AWSの生成AIサービス、Amazon Bedrockに新機能「マルチエージェントコラボレーション」がプレビューとして登場しています。
人間の代わりに仕事をこなしてくれるAIエージェントですが、この機能を使えば「複数のエージェントを協働させる高度なアプリケーション」が簡単に作れます。
実際にハンズオンしてみましょう! 1〜2時間あれば実施できます。
※今回紹介する手順は、以下のオンラインイベントでも使用します。
今回構築するアプリ
サンプルアプリとして 「生成AIユースケース検討くん」 を構築してみましょう。
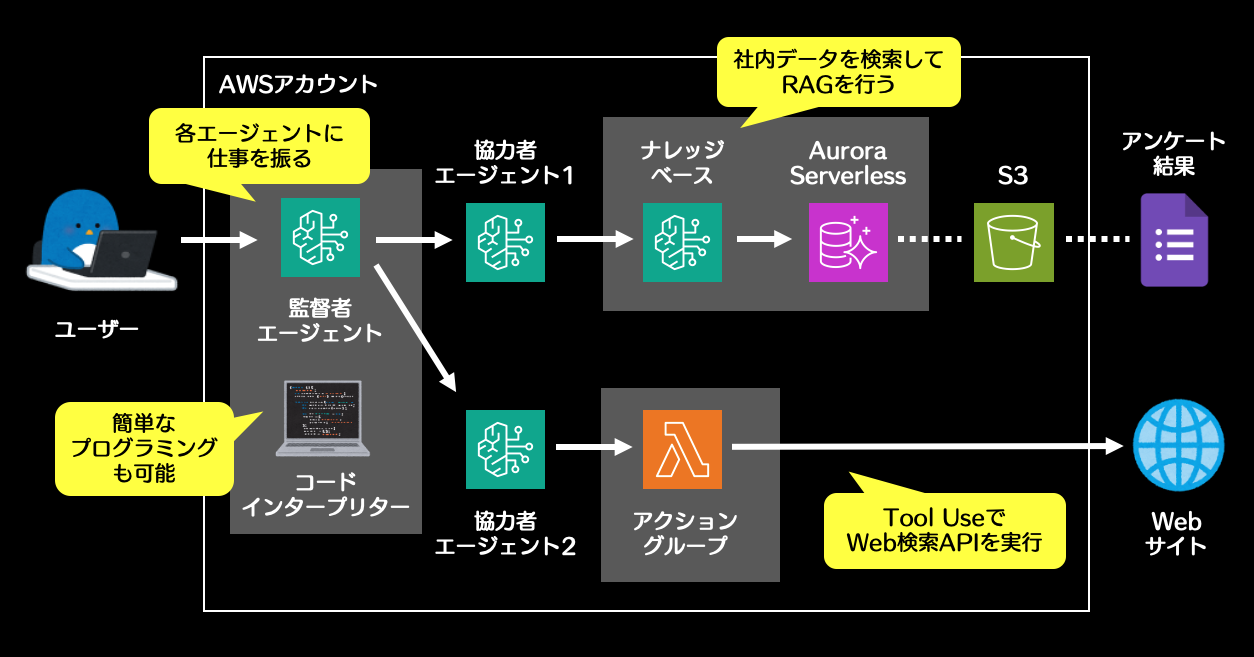
3体のAIエージェントが協働します。ユーザーの質問をもとに、監督者エージェントが2体の協力者エージェントに指示を出します。
- 協力者エージェント1は、Googleフォームの社内アンケート結果を参照して、自社の生成AIユースケースを分析します。
- 協力者エージェント2は、アクショングループでLambdaを実行します。TavilyというWeb検索サービスのAPIを呼び出して、既存製品や他社事例の市場調査を行います。
ハンズオンを実施すると、多少のAWS利用料が発生します。数十円以内を想定していますが保証はできません。ご自身の責任で実施ください。
これまではRAG用のベクトルDBの維持コストが結構かかっていましたが、最近登場したAurora Serverlessの「ナレッジベースからのクイック作成対応」と「アイドル時のゼロスケール対応」という新機能をフル活用することで、使っていない間は自動縮退するベクトルDBを簡単に構築できるようになりました!
事前準備
以下を参考に、AWSアカウントを作成してください。クレジットカードの登録が必要です。
※ハンズオン終了後に解約される場合は、メールアドレスが再利用できなくなるためフリーメール等の不要なアドレスで登録されることをお勧めします。
アカウント作成後、登録したメールアドレスを使って「ルートユーザー」としてサインインして始めましょう。
AWSマネジメントコンソールにサインインしたら、画面右上のリージョン設定を米国(オレゴン)に変更しておいてください。
このハンズオンは、すべてオレゴンリージョンで実施します。新規AWSアカウントではBedrockモデルの初期クォータ値が低いなかで、最も制限の緩いリージョンのためです。
【手順1】 作業用IAMユーザーの作成
マネジメントコンソール上部の検索バーで「IAM」を検索し、IAMコンソールへ移動します。
IAMコンソール左側の「ユーザー」 > 画面右の「ユーザーの作成」をクリックして、以下のとおり設定します。(記載ないものはデフォルトでOK)
ステップ1:
- ユーザー名:
handson - AWSマネコンへのアクセスを提供する: チェックを入れる
- ユーザータイプ: IAMユーザーを作成します
- コンソールパスワード: カスタムパスワードを選択し、パスワードを決めて入力(この後すぐ使います)
- ユーザーは次回サインイン時に新しいパスワード作成が必要: チェックを外す
ステップ2:
- 許可のオプション:ポリシーを直接アタッチする
- 許可ポリシー:上から2つ目の「AdministratorAccess」にチェック
ステップ3で「ユーザーの作成」をクリックして、作成完了画面で「コンソールサインインURL」をコピーしておきます。
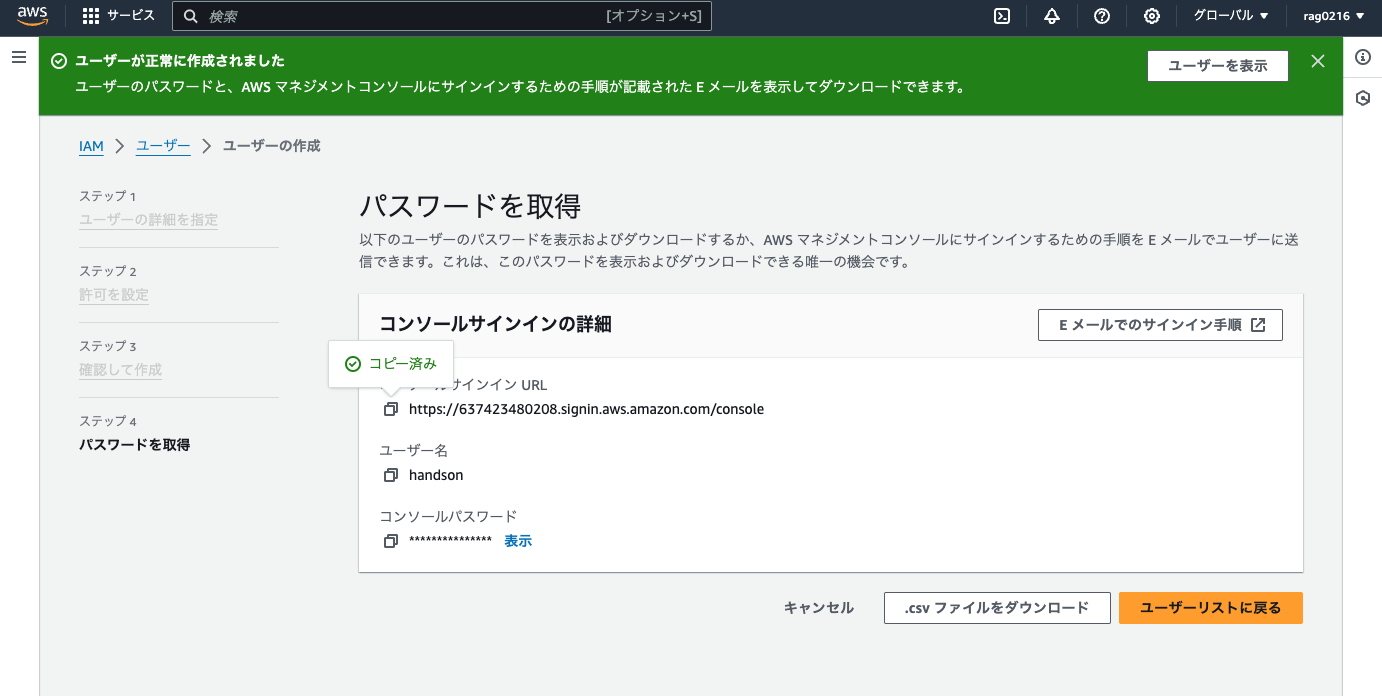
マネジメントコンソール右上のAWSアカウント名をクリックして「サインアウト」してから、ブラウザのアドレスバーに今コピーした「サインインURL」を貼り付けてアクセスします。
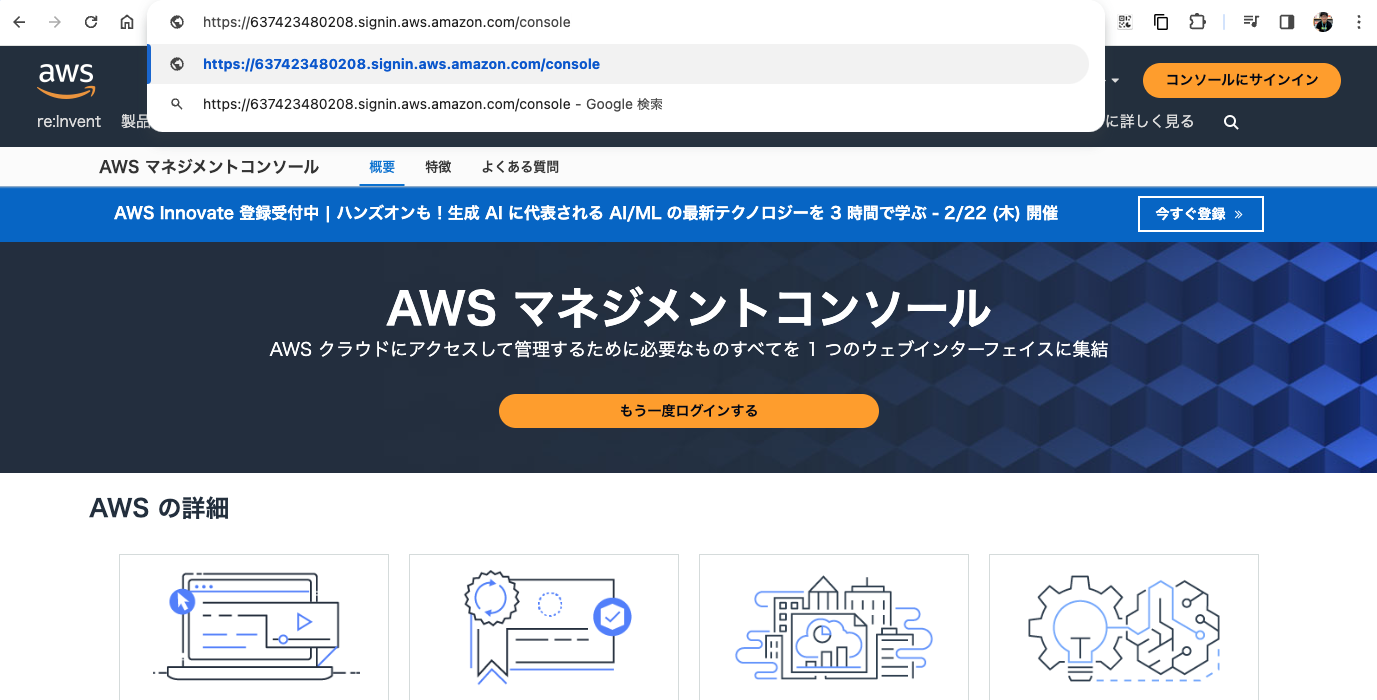
すると、専用URLを使ったおかげで「アカウントID」が入力済みのサインイン画面に飛びます。以下を入力して、IAMユーザーでサインインします。
- ユーザー名:
handson - パスワード: 先ほど設定したIAMユーザー用のパスワード
このハンズオンは、すべてオレゴンリージョンで実施します。画面右上のリージョン表示を確認し、オレゴンでない場合は切り替えておいてください。
【手順2】 協力者エージェント1(RAG担当)の作成
2-1. S3バケットの作成
マネジメントコンソール上部の検索バーから「S3」を探してアクセスし、「バケット作成」をクリックして以下の設定で新規バケットを作成します。(記載ないものはデフォルトでOK)
- AWSリージョン: 米国西部 (オレゴン) us-west-2 ※確認のみ
- バケット名:
handson-(年月日の数字)-(あなたのニックネームなど)
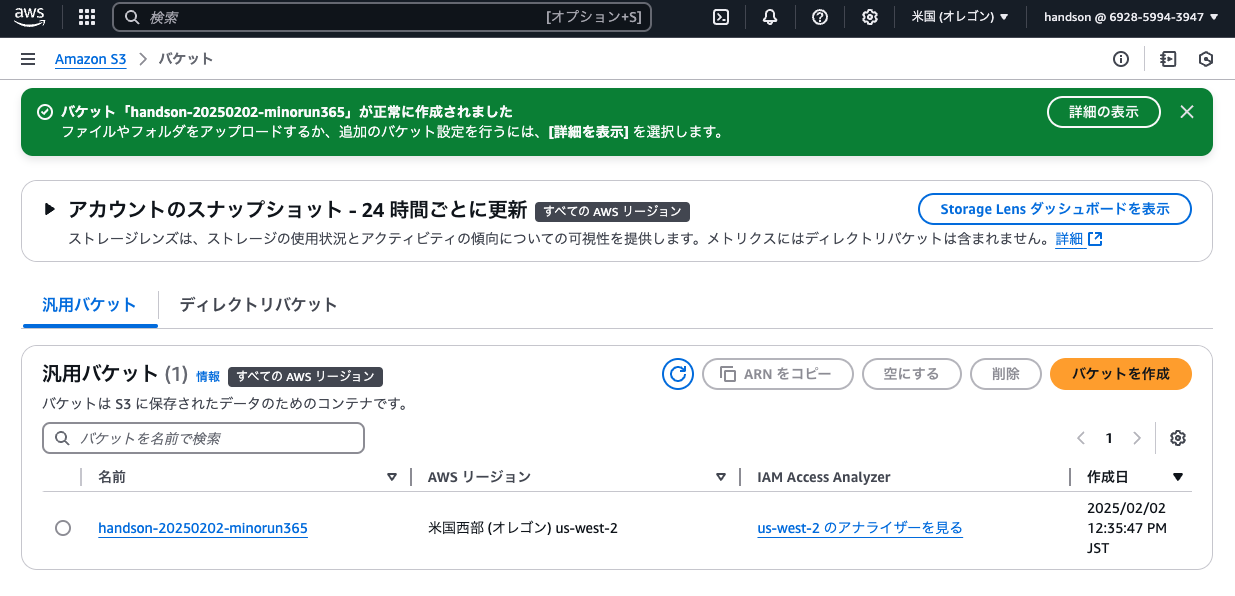
作成されたバケット名をクリックして開き、オレンジ色の「アップロード」ボタンから以下CSVファイルをアップロードしましょう。
作業PCのローカルでメモ帳などを開き、下記の内容をコピペして survey.csv という名前でPC上に保存してから、上記S3バケットにアップロードしましょう。
"タイムスタンプ","職種","年齢","生成AIの活用頻度","生成AI活用の課題","業務上の課題"
"2025/02/02 9:49:45 午前 GMT+9","営業","35","週に1回以上","機密情報を入れられない","商談の議事録作成に工数がかかっている"
"2025/02/02 9:50:50 午前 GMT+9","社内SE","32","月に1回以上","業務のどこで生成AIを使えばいいか分からない","他部署との調整業務が多く自動化しづらい"
"2025/02/02 9:52:44 午前 GMT+9","人事","42","毎日","最新情報が学習されていない","Excelで処理すべきデータがとても多い"
"2025/02/02 9:54:08 午前 GMT+9","営業","25","毎日","回答に嘘が混じっているか分からない","まだ年次が浅いため業務経験が少ない"
"2025/02/02 9:55:41 午前 GMT+9","マーケティング","51","ほとんど使っていない","自分の業務のどこで生成AIが使えるか分からない","プレスリリースの文章チェックが大変"
参考まで、CSVには以下のようなGoogleフォームの回答が記録されています。
| タイムスタンプ | 職種 | 年齢 | 生成AIの活用頻度 | 生成AI活用の課題 | 業務上の課題 |
|---|---|---|---|---|---|
| 2025/02/02 9:49:45 午前 GMT+9 | 営業 | 35 | 週に1回以上 | 機密情報を入れられない | 商談の議事録作成に工数がかかっている |
| 2025/02/02 9:50:50 午前 GMT+9 | 社内SE | 32 | 月に1回以上 | 業務のどこで生成AIを使えばいいか分からない | 他部署との調整業務が多く自動化しづらい |
| 2025/02/02 9:52:44 午前 GMT+9 | 人事 | 42 | 毎日 | 最新情報が学習されていない | Excelで処理すべきデータがとても多い |
| 2025/02/02 9:54:08 午前 GMT+9 | 営業 | 25 | 毎日 | 回答に嘘が混じっているか分からない | まだ年次が浅いため業務経験が少ない |
| 2025/02/02 9:55:41 午前 GMT+9 | マーケティング | 51 | ほとんど使っていない | 自分の業務のどこで生成AIが使えるか分からない | プレスリリースの文章チェックが大変 |
2-2. Bedrockナレッジベースの作成
繰り返しますが、この手順はルートユーザーで実施するとエラーになります。IAMユーザーで実施してください。
マネジメントコンソール上部の検索バーに bedrock と入力して、Amazon Bedrockのコンソールに移動します。
画面左側のメニューから「ナレッジベース」をクリックし、画面右側の「ナレッジベースを作成 > Knowledge Base with vector store」から以下の設定でナレッジベースを作成します。(記載ないものはデフォルトでOK)
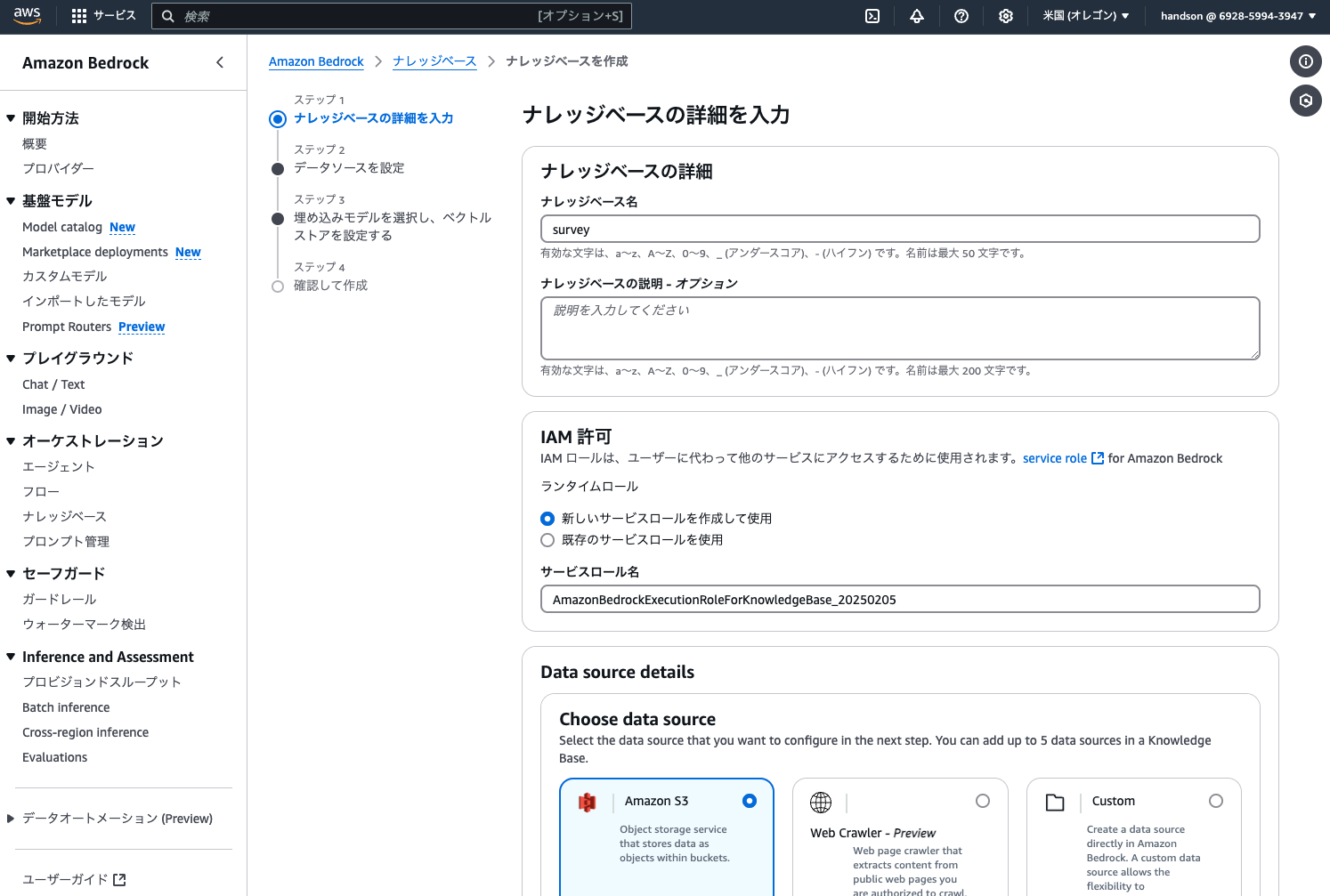
ステップ1:
- ナレッジベース名:
survey
ステップ2:
- データソース名:
survey - S3 URI:「S3を参照」ボタンから先ほど作成したバケットを選択
ステップ3:
- 埋め込みモデル:Embed Multilingual v3
- Vector store:Amazon Aurora PostgreSQL Serverless
上記設定により、オレゴンリージョンのデフォルトVPCにAurora Serverlessクラスターが自動作成されます。デフォルトVPCを削除してしまった方は、画面右上のCloudShellより以下コマンドを実行すれば再作成できます。
aws ec2 create-default-vpc
ステップ4で「ナレッジベースを作成」をクリックすると、10分程度でAuroraクラスターとナレッジベースが自動作成されます。待っている間、次の作業に進みましょう。
2-3. Bedrockモデルアクセスの有効化
Bedrockコンソールの左メニュー下方にある「モデルアクセス」をクリックし、「すべてのモデルを有効にする」をクリックします。
ステップ1:
そのまま「次へ」をクリック
ステップ2:
Bedrockの用途を申告します。内容はざっくりでOKです。
- 会社名/ウェブサイト/業界:あなたの会社情報を入力
- 対象ユーザー:「社内の従業員」にチェック
- ユースケースの説明:
個人検証
ステップ3で「送信」をクリックすると、1分程度でモデルアクセスが承認されます。
一部の古いモデル(ClaudeとClaude 3 Opus)でエラーが出ることがありますが、今回使わないため気にせずでOKです。
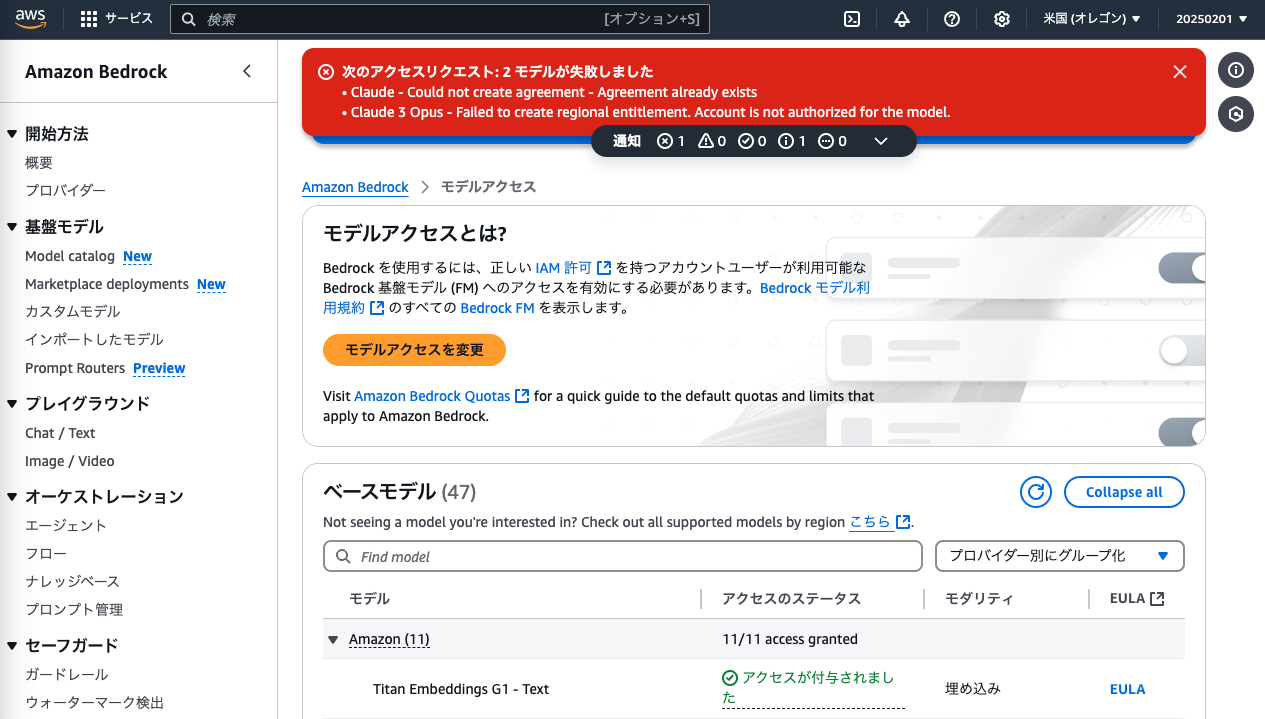
モデル有効化した数だけ、AWSマーケットプレイスからの通知メールが飛んできますが気にしなくてOKです。
完了を待たずにそのまま次の作業へ進みましょう。
2-4. Bedrockエージェントの作成
このナレッジベースを持たせたAIエージェントを作成しましょう。
Bedrockコンソール画面左側のメニューから「エージェント」をクリックし、「エージェントを作成」をクリックして以下のとおり設定します。(記載ないものはデフォルトでOK)
エージェントを作成:
- 名前:
survey
エージェントビルダー > エージェントの詳細:
- モデルを選択:Anthropic > Claude 3.5 Haiku > US Anthropic Claude 3.5 Haiku(推論プロファイル) ※オンデマンドではなく、必ず推論プロファイルを選択してください。
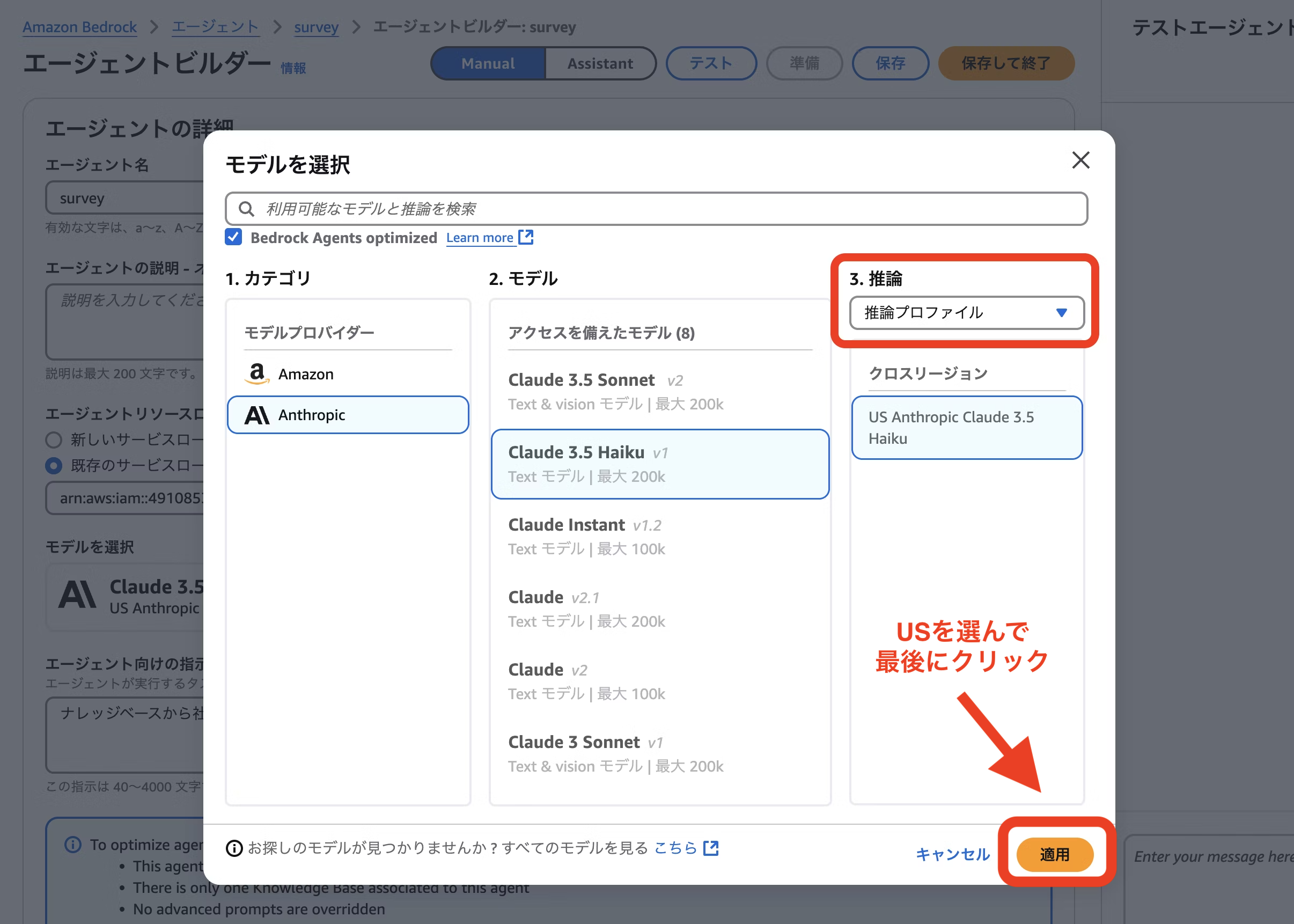
- エージェント向けの指示:
ナレッジベースから社内アンケート結果を取得して、生成AIユースケース検討のヒントを提供してください。
ここまで入力したら、画面上部の「保存」をクリックします。
次に画面下部の「ナレッジベース > 追加」をクリックし、以下のとおり設定します。
- ナレッジベースを選択:survey
- エージェント向けのナレッジベースの指示:
社内向けの生成AI活用アンケートの結果が格納されています。
まだナレッジベースの作成が完了していない場合は、「survey」がリストに表示されません。待っている間、ブラウザの別タブを開いて、後続の手順3-1を先に実施しておいてください。
更新ボタンをクリックすると、ナレッジベースの最新状況を取得できます。
設定後はエージェントビルダーを「保存して終了」し、画面右側のテスト用サイドバーにある「準備」ボタンを押したのち、「エイリアスを作成」を実施しましょう。
- エイリアス名:
v1
2-5. ナレッジベースの同期
Bedrockコンソール左側からナレッジベースの画面を開き、先ほど作成した「survey」ナレッジベースをクリックして作成状況を確認します。
ナレッジベースの作成が完了していたら、画面中段の「データソース」から「survey」にチェックを入れ、「同期」をクリックします。
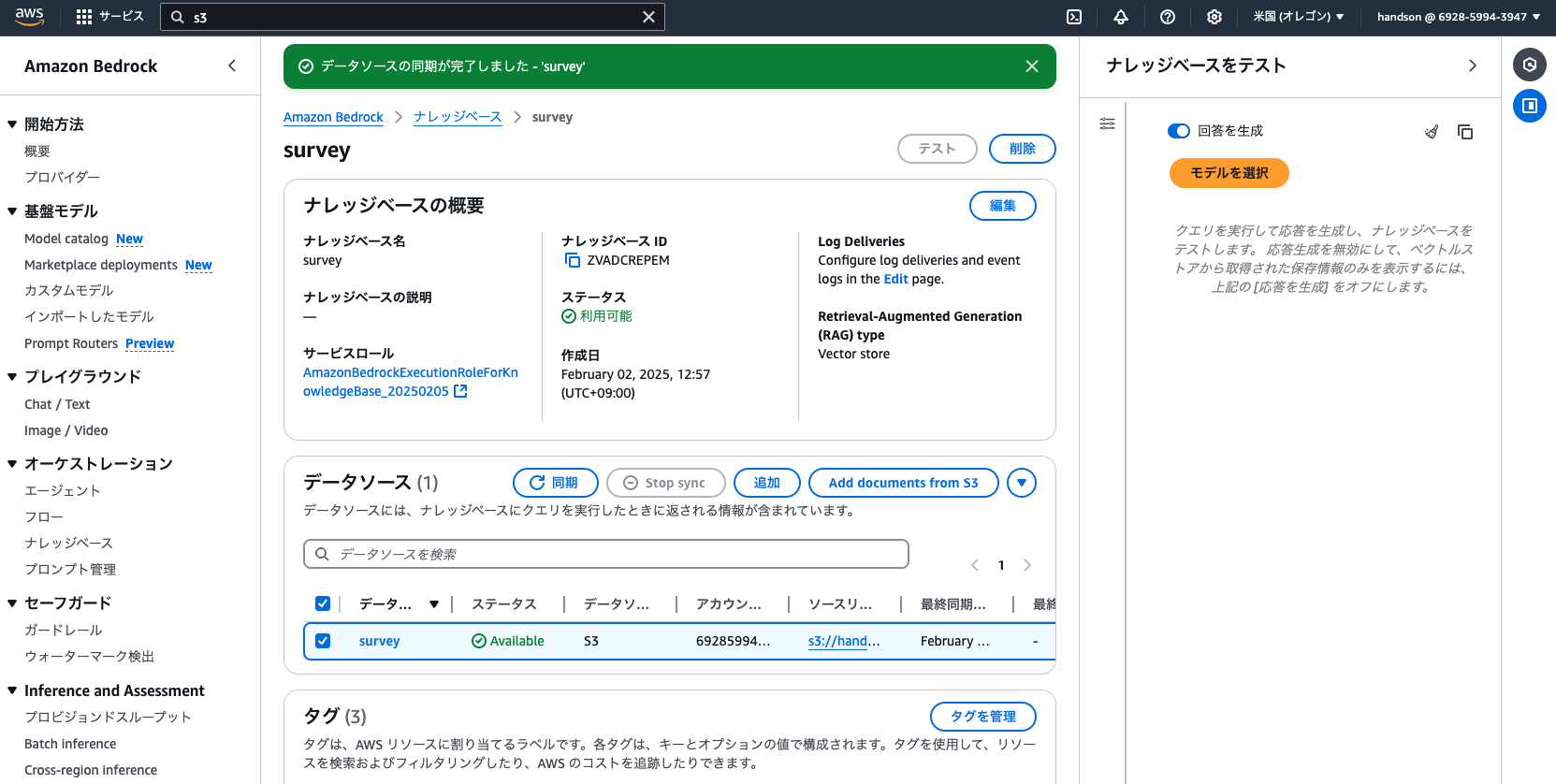
これでS3上のCSVデータが、Cohereの埋め込みモデルによってベクトルに変換されて、Aurora Serverlessに登録されました。
【手順3】 協力者エージェント2(Web検索担当)の作成
3-1. Tavily APIキーの取得
BedrockエージェントにWeb検索を実行させるため、Tavilyという検索サービスを利用します。APIの利用にユーザー登録が必要なため、以下のサイトよりサインアップしましょう。
GoogleやGitHubアカウントを使って簡単にアカウント作成できます。なんと無料で月1,000回までAPIを実行できます。
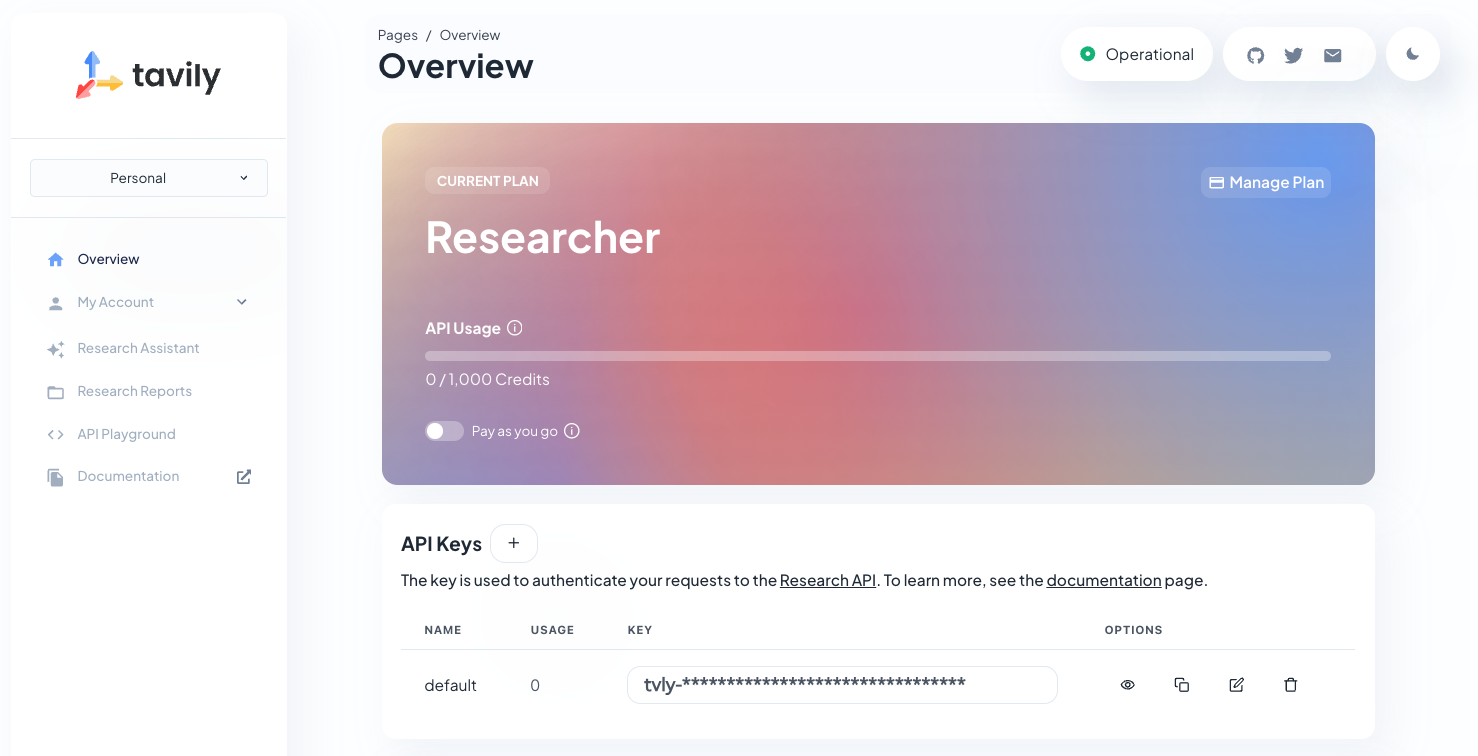
上記の画面でAPIキーをコピーできます。後で使うので、タブを開いておいてください。
3-2. Bedrockエージェントの作成
Bedrockコンソールに戻り、画面左側のメニューから「エージェント」をクリックし、「エージェントを作成」をクリックして2体目のエージェントを設定します。
エージェントを作成:
- 名前:
web-search
エージェントビルダー > エージェントの詳細:
- モデルを選択:Anthropic > Claude 3.5 Sonnet v2 > US Anthropic Claude 3.5 Sonnet v2(推論プロファイル) ※オンデマンドではなく、必ず推論プロファイルを選択してください。
- エージェント向けの指示:
「web-search」ツールでWeb検索を行い、生成AIユースケースの事例や既存サービスを調査してください。
モデルの負荷分散のため、エージェントは3体とも利用するClaudeモデルを微妙に変えています。注意して設定してください。
ここまで入力したら、画面上部の「保存」をクリックします。
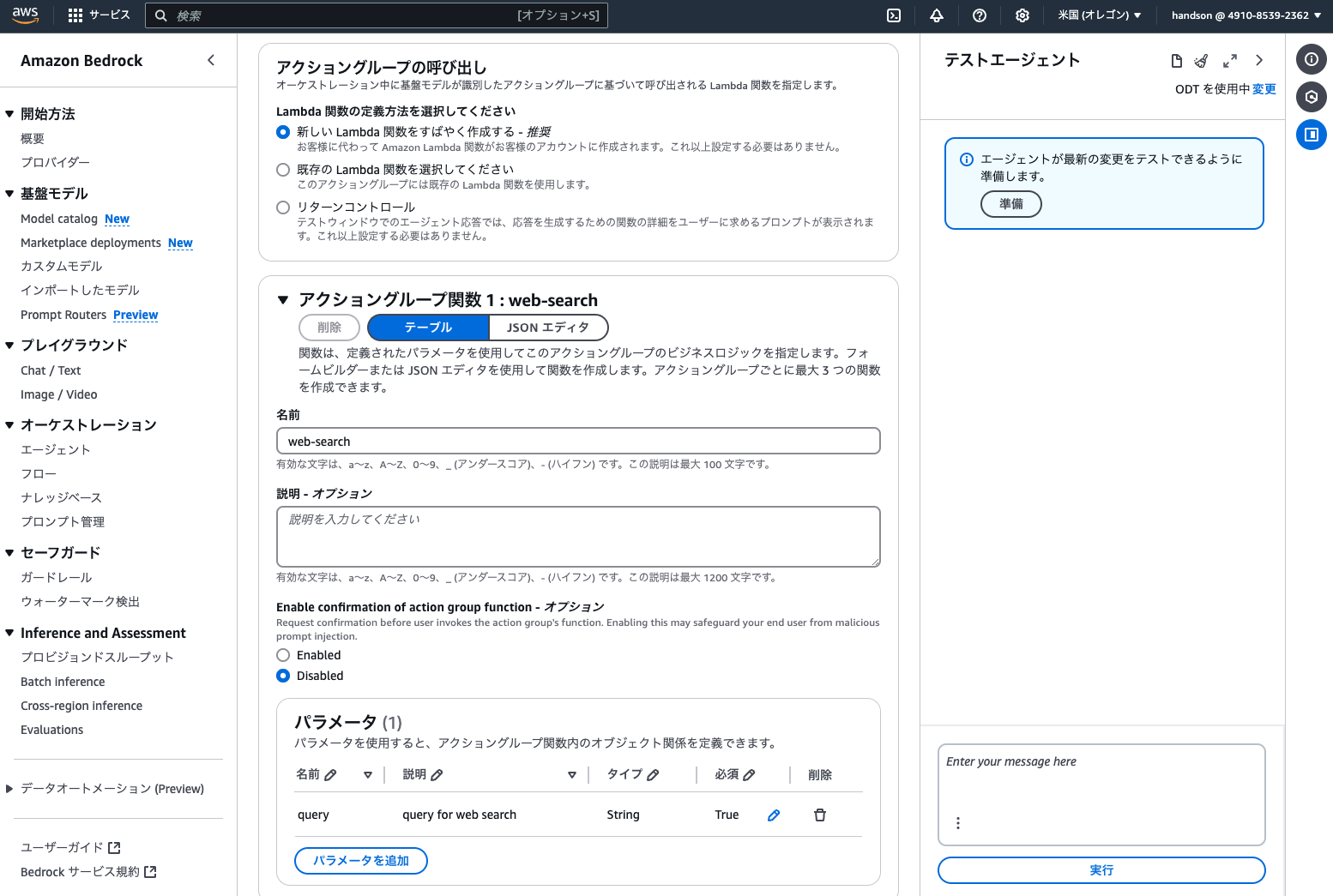
次に画面下部の「アクショングループ > 追加」をクリックし、以下のとおり設定します。
- アクショングループ名を入力:
web-search - アクショングループ関数 1
- 名前:
web-search - パラメータ:以下のとおり
- 名前:
| 名前 | 説明 | タイプ | 必須 |
|---|---|---|---|
| query | query for web search | String | True |
「作成」をクリックしたら、エージェントビルダーを「保存して終了」します。
その後、画面右側のテスト用サイドバーにある「準備」ボタンを押したのち、「エイリアスを作成」を実施しましょう。
- エイリアス名:
v1
3-3. Lambdaの設定
Bedrockエージェントでアクショングループを作成したことにより、Lambda関数が自動で作成されています。マネジメントコンソールから「Lambda」に移動し、追加の設定を実施しましょう。
最初に画面右上の [>_] アイコンをクリックしてCloudShellを起動し、Lambdaレイヤー用のZIPファイルを作成します。
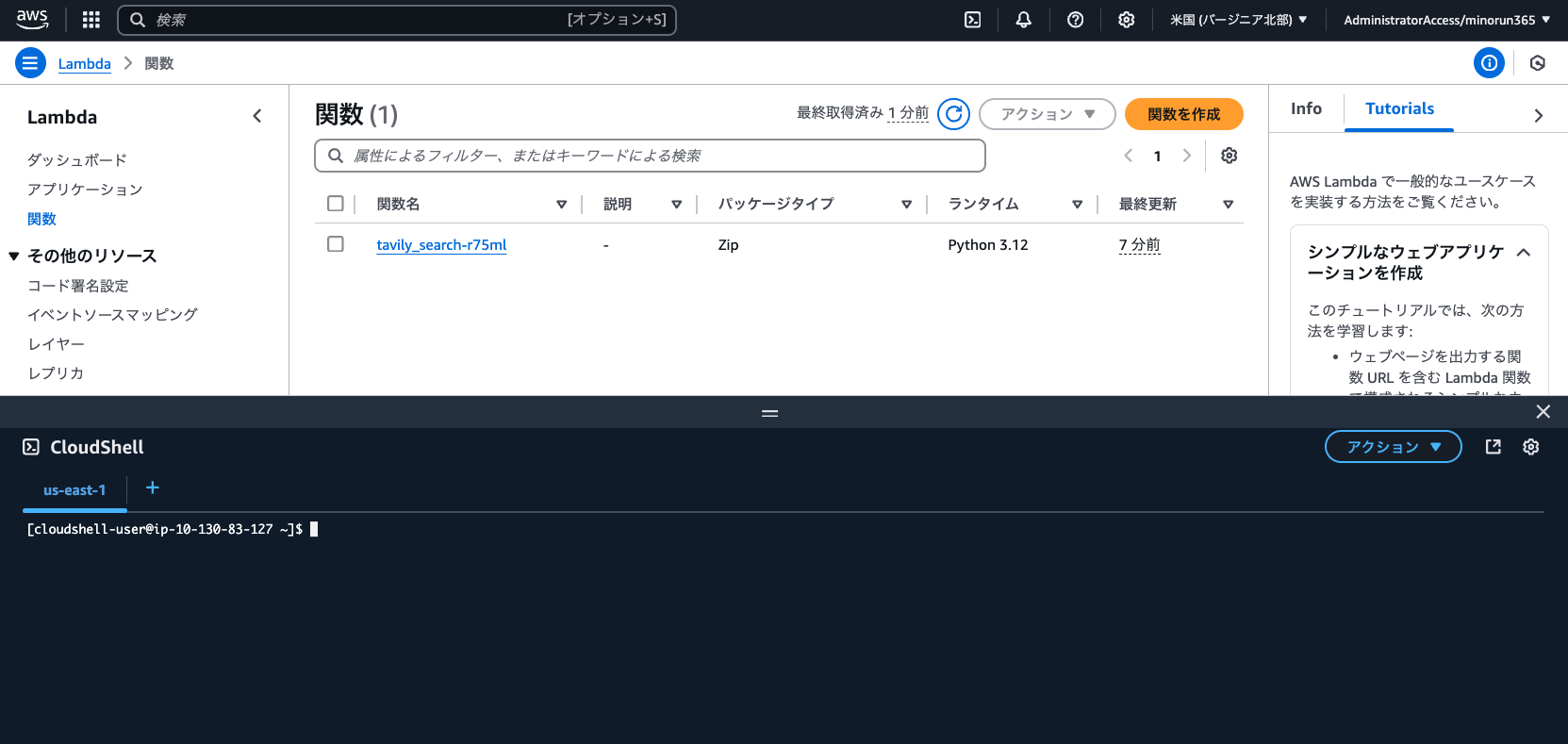
下記コマンドをコピーして実行しましょう。(複数行の貼り付け警告が出ますが「貼り付け」をクリックします)
# インストール用ディレクトリを作成
mkdir python
# TavilyのPython用ライブラリをインストール
pip install tavily-python --target python
# インストールしたディレクトリを圧縮
zip -r layer.zip python
pip installコマンドでライブラリの依存性エラーが表示されることがありますが、無視して問題ありません。
実行後、CloudShell右上の「アクション > ファイルのダウンロード」から layer.zip と入力し、ZIPファイルをダウンロードしておきます。
その後、Lambdaコンソール左メニューの「レイヤー」より、「レイヤーの作成」を実施します。
- レイヤー名:
Tavily - 「.zip ファイルをアップロード」より、上記のZIPファイルをアップロード
- 互換性のあるアーキテクチャ:「x86_64」にチェック
- 互換性のあるランタイム:Python 3.9
設定したら「作成」をクリックします。
その後、左メニュー( ≡ )を開いて「関数」より、「web-search-(ランダム文字列)」に移動し、以下のとおり設定します。(記載ないものはデフォルトでOK)
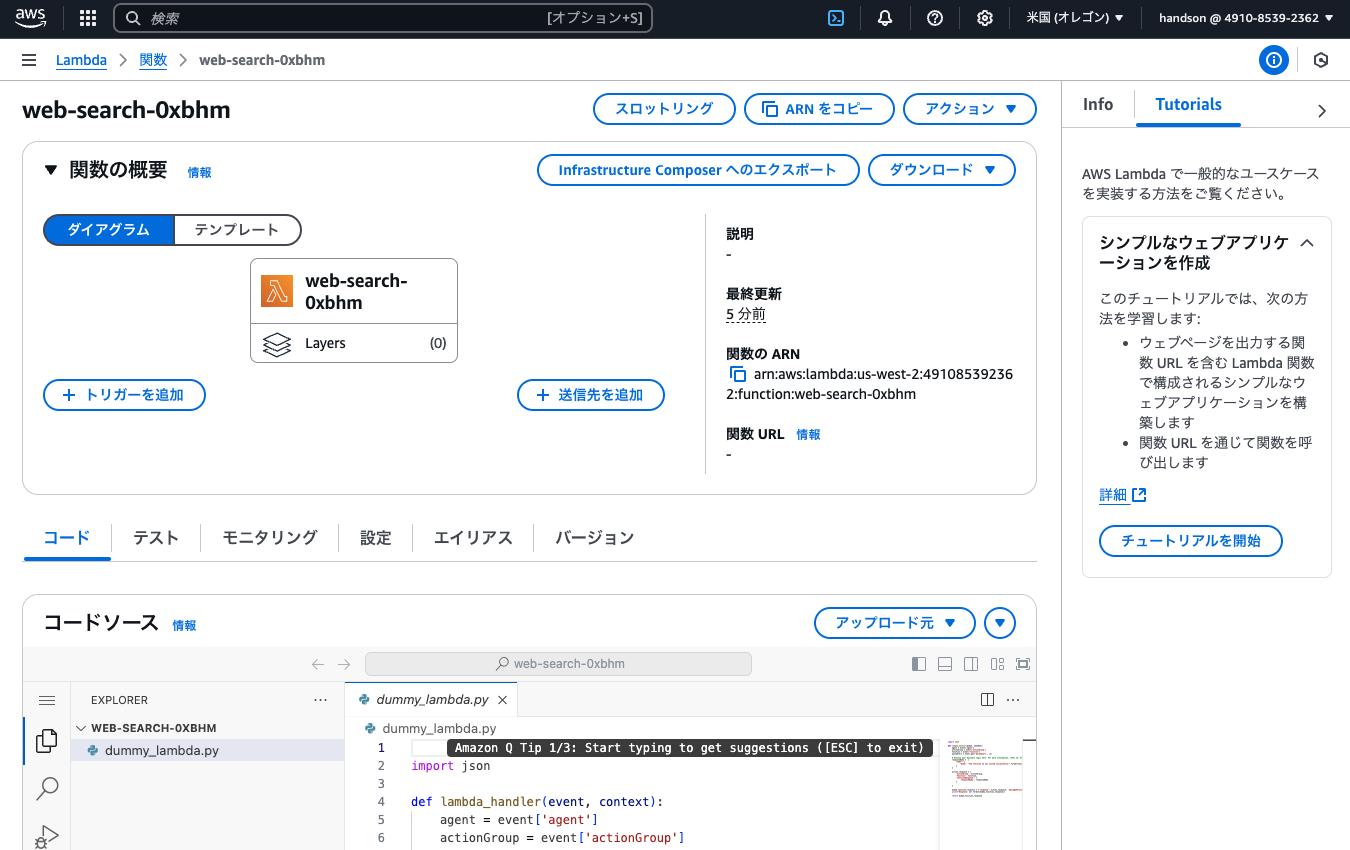
「コード」タブ:
- コードソース:
dummy_lambda.pyを以下コードで上書きし「Deploy」を実行
import os
import json
from tavily import TavilyClient
def lambda_handler(event, context):
# 環境変数からAPIキーを取得
tavily_api_key = os.environ.get('TAVILY_API_KEY')
# eventからクエリパラメータを取得
parameters = event.get('parameters', [])
for param in parameters:
if param.get('name') == 'query':
query = param.get('value')
break
# Tavilyクライアントを初期化して検索を実行
client = TavilyClient(api_key=tavily_api_key)
search_result = client.get_search_context(
query=query,
search_depth="advanced",
max_results=10
)
# 成功レスポンスを返す
return {
'messageVersion': event['messageVersion'],
'response': {
'actionGroup': event['actionGroup'],
'function': event['function'],
'functionResponse': {
'responseBody': {
'TEXT': {
'body': json.dumps(search_result, ensure_ascii=False)
}
}
}
}
}
- ランタイム設定:「編集」より以下を設定
- ランタイム:Python 3.9 ※CloudShellと合わせる
- レイヤー:「レイヤーの追加」より以下を設定
- レイヤーソース:カスタムレイヤー
- カスタムレイヤー:Tabily
- バージョン:1
「設定」タブ:
- 一般設定:「編集」より以下を設定
- タイムアウト:0分30秒
- 環境変数:「編集 > 環境変数の追加」から以下を設定
| キー | 設定 |
|---|---|
| TAVILY_API_KEY | 手順3-1のTavily APIキーをコピーして入力 |
今回はTavily無料枠を使った簡易検証のため、APIキーを環境変数に登録していますが、本格利用の際はAWS Secret Manager等を用いてセキュアに保存しましょう。
【手順4】 監督者エージェントの作成
Bedrockコンソールに戻り、画面左側のメニューから「エージェント」をクリックし、「エージェントを作成」をクリックして3体目のエージェントを設定します。
エージェントを作成:
- 名前:
usecase-advisor
エージェントビルダー > エージェントの詳細:
- モデルを選択:Anthropic > Claude 3.5 Sonnet v1 > US Anthropic Claude 3.5 Sonnet v1(推論プロファイル) ※オンデマンドではなく、必ず推論プロファイルを選択してください。
- エージェント向けの指示:
あなたは生成AI活用の専門家です。ユーザーに対して、社内の生成AI活用ユースケースをアドバイスしてください。ユーザーの社内での生成AI活用状況を把握するために、surveyエージェントから社内情報を取得してください。また、Web上の事例や既存サービスを調査するために、web-searchエージェントから最新情報を取得してください。もし現在日時の取得が必要な場合は、Code Interpreterを利用してPythonコードを実行してください。 - その他の設定(クリックして展開)
- Code Interpreter:有効
ここまで入力したら、画面上部の「保存」をクリックします。
モデルの負荷分散のため、エージェントは3体とも利用するClaudeモデルを微妙に変えています。注意して設定してください。
次に、画面下段の「Multi-agent collaboration」の「編集」をクリックして、以下のとおり設定します。
- Multi-agent collaboration:オン
- Agent collaborator(1件目)
- Collaborator agent:survey
- Agent alias:v1
- Collaborator name:
survey - Collaborator instruction:
社内の生成AI活用アンケート結果を取得します。
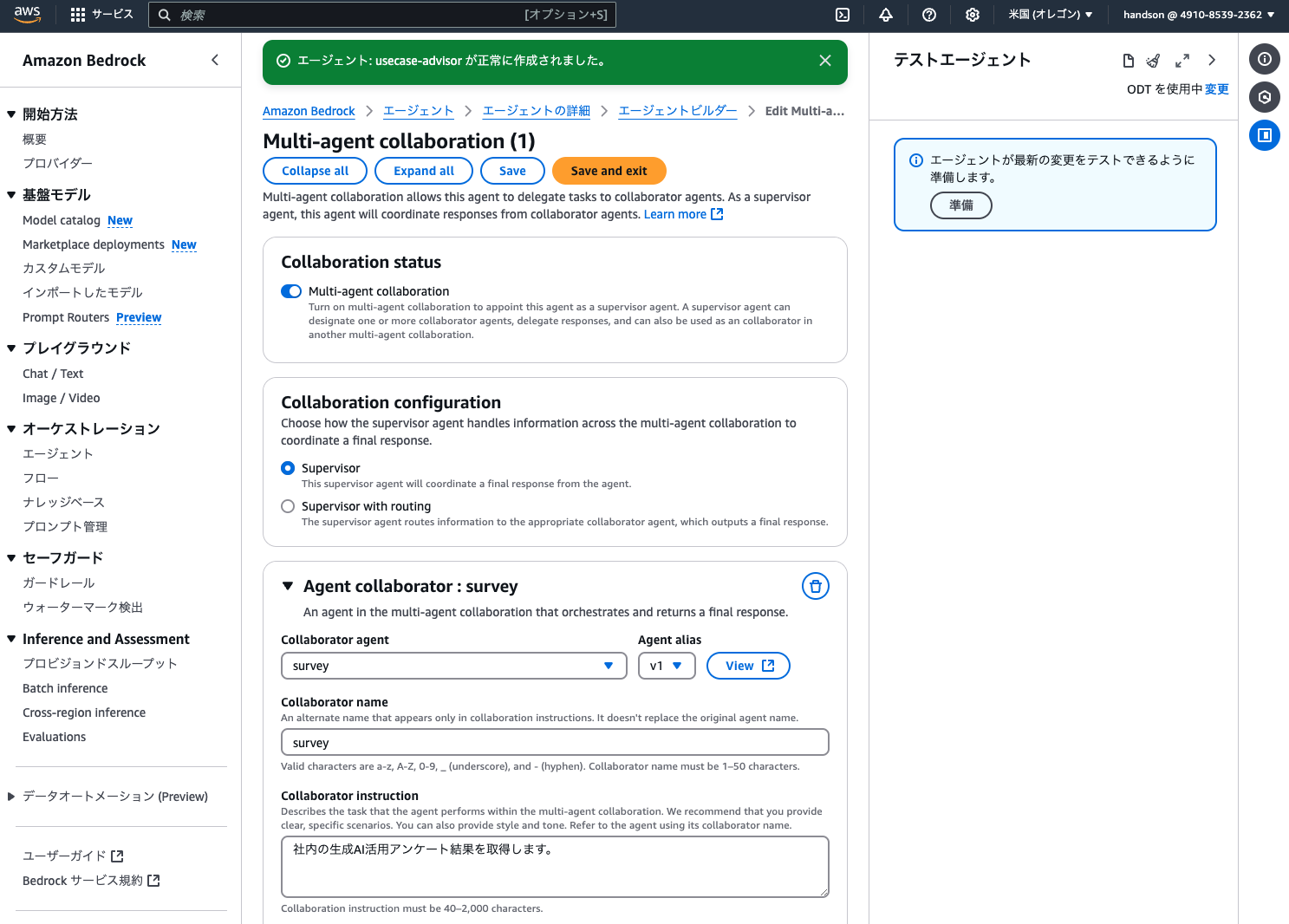
エージェントコラボレーターを2件一度に保存するとエラーになることがあるため、ここで一度「Save」ボタンをクリックします。(プレビュー中の新機能のため、恐らくマネジメントコンソールのバグかも知れません)
その後、画面最下部の「Add collaborator」をクリックして、2件目のサブエージェントを設定します。
- Agent collaborator(2件目)
- Collaborator agent:web-search
- Agent alias:v1
- Collaborator name:
web-search - Collaborator instruction:
Web検索を行って生成AI活用事例や既存サービスの最新情報を取得します。
最後に「Save and exit」をクリックし、エージェントビルダーも「保存して終了」します。
画面右側のテスト用サイドバーにある「準備」ボタンを押したのち、「エイリアスを作成」を実施しましょう。
- エイリアス名:
v1
これで3体のAIエージェントの構築が完了しました!
画面右側のテスト用サイドバーから、監督者エージェントとのチャットを試してみましょう。
質問の例: 弊社の営業担当向けに生成AIアプリを開発したいです。アンケート結果をふまえて、良いアイディアはありますか?
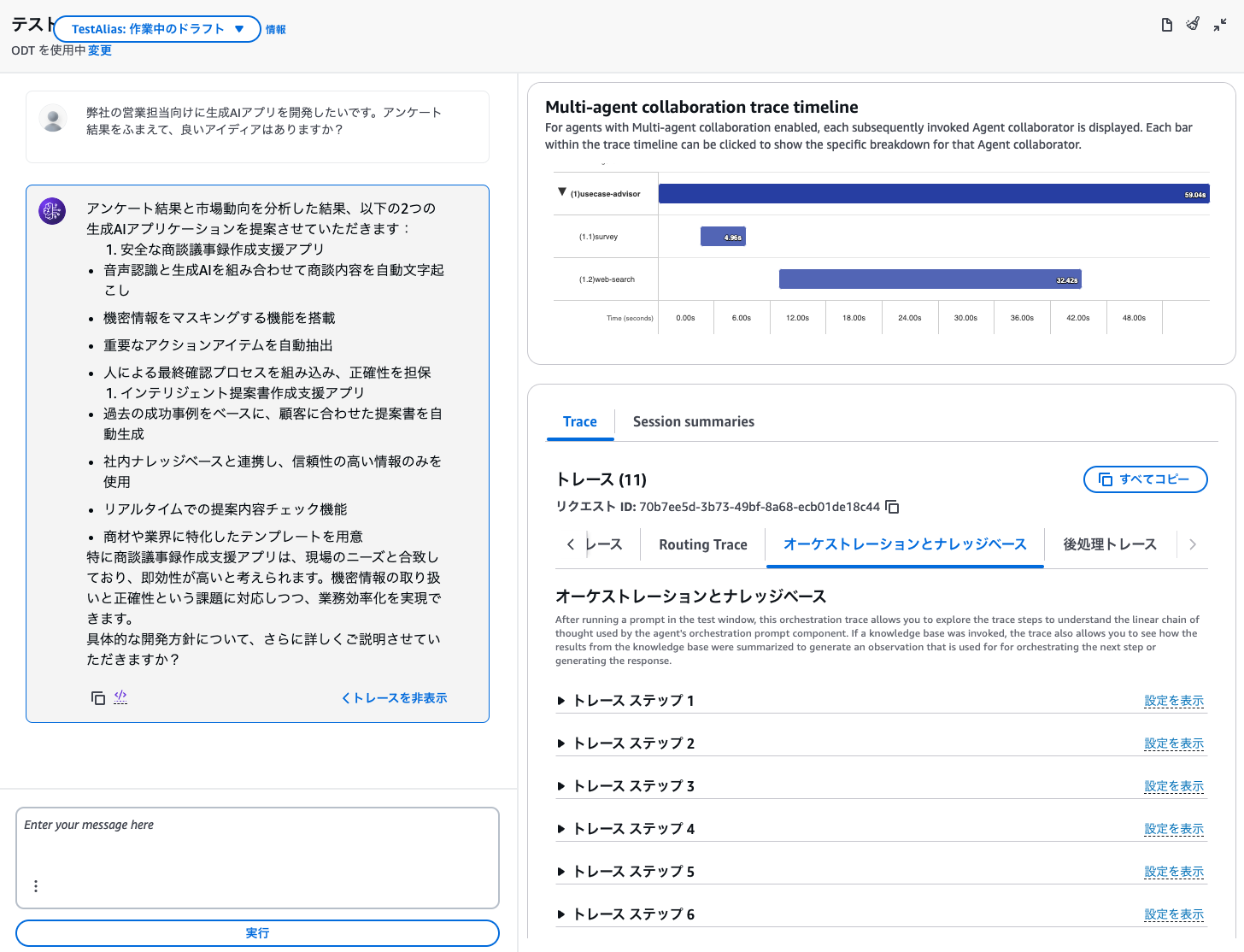
「トレースを表示」をクリックすると、裏で3体のエージェントがどのように動作しているか眺めることができます。
※この監督者エージェントのID(画面上部)と、「エイリアスID(画面最下部)」の2つをメモしておきましょう。この後すぐ使います。
エラーになった場合の確認ポイント
この段階でエラーが発生してしまう方は、以下のあたりを重点的に確認してみてください。
- 各エージェントに設定するClaudeモデルで「オンデマンド」ではなく「推論プロファイル」を選択できているか?(リージョン固定だとクォータ制限に引っかかりやすい)
- ナレッジベースの「同期」を忘れていないか?(手順2-5)
- Lambdaの設定項目をどこか漏らしていないか?(手順3-3)
- Lambdaのエラーの場合、CloudWatch LogsからPythonのエラーログが出ていないか確認
協力者エージェントの設定を変更したときは、新しいエイリアスを作成し、監督者エージェントのコラボレーション設定も更新する必要があります。
その際、コラボレーション設定画面で協力者エージェント名を変更しないとエラーになるため、少しだけ名前を変えてみてください。また、最後に監督者エージェントのエイリアスも再発行する必要があるため注意してください。
手順どおりに設定しても、下記のレートリミット抵触エラーが出てしまう際は、監督者エージェントのモデルを「Claude 3 Sonnet」の推論プロファイルに設定してみてください。
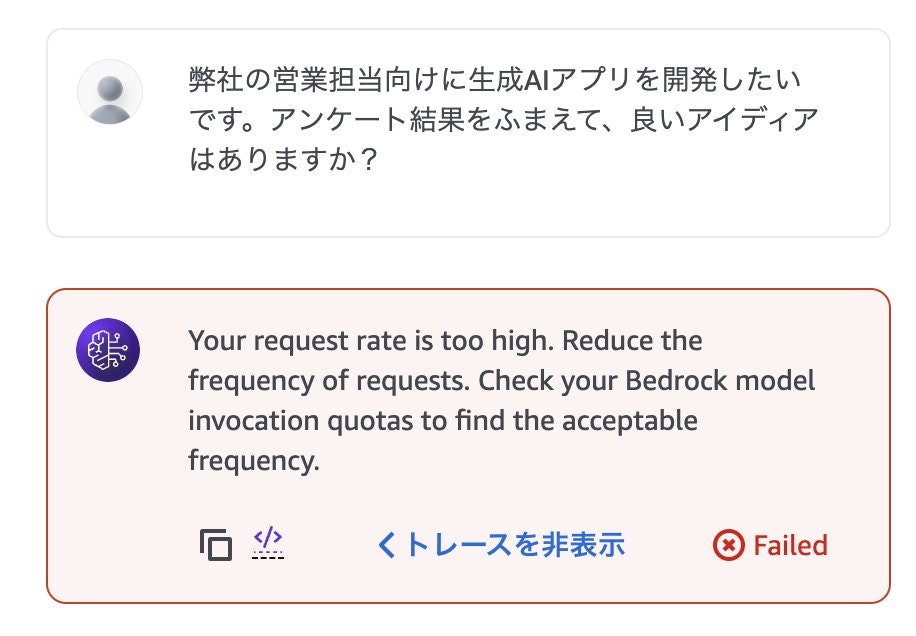
なお、Bedrockは世界的に需要が高く、新規作成したばかりのAWSアカウントでは初期クォータがかなり低く設定されています。
本ハンズオンではクロスリージョン推論を活用し、さらに3体のエージェントでモデルを変えるという最大限の対策を実施していますが、それでもレートリミットに抵触してしまう場合は、数日かかりますがAWSサポートにリクエストを上げるとクォータを緩和してもらえます。
※参考:今回、モデル負荷分散する際のアサイン検討経緯は以下です。
| エージェント | 使用モデル | 初期クォータの例(US合計) | アサイン理由 |
|---|---|---|---|
| 協力者(RAG) | Claude 3.5 Haiku | 70 RPM | 推論性能を下げても支障が少ない |
| 協力者(Web検索) | Claude 3.5 Sonnet v2 | 5 RPM | Tool Use失敗率を下げたい(最重要) |
| 監督者 | Claude 3.5 Sonnet v1 | 4 RPM | そこそこの推論性能を維持したい |
【手順5】 Pythonフロントエンドの作成
ここまでで構築したマルチエージェントを、Pythonの簡易アプリからAPIで呼び出してみましょう。
まず、以下のソースコードを作業PCのメモ帳などに貼り付けて、8-9行目の XXXXXXXXXX 部分に先ほどメモした監督者エージェントのIDとエイリアスIDを記載してください。
その後、frontend.py という名前で作業PCのローカルに保存しましょう。
import json
import uuid
import boto3
import streamlit as st
from botocore.exceptions import ClientError
from botocore.eventstream import EventStreamError
agent_id = "XXXXXXXXXX" # 監督者エージェントのIDで置き換えてね
agent_alias_id = "XXXXXXXXXX" # 監督者エージェントのエイリアスIDで置き換えてね
def initialize_session():
"""セッションの初期設定を行う"""
if "client" not in st.session_state:
st.session_state.client = boto3.client("bedrock-agent-runtime")
if "session_id" not in st.session_state:
st.session_state.session_id = str(uuid.uuid4())
if "messages" not in st.session_state:
st.session_state.messages = []
if "last_prompt" not in st.session_state:
st.session_state.last_prompt = None
return st.session_state.client, st.session_state.session_id, st.session_state.messages
def display_chat_history(messages):
"""チャット履歴を表示する"""
st.title("生成AIユースケース検討くん")
st.text("社内データとWeb情報をもとに、生成AI活用のアドバイスをするよ!")
for message in messages:
with st.chat_message(message['role']):
st.markdown(message['text'])
def handle_trace_event(event):
"""トレースイベントの処理を行う"""
if "orchestrationTrace" not in event["trace"]["trace"]:
return
trace = event["trace"]["trace"]["orchestrationTrace"]
# 「モデル入力」トレースの表示
if "modelInvocationInput" in trace:
with st.expander("🤔 思考中…", expanded=False):
input_trace = trace["modelInvocationInput"]["text"]
try:
st.json(json.loads(input_trace))
except:
st.write(input_trace)
# 「モデル出力」トレースの表示
if "modelInvocationOutput" in trace:
output_trace = trace["modelInvocationOutput"]["rawResponse"]["content"]
with st.expander("💡 思考がまとまりました", expanded=False):
try:
thinking = json.loads(output_trace)["content"][0]["text"]
if thinking:
st.write(thinking)
else:
st.write(json.loads(output_trace)["content"][0])
except:
st.write(output_trace)
# 「根拠」トレースの表示
if "rationale" in trace:
with st.expander("✅ 次のアクションを決定しました", expanded=True):
st.write(trace["rationale"]["text"])
# 「ツール呼び出し」トレースの表示
if "invocationInput" in trace:
invocation_type = trace["invocationInput"]["invocationType"]
if invocation_type == "AGENT_COLLABORATOR":
agent_name = trace["invocationInput"]["agentCollaboratorInvocationInput"]["agentCollaboratorName"]
with st.expander(f"🤖 サブエージェント「{agent_name}」を呼び出し中…", expanded=True):
st.write(trace["invocationInput"]["agentCollaboratorInvocationInput"]["input"]["text"])
elif invocation_type == "ACTION_GROUP_CODE_INTERPRETER":
with st.expander("💻 Pythonコードを実行中…", expanded=False):
st.write(trace["invocationInput"]["codeInterpreterInvocationInput"])
elif invocation_type == "KNOWLEDGE_BASE":
with st.expander("📖 ナレッジベースを検索中…", expanded=False):
st.write(trace["invocationInput"]["knowledgeBaseLookupInput"]["text"])
elif invocation_type == "ACTION_GROUP":
with st.expander("💻 Lambdaを実行中…", expanded=False):
st.write(trace['invocationInput']['actionGroupInvocationInput'])
# 「観察」トレースの表示
if "observation" in trace:
obs_type = trace["observation"]["type"]
if obs_type == "KNOWLEDGE_BASE":
with st.expander("🔍 ナレッジベースから検索結果を取得しました", expanded=False):
st.write(trace["observation"]["knowledgeBaseLookupOutput"]["retrievedReferences"])
elif obs_type == "ACTION_GROUP":
with st.expander(f"🔍 Lambdaの実行結果を取得しました", expanded=False):
st.write(trace["observation"]["actionGroupInvocationOutput"]["text"])
elif obs_type == "AGENT_COLLABORATOR":
agent_name = trace["observation"]["agentCollaboratorInvocationOutput"]["agentCollaboratorName"]
with st.expander(f"🤖 サブエージェント「{agent_name}」から回答を取得しました", expanded=True):
st.write(trace["observation"]["agentCollaboratorInvocationOutput"]["output"]["text"])
def invoke_bedrock_agent(client, session_id, prompt):
"""Bedrockエージェントを呼び出す"""
return client.invoke_agent(
agentId=agent_id,
agentAliasId=agent_alias_id,
sessionId=session_id,
enableTrace=True,
inputText=prompt,
)
def handle_agent_response(response, messages):
"""エージェントのレスポンスを処理する"""
with st.chat_message("assistant"):
for event in response.get("completion"):
if "trace" in event:
handle_trace_event(event)
if "chunk" in event:
answer = event["chunk"]["bytes"].decode()
st.write(answer)
messages.append({"role": "assistant", "text": answer})
def show_error_popup(exeption):
"""エラーポップアップを表示する"""
if exeption == "dependencyFailedException":
error_message = "【エラー】ナレッジベースのAurora Serverlessがスリープしていたようです。1分ほど待ってから、ブラウザをリロードして再度お試しください🙏"
elif exeption == "throttlingException":
error_message = "【エラー】Bedrockのモデル負荷が高いようです。1分ほど待ってから、ブラウザをリロードして再度お試しください🙏(改善しない場合は、モデルを変更するか[サービスクォータの引き上げ申請](https://aws.amazon.com/jp/blogs/news/generative-ai-amazon-bedrock-handling-quota-problems/)を実施ください)"
st.error(error_message)
def main():
"""メインのアプリケーション処理"""
client, session_id, messages = initialize_session()
display_chat_history(messages)
if prompt := st.chat_input("例:弊社の営業メンバーの悩みを、生成AIで解決する良いアイディアはある?"):
messages.append({"role": "human", "text": prompt})
with st.chat_message("user"):
st.markdown(prompt)
try:
response = invoke_bedrock_agent(client, session_id, prompt)
handle_agent_response(response, messages)
except (EventStreamError, ClientError) as e:
if "dependencyFailedException" in str(e):
show_error_popup("dependencyFailedException")
elif "throttlingException" in str(e):
show_error_popup("throttlingException")
else:
raise e
if __name__ == "__main__":
main()
マネジメントコンソール右上の「 >. 」アイコンからCloudShellを再度開き、右上の「アクション > ファイルのアップロード」より上記ファイルをアップロードします。

その後、以下のコマンドを実行しましょう。
# Pythonの外部ライブラリをインストール
pip install boto3 streamlit
# Streamlitアプリを起動
streamlit run frontend.py
Streamlitのアクセス用URLが表示されたら、うまく起動しています。

その後、CloudShell上部の「+」をクリックし、2つ目の「us-west-2」ターミナルを起動して以下を実行します。
# PinggyにSSH接続し、インターネットからアクセス可能なURLを生成する
ssh -p 443 -R0:localhost:8501 a.pinggy.io
確認メッセージが出力されたら yes と入力してEnterを押すと、Pinggyという外部サービスを通じてこのアプリにアクセス可能なURLが発行されます。
下側のHTTPSの方のURLをコピーして、ブラウザの別タブからアクセスしてみましょう。

赤色の「Enter site」をクリックすると、先ほどアップロードしたPythonアプリにアクセスできます。Streamlitというフレームワークを使って、フロントエンドを表示しています。
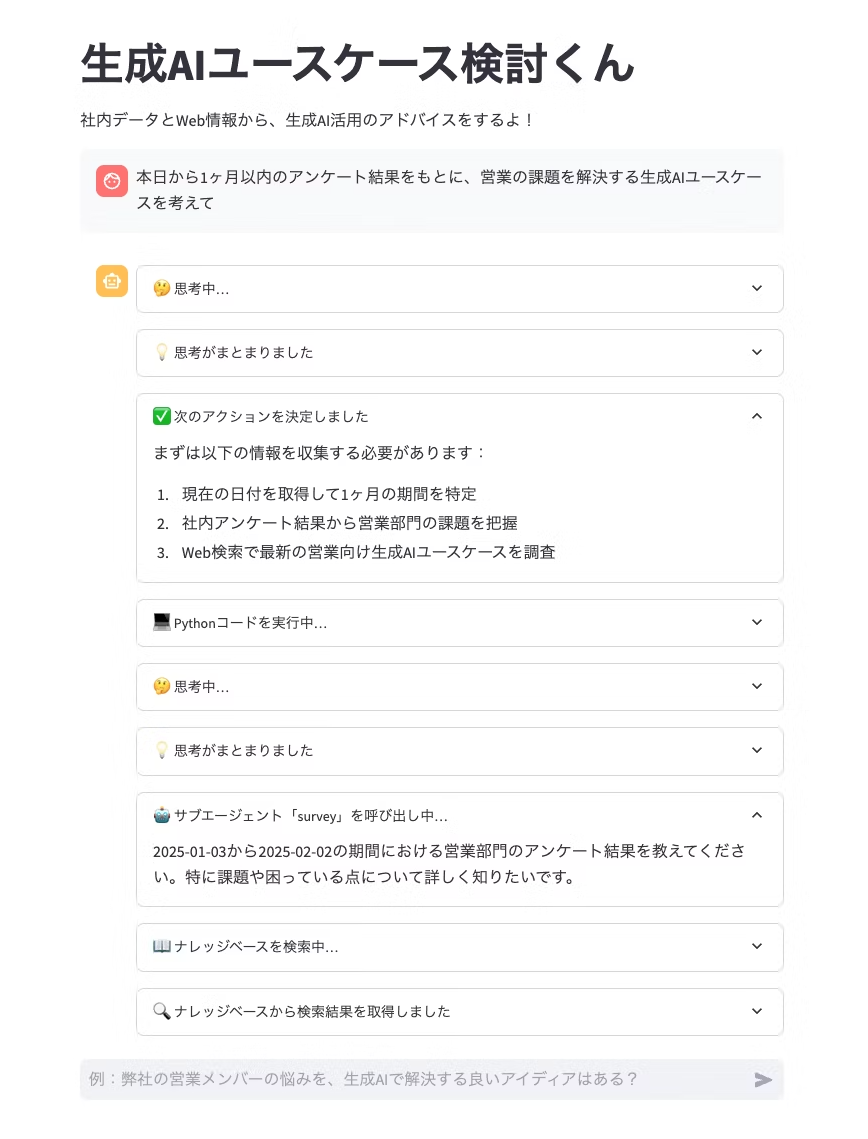
試しに 本日から1ヶ月以内のアンケート結果をもとに、営業の課題を解決する生成AIユースケースを考えて と依頼してみましょう。
Code Interpreterを駆使して、現在日時を取得しつつアンケート結果を分析してくれるはずです。
3体のエージェントが自律的に動くため、上手くいくときと途中でコケてしまうときがあります。安定するプロンプトを見つけたり、各エージェントの設定を変更してチューニングするのも面白いですね!
協力者エージェントの設定を変更したときは、新しいエイリアスを作成し、監督者エージェントのコラボレーション設定も更新する必要があります。
その際、コラボレーション設定画面で協力者エージェント名を変更しないとエラーになるため、少しだけ名前を変えてみてください。また、最後に監督者エージェントのエイリアスも再発行する必要があるため注意してください。
Pythonコード内の「エイリアスID」の更新も忘れずに!
※なおCloudShellは、20分ほどで自動スリープしてしまいます。再開時にローカルディスクがリフレッシュされてしまうので、止まってしまったら手順5を再実施ください。
もしPythonコードを修正したいときは
CloudShellではファイルの上書きアップロードができないため、新規タブを開いて以下コマンドを実施すれば一度ファイルを削除できます。
rm frontend.py
削除後、作業PCのローカル上でファイルを更新してから、CloudShellにアップロードし直してみましょう。
お片付け
ハンズオンの終了後は、不要なリソースを削除しておきましょう。
サーバーレス構成なので、利用していない間はコストが発生しにくくなっていますが、Auroraクラスターを削除しておくとアイドル中のストレージ料金なども節約できます。
コスト削減に限らず、景観美化のために不要リソースを削除される場合は、以下を確認ください。
- Bedrock(ナレッジベース、エージェント)
- S3(バケット)
- Lambda(関数、レイヤー)
- RDS(Aurora Serverlessクラスター)
- CloudShell(環境を削除)
- IAM(ユーザー、ロール)
また、しばらく触らない場合はAWSアカウントを解約してしまいましょう。
AWSアカウントを解約した場合、同じメールアドレスでAWSアカウントを再作成できなくなってしまうため、事前にメールアドレスを不要なものへ変更しておくことをお勧めします。
※アカウントを継続利用する場合は、ルートユーザーとIAMユーザーにMFAを忘れず設定して、セキュリティ事故を防ぎましょう。
おまけ:なぜマルチエージェントなのか?
察しの良い方なら「今回の構成、別にシングルエージェントでも作れるのでは?」と気づかれたかも知れません。実は正解で、1体のエージェントにナレッジベースとアクショングループを両方設定することもできます。
ただし、エージェントは自律的に動作するため「使ってほしいツールをスキップしてしまう」といった課題がよく発生します。マルチエージェントを採用すると、各エージェントが一つの得意作業に集中できるため、人間が意図したタスクを漏らさず実行してくれる確率が高まるというメリットがあります。
マルチエージェントのデメリットとしては、最終的な結果出力までに時間がかかってしまうため、今回のように画面上に処理状態を都度表示するなどのUX上の工夫がとても重要になります。
次のステップ
ナレッジベースにDBを検索させてみる
ナレッジベースは最近、ベクトルDBだけでなくRedshiftのようなリレーショナルDBを接続し、自然言語をSQLに自動変換してRAGに使えるようになりました。
あなたの社内DBをRedshiftにゼロETL連携して、マルチエージェントから呼び出せればすごく便利な業務アプリが作れるかも?
作ったアプリをコンテナにデプロイしてみる
作ったアプリの監視・評価に挑戦してみる