この記事について
Python の自然言語処理用ライブラリ spaCy の公式ページ(2019 年 12 月時点)より、spaCy 101: Everything you need to knowを自身の理解のため和訳。
訳してみた限りで必要そうな前提知識:
- Python の基礎
- 自然言語処理についての基礎
- 機械学習の基本的な枠組み
- オブジェクト指向の基本的な枠組み
次の知識はなくてもある程度は読めると思う:
- 言語学の知識(必要に応じ別ページで補足 or 参考文献の案内がある)
コード・図表はすべて前掲の公式ページから引用している。
公式ページではコードをブラウザ上で実行し結果を確認できるようになっている。
**義務感からコードと実行結果も全部コピペしたが、公式で実際動かした方が100倍楽しいので本家を参照することを推奨する。**貼り付け作業の虚無感がすごかった。
以降訳...
spaCy 101: Everything you need to know
spaCy にふれるのが初めてであるにせよ,NLP の基礎や実装の詳細について掘り下げるのが目的であるにせよ,このページはその目的に適っているはずだ.各セクションで spaCy の特徴について,実際に動作する例と図とともに平易な文でひとつずつ説明してある.セクションのうちいくつかは手軽なイントロダクションとして利用ガイドの中で繰り返し登場する.
spaCy とは
spaCy は自然言語処理(Natural Language Processing; 以降 NLP)のための,無料で利用可能なオープンソース Python ライブラリ.
大量のテキストの処理に取り組んでいると,次第により深く知りたくなるものだ.それらが何を説明しているか?その文脈の中である語がどんな意味を持っているか?誰が誰に何をしているか?どの会社のなんという製品が話題に上がっているか?似通ったテキストはあるか?
spaCy は主としてプロダクト向けに設計されており,大量のテキストを処理し「理解する」アプリケーションの構築をサポートする.情報抽出システム,言語理解システム,深層学習のための前処理などに利用が可能である.
目次
- 特徴
- 言語学的メタ情報
- トークナイズ
- 品詞タグ付けと係り受け解析
- 固有表現抽出
- 単語ベクトルと類似度計算
- パイプライン
- 語彙,ハッシュ化,語彙素
- 知識ベース
- 候補生成
- シリアライズ
- モデルの学習
- 言語データ
- チュートリアル
- インストールとテキスト処理
- トークン・名詞句・文の抽出
- 品詞タグとフラグ取得
- 任意の文字列のハッシュ化
- 固有表現認識と更新
- ニューラルネットワークモデルの学習と更新
- ブラウザ上での係り受け構造解析・固有表現抽出の可視化
- 単語ベクトル取得と類似度計算
- シンプルかつ高速なシリアライズ
- トークン規則によるテキストマッチング
- ミニバッチによるストリーム処理
- 統語依存関係抽出
- numpy array の抽出
- マークアップ生成
- アーキテクチャ
- Container objects
- Processing pipeline
- Other classes
- Community & QA
What spaCy isn't
- spaCy は,プラットフォームではない.即ち API による呼び出しが可能な公開されたサービスではない.spaCy はプラットフォームのようにサービスとしてのソフトウェア提供はしない.spaCy は NLP アプリケーション構築を補助するオープンソースのライブラリであり,利用可能なサービスを提供するわけではない.
- 即席チャットボットエンジンではない.対話アプリケーションの構築のために使うことは可能だが,チャットボットを開発するために設計されているわけではない.提供されるのはあくまでそれらのアプリケーションの基礎となるテキスト処理機能である.
- 研究用ではない.spaCy は最新の研究を部分的に取り入れてはいるが,あくまで実世界の課題を解くために設計されている.これにより NLTK や CoreNLP といったモジュールとはだいぶ異なった設計に辿り着いている.主な違いは spaCy は,その仕様において自己完結的で変更不可である点だ.spaCy は,複数の代替可能な選択肢の中からアルゴリズムを選択させたりはしない.構成要素を少なく保つことで,高速な処理と開発者の負担軽減を実現している.
- spaCy はオープンソースのライブラリであり会社ではない.spaCy は私たちの会社が提供する製品であり,他に Explosion AI という製品もある.
特徴
このドキュメントでは spaCy の特徴と機能について紹介する.言語学に関するものもあれば,一般的な機械学習の機能に関するものもある.
| 特徴 | 概要 |
|---|---|
| Tokenization トークナイズ |
テキストを語や句読点に分割する. |
| Part-of-speech Tagging 品詞タグ付け |
動詞や名詞など,語の種類をトークンに付与する. |
| Dependency Parsing 係り受け解析 |
統語的な依存関係のラベルを付与し,主語や目的語など,個々のトークン間の関係性を叙述する. |
| Lemmatization 見出し語化 |
語の基本形を付与する.例えば, "was" なら "be", "rats" なら "rat". |
| Sentence Boundary Detection 文境界推定 |
テキストを個々の文に分割する. |
| Named Entry Recognition 固有表現抽出 |
人間や会社,地名など,名前をもつ「現実世界のもの」を判別する. |
| Entity Linking エンティティ・リンキング |
実テキスト中の表現を,知識ベース(Knowledge Base)内における一意な表現に紐づけ,曖昧性を解消する.(訳者注:参考) |
| Similarity 類似度計算 |
語,テキストの特定範囲,文書などを比較し,それらがどれくらい似ているか求める. |
| Text Classification テキスト分類 |
文書や,文書内の特定の範囲に対してカテゴリーやラベルを付与する. |
| Rule-based Matching ルールベースのマッチング |
正規表現のように,テキスト自体や言語学的アノテーションに基づき,トークンの連なりを探す. |
| Training 統計的学習モデルのトレーニング |
モデルによる予測タスクを更新・改善する |
| Serialization シリアライズ |
成果物をファイルに保存する. |
統計モデルについて
いくつかの機能は動作に統計モデルが必要.統計モデルは言語学的な注釈を推定するもの.例えば,ある語が動詞なのか名詞なのか,など.多様な言語のモデルが用意されており,各モデルは Python モジュールとしてインストール可能.モデルは容量やスピード,メモリ利用,正確さ,内包するデータなどの点でそれぞれ異なる.ユースケースと扱うテキストの質によってモデルを選択する.一般的な用途には,小規模な既定のモデルから始めるのがよい.以下の特徴を持つ:
- 2値のパラメータ;特定文脈内での品詞タグ付け・係り受け解析・固有表現認識等の各種メタ情報推定に使用
- 語彙における語彙記載項[訳者註];型やスペルなどの語とそれらの文脈依存属性
- データファイル;見出し語化のルールや索引テーブルなど
- 語ベクトル;語意を多次元ベクトルで表現したもの.単語の類似度計算などに用いられる.
- 環境設定;言語情報や処理のパイプラインの設定といったような,モデル読み込み時に spaCy を動作可能な状態にするためのもの.
言語学に基づくアノテーション
spaCy は,テキストの文法的構造に基づく理解に有用な,言語学に基づく種々のアノテーションを提供する.アノテーション可能な情報には,品詞などの語の種類や,語同士の関係などがある.テキストを分析する上で,ある文においてある名詞が主語なのか目的語なのか, "google" が動詞なのか名詞なのか,といったような問題は大きな関心ごとであるだろう.
python -m spacy download en_core_web_sm
>>> import spacy
>>> nlp = spacy.load("en_core_web_sm")
ひとたびモデルをダウンロード・インストールすれば, spacy.load() を用いて読み込むことができる.これはテキスト処理に必要な全てのコンポーネントとデータを内包する Language オブジェクトを返す.慣習的にこれは nlp というインスタンスに格納される.何らかのテキスト文字列について nlp インスタンスを呼び出すことで,処理済みの Doc が得られる:
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("Apple is looking at buying U.K. startup for $1 billion")
for token in doc:
print(token.text, token.pos_, token.dep_)
# Apple PROPN nsubj
# is AUX aux
# looking VERB ROOT
# at ADP prep
# buying VERB pcomp
# U.K. PROPN compound
# startup NOUN dobj
# for ADP prep
# $ SYM quantmod
# 1 NUM compound
# billion NUM pobj
Doc は処理を経た文書であるが − すなわち,個々の語に分割済みで,かつアノテーションも付与されているが − 空白文字等を含め,もとのテキストの情報を不足なく保持している.もとのテキストにおけるあるトークンの位置をいつでも得ることができるし,個々のトークンとそれぞれの後ろの空白文字を結合することで,もとのテキストを再生成できる.このように spaCy でのテキスト処理において,もとのテキストの情報は何ひとつ失われることがない.
トークナイズ
処理の過程で, spaCy はまずテキストをトークナイズ(単語と句読点などに分割)する.これは各言語に特有な規則を適用することで実現される.典型的な課題として,文末の句読点は取り除かれるべきだが,"U.K." はピリオドを含めそれ自体ひとつのトークンとして残されるべきである,というようなものが挙げられる.Doc は個々のトークンから為り,それらは iterable である.
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("Apple is looking at buying U.K. startup for $1 billion")
for token in doc:
print(token.text)
# Apple
# is
# looking
# at
# buying
# U.K.
# startup
# for
# $
# 1
# billion
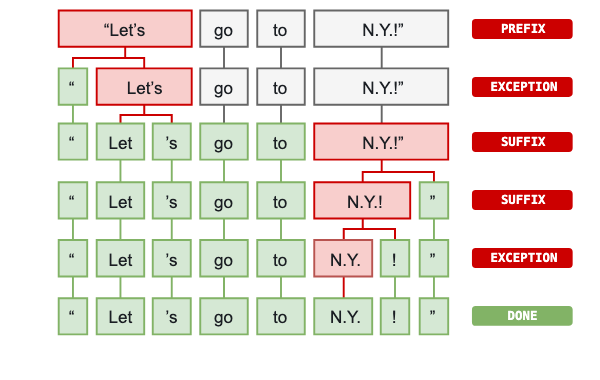
はじめに,もとのテキストは text.split(' ') を用いた時のように,空白文字によって分かたれる.それから,トークナイザは左から右に処理を進めていく.それぞれの部分文字列において,2つのチェックが行われる.
- 部分文字列はトークナイザの例外規則に合致するか?"don't" には空白文字が含まれないが,"do" と "n't" の2トークンに分かたれるべきである.一方で "U.K." はいかなる場合においても1トークンとして残されるべきである.
- **接頭辞,接尾辞,挿入辞は分割可能か?**カンマ,ピリオド,ハイフンやクオートなど.
合致があると規則が適用され,分割され新たに生成された部分文字列の集合について,処理を継続する.このように spaCy は,括弧のペアやいくつもの句読点を含むような,複雑で入れ子状になったテキストを,トークンに分割することができる.
画像:https://spacy.io/usage/spacy-101#annotations-token
句読点のルールは普遍的だが,トークナイザの例外判定は個々の言語の特徴に強く依存する.このため利用可能な個々の言語には,English や German のような対応する下位クラスがあり,それはハードコーディングされたデータと例外処理のルールを内包している.
トークナイズの規則
spaCy におけるトークナイズの規則の詳細や,既定のトークナイザのカスタマイズ・差し替えの方法や,個別言語特有のデータの追加などについては,adding languages や customizing the tokenizer を参照.
品詞タグと依存関係
トークナイズをすると,Doc への 構文解析 と タグ付け が可能になる.ここで統計的モデルが登場する.統計的言語モデルは,ある文脈における最適なタグ付け・ラベリングを可能たらしめる.モデルはバイナリ形式で保存されており,ある言語の特徴を一般化し推論を行うのに十分な量の例を学習システムに入力することで生成されるものである.ここでいう推論というのは,例えば英語において "the" のあとにくる語は名詞であろう,というようなことである.
言語学的なアノテーションは Token 属性を介し操作可能である.他の多くのパッケージと同様,メモリ節約と処理効率改善のため,spaCy は 全ての文字列をハッシュ値に変換 する.このため,ある属性の可読な文字列を得るためには,その名称の末尾にアンダースコア _ をつける必要がある.
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("Apple is looking at buying U.K. startup for $1 billion")
for token in doc:
print(token.text, token.lemma_, token.pos_, token.tag_, token.dep_,
token.shape_, token.is_alpha, token.is_stop)
# Apple Apple PROPN NNP nsubj Xxxxx True False
# is be AUX VBZ aux xx True True
# looking look VERB VBG ROOT xxxx True False
# at at ADP IN prep xx True True
# buying buy VERB VBG pcomp xxxx True False
# U.K. U.K. PROPN NNP compound X.X. False False
# startup startup NOUN NN dobj xxxx True False
# for for ADP IN prep xxx True True
# $ $ SYM $ quantmod $ False False
# 1 1 NUM CD compound d False False
# billion billion NUM CD pobj xxxx True False
Text: もとの語
Lemma: 語の基本形
POS: シンプルな品詞タグ
Tag: 詳細な品詞タグ
Dep: 統語的依存関係;トークンどうしの関係
Shape: 語形;大文字小文字,カンマ/ピリオドの使い方,数字,記号などの分類
is alpha: 英字か否か
is stop: stop words リストに含まれるか否か;高頻出語か否か
TIP: タグ・ラベルの理解を深める
タグやラベルの多くが極度に抽象化されており,しかも言語によってその意味が異なる.
spacy.explainによって簡易な説明を参照できる.例えば,spacy.explain("VBZ")は "verb, 3rd person singular present" といったような説明を返す.
spaCy 組み込みの displaCy visualize を用いると例文の統語的依存関係を可視化できる:
図
品詞タグ付けと形態論
品詞タグ付け とルールベース形態論をより深く理解し,より効果的に 解析木を使いこなす ためには品詞タグ付けと解析木の使用を参照.
固有表現抽出
固有表現とは,名前が与えられた「実世界のもの」である − 例えば,人物,国,製品,あるいは本のタイトルなど. spaCy では統計モデルに推論をさせることで,文書中に登場する様々な種類の固有表現を識別することができる.モデルは統計的なものであり,学習に用いたサンプルに強く依存するため,この方法は常に完璧に機能するわけではなく,用途によっては一度構築したのちに改めてチューニングを要することもある.
固有表現は Doc オブジェクトの ents プロパティとして利用可能である:
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("Apple is looking at buying U.K. startup for $1 billion")
for ent in doc.ents:
print(ent.text, ent.start_char, ent.end_char, ent.label_)
# Apple 0 5 ORG
# U.K. 27 31 GPE
# $1 billion 44 54 MONEY
Text: もとのテキスト
Start: Doc における当該固有名の開始位置
End: 同終了位置
Label: 固有名のラベル.
| TEXT | START | END | LABEL | DESCRIPTION |
|---|---|---|---|---|
| Apple | 0 | 5 | ORG | Companies, agencies, institutions. |
| U.K. | 27 | 31 | GPE | Geopolitical entity, i.e. countries, cities, states. |
| $1 billion | 44 | 54 | MONEY | Monetary values, including unit. |
spaCy 組み込みの displaCy visualize を用いると例文内の固有表現を可視化できる:
図
📖 固有表現抽出
spaCy による固有表現抽出について,固有表現追加の方法や,モデルの学習・推論の方法をより詳しく学びたい場合は, named entity recognition と training the named entity recognizer を見よ.
単語ベクトルと類似度計算
類似度は単語ベクトル,即ち「単語埋め込み表現」,多次元ベクトルの形をした単語の意味表現を比較することで求められる.単語ベクトルは word2vec のようなアルゴリズムを用いて生成が可能で,次のような形をしている:
array([2.02280000e-01, -7.66180009e-02, 3.70319992e-01,
3.28450017e-02, -4.19569999e-01, 7.20689967e-02,
-3.74760002e-01, 5.74599989e-02, -1.24009997e-02,
5.29489994e-01, -5.23800015e-01, -1.97710007e-01,
-3.41470003e-01, 5.33169985e-01, -2.53309999e-02,
1.73800007e-01, 1.67720005e-01, 8.39839995e-01,
5.51070012e-02, 1.05470002e-01, 3.78719985e-01,
2.42750004e-01, 1.47449998e-02, 5.59509993e-01,
1.25210002e-01, -6.75960004e-01, 3.58420014e-01,
# ... and so on ...
3.66849989e-01, 2.52470002e-03, -6.40089989e-01,
-2.97650009e-01, 7.89430022e-01, 3.31680000e-01,
-1.19659996e+00, -4.71559986e-02, 5.31750023e-01], dtype=float32)
注
モデルをコンパクトで高速に保つため,spaCy の small model(モデル名が sm で終わるもの)は単語ベクトルを内包せず,文脈依存のテンソルのみを持っている.
これは文書やテキストの一部,トークンのの比較にsimilarity()メソッドを利用できることを意味するが,結果はあまり良いものではなく,個々のトークンにベクトルがアサインされるわけではない.実際のテキストに基づいて算出されたベクトルを利用するためには,より大きなモデルをダウンロードする必要がある:
- python -m spacy download en_core_web_sm
- python -m spacy download en_core_web_lg
単語ベクトルつきのモデルでは `Token.vector` 属性を介してベクトルを操作可能である. `Doc.vector` と `Span.vector` のベクトルは,内包する語のベクトルの平均が既定値として用いられる.トークンがベクトルを持っているかの確認や,L2 正則化などの操作も可能である.
```python
import spacy
nlp = spacy.load("en_core_web_md")
tokens = nlp("dog cat banana afskfsd")
for token in tokens:
print(token.text, token.has_vector, token.vector_norm, token.is_oov)
# dog True 7.0336733 False
# cat True 6.6808186 False
# banana True 6.700014 False
# afskfsd False 0.0 True
Text: もとのテキスト
has vector: トークンがベクトルを持っているか
Vector norm: トークンベクトルの L2 正則化
OOV: 語彙に登録があるか否か
"dog","cat","banana" はいずれも英語において頻出する語であるため,語彙として登録があり,ベクトルもある.一方 "afskfsd" は一般的な語ではないため語彙に含まれない − このためベクトルは 300 個の 0 が連なったものになっており,対応するベクトルが実質存在しないことが分かる.開発するアプリケーションが,より多くのベクトルを伴う大規模な語彙の恩恵を受けるものであるならば,より大規模なモデルを読み込むことを検討するべきである.例えば en_vectors_web_lg は 100 万語のベクトルを内包している.
Doc や Span,Token などのオブジェクトは,.similarity() メソッドを持ち,他のオブジェクトとの比較によって類似度を算出することが可能である.言うまでもなく類似度は常に相対的である − "dog" と "cat" が似ているかどうかは観測者が置かれた状況次第である.spaCy の類似度計算モデルにおける類似度の定義は極めて一般的な用途を想定している.
import spacy
nlp = spacy.load("en_core_web_md") # make sure to use larger model!
tokens = nlp("dog cat banana")
for token1 in tokens:
for token2 in tokens:
print(token1.text, token2.text, token1.similarity(token2))
# dog dog 1.0
# dog cat 0.80168545
# dog banana 0.24327643
# cat dog 0.80168545
# cat cat 1.0
# cat banana 0.28154364
# banana dog 0.24327643
# banana cat 0.28154364
# banana banana 1.0
上述のケースでは,モデルによる予測結果は大変イイ感じである.dog は cat にとても近く,一方で banana はそれほど他の語と近くない.個々のトークンが 100 % それ自体に似ていることが一目瞭然でみて取れる(ベクトル計算と浮動小数点の問題のために,常にきっかり 1.0 となるわけではないことに注意).
📖 単語ベクトル
単語ベクトルをカスタマイズする方法や,自作のベクトルの spaCy への取り込みの方法については,using word vectors and semantic similarities を見よ.
パイプライン
あるテキストについて nlp を呼び出すと,spaCy ははじめにテキストをトークナイズし Doc オブジェクトを生成する.Doc はその後いくつかの処理を経る − これは processing pipeline と呼ばれる.既定モデルが用いるパイプラインは tagger(タグ付け器),parser(構文解析器),固有表現抽出器で構成されている.それぞれのパイプライン構成要素は処理済みの Doc オブジェクトを出力し,それは後続の処理に渡される.
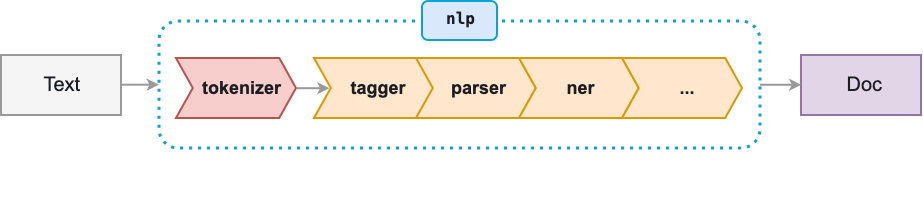
画像:https://spacy.io/usage/spacy-101#pipelines
Name: パイプライン構成要素の ID
Component: パイプライン構成要素のspaCy 実装
Creates: パイプライン構成要素により生成・設定されたオブジェクト・属性・プロパティ
processing pipeline は常に統計モデルとその性能に依存している.例えば,パイプラインが固有表現抽出器をその構成要素として持つことができるのは,統計モデルが固有表現ラベルを推定するのに十分な情報を持つ場合に限る.このため個々の統計モデルは,利用するパイプラインを,個々の構成要素を要素とするシンプルなリスト形式のメタデータとして明示的に持つ.
"pipeline": ["tagger", "parser", "ner"]
📖 Processing pipelines
processing pipeline の詳細な挙動や,パイプライン構成要素の有効化・無効化の方法,自作のパイプラインの構築方法などについては, language processing pipelines を見よ.
語彙,ハッシュ化,語彙素
spaCy では可能な限り,データは VOCAB オブジェクトに格納される.これは複数の文書間で共有されるものである.加えて,メモリ使用量を抑えるために spaCy は文字列をハッシュ値に変換する − たとえば,"coffee" は 3197928453018144401 といったようなハッシュ値に対応づけられる."ORG" といったような固有表現ラベルや "VERB" といったような品詞タグもハッシュ化される.spaCy はその内部においてはハッシュ値のみを用いて「やりとり」を行う.
Token: 語や句読点.文脈によってはそれらの属性やタグ,依存関係も含める.
Lexeme: 文脈を考慮しない「語タイプ」.形やフラグ[訳注:要確認],即ち大文字・小文字等の別や数値か否か,句読点か否かなど.
Doc: 処理済みの,文脈を考慮したトークンの集まり.
Vocab: lexeme の集合.
StringStore: ハッシュ値を文字列に紐づけるためのテーブル.例えば `3197928453018144401` → "coffee".
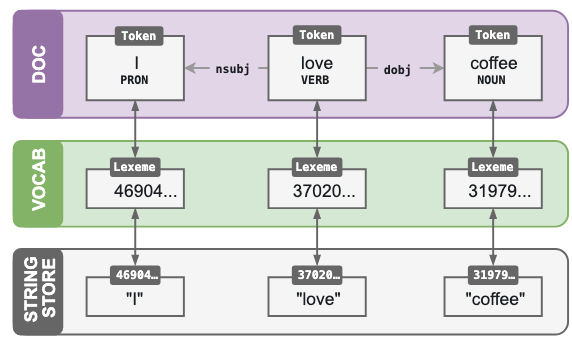
画像:https://spacy.io/usage/spacy-101#vocab
あらゆる文脈で "coffee" という語が用いられているような大量の文書を処理する場合,"coffee" という文字列そのものを毎回保存するのには非常に大きい記憶領域が必要になる.代わりに双方向の検索テーブルとして StringStore を利用することが考えられる − 文字列からハッシュ値を得ることもその逆も,意のままに可能である.
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("I love coffee")
print(doc.vocab.strings["coffee"]) # 3197928453018144401
print(doc.vocab.strings[3197928453018144401]) # 'coffee'
知識ベース
エンティティ・リンキングを実現するため,spaCy は KnowledgeBase (知識ベース)として外界知識を保持している. この知識ベースはデータを効率的に保持するため Vocab を利用している.
Mention: 固有表現の原文における出現形.'Miss Lovelace' など.
KB ID: 実世界の特定の概念と紐づく ID.'Q7259' など.
Alias: KB ID が意味する語やその内容を叙述したもの.'Ada Lovelace' など.
Prior probability: 文脈中での出現の仕方を考慮せずに算出される,その表現がある KB ID に紐づく確からしさ.
Entity vector: 当該固有表現を表す,事前学習により生成された単語ベクトル.
はじめに,知識ベースはエンティティを登録することで作られる.次に,考えられる文中表現即ち別名全てについて,関連する KB ID と Prior Probability が加えられる.全ての別名それぞれについて,これらの Prior Probability の和が 1 を超えることはない.
import spacy
from spacy.kb import KnowledgeBase
# load the model and create an empty KB
nlp = spacy.load('en_core_web_sm')
kb = KnowledgeBase(vocab=nlp.vocab, entity_vector_length=3)
# adding entities
kb.add_entity(entity="Q1004791", freq=6, entity_vector=[0, 3, 5])
kb.add_entity(entity="Q42", freq=342, entity_vector=[1, 9, -3])
kb.add_entity(entity="Q5301561", freq=12, entity_vector=[-2, 4, 2])
# adding aliases
kb.add_alias(alias="Douglas", entities=["Q1004791", "Q42", "Q5301561"], probabilities=[0.6, 0.1, 0.2])
kb.add_alias(alias="Douglas Adams", entities=["Q42"], probabilities=[0.9])
print()
print("Number of entities in KB:",kb.get_size_entities()) # 3
print("Number of aliases in KB:", kb.get_size_aliases()) # 2
# Number of entities in KB: 3
# Number of aliases in KB: 2
候補生成
原文のエンティティを与えられると,知識ベースは考えられる候補即ちエンティティ ID のリストを出力できる.EntityLinker はこの候補リストと文書コンテキストを入力として,文中表現をもっとも可能性が高い ID に紐付け,語義曖昧性解消タスクを実行することができる.
import spacy
from spacy.kb import KnowledgeBase
nlp = spacy.load('en_core_web_sm')
kb = KnowledgeBase(vocab=nlp.vocab, entity_vector_length=3)
# adding entities
kb.add_entity(entity="Q1004791", freq=6, entity_vector=[0, 3, 5])
kb.add_entity(entity="Q42", freq=342, entity_vector=[1, 9, -3])
kb.add_entity(entity="Q5301561", freq=12, entity_vector=[-2, 4, 2])
# adding aliases
kb.add_alias(alias="Douglas", entities=["Q1004791", "Q42", "Q5301561"], probabilities=[0.6, 0.1, 0.2])
candidates = kb.get_candidates("Douglas")
for c in candidates:
print(" ", c.entity_, c.prior_prob, c.entity_vector)
# Q1004791 0.6000000238418579 [0.0, 3.0, 5.0]
# Q42 0.10000000149011612 [1.0, 9.0, -3.0]
# Q5301561 0.20000000298023224 [-2.0, 4.0, 2.0]
シリアライズ
パイプラインやボキャブラリ,単語ベクトルやエンティティを作ったり,モデルを更新したりしているうちに,成果物を保存しておきたくなる − nlp オブジェクトの中のもの全てを保存するようなケースも考えられるだろう.これを成し遂げるためには,オブジェクトの全ての構成要素とそれらの関係性を,ファイルやバイト列などのような保存可能な形式に変換する必要がある.この過程はシリアライズと呼ばれる.spaCy には備え付けのシリアライズ用メソッドが用意されており, Pickle プロトコルに対応している.
Pickle とは?
Pickle は Python の備え付けの永続化システム.任意の Python オブジェクトをプロセス間で受け渡しするために使える.一般的にはディスクにオブジェクトを読み書きすることに用いられるが,PySpark や Dask などの分散処理にも使われている.オブジェクトを unpickle すると,内容物を実行することに同意したことになる.それは文字列に対してeval()を適用するのと同じようなことである - 信用できない配布元から取得したオブジェクトを unpickle するのはよした方がよい.
Language,(nlp オブジェクト),Doc,Vocab,StringStore などは全て以下のメソッドを持つ:
| METHOD | RETURNS | EXAMPLE |
|---|---|---|
to_bytes |
bytes | data = nlp.to_bytes() |
from_bytes |
object | nlp.from_bytes(data) |
to_disk |
- | nlp.to_disk("/path") |
from_disk |
object | nlp.from_disk("/path") |
📖 保存とロード
保存とロードの方法について更に知りたければ,saving and loadingを見よ.
モデルの学習
spaCy のモデルは統計的なものであり,モデルによって下される全ての「判断」 − たとえばどの品詞を採用するかや,どれがエンティティに該当する単語なのか,等々 − は推論である.この推論は学習の過程を通してモデルに与えられた事例に基づいて為される.モデルを学習させるためには,まずは教師データ − テキストと予測したいラベルの組み合わせからなる事例 − が必要である.ラベルとしては品詞タグや固有表現などが考えられる.
学習後は,モデルはラベル無しのテキストを与えられると推論を行う.利用者側は正解を知っているので,正解ラベルと予測値の差を計算する損失関数の誤差の勾配の形で推論についてモデルにフィードバックできる.差が大きいほど勾配もモデルの更新の度合いも大きくなる.
Training data: 個々の事例とそれらについてのアノテーション.
Text: モデルがラベルの推論に用いる入力テキスト.
Label: モデルが予測するラベル.
Gradient: 入力ラベルと予測されたラベルの差から計算される損失関数の勾配.
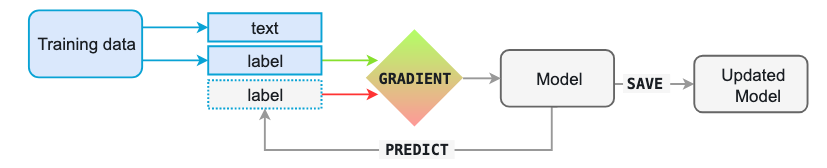
画像:https://spacy.io/usage/spacy-101#training
モデルを学習させるにあたり,単に与えた事例を記憶するようなものが出来上がっては困る − 未知の事例に対しても適用可能な,一般化された法則を学習してほしいのだ.つまり,"Amazon" というこの単語が特定の企業を指すものであるとモデルに学んでほしいわけではないのだ − ある文脈においては企業を指すのだ,ということを学んでもらいたいのだ.これが,教師データは処理対象とするデータを代表するものであるべき理由である.Wikipedia において一人称の文は極めて出現頻度が低いため,Wikipedia のデータで学習したモデルは Twitter のテキストデータ解析においてはひどい性能になってしまう.恋愛小説で学習したモデルで法文書を解析しても同様の結果になる.
これはモデルがどのような性能を示すか,適切に学習が行われているかを判断するためには,教師データだけでは不十分であることを意味する − 評価データも必要なのだ.学習に用いたデータだけを用いて性能を評価したのでは,どれほど汎化性能があるかを判断できない.モデルをスクラッチで構築するのであれば,少なくとも数百のデータが,学習用・評価用それぞれで必要になる.既成のモデルを更新したいのなら,ごく少ない追加データさえあれば使い物になる結果を得られる − それが分析対象の代表として適切なものでありさえすれば.
📖 統計的モデルの学習
教師データの生成方法,spaCy の固有表現認識モデルの更新方法など,モデルの学習と更新について更に知りたければ,trainingを見よ.
言語データ
全ての言語は異なる − そしてたくさんの例外と特別なケースであふれている.出現頻度が高い一般的な語であれば特にその傾向が強い.これらの例外のうち,言語をまたいで見られるものもあるし,一方で完全に言語固有のものもある − 多くの場合ハードコーディングする必要があるほど固有である.lang モジュールはシンプルな Python ファイルで編成されており,言語固有のデータが全て入っている.これによりデータの更新と拡張が容易になっている.
spaCy モジュールのルートディレクトリに入っている共通言語データは言語をまたいで適用可能なルールを含んでいる − たとえば基本的な句読点の打ち方や,絵文字,顔文字,1字の略語," と ” など同等の意味を持つ1字のトークンの名寄せルールなどである.これによりモデルはより正確な推論が可能になる.サブモジュールのディレクトリ配下にある固有言語データは,特定の言語のみに関するルールを保持している.固有言語データはまた,[訳者註:トークナイザなどの]コンポーネントをひとまとめにし,English や German のような Language サブクラスの生成も担う.
from spacy.lang.en import English
from spacy.lang.de import German
nlp_en = English() # Includes English data
nlp_de = German() # Includes German data
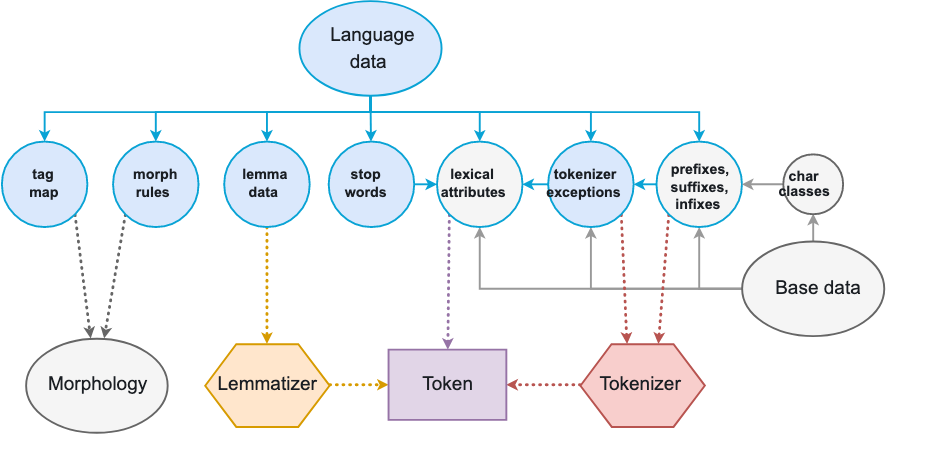
画像:https://spacy.io/usage/spacy-101#language-data
| コンポーネント名 | 説明 |
|---|---|
Stop wordsstop_words.py
|
ある言語においてフィルタリング対象とされることが多い頻出語のリスト.英語における "and" や "I" など.当てはまるトークンは is_stop 属性として True を返す. |
Tokenizer exceptionstokenizer_exceptions.py
|
トークナイザー用の特別なケース. "can't" のような縮約形や,"U.K." のようなピリオドを伴う略語など. |
Norm exceptionsnorm_exceptions.py
|
モデルの推論の性能向上のためのトークンの正規化に用いる特別な規則.アメリカ英語とイギリス英語の綴りなど. |
Punctuation rulespunctuation.py
|
トークン分割用の正規表現.ピリオドを基準とするものや,絵文字などの特別な文字を基準とするものなど.接頭辞,接尾辞,接中辞も含む. |
Character classeschar_classes.py
|
正規表現内で基準として用いられる文字のクラス.ラテン文字,クオート,ハイフン,アイコンなど. |
Lexical attributeslex_attrs.py
|
トークンに語彙属性を割り当てるユーザ定義[訳者註:要確認]関数群."ten" や "hundred" といった語には like_num という属性が割り振られる,など. |
Syntax iteratorssyntax_iterators.py
|
Doc オブジェクトを構文情報にもとづき可視する関数群.現時点では noun chunks のみに利用されている. |
Tag maptag_map.py
|
タグ集合の文字列を Universal Dependencies タグにマッピングする辞書. |
Morph rulesmorph_rules.py
|
人称代名詞のような不規則な語の形態素解析に用いられる例外規則. |
Lemmatizerspacy-lookup-data.py
|
語の基本形を得るための見出し語化規則や探索テーブル."for" から "be" への変換など. |
📖 言語データ
言語データの個々のコンポーネントについて更に知りたい場合や,言語モデルを学習させるために新たな言語を spaCy に加えるための方法について知りたい場合は,adding languagesを見よ.
ライトニング・ツアー
以降の例とコードスニペットは spaCy の機能と使い方についての概観を示してくれるだろう.
インストールとテキスト処理
python -m spacy download en_core_web_sm
python -m spacy download de_core_news_sm
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("Hello, world. Here are two sentences.")
print([t.text for t in doc])
nlp_de = spacy.load("de_core_news_sm")
doc_de = nlp_de("Ich bin ein Berliner.")
print([t.text for t in doc_de])
# ['Hello', ',', 'world', '.', 'Here', 'are', 'two', 'sentences', '.']
# ['Ich', 'bin', 'ein', 'Berliner', '.']
API: spacy.load() Usage: Models, spaCy 101
トークン・名詞句・文の抽出
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("Peach emoji is where it has always been. Peach is the superior "
"emoji. It's outranking eggplant 🍑 ")
print(doc[0].text) # 'Peach'
print(doc[1].text) # 'emoji'
print(doc[-1].text) # '🍑'
print(doc[17:19].text) # 'outranking eggplant'
noun_chunks = list(doc.noun_chunks)
print(noun_chunks[0].text) # 'Peach emoji'
sentences = list(doc.sents)
assert len(sentences) == 3
print(sentences[1].text) # 'Peach is the superior emoji.'
# Peach
# emoji
# 🍑
# outranking eggplant
# Peach emoji
# Peach is the superior emoji.
品詞タグとフラグ取得
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("Apple is looking at buying U.K. startup for $1 billion")
apple = doc[0]
print("Fine-grained POS tag", apple.pos_, apple.pos)
print("Coarse-grained POS tag", apple.tag_, apple.tag)
print("Word shape", apple.shape_, apple.shape)
print("Alphabetic characters?", apple.is_alpha)
print("Punctuation mark?", apple.is_punct)
billion = doc[10]
print("Digit?", billion.is_digit)
print("Like a number?", billion.like_num)
print("Like an email address?", billion.like_email)
# Fine-grained POS tag PROPN 96
# Coarse-grained POS tag NNP 15794550382381185553
# Word shape Xxxxx 16072095006890171862
# Alphabetic characters? True
# Punctuation mark? False
# Digit? False
# Like a number? True
# Like an email address? False
API: Token Usage: Part-of-speech tagging
任意の文字列のハッシュ化
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("I love coffee")
coffee_hash = nlp.vocab.strings["coffee"] # 3197928453018144401
coffee_text = nlp.vocab.strings[coffee_hash] # 'coffee'
print(coffee_hash, coffee_text)
print(doc[2].orth, coffee_hash) # 3197928453018144401
print(doc[2].text, coffee_text) # 'coffee'
beer_hash = doc.vocab.strings.add("beer") # 3073001599257881079
beer_text = doc.vocab.strings[beer_hash] # 'beer'
print(beer_hash, beer_text)
unicorn_hash = doc.vocab.strings.add("🦄") # 18234233413267120783
unicorn_text = doc.vocab.strings[unicorn_hash] # '🦄'
print(unicorn_hash, unicorn_text)
# 3197928453018144401 coffee
# 3197928453018144401 3197928453018144401
# coffee coffee
# 3073001599257881079 beer
# 18234233413267120783 🦄
API: StringStore Usage: Vocab, hashes and lexemes 101
固有表現認識と更新
import spacy
from spacy.tokens import Span
nlp = spacy.load("en_core_web_sm")
doc = nlp("San Francisco considers banning sidewalk delivery robots")
for ent in doc.ents:
print(ent.text, ent.start_char, ent.end_char, ent.label_)
doc = nlp("FB is hiring a new VP of global policy")
doc.ents = [Span(doc, 0, 1, label="ORG")]
for ent in doc.ents:
print(ent.text, ent.start_char, ent.end_char, ent.label_)
# San Francisco 0 13 GPE
# FB 0 2 ORG
Usage: Named entity recognition
ニューラルネットワークモデルの学習と更新
import spacy
import random
nlp = spacy.load("en_core_web_sm")
train_data = [("Uber blew through $1 million", {"entities": [(0, 4, "ORG")]})]
other_pipes = [pipe for pipe in nlp.pipe_names if pipe != "ner"]
with nlp.disable_pipes(*other_pipes):
optimizer = nlp.begin_training()
for i in range(10):
random.shuffle(train_data)
for text, annotations in train_data:
nlp.update([text], [annotations], sgd=optimizer)
nlp.to_disk("/model")
API: Language.update Usage: Training spaCy's statistical models
ブラウザ上での係り受け構造解析・固有表現抽出の可視化
OUTPUT
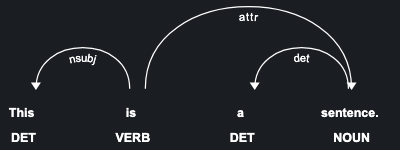
from spacy import displacy
doc_dep = nlp("This is a sentence.")
displacy.serve(doc_dep, style="dep")
doc_ent = nlp("When Sebastian Thrun started working on self-driving cars at Google "
"in 2007, few people outside of the company took him seriously.")
displacy.serve(doc_ent, style="ent")
API: displacy Usage: Visualizers
単語ベクトル取得と類似度計算
import spacy
nlp = spacy.load("en_core_web_md")
doc = nlp("Apple and banana are similar. Pasta and hippo aren't.")
apple = doc[0]
banana = doc[2]
pasta = doc[6]
hippo = doc[8]
print("apple <-> banana", apple.similarity(banana))
print("pasta <-> hippo", pasta.similarity(hippo))
print(apple.has_vector, banana.has_vector, pasta.has_vector, hippo.has_vector)
# apple <-> banana 0.5831845
# pasta <-> hippo 0.12069741
# True True True True
Usage: Word vectors and similarity
シンプルかつ高速なシリアライズ
import spacy
from spacy.tokens import Doc
from spacy.vocab import Vocab
nlp = spacy.load("en_core_web_sm")
customer_feedback = open("customer_feedback_627.txt").read()
doc = nlp(customer_feedback)
doc.to_disk("/tmp/customer_feedback_627.bin")
new_doc = Doc(Vocab()).from_disk("/tmp/customer_feedback_627.bin")
API: Language, Doc Usage: Saving and loading models
トークン規則によるテキストマッチング
import spacy
from spacy.matcher import Matcher
nlp = spacy.load("en_core_web_sm")
matcher = Matcher(nlp.vocab)
def set_sentiment(matcher, doc, i, matches):
doc.sentiment += 0.1
pattern1 = [{"ORTH": "Google"}, {"ORTH": "I"}, {"ORTH": "/"}, {"ORTH": "O"}]
pattern2 = [[{"ORTH": emoji, "OP": "+"}] for emoji in ["😀", "😂", "🤣", "😍"]]
matcher.add("GoogleIO", None, pattern1) # Match "Google I/O" or "Google i/o"
matcher.add("HAPPY", set_sentiment, *pattern2) # Match one or more happy emoji
doc = nlp("A text about Google I/O 😀😀")
matches = matcher(doc)
for match_id, start, end in matches:
string_id = nlp.vocab.strings[match_id]
span = doc[start:end]
print(string_id, span.text)
print("Sentiment", doc.sentiment)
# GoogleIO Google I/O
# HAPPY 😀
# HAPPY 😀😀
# HAPPY 😀
# Sentiment 0.30000001192092896
API: Matcher Usage: Rule-based matching
ミニバッチによるストリーム処理
texts = ["One document.", "...", "Lots of documents"]
# .pipe streams input, and produces streaming output
iter_texts = (texts[i % 3] for i in range(100000000))
for i, doc in enumerate(nlp.pipe(iter_texts, batch_size=50)):
assert doc.is_parsed
if i == 100:
break
統語依存関係抽出
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("When Sebastian Thrun started working on self-driving cars at Google "
"in 2007, few people outside of the company took him seriously.")
dep_labels = []
for token in doc:
while token.head != token:
dep_labels.append(token.dep_)
token = token.head
print(dep_labels)
# ['advmod', 'advcl', 'compound', 'nsubj', 'advcl', 'nsubj', 'advcl', 'advcl', 'xcomp', 'advcl', 'prep', 'xcomp', 'advcl', 'npadvmod', 'amod', 'pobj', 'prep', 'xcomp', 'advcl', 'punct', 'amod', 'pobj', 'prep', 'xcomp', 'advcl', 'amod', 'pobj', 'prep', 'xcomp', 'advcl', 'pobj', 'prep', 'xcomp', 'advcl', 'prep', 'xcomp', 'advcl', 'pobj', 'prep', 'xcomp', 'advcl', 'prep', 'advcl', 'pobj', 'prep', 'advcl', 'punct', 'amod', 'nsubj', 'nsubj', 'prep', 'nsubj', 'prep', 'prep', 'nsubj', 'det', 'pobj', 'prep', 'prep', 'nsubj', 'pobj', 'prep', 'prep', 'nsubj', 'dobj', 'advmod', 'punct']
API: Token Usage: Using the dependency parse
numpy array の抽出
import spacy
from spacy.attrs import ORTH, LIKE_URL
nlp = spacy.load("en_core_web_sm")
doc = nlp("Check out https://spacy.io")
for token in doc:
print(token.text, token.orth, token.like_url)
attr_ids = [ORTH, LIKE_URL]
doc_array = doc.to_array(attr_ids)
print(doc_array.shape)
print(len(doc), len(attr_ids))
assert doc[0].orth == doc_array[0, 0]
assert doc[1].orth == doc_array[1, 0]
assert doc[0].like_url == doc_array[0, 1]
assert list(doc_array[:, 1]) == [t.like_url for t in doc]
print(list(doc_array[:, 1]))
# Check 8104846059040039827 False
# out 1696981056005371314 False
# https://spacy.io 17142293684782158888 True
# (3, 2)
# 3 2
# [0, 0, 1]
マークアップ生成
import spacy
def put_spans_around_tokens(doc):
"""Here, we're building a custom "syntax highlighter" for
part-of-speech tags and dependencies. We put each token in a
span element, with the appropriate classes computed. All whitespace is
preserved, outside of the spans. (Of course, HTML will only display
multiple whitespace if enabled – but the point is, no information is lost
and you can calculate what you need, e.g. <br />, <p> etc.)
"""
output = []
html = '<span class="{classes}">{word}</span>{space}'
for token in doc:
if token.is_space:
output.append(token.text)
else:
classes = "pos-{} dep-{}".format(token.pos_, token.dep_)
output.append(html.format(classes=classes, word=token.text, space=token.whitespace_))
string = "".join(output)
string = string.replace("\n", "")
string = string.replace("\t", " ")
return "<pre>{}</pre>".format(string)
nlp = spacy.load("en_core_web_sm")
doc = nlp("This is a test.\n\nHello world.")
html = put_spans_around_tokens(doc)
print(html)
# <pre><span class="pos-DET dep-nsubj">This</span> <span class="pos-AUX dep-ROOT">is</span> <span class="pos-DET dep-det">a</span> <span class="pos-NOUN dep-attr">test</span><span class="pos-PUNCT dep-punct">.</span><span class="pos-INTJ dep-intj">Hello</span> <span class="pos-NOUN dep-ROOT">world</span><span class="pos-PUNCT dep-punct">.</span></pre>
アーキテクチャ
spaCy において中心的役割を果たすのが Doc と Vocab である. Doc オブジェクトはトークン列とそれらに付されたアノテーション情報を保持している.Vocab オブジェクトは探索テーブルを保持しており,これにより文書をまたいだ情報の共有が可能になっている.文字列情報の一元化,単語ベクトル,そして語彙属性により,重複するデータを保持しないで済む.その結果メモリ使用量は削減され,信頼できる唯一の情報源が実現される.
テキストのアノテーションもまた,信頼できる唯一の情報源を実現するよう設計されている:Doc オブジェクトがデータを保持し, Span と Token はその参照である.Doc オブジェクトは Tokenizer によって構築され,パイプラインのコンポーネントによって利用可能な状態に修正が加えられる.Language オブジェクトはこれらのコンポーネントを調整する.生のテキストをパイプラインに送り,アノテーション付き文書を返す.モデルの学習やシリアライズも Language オブジェクトが担う.
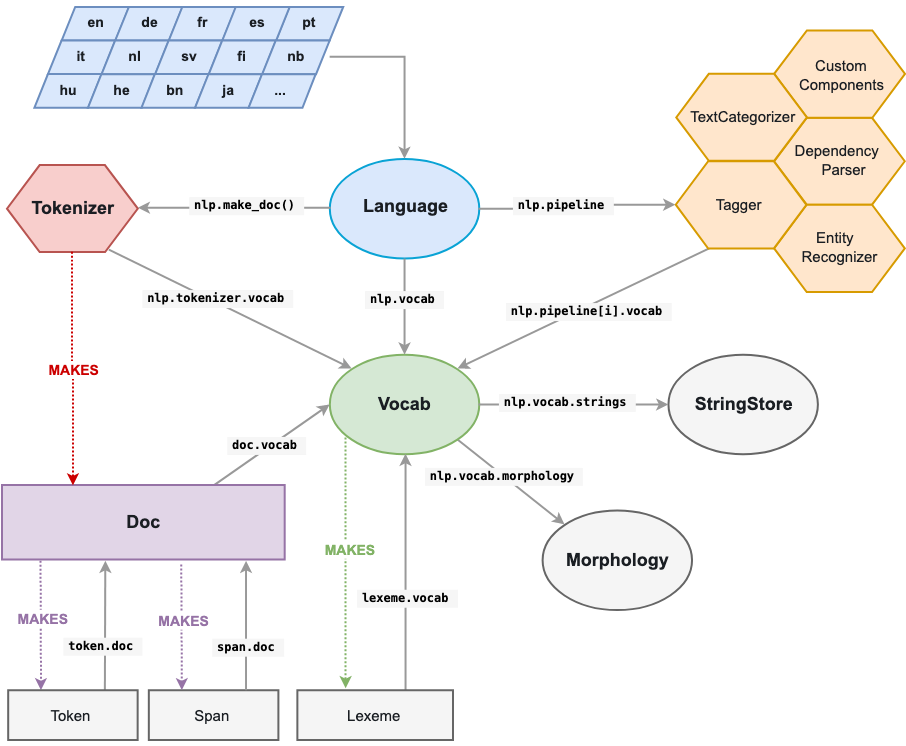
画像:https://spacy.io/usage/spacy-101#architecture
コンテナオブジェクト
| NAME | DESCRIPTION |
|---|---|
| Doc | 言語学的アノテーションにアクセスするためのコンテナ. |
| Span | Doc オブジェクトの一部を切り出した部分文字列. |
| Token | 個々のトークン − 単語,句読点記号,空白文字など. |
| Lexeme | 語彙中のひとつの項目.単語トークンとは対象的に,文脈から切り離された,単語の種類を表すもの.このため品詞タグや依存関係などを持たない. |
処理パイプライン
| NAME | DESCRIPTION |
|---|---|
| Language | テキストを処理するパイプライン.通例 nlp として処理のたびに一度だけ読み込んだものをアプリケーション内で使いまわせば良い. |
| Tokenizer | テキストを区切り, 発見された境界の情報をもつ Doc オブジェクトを生成する. |
| Lemmatizer | 単語の基本形を決定する. |
| Morphology | 見出し語や名詞の格,動詞の時制などの言語学的特徴を,単語と品詞タグにもとづき割り当てる. |
| Tagger | Doc オブジェクトに品詞タグをメタ情報として付する. |
| DependencyParser | Doc オブジェクトに統語的依存関係をメタ情報として付する. |
| EntityRecognizer | Doc オブジェクトに,人物や商品などの固有表現種別をメタ情報として付する. |
| TextCategorizer | カテゴリまたはラベルを Doc オブジェクトに付する. |
| Matcher | 正規表現と似た仕組みで,パターンの検出ルールにもとづき,トークン列を探索する. |
| PhraseMatcher | フレーズにもとづき,トークン列を探索する. |
| EntityRuler | トークン基準のルールかフレーズの完全一致にもとづき,エンティティの範囲を Doc オブジェクトに付する. |
| Sentencizer | 構文解析を必要としない,ユーザー定義の文境界推定ロジックを実装する. |
| Other functions | 部分単語列を結合するなど,Doc に対して自動的に適用されるものがある. |
その他のクラス
| NAME | DESCRIPTION |
|---|---|
| Vocab | 語彙の探索テーブル.Lexeme オブジェクトにアクセスを可能になる. |
| StringStore | 文字列とハッシュ値を相互に紐づける. |
| Vectors | 文字列のキーをもつ単語ベクトルのコンテナクラス. |
| GoldParse | 学習に用いられるアノテーションの集合. |
| GoldCorpus | JSON 形式で保存された,アノテーション付きコーパス.タグ付けや構文解析,固有表現抽出用のアノテーションを管理する. |
コミュニティ&FAQ
省略
...以上訳。
Universal Dependencies が重要概念っぽい(そのわりに本記事での紹介が無い)のでこちらも読み進める。