10/15更新:この投稿の翌日、Ragas v0.2.0がリリースされ大きめの変更が入りました! RAGだけでなく、エージェントなどの生成内容も評価できるようアップデートされています。
記事内のサンプルコードも動くように修正済みです。
RAG評価の定番ツール「Ragas」とは?
みなさん、生成AIでアプリ作ってますか?
そろそろRAGを使ったチャットボットみたいなPoCはやり飽きてきた方も多いのではないでしょうか。
PoCから本番運用へ移行するためには、RAGを使ったテキスト生成結果がユーザーにとって価値ある品質になっているか、「評価」をうまく行う必要があります。
様々な生成結果を実際のユーザーに評価してもらえるなら最高ですが、膨大なパターンを検証したり、アプリや参照データの日々の変化に追従して試験し続けるのは人力だと辛いものがあります。そこで有用なツールが「Ragas」です。
Ragasは簡単に言うと、Python言語用のライブラリです。GitHub上でコードが公開されており、誰でも無料で試すことができます。
Ragasの思想とできること
Ragasでは「メトリクス駆動開発」というコンセプトのもと、LLMアプリの性能評価に特化した専用のメトリクスが用意されています。
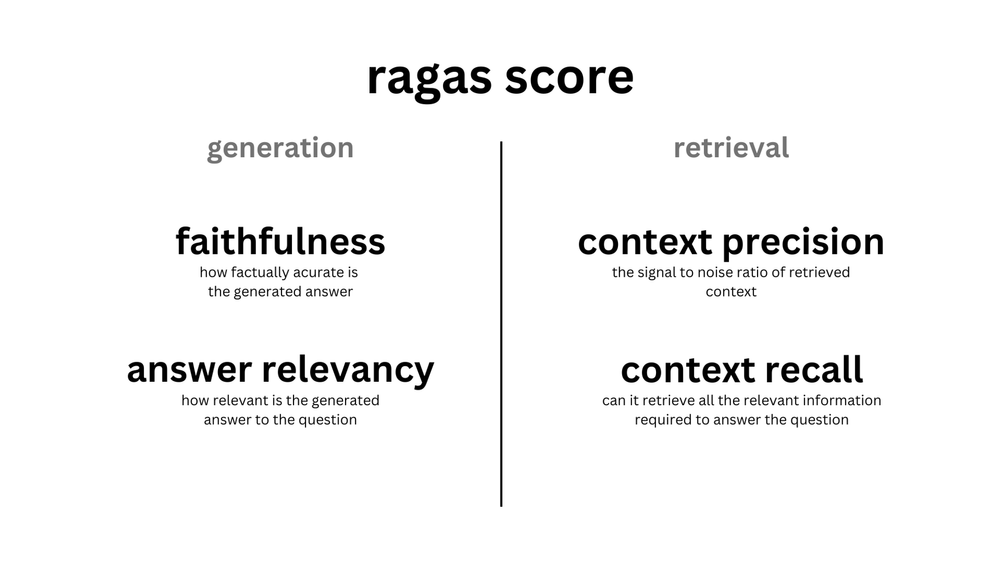
(Ragasの主要メトリクス / 公式サイトより)
アプリ開発中の評価だけでなく、評価用テストデータの生成、運用中の監視(例:ハルシネーション回数など)なども行えます。
また、評価やデータ生成にはLLMを利用しているのが興味深いポイントです。
実際に触ってみよう!
説明だけだとピンと来ない方も多いと思うので、自分で実際に動かしてみましょう。
Ragasの公式サイトにもチュートリアルがあるのですが、以下の理由から初心者にとっつきづらい印象です。
- そもそも日本語の情報が少ない
- データ分析関連の基本的な補足説明がバッサリ割愛されている
- 関連するLangChainモジュールのアップデートが早く、コードが古くなっている
- デフォルトだとOpenAIのモデルを利用するため、AWS用にカスタマイズしたい
そのため今回、日本語でシンプルなハンズオンを紹介していきます。
RAGアプリの準備
まずは評価対象のRAGアプリを用意します。
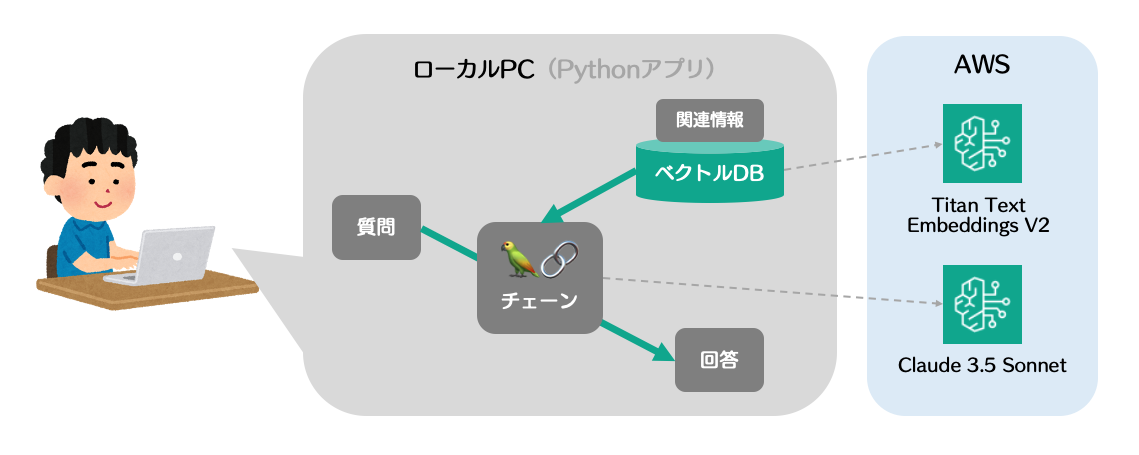
回答生成や埋め込みに必要なモデルは、AWSのAmazon Bedrockを利用します。
バージニア北部リージョンで「Claude 3.5 Sonnet」と「Titan Text Embeddings V2」を有効化しておいてください。
また、ローカルPCへ上記AWSアカウントへの認証情報を設定しておいてください。
以下のPythonファイルをローカルで実行してみましょう。
# 外部ライブラリをインポート
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
from langchain_community.vectorstores import FAISS
from langchain_aws import ChatBedrockConverse, BedrockEmbeddings
# LLMと埋め込みモデルを設定
llm = ChatBedrockConverse(model="anthropic.claude-3-5-sonnet-20240620-v1:0")
embeddings = BedrockEmbeddings(model_id="amazon.titan-embed-text-v2:0")
# 検索対象の「社内文書」を作成
texts = [
"情報1:KDDIアジャイル開発センター株式会社は、KAGという略称で親しまれています。",
"情報2:KAG社は、かぐたんというSlackアプリを開発しました。"
]
# ベクトルDBをローカルPC上に作成
vectorstore = FAISS.from_texts(texts=texts,embedding=embeddings)
# RAGの検索対象としてベクトルDBを指定
retriever = vectorstore.as_retriever()
# プロンプトテンプレートを定義
prompt = ChatPromptTemplate.from_template(
"背景情報をもとに質問に回答してください。背景情報: {context} 質問: {question}"
)
# RAGを使ったLangChainチェーンを定義
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
# 質問文を入れてチェーンを実行
question = "かぐたんって何?"
answer = chain.invoke(question)
# LLMからの出力を表示
print(answer)
実行コマンドは以下です。
# ライブラリのインストール
pip install -U boto3 langchain langchain-core langchain-community langchain-aws
# アプリの実行
python rag.py
以下のような回答が生成されると思います。
かぐたんは、KAG社(KDDIアジャイル開発センター株式会社)が開発したSlackアプリです。
背景情報から以下のことがわかります:
1. KDDIアジャイル開発センター株式会社は、KAGという略称で知られています。
2. KAG社が「かぐたん」というSlackアプリを開発しました
RAGを用いて、ニッチな質問に正しく回答することができています。
ちなみにFAISSというベクトルDBをローカルで起動しており、AWS上のTitanモデルを利用して背景情報をベクトルに変換してFAISSに格納して検索しています。
Ragasで評価してみる
それでは、このアプリの生成結果をRagasで評価してみましょう。
Ragasの動作に必要なコードは以下です。
# 外部ライブラリをインポート
from datasets import Dataset
from ragas import evaluate
from ragas.metrics import (
answer_relevancy,
faithfulness,
context_recall,
context_precision,
)
# 評価対象のデータセットを定義
dataset = Dataset.from_dict({
"question": ["ここに質問を入れる"],
"answer": ["ここにLLMの回答を入れる"],
"contexts": [["ここに背景情報を入れる"]],
"ground_truth": ["ここに正解を入れる"],
})
# 評価を実行
result = evaluate(
dataset,
metrics=[
faithfulness, # 忠実性:背景情報と一貫性のある回答ができているか
answer_relevancy, # 関連性:質問と関連した回答ができているか
context_precision, # 文脈精度:質問や正解に関連した背景情報を取得できているか
context_recall, # 文脈回収:回答に必要な背景情報をすべて取得できているか
]
)
# 評価結果を表示
print(result)
ようは、データセットを定義して evaluate を実行するだけです。簡単ですね。
データセットには以下の情報を含めます。
- question:ユーザーの質問
- answer:RAGアプリの生成結果
- contexts:RAGで取得した背景情報
- ground_truth:正解
evaluate で利用できる評価メトリクスは10以上ありますが、今回は代表的な以下の4つを利用してみます。
- faithfulness(忠実性):背景情報と一貫性のある回答ができているか
- answer_relevancy(関連性):質問と関連した回答ができているか
- context_precision(文脈精度):質問や正解に関連した背景情報を取得できているか
- context_recall(文脈回収):回答に必要な背景情報をすべて取得できているか
上記のコードを前述のアプリに追記した例は以下です。
# 外部ライブラリをインポート
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
from langchain_community.vectorstores import FAISS
from langchain_aws import ChatBedrockConverse, BedrockEmbeddings
from datasets import Dataset
from ragas import evaluate
from ragas.llms import LangchainLLMWrapper
from ragas.embeddings import LangchainEmbeddingsWrapper
from ragas.metrics import (
answer_relevancy,
faithfulness,
context_recall,
context_precision,
)
# LLMと埋め込みモデルを設定
llm = ChatBedrockConverse(model="anthropic.claude-3-5-sonnet-20240620-v1:0")
embeddings = BedrockEmbeddings(model_id="amazon.titan-embed-text-v2:0")
# 検索対象の「社内文書」を作成
texts = [
"情報1:KDDIアジャイル開発センター株式会社は、KAGという略称で親しまれています。",
"情報2:KAG社は、かぐたんというSlackアプリを開発しました。"
]
# ベクトルDBをローカルPC上に作成
vectorstore = FAISS.from_texts(texts=texts,embedding=embeddings)
# RAGの検索対象としてベクトルDBを指定
retriever = vectorstore.as_retriever()
# プロンプトテンプレートを定義
prompt = ChatPromptTemplate.from_template(
"背景情報をもとに質問に回答してください。背景情報: {context} 質問: {question}"
)
# RAGを使ったLangChainチェーンを定義
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
# 質問文を入れてチェーンを実行
question = "かぐたんって何?"
answer = chain.invoke(question)
# LLMからの出力を表示
print(answer)
# 評価対象のデータセットを定義
dataset = Dataset.from_dict({
"question": [question],
"answer": [answer],
"contexts": [texts],
"ground_truth": ["かぐたんとは、KAG社が開発したSlack用チャットボットです。"],
})
# 評価を実行
result = evaluate(
dataset,
metrics=[
faithfulness, # 忠実性:背景情報と一貫性のある回答ができているか
answer_relevancy, # 関連性:質問と関連した回答ができているか
context_precision, # 文脈精度:質問や正解に関連した背景情報を取得できているか
context_recall, # 文脈回収:回答に必要な背景情報をすべて取得できているか
],
llm=LangchainLLMWrapper(llm),
embeddings=LangchainEmbeddingsWrapper(embeddings),
)
# 評価結果を表示
print(result)
追加のライブラリをインストールして実行してみましょう。
# ライブラリのインストール
pip install -U ragas datasets
# アプリの実行
python rag-eval.py
以下のような回答が生成されると思います。
# (前略:Ragasが利用しているLangChain関連のモジュールが古いため、警告が出ますが今は気にしないでください)
かぐたんは、KAG社(KDDIアジャイル開発センター株式会社)が開発したSlackアプリです。
背景情報から以下のことがわかります:
1. KDDIアジャイル開発センター株式会社は、KAGという略称で知られています。
2. KAG社が「かぐたん」というSlackアプリを開発しました。
したがって、かぐたんはKAG社が開発したSlackアプリであると言えます。ただし、このアプリの具体的な機能や用途については、与えられた情報からは詳細がわかりません。
Evaluating: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 4/4 [00:18<00:00, 4.74s/it]
{'faithfulness': 1.0000, 'answer_relevancy': 0.7914, 'context_precision': 0.5000, 'context_recall': 1.0000}
最後に出ているJSONが、Ragasの評価結果です。
- faithfulness: 1.0000(背景情報と回答に一貫性があり、忠実度が高い)
- answer_relevancy: 0.7914(質問とそこそこ関連した回答ができており、関連性が高め)
- context_precision: 0.5000(背景情報の半分は質問や正解に関係なく、文脈精度はまずまず)
- context_recall: 1.0000(回答に必要な背景情報をすべて取得できており、文脈回収はOK)
おわりに
実際に動かしてみると、Ragasとはメトリクスを使った定量評価をしてくれるツールであることが具体的に理解できたと思います。
本番アプリケーションで利用する際には、Ragasの出力をLangSmith等に送って、GUI上で可視化・分析するとより便利ですね。
各メトリクスをより細かく知りたい方は、公式ドキュメントや、以下の記事を参照してみてください。
RAGASはLangChain関連のコードが古くなっていたりするので、ぜひコントリビュートにも挑戦してみましょう。(私もAmazon Bedrock用のサンプルコードを最新化するPRを出してみました)