(2026/1/9追記)
以下の内容は、seleniumのアップデートに伴いoutdatedになってしまっており、コードもそのままでは動かない状態になっています。すみませんが、直近の他のエントリを参照して頂いた方が良いかもしれません。
0 モチベーション
本稿は、スクレイピング初心者のPython使いを対象として書きました。筆者自身もスクレイピングの知識が不十分なところもあるかと思いますので、何かあればご指摘いただければと思います…。
スクレイピングに用いるモジュールとしては、urllibやbeautifulsoupなどがありますが、これらのモジュールでは動的なサイト(airbnbなど検索機能を用いたりする、javascriptなどを用いて構築されたサイト)は取得できません。
これらの動的なサイトのスクレイピングにはSeleniumが有用です。Seleniumは本来ウェブアプリケーションのテストのために開発されたソフトウェアであり、人間が実際にウェブを見る際の操作を模してくれるので、原理的にはどのようなサイトでもスクレイピング可能となります。
全体の手順の流れとしては、
モジュールのインポート⇒ ウィンドウを開く⇒ スクレイピング要素の取得⇒ 要素からテキストの取得
となっており、その他付随して必要な操作も以下に追記します。
なお、環境は、Windows、Pythonを想定して、chromeを使ってスクレイピングします。
1 インストール・インポート
インストールは
pip install selenium
によって行い、seleniumのスクレイピングに必要なモジュールは下記のようにインポートします。
- webdriver:ブラウザを作動させる
from selenium import webdriver - options:ブラウザ閲覧時のオプション編集、ウィンドウサイズ設定等を行う
from selenium.webdriver.chrome.options import Options - keys:キー入力操作を行う
from selenium.webdriver.common.keys import Keys
2 ウィンドウを開く
次はブラウザのウィンドウを開きます。このとき、閲覧時のオプションとウェブドライバの所在パスを指定します。(オプションは任意)
オプション・パスは下記のように指定します。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
# ブラウザ閲覧時のオプションを指定するオブジェクト"options"を作成
options= Options()
# 必要に応じてオプションを追加
options.add_argument('...')
# ドライバのpathを指定
path = 'C:/.../chromedriver'
# ブラウザのウィンドウを表すオブジェクト"driver"を作成
driver = webdriver.Chrome(executable_path=path, chrome_options=options)
driver.get(url)
オプション
オプションとしては以下のようなものを用いたりします。
- headless:ブラウザを非表示のまま起動
options.add_argument('--headless') - images Enabled=false:ブラウザの画像を非表示にする
options.add_argument('--blink-settings=imagesEnabled=false') - windowsize=...:ウィンドウサイズを指定
options.add_argument('--window-size=1024,768')
参考:https://chida09.com/selenium-chrome-option/
path
下記リンクからchromedriverをインストールして格納、そのパスを指定します。
http://chromedriver.chromium.org/downloads
その他操作
ウィンドウを開く際は
driver.get(url)
ウィンドウを閉じる際は
driver.quit()
と操作します。
コード例
airbnbのサイトをwindowサイズ(1024,768)、画像非表示で開いてみます。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
# cromedriverの所在パス
path = 'C:/.../chromedriver'
options.add_argument('--window-size=1024,768')
options.add_argument('--blink-settings=imagesEnabled=false')
driver = webdriver.Chrome(executable_path=path, chrome_options=options)
url = 'https://www.airbnb.jp'
driver.get(url)
3 スクレイピング要素の取得(xpathで取得)
指定したurlを開いた後、アクティブウィンドウに表示されているサイトの要素をスクレイピングすることができます。ここでは、最も有用と思われるxpathを用いた取得方法を中心に述べます。
xpathの取得方法
スクレイピングしたいサイトをchromeで開き、取得したいブラウザ上の場所を右クリックして「検証(I)」を選択します。
すると、画面の右側にHTMLソースが表示されます。青掛けで表示されるHTMLのコードをさらに右クリックし、
「Copy」⇒「Copy Xpath」を選択すると、該当箇所のxpathがコピーされた状態になります。
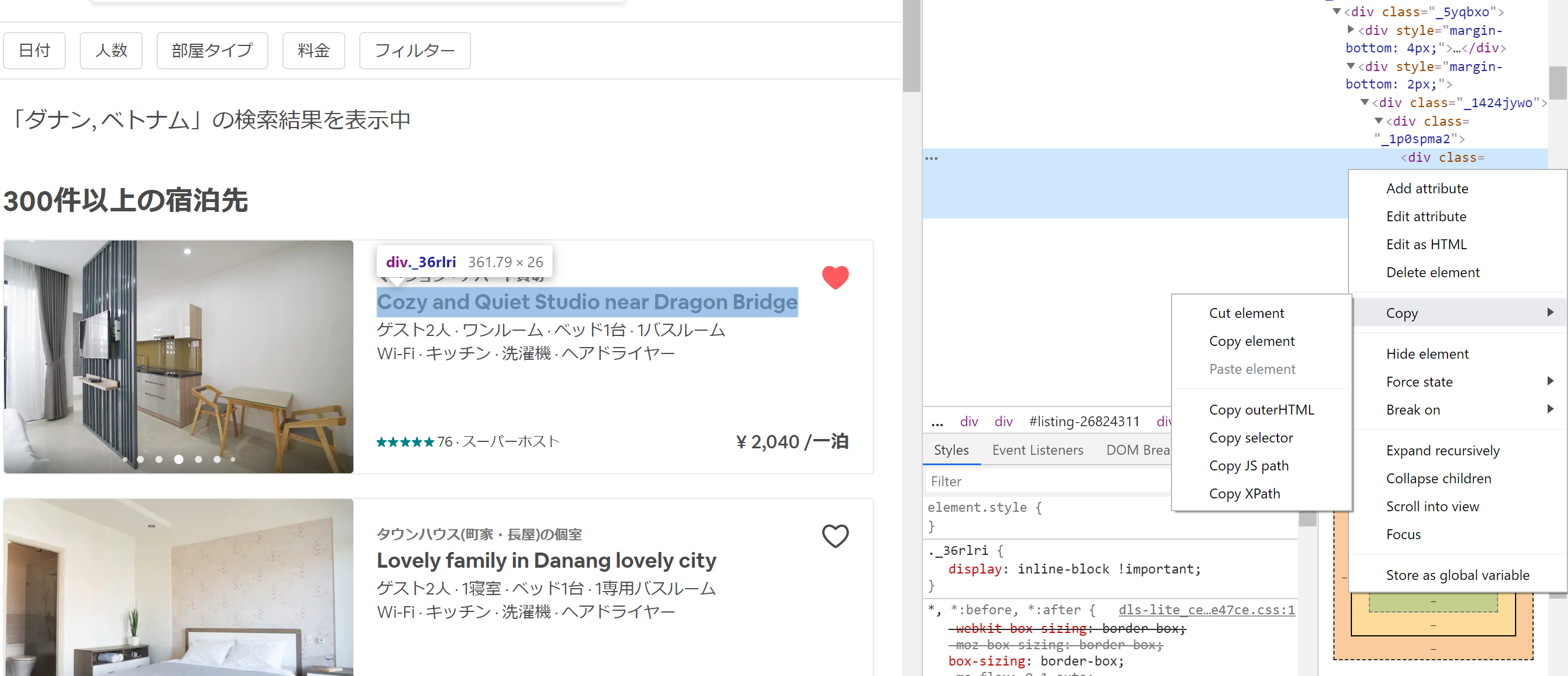
xpathの構造
例えば、xpathは下記のような構造をしており、
//*[@id="listing-XXXXXXX"]/div/div[2]/div/span/a/div[1]/div[2]/div/div/div
/ごとに階層が分かれており、HTMLタグの種類が表示され、[]内の数字はそのタグを持つものの中で何番目の要素かということを示します。
xpathを用いた検索方法
driver.find_elements_by_xpath("(上記のxpath)")
とすれば、求めるxpathの条件に適合する要素がリストで取得されます。検索時には先ほど取得したxpathをコピペしても良いですし、[]の部分を省略したり、一部のxpathを省略したうえで検索条件と組み合わせて、サイトの変更に対して頑強になるようにしても良いと思います。
注:検索した要素はリストとして得られるので、その後は取得したリスト内の要素について操作を行います。
なお、find_element_by_xpathとすれば、適合する要素の1つ目が取得されます。
注:htmlの要素にはさまざまな属性が付与されており、その属性を用いて要素を検索することも可能です。例えば、find_element_by_idでidでの検索、find_element_by_class_nameでclass_nameでの検索も可能です。
注:xpathのタグ部分を*に変えれば、その階層の要素が何でも選択することができます。また、//を用いれば、それ以降のxpathが一致するすべてのxpathを検索することができます。
例://divとすれば、ページに含まれるすべてのdivタグの要素が検索されます。
//div/*とすれば、ページに含まれるすべてのdivタグの1階層下の要素が検索されます。
参考: https://qiita.com/mochio/items/dc9935ee607895420186 , https://webbibouroku.com/Blog/Article/xpath
その他、便利な要素の検索方法
xpathによる検索と下記のような条件検索を組み合わせて使うこともできます。
div[...]のように、タグの後ろに[(要素の満たす条件)]のように、追加条件を付記することができます。
-
テキストで検索
テキストが一致する:[text()="..."]
特定のテキストを含む:[contains(text(),"...")]
特定のテキストから始まる:[starts-with(text(),'')] -
id, class, name等html要素の属性で検索
上記のテキスト検索と同様に行うことができます。
idが一致する:[@id='...']
id内に特定の文字を含む:[contains(@id,"...")]
idが特定の文字から始まる:[starts-with(@id,"")] -
複数条件の組み合わせ
or や andを用いて、[]内の条件を組み合わせることもできます。
例:[@id="" and contains(text(),"")] -
親要素、子要素の取得
取得した要素の上の階層の要素、あるいは下の階層の要素をさらに取得することもできます。
elementA = driver.find_elements_by_xpath("")
(Aの)親要素の取得(点ふたつで親階層を表します)
elementB = elementA.find_elements_by_xpath("..")
(Aの)子要素の取得
elementC = elementA.find_elements_by_xpath("./...")
元要素からの相対パスを書けば子要素が取得できます。
参考:
seleniumでの要素の選択方法
https://qiita.com/VA_nakatsu/items/0095755dc48ad7e86e2f
containsなどのxml記法
https://webbibouroku.com/Blog/Article/xpath
コード例
spaceeの検索結果画面で、「最後」という文字を含むリンクの要素を取得します。
from selenium import webdriver
path = 'C:/.../chromedriver'
driver = webdriver.Chrome(executable_path=path)
url = 'https://www.spacee.jp/stations/1130208/listings'
# テキストに「最後」を含む要素を選択します。クォーテーションを"と'の2種類使わないと正しく動かないことに注意してください。(違う部分が囲まれていると認識してしまうので)
driver.get(url)
elements = driver.find_elements_by_xpath("//*[contains(text(),'最後')]")
element = elements[0]
4 スクレイピング要素からテキスト、属性の取得
選択した要素に下記の関数を作用させれば、要素のテキスト、属性が取得できます。
- テキスト:.text()
- 属性:get_attribute('')
例えば、上記のコードに
element.get_attribute('id')
とすれば要素のid属性が取得できます。
コード例
airbnbで「ベトナム」と検索した結果のリスティングのID、それに付随するテキストをいくつか取得しました。
このように途中のxpathを省略して//*[...]のように書くと、ソースの構造が若干変わった時でも影響を受けずに済みます。
from selenium import webdriver
path = 'C:/.../chromedriver'
driver = webdriver.Chrome(executable_path=path)
url = "https://www.airbnb.jp/s/homes?refinement_paths%5B%5D=%2Fhomes&query=ベトナム"
driver.get(url)
elements = driver.find_elements_by_xpath("//*[contains(@id,'listing-')]")
for element in elements:
print(element.get_attribute('id'))
print(element.text)
5 様々な操作
その他、seleniumでブラウザを操作するコマンドをまとめました。
-
windowサイズを変える
指定したサイズに変更:driver.set_window_size(1250, 1036)のようにする
最大サイズに変更:driver.maximize_window() -
ブラウザのズーム比率を設定
driver.execute_script("document.body.style.zoom='50%'")
("driver"は、上記で開いたウェブブラウザのウィンドウのオブジェクト名) -
スクロール
(スクロールして表示ないとクリックできないようなボタンもあるため、必要となる)
actions = ActionChains(driver)
actions.move_to_element(element).perform() -
クリック
element.click() -
フォームを入力
element.send_keys(place)
element.send_keys(Keys.ENTER) -
待機
何秒か明示的に待つ:time.sleep(3)
要素がロードされるまで待つ時間を指定:driver.implicitly_wait(10)
例:
driver.implicitly_wait(10) driver.get("https://google.co.jp/)
のようにすれば、指定したurlを表示するまでに10秒間待つようになります。
特定の条件を満たすまで待つ:WebdriverWait(driver, 10).until(EC.title_contains("Google"))
例(urlを開き、タイトルに"Google"を含むページが現れるまで待機):
from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC driver.get("https://www.google.co.jp") WebDriverWait(driver, 10).until(EC.title_contains("Google")) -
ブラウザ操作
戻る:driver.back()
リフレッシュ:driver.refresh()
参考:(様々な操作)https://qiita.com/mochio/items/dc9935ee607895420186
(待機)http://softwaretest.jp/labo/tech/labo-294/
https://a-zumi.net/python-selenium-wait-title-contains/
コード例
Googleでキーワードを検索します。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
path = 'C:/.../chromedriver'
driver = webdriver.Chrome(executable_path=path)
url = 'https://www.google.com'
driver.get(url)
element = driver.find_element_by_xpath("//*[@id='tsf']//input[@title='検索']")
element.send_keys('くま')
element.send_keys(Keys.ENTER)
コード例
airbnbのリスティングサイトでは、クリックしたいリンク先が画面内に表示されないとクリックできません。そのため、スクロールしてからクリックします。
from selenium.webdriver.common.action_chains import ActionChains
import time
path = 'C:/.../chromedriver'
driver = webdriver.Chrome(executable_path=path, chrome_options=options)
url = 'https://www.airbnb.jp/rooms/19740252?'
driver.get(url)
driver.maximize_window()
element = driver.find_element_by_xpath("//*[contains(text(),'このエリア情報の続きを読む')]")
time.sleep(3)
ActionChains(driver).move_to_element(element).perform()
# スクロールの微調整
driver.execute_script("window.scrollBy(0, 200);")
time.sleep(3)
element.click()
6 retryの方法
スクレイピングの際には、サイトが応答せずエラーが出てしまうことがあり、何度か読み込みをリトライしないといけないことがあります。(おそらくスクレイピング対策として一定割合でページが読み込まれないようになっているのではないかと思います)もしくは、何らかの理由で操作上のエラーが出てくるけれど、操作をストップさせたくないときなど、例外処理が必要になると思います。
そんな時のために、下記2通りでリトライを試してもらえればと思います。
retryモジュール
from retry import retry
としてモジュールをインポートしたうえで、サイトの読み込みを含む関数の前に@retry(tries=..., delay=...)を書き加えるだけです。triesは試行回数でdelayは待ち時間です。
@retry(tries=3,delay=5)
# ページ読み込みを含んだ関数の定義
def readpage():
...
driver.get(url)
...
try-except
要素の検索を含む関数を書くときに、要素が空だったために想定していた操作ができないときなど、エラーが出て操作がストップしてしまいます。そのような時のため(操作がストップしないため)、
try: (エラーになるかもしれない操作) except: (エラーになったときの操作)
としておきます。
なお、出ると予想されたエラーに関する処理ができるように、関連するエラーのモジュールを予めインポートしておくことが必要です。
- ウィンドウが無いエラー:
from selenium.common.exceptions import NoSuchWindowException - クリックしている要素が無い、などのエラー:
from selenium.common.exceptions import WebDriverException - 操作が実行できず、タイムアウトになるエラー:
from selenium.common.exceptions import TimeoutException
コード例
from selenium.common.exceptions import TimeoutException
elements = driver.find_elements_by_xpath("//*[...]")
try:
#要素のリストの1番目を取得して整数に変換
result = int(element[0])
except (TimeoutException):
#リストが空だったりelement[0]が整数に変換できない場合、resultは0とする
result = 0
その他参考:
http://kyufast.hatenablog.jp/entry/2013/11/22/000718
https://tanuhack.com/python/selenium/
https://qiita.com/Taro56/items/7cb048f5e8e8bae192e0