageDatasetに渡せば良いだけです。これは (img, label) のようなタプルを返すイテレータになっています。
from chainer.datasets import LabeledImageDataset
# データセット作成
d = LabeledImageDataset(list(zip(fnames, labels)))
次に、Chainerが提供しているTransformDatasetという便利な機能を使ってみます。これは、データセットオブジェクトと各データへの変換を表す関数を取るラッパークラスで、これを使うとdata augmentationや前処理などを行う部分をデータセットクラスの外に用意しておくことができます。
from chainer.datasets import TransformDataset
from PIL import Image
width, height = 160, 160
# 画像のresize関数
def resize(img):
img = Image.fromarray(img.transpose(1, 2, 0))
img = img.resize((width, height), Image.BICUBIC)
return np.asarray(img).transpose(2, 0, 1)
# 各データに行う変換
def transform(inputs):
img, label = inputs
img = img[:3, ...]
img = resize(img.astype(np.uint8))
img = img - mean[:, None, None]
img = img.astype(np.float32)
# ランダムに左右反転
if np.random.rand() > 0.5:
img = img[..., ::-1]
return img, label
# 変換付きデータセットにする
td = TransformDataset(d, transform)
こうすることで、LabeledImageDatasetオブジェクトであるdが返す (img, label) のようなタプルを受け取って、それをtransform関数にくぐらせてから返すようなデータセットオブジェクトが作れました。
では、これを学習用と検証用の2つの部分データセットにsplitしましょう。今回は、データセット全体のうち80%を学習用に、残り20%を検証用に使うことにします。split_dataset_randomを使うと、データセット内のデータを一度シャッフルしたのちに、指定した区切り目で分割したものを返してくれます。
from chainer import datasets
train, valid = datasets.split_dataset_random(td, int(len(d) * 0.8), seed=0)
データセットの分割は他にも、交差検定をするための複数の互いに異なる訓練・検証用データセットペアを返すようなget_cross_validation_datasets_randomなど、いくつかの関数が用意されています。こちらをご覧ください。:SubDataset
さて、変換の中で使っているmeanは、今回使う学習用データセットに含まれる画像の平均画像です。これを計算しておきましょう。
import matplotlib.pyplot as plt
import numpy as np
from tqdm import tqdm_notebook
# 平均画像が未計算なら計算する
if not os.path.exists('image_mean.npy'):
# 変換をかまさないバージョンの学習用データセットで平均を計算したい
t, _ = datasets.split_dataset_random(d, int(len(d) * 0.8), seed=0)
mean = np.zeros((3, height, width))
for img, _ in tqdm_notebook(t, desc='Calc mean'):
img = resize(img[:3].astype(np.uint8))
mean += img
mean = mean / float(len(d))
np.save('image_mean', mean)
else:
mean = np.load('image_mean.npy')
試しに計算した平均画像を表示してみましょう。
# 平均画像の表示
%matplotlib inline
plt.imshow(mean.transpose(1, 2, 0) / 255)
plt.show()

なんか怖いですね…
各画像から平均を引くときはピクセルごとの平均を使うので、この平均画像の平均画素値(RGB)を計算しておきます。
mean = mean.mean(axis=(1, 2))
4. モデルの定義とFine-tuningの準備
では次に、訓練を行うモデルの定義を行います。ここではたくさんの2Dイラスト画像を使って学習したモデルでタグ予測や特徴抽出などを行うIllustration2Vecで使われたネットワークをベースとし、その最後の2層を削除してランダムに初期化された2つの全結合層を付け加えたものを新しいモデルとします。
学習時には、Illustration2Vecのpre-trained weightで出力から3層目以下の部分を初期化したのち、その部分の重みは固定しておきます。つまり、新たに追加した2つの全結合層だけを訓練します。
まず、配布されているIllustration2Vecモデルの訓練済みパラメータをダウンロードしてきます。
%%bash
if [ ! -f illust2vec_ver200.caffemodel ]; then
curl -L -O https://github.com/rezoo/illustration2vec/releases/download/v2.0.0/illust2vec_ver200.caffemodel
fi
この訓練済みパラメータはcaffemodelの形式で提供されていますが、Chainerには非常に簡単にCaffeの訓練済みモデルを読み込む機能(CaffeFunction)があるので、これを使ってパラメータとモデル構造をロードします。ただし、読み込みには時間がかかるため、一度読み込んだ際に得られるChainオブジェクトをPython標準のpickleを使ってファイルに保存しておきます。こうすることで次回からの読み込みが速くなります。
実際のネットワークのコードは以下のようになります。
import dill
import chainer
import chainer.links as L
import chainer.functions as F
from chainer import Chain
from chainer.links.caffe import CaffeFunction
from chainer import serializers
class Illust2Vec(Chain):
CAFFEMODEL_FN = 'illust2vec_ver200.caffemodel'
def __init__(self, n_classes, unchain=True):
w = chainer.initializers.HeNormal()
model = CaffeFunction(self.CAFFEMODEL_FN) # CaffeModelを読み込んで保存します。(時間がかかります)
del model.encode1 # メモリ節約のため不要なレイヤを削除します。
del model.encode2
del model.forwards['encode1']
del model.forwards['encode2']
model.layers = model.layers[:-2]
super(Illust2Vec, self).__init__()
with self.init_scope():
self.trunk = model # 元のIllust2Vecモデルをtrunkとしてこのモデルに含めます。
self.fc7 = L.Linear(None, 4096, initialW=w)
self.bn7 = L.BatchNormalization(4096)
self.fc8 = L.Linear(4096, n_classes, initialW=w)
def __call__(self, x):
h = self.trunk({'data': x}, ['conv6_3'])[0] # 元のIllust2Vecモデルのconv6_3の出力を取り出します。
h.unchain_backward()
h = F.dropout(F.relu(self.bn7(self.fc7(h)))) # ここ以降は新しく追加した層です。
return self.fc8(h)
n_classes = len(dnames)
model = Illust2Vec(n_classes)
model = L.Classifier(model)
/home/mitmul/chainer/chainer/links/caffe/caffe_function.py:165: UserWarning: Skip the layer "encode1neuron", since CaffeFunction does notsupport Sigmoid layer
'support %s layer' % (layer.name, layer.type))
/home/mitmul/chainer/chainer/links/caffe/caffe_function.py:165: UserWarning: Skip the layer "loss", since CaffeFunction does notsupport SigmoidCrossEntropyLoss layer
'support %s layer' % (layer.name, layer.type))
__call__の部分にh.unchain_backward()という記述が登場しました。unchain_backwardは、ネットワークのある中間出力Variable などから呼ばれ、その時点より前のあらゆるネットワークノードの接続を断ち切ります。そのため、学習時にはこれが呼ばれた時点より前の層に誤差が伝わらなくなり、結果としてパラメータの更新も行われなくなります。
前述の
学習時には、Illustration2Vecのpre-trained weightで出力から3層目以下の部分を初期化したのち、その部分の重みは固定しておきます。
これを行うためのコードが、このh.unchain_backward()です。
このあたりの仕組みについて、さらに詳しくは、Define-by-RunによるChainerのautogradの仕組みを説明しているこちらの記事を参照してください。: 1-file Chainerを作る
5. 学習
それでは、このデータセットとモデルを用いて、学習を行ってみます。まず必要なモジュールをロードしておきます。
from chainer import iterators
from chainer import training
from chainer import optimizers
from chainer.training import extensions
from chainer.training import triggers
from chainer.dataset import concat_examples
次に学習のパラメータを設定します。今回は
- バッチサイズ64
- 学習率は0.01からスタートし、10エポック目で0.1倍にする
- 20エポックで学習終了
とします。
batchsize = 64
gpu_id = 0
initial_lr = 0.01
lr_drop_epoch = 10
lr_drop_ratio = 0.1
train_epoch = 20
以下が学習を行うコードです。
train_iter = iterators.MultiprocessIterator(train, batchsize)
valid_iter = iterators.MultiprocessIterator(
valid, batchsize, repeat=False, shuffle=False)
optimizer = optimizers.MomentumSGD(lr=initial_lr)
optimizer.setup(model)
optimizer.add_hook(chainer.optimizer.WeightDecay(0.0001))
updater = training.StandardUpdater(
train_iter, optimizer, device=gpu_id)
trainer = training.Trainer(updater, (train_epoch, 'epoch'), out='AnimeFace-result')
trainer.extend(extensions.LogReport())
trainer.extend(extensions.observe_lr())
# 標準出力に書き出したい値
trainer.extend(extensions.PrintReport(
['epoch',
'main/loss',
'main/accuracy',
'val/main/loss',
'val/main/accuracy',
'elapsed_time',
'lr']))
# ロスのプロットを毎エポック自動的に保存
trainer.extend(extensions.PlotReport(
['main/loss',
'val/main/loss'],
'epoch', file_name='loss.png'))
# 精度のプロットも毎エポック自動的に保存
trainer.extend(extensions.PlotReport(
['main/accuracy',
'val/main/accuracy'],
'epoch', file_name='accuracy.png'))
# モデルのtrainプロパティをFalseに設定してvalidationするextension
trainer.extend(extensions.Evaluator(valid_iter, model, device=gpu_id), name='val')
# 指定したエポックごとに学習率をlr_drop_ratio倍にする
trainer.extend(
extensions.ExponentialShift('lr', lr_drop_ratio),
trigger=(lr_drop_epoch, 'epoch'))
trainer.run()
epoch main/loss main/accuracy val/main/loss val/main/accuracy elapsed_time lr
1 1.58266 0.621792 0.623695 0.831607 29.4045 0.01
2 0.579938 0.835989 0.54294 0.85179 56.3893 0.01
3 0.421797 0.877897 0.476766 0.876872 83.9976 0.01
4 0.3099 0.909251 0.438246 0.879637 113.476 0.01
5 0.244549 0.928394 0.427892 0.884571 142.931 0.01
6 0.198274 0.938638 0.41589 0.893617 172.42 0.01
7 0.171127 0.946709 0.432277 0.89115 201.868 0.01
8 0.146401 0.953125 0.394634 0.902549 231.333 0.01
9 0.12377 0.964404 0.409338 0.894667 260.8 0.01
10 0.109239 0.967198 0.400371 0.907746 290.29 0.01
11 0.0948708 0.971337 0.378603 0.908831 319.742 0.001
12 0.0709512 0.98065 0.380891 0.90786 349.242 0.001
13 0.0699093 0.981892 0.384257 0.90457 379.944 0.001
14 0.0645318 0.982099 0.370053 0.908008 410.963 0.001
15 0.0619039 0.983547 0.379178 0.908008 441.941 0.001
16 0.0596897 0.983646 0.375837 0.911709 472.832 0.001
17 0.0579783 0.984789 0.379593 0.908008 503.836 0.001
18 0.0611943 0.982202 0.378177 0.90842 534.86 0.001
19 0.061885 0.98303 0.373961 0.90569 565.831 0.001
20 0.0548781 0.986341 0.3698 0.910624 596.847 0.001
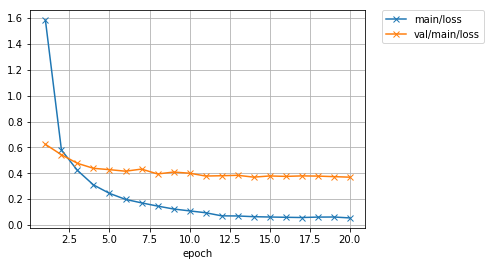
6分弱くらいで学習が終わりました。標準出力に出る途中経過は上記のような感じでした。最終的に検証用データセットに対しても90%以上のaccuracyが出せていますね。では、画像ファイルとして保存されている学習経過でのロスカーブとaccuracyのカーブを表示してみます。
from IPython.display import Image
Image(filename='AnimeFace-result/loss.png')
Image(filename='AnimeFace-result/accuracy.png')
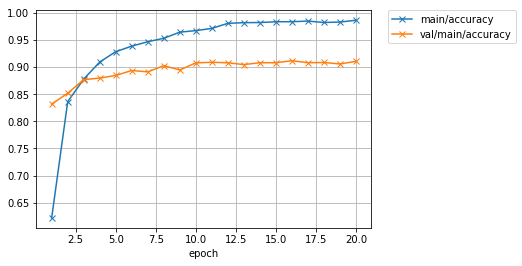
無事収束している感じがします。
最後に、いくつかvalidationデータセットから画像を取り出してきて個別の分類結果を見てみます。
%matplotlib inline
import matplotlib.pyplot as plt
from PIL import Image
from chainer import cuda
chainer.config.train = False
for _ in range(10):
x, t = valid[np.random.randint(len(valid))]
x = cuda.to_gpu(x)
y = F.softmax(model.predictor(x[None, ...]))
pred = os.path.basename(dnames[int(y.data.argmax())])
label = os.path.basename(dnames[t])
print('pred:', pred, 'label:', label, pred == label)
x = cuda.to_cpu(x)
x += mean[:, None, None]
x = x / 256
x = np.clip(x, 0, 1)
plt.imshow(x.transpose(1, 2, 0))
plt.show()
pred: 097_kamikita_komari label: 097_kamikita_komari True

pred: 127_setsuna_f_seiei label: 127_setsuna_f_seiei True

pred: 171_ikari_shinji label: 171_ikari_shinji True

pred: 042_tsukimura_mayu label: 042_tsukimura_mayu True

pred: 001_kinomoto_sakura label: 001_kinomoto_sakura True

pred: 090_minase_iori label: 090_minase_iori True

pred: 132_minamoto_chizuru label: 132_minamoto_chizuru True

pred: 106_nia label: 106_nia True

pred: 174_hayama_mizuki label: 174_hayama_mizuki True

pred: 184_suzumiya_akane label: 184_suzumiya_akane True

ランダムに10枚選んでみたところこの画像たちに対しては全て正解できました。
最後に、いつか何かに使うかもしれないので、一応snapshotを保存しておきます。
from chainer import serializers
serializers.save_npz('animeface.model', model)
6. おまけ1:データセットクラスをフルスクラッチで書く方法
データセットクラスをフルスクラッチで書くには、chainer.dataset.DatasetMixinクラスを継承した自前クラスを用意すれば良いです。そのクラスは__len__メソッドとget_exampleメソッドを持つ必要があります。例えば以下のようになります。
class MyDataset(chainer.dataset.DatasetMixin):
def __init__(self, image_paths, labels):
self.image_paths = image_paths
self.labels = labels
def __len__(self):
return len(self.image_paths)
def get_example(self, i):
img = Image.open(self.image_paths[i])
img = np.asarray(img, dtype=np.float32)
img = img.transpose(2, 0, 1)
label = self.labels[i]
return img, label
これは、コンストラクタに画像ファイルパスのリストと、それに対応した順番でラベルを並べたリストを渡しておき、[]アクセサでインデックスを指定すると、対応するパスから画像を読み込んで、ラベルと並べたタプルを返すデータセットクラスになっています。例えば、以下のように使えます。
image_files = ['images/hoge_0_1.png', 'images/hoge_5_1.png', 'images/hoge_2_1.png', 'images/hoge_3_1.png', ...]
labels = [0, 5, 2, 3, ...]
dataset = MyDataset(image_files, labels)
img, label = dataset[2]
# => 'images/hoge_2_1.png'から読み込まれた画像データと、そのラベル(ここでは2)が返る
このオブジェクトは、そのままIteratorに渡すことができ、Trainerを使った学習に使えます。つまり、
train_iter = iterators.MultiprocessIterator(dataset, batchsize=128)
のようにしてイテレータを作って、UpdaterにOptimizerと一緒に渡し、そのupdaterをTrainerに渡せばTrainerを使って学習を開始できます。
7. おまけ2:最もシンプルなデータセットオブジェクトの作り方
実はChainerのTrainerと一緒に使うためのデータセットは、単なるPythonのリストでOKです。どういうことかというと、len()で長さが取得でき、[]アクセサで要素が取り出せるものなら、全てデータセットオブジェクトとして扱う事ができるということです。例えば、
data_list = [(x1, t1), (x2, t2), ...]
のような(データ, ラベル)というタプルのリストを作れば、これをIteratorに渡すことができます。
train_iter = iterators.MultiprocessIterator(data_list, batchsize=128)
ただこういったやりかたの欠点は、データセット全体を学習前にメモリに載せなければいけない点です。これを防ぐために、ImageDatasetとTupleDatasetを組み合わせる方法やLabaledImageDatasetといったクラスが用意されています。詳しくはドキュメントをご参照ください。
http://docs.chainer.org/en/stable/reference/datasets.html#general-datasets