はじめに
この記事はeeic(東京大学工学部電気電子・電子情報工学科)その2 Advent Calendar 201823日目の記事です。
最近強化学習に興味があるので, 勉強がてら簡単なゲームAIを実装してみました!
といっても, ほとんどネットからとってきたのをちょこっと変えたです。私自身ょゎょゎなので許してほしいです。
強化学習を知らない人には興味を持ってもらい, 知っている人にはアドバイスをもらえると嬉しいです。
コードはGitHubにあげておきました。
強化学習
強化学習は機械学習の一分野で, 与えられた環境の中で「価値が最大になるような行動」を学ぶものです。
AlphaGoという囲碁AIがプロ棋士のイ・セドル九段に勝利したことは記憶に新しいですね。 AlphaGoはアルゴリズムの一部に強化学習を使っています。
強化学習では, エージェントと呼ばれるプレイヤーが環境から受け取った「状態」をもとに「行動」して, それに応じて「報酬」を受け取ります。この報酬の大小によって自らの行動戦略を更新し, 最適解に近づいていきます~~(うまくいけばね)~~。

強化学習の基本についてはこちらに素晴らしい記事がありますのでご覧ください。
3 players四目並べ
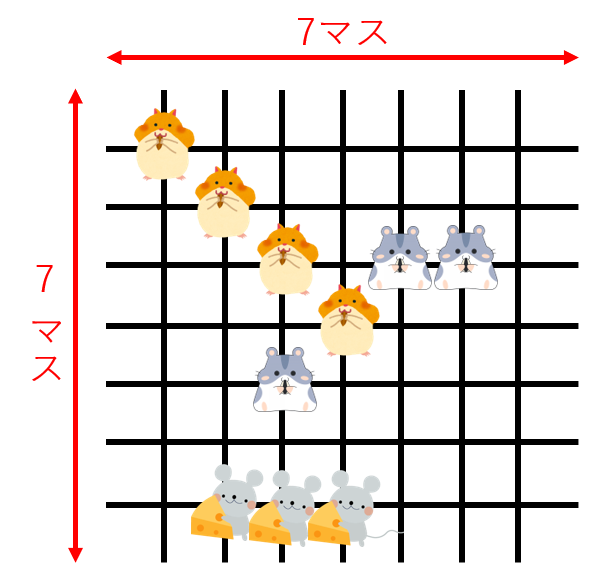
アメリカに住んでいた人は下のConnect Fourのような重力つき四目並べをイメージするかもしれませんが, 今回実装するのは五目並べを四目にしただけの, 平面のものです。
プレイヤーが順番に石(下の画像ではハムスター)を置いていき, 先に縦・横・斜めのいずれかに4つ直線状に並べた方の勝ちです。今回せっかくAIにゲームを学んでもらうので, 人にとってすぐに最適な方策が分からないようにプレイヤーを三人にしてみます。盤面の大きさは7×7です。
どんな戦略を学んでくれるんでしょうか。楽しみです!

実装
ほとんど下の記事に公開されているコードをそのまま使わせて頂きました。
その上で, 盤面を7×7に拡大し, またPlayer1→Player2→Player3とターンが進むよう変更しました。
コードは大まかに次の3つに分かれています。
- 盤面:0-48の配列に, Player1ならX, Player2ならO, Player3ならIを入れます。勝敗条件などゲームのルールは全部ここに入っています。
- ゲーム進行役: ターン進行, 勝敗判定, 盤面表示などを実際に行います。
- プレーヤー:異なる動きをする様々なAIを作ります. 人間の操作部分もここに作ります。
上の変更は一瞬でできたので, 試しにランダムな場所に置くランダム君×2と対戦してみます。
私はPlayer1 (石は"X")になりました!
(中略)
'Turn is Human'
Where would you like to place 1 (1-100)? 19'
' | | | | | O |'
'--------------------------'
| | | O | | O |
--------------------------
| X | X | X | X | |
--------------------------
| I | | | | |
--------------------------
I | I | O | | | I |
--------------------------
| | | | | |
--------------------------
| | | | | |
Winner : Human
Human:1,Random1:0,Random2:0,DRAW:0'
勝ちました。クソ雑魚めちゃめちゃ弱いです。相手はランダムに打つだけなので当然ですね。
3×3のTicTacToe (三目並べ)より盤面が広い分, 自分の打ちたい場所が遮られる確率が低いのでランダムは不利なようでした。
Q学習
それでは, ここからエージェントを作っていきましょう。最初はQ学習です。
ここで, 報酬について, 下の2つの考えが必要になります。
- 長期的な報酬(累積報酬)を最大化する。
- 未来の報酬は割り引いて考える。
明日もらえるお金だけでなく1年後までにもらえるお金の総和で考え、1年後にもらえる1万円より今日もらえる3千円の方が嬉しく感じるということです。
tを時間, $\gamma$を時間割引率とすると、時間割引された報酬の総和$G_t$はこんな感じです。
$$
{G_t:=\sum_{i=0}^{\infty} \gamma^ir_{t+1+i}
}
$$
Qは**「ある状態において、ある行動を取った時の価値」**を表し, 状態行動価値と呼ばれます。
Q学習というのはざっくり言うと, ある状態にいるとき, 報酬の合計が一番多くなるような行動$a$が何かを学習するものです。
これは, 何か1つ行動するたびに, 「ある状態$s$において、ある行動$a$を取った時の価値」$Q(s_t, a_t)$を、行動$a$をとった1ステップ後に見込まれる報酬の総和に近づけて値を更新するというのを繰り返すことで、試行錯誤により学んでいきます。
コードはこちらからお借りしました。
それでは実行してみます。結構時間がかかるので, 寝て待ちました。
目が覚めてパソコンを見てみると...
(中略)
Q1:12456,Q2:12343,Q3:17201,DRAW:17201
Q1:12753,Q2:12645,Q3:17602,DRAW:17602
Q1:13066,Q2:12931,Q3:18003,DRAW:18003
Q1:13364,Q2:13232,Q3:18404,DRAW:18404
Traceback (most recent call last):
File "main.py", line 7, in <module>
File "C:\Users\connect_for\versus.py", line 41, in ql_vs_ql_vs_ql
File "C:\Users\connect_for\game_organizer.py", line 55, in progress
File "C:\Users\connect_for\player_ql.py", line 52, in getGameResult
File "C:\Users\connect_for\player_ql.py", line 70, in learn
File "C:\Users\connect_for\player_ql.py", line 70, in <listcomp>
MemoryError
あれ、メモリエラーになってしまいました。。16GBあるのに。。
どの箇所で容量が増えているか見てみたところ, Q学習に使うテーブル$Q(s,a)$の保持にメモリを大量に使っていました。新しいsとaの組み合わせが来るたびにそれを追加していく形だったのですが, 試行回数を重ねるごとに容量がどんどん膨れていました。
(12/25追記) 後から気付いたんですが, 状態sをリストで保存してたのがメモリエラーの原因だったみたいです。numpyなら多分大丈夫ですね。
ニューラルネットワークを用いたQ学習
小さな迷路のような簡単なタスクでは普通のQ学習でもよく動きますが, もう少し複雑なタスクを学習したい場合にはテーブル形式だと行数が多くなり学習に時間がかかってしまいます。
そこで、 表形式だった行動価値関数$Q(s,a)$をニューラルネットワークを使った近似に変更します。
先ほどのQ学習では価値を示すパラメータはテーブルに保持していましたが、今度はQはニューラルネットワークの出力として表現します。
ニューラルネットワークは、人間のニューロンを模したノードを複数組み合わせることで、入力と出力の間の非線形な関係を表現するもので、各ノードは一定の条件で発火(0.5以上で1, 0.5未満で0を出力するなど)します。ニューロンと同じですね。(←ニューロンのことをよく知らない人)
ネットワークはこちらを参考にして作りました。
こんな感じです。
# Network definition
class MLP(chainer.Chain):
def __init__(self, n_in, n_units, n_out):
super(MLP, self).__init__(
l1=L.Linear(n_in, n_units), # first layer
l2=L.Linear(n_units, n_units), # second layer
l3=L.Linear(n_units, n_units), # Third layer
l4=L.Linear(n_units, n_units), # Fourth layer
l5=L.Linear(n_units, n_out), # output layer
)
def __call__(self, x, t=None, train=False):
x, t = Variable(cuda.to_gpu(x)), Variable(cuda.to_gpu(t))
h = F.leaky_relu(self.l1(x))
h = F.leaky_relu(self.l2(h))
h = F.leaky_relu(self.l3(h))
h = F.leaky_relu(self.l4(h))
h = self.l5(h)
if train:
return F.mean_squared_error(h,t)
else:
return h
def get(self,x):
# input x as float, output float
return self.predict(Variable(xp.array([x]).astype(xp.float32).reshape(1,1))).data[0][0]
それでは, 先ほどと同じランダム君と10万回くらい戦わせて鍛えます。
5層の全結合層からなるニューラルネットワークで、活性化関数はLeaky ReLUを用いました。
DQ1がDQN, あとの2プレイヤーはランダム君です。
C:\Users\\connect_for>python main.py
DQ1:29,Random1:28,Random2:43,DRAW:43
DQ1:68,Random1:50,Random2:82,DRAW:82
DQ1:103,Random1:74,Random2:123,DRAW:123
(中略)
DQ1:41210,Random1:25115,Random2:33475,DRAW:33475
DQ1:41253,Random1:25137,Random2:33510,DRAW:33510
DQ1:41294,Random1:25166,Random2:33540,DRAW:33540
(回数の数え方にミスがあり, Random2のところにDRAWの結果が入ってしまいました。すみません。)
ランダム君に勝ち越してはいるものの(DQ1 > Random1), あんまり強くないですね。
Deep Q Network (DQN)
精度を上げるため, ニューラルネットワークに畳み込み層を使ってみました。
強化学習に, 畳み込みニューラルネットワークを組み合わせた手法はDeep Q Network (DQN)と呼ばれます。
DQNの元論文で提案された手法ではExperience Replayなどいくつかの工夫がされていますが, 今回は簡単のため省略しました。
ネットワークをこんな感じに3層のCNNに変えます。
# Network definition
class MLP(chainer.Chain):
def __init__(self, n_in, n_units, n_out):
initializer = chainer.initializers.HeNormal()
super(MLP, self).__init__(
l1=L.Convolution2D(None, 16, ksize=3, stride=1, pad=0, initialW=initializer), # first layer
l2=L.Convolution2D(None, 32, ksize=2, stride=1, pad=0, initialW=initializer), # second layer
l3=L.Convolution2D(None, 64, ksize=2, stride=1, pad=0, initialW=initializer), # second layer
l4=L.Linear(None, 256), # Third layer
l5=L.Linear(None, n_out,
initialW=np.zeros((n_out, 256),
dtype=np.float32))
)
def __call__(self, x, t=None, train=False):
x, t = Variable(cuda.to_gpu(x)), Variable(cuda.to_gpu(t))
x = x.reshape(1,1,7,7)
h = F.leaky_relu(self.l1(x))
h = F.leaky_relu(self.l2(h))
h = F.leaky_relu(self.l3(h))
h = F.leaky_relu(self.l4(h))
h = self.l5(h)
if train:
return F.mean_squared_error(h,t)
else:
return h
def get(self,x):
# input x as float, output float
return self.predict(Variable(xp.array([x]).astype(xp.float32).reshape(1,1))).data[0][0]
VS ランダム君
先ほどのランダム君2体と10万回戦わせました。DQ1が私たちのDQNです。
C:\Users\connect_for>python main.py
DQ1:24,Random1:27,Random2:38,DRAW:11
DQ1:60,Random1:62,Random2:65,DRAW:13
DQ1:97,Random1:83,Random2:97,DRAW:23
(中略)
DQ1:89643,Random1:4340,Random2:4476,DRAW:1341
DQ1:89740,Random1:4341,Random2:4478,DRAW:1341
DQ1:89832,Random1:4344,Random2:4482,DRAW:1342
おお、DQ1の圧勝ですね!学習がよく進んでいることが分かります。
どれくらい強くなったのか、私が相手になってみます。碁石はXです。
C:\Users\connect_for>python main.py
Turn is DQ1
| | | | | |
--------------------------
| | | | | |
--------------------------
| | | | | |
--------------------------
| | | I | | |
--------------------------
| | | | | |
--------------------------
| | | | | |
--------------------------
| | | | | |
Turn is Human
Where would you like to place 1 (1-7) (1-7)? 3 3
| | | | | |
--------------------------
| | | | | |
--------------------------
| | X | | | |
--------------------------
| | | I | | |
--------------------------
| | | | | |
--------------------------
| | | | | |
--------------------------
| | | | | |
Turn is DQ1
| | | | | |
--------------------------
| | | | | |
--------------------------
| | X | | | |
--------------------------
| | | I | | |
--------------------------
| | | | | |
--------------------------
| | | | | |
--------------------------
| | | | O | |
Turn is DQ1
| | | | | |
--------------------------
| | | | | |
--------------------------
| | X | | | |
--------------------------
| | | I | | |
--------------------------
| | | | I | |
--------------------------
| | | | | |
--------------------------
| | | | O | |
Turn is Human
Where would you like to place 1 (1-7) (1-7)? 4 3
| | | | | |
--------------------------
| | | | | |
--------------------------
| | X | | | |
--------------------------
| | X | I | | |
--------------------------
| | | | I | |
--------------------------
| | | | | |
--------------------------
| | | | O | |
Turn is DQ1
| | | | | |
--------------------------
| | | | | |
--------------------------
| | X | | | O |
--------------------------
| | X | I | | |
--------------------------
| | | | I | |
--------------------------
| | | | | |
--------------------------
| | | | O | |
Turn is DQ1
| | | | | |
--------------------------
| | | | | |
--------------------------
| | X | | | O | I
--------------------------
| | X | I | | |
--------------------------
| | | | I | |
--------------------------
| | | | | |
--------------------------
| | | | O | |
Turn is Human
Where would you like to place 1 (1-7) (1-7)? 5 3
| | | | | |
--------------------------
| | | | | |
--------------------------
| | X | | | O | I
--------------------------
| | X | I | | |
--------------------------
| | X | | I | |
--------------------------
| | | | | |
--------------------------
| | | | O | |
Turn is DQ1
| | | | | |
--------------------------
| | | | | |
--------------------------
| | X | | | O | I
--------------------------
| | X | I | | |
--------------------------
| | X | | I | |
--------------------------
| | | | O | |
--------------------------
| | | | O | |
Turn is DQ1
| | | | | |
--------------------------
| | I | | | |
--------------------------
| | X | | | O | I
--------------------------
| | X | I | | |
--------------------------
| | X | | I | |
--------------------------
| | | | O | |
--------------------------
| | | | O | |
Turn is Human
Where would you like to place 1 (1-7) (1-7)? 6 3
| | | | | |
--------------------------
| | I | | | |
--------------------------
| | X | | | O | I
--------------------------
| | X | I | | |
--------------------------
| | X | | I | |
--------------------------
| | X | | O | |
--------------------------
| | | | O | |
Winner : Human
Human:1,DQ1:0,DQ1:0,DRAW:0
相変わらず弱いですが, 並べて石を置いたり, 私がリーチになると上から押さえつけてくる(左上のI)など, それらしい動きも出てきました。
VS アルファランダム君
さらに鍛えるため, ランダム君と10万回対戦したエージェントをこちらのアルファランダム君と2000回戦わせます。
アルファランダム君は基本ランダムですが, 次に勝てる手があるときだけしっかり指します。
C:\Users\connect_for>python main.py
AlphaRandom:55,DQ1:27,DQ1:16,DRAW:2
AlphaRandom:109,DQ1:64,DQ1:25,DRAW:2
AlphaRandom:124,DQ1:145,DQ1:29,DRAW:2
(中略)
AlphaRandom:162,DQ1:2559,DQ1:74,DRAW:5
AlphaRandom:162,DQ1:2657,DQ1:76,DRAW:5
AlphaRandom:162,DQ1:2752,DQ1:81,DRAW:5
DQ1が二人いますが, ネットワークの値は共有ではなく, 別のオブジェクトです。
なぜか二人目のDQNがボコボコにされてますが, DQNの圧勝ですね。600回目以降くらいはアルファランダム君は全く勝てなくなっていました。
DQN VS DQN VS DQN
それでは全員DQNにしてさらに戦わせます。12万回戦わせました。
相手になってみます。私の碁石は相変わらずXです。
C:\Users\minori\Desktop\connect_for>python main.py
Turn: 1
Turn is DQ2
| | | | | |
--------------------------
| | | I | | |
--------------------------
| | | | | |
--------------------------
| | | | | |
--------------------------
| | | | | |
--------------------------
| | | | | |
--------------------------
| | | | | |
Turn: 2
Turn is Human
Where would you like to place 1 (1-7) (1-7)? 4 3
| | | | | |
--------------------------
| | | I | | |
--------------------------
| | | | | |
--------------------------
| | X | | | |
--------------------------
| | | | | |
--------------------------
| | | | | |
--------------------------
| | | | | |
Turn: 3
Turn is DQ1
| | | | | |
--------------------------
| | | I | | |
--------------------------
| | | | | |
--------------------------
| | X | | O | |
--------------------------
| | | | | |
--------------------------
| | | | | |
--------------------------
| | | | | |
Turn: 4
Turn is DQ2
| | | | | |
--------------------------
| | | I | | |
--------------------------
| | | I | | |
--------------------------
| | X | | O | |
--------------------------
| | | | | |
--------------------------
| | | | | |
--------------------------
| | | | | |
Turn: 5
Turn is Human
Where would you like to place 1 (1-7) (1-7)? 5 4
| | | | | |
--------------------------
| | | I | | |
--------------------------
| | | I | | |
--------------------------
| | X | | O | |
--------------------------
| | | X | | |
--------------------------
| | | | | |
--------------------------
| | | | | |
Turn: 6
Turn is DQ1
| | | | | |
--------------------------
| | | I | | |
--------------------------
| | | I | | |
--------------------------
| | X | | O | |
--------------------------
| | | X | O | |
--------------------------
| | | | | |
--------------------------
| | | | | |
Turn: 7
Turn is DQ2
| | | | | |
--------------------------
| | | I | | |
--------------------------
| | | I | | |
--------------------------
| | X | I | O | |
--------------------------
| | | X | O | |
--------------------------
| | | | | |
--------------------------
| | | | | |
Turn: 8
Turn is Human
Where would you like to place 1 (1-7) (1-7)? 1 4
| | | X | | |
--------------------------
| | | I | | |
--------------------------
| | | I | | |
--------------------------
| | X | I | O | |
--------------------------
| | | X | O | |
--------------------------
| | | | | |
--------------------------
| | | | | |
Turn: 9
Turn is DQ1
| | | X | | |
--------------------------
| | | I | | |
--------------------------
| | | I | O | |
--------------------------
| | X | I | O | |
--------------------------
| | | X | O | |
--------------------------
| | | | | |
--------------------------
| | | | | |
Turn: 10
Turn is DQ2
| | | X | | |
--------------------------
| | | I | | |
--------------------------
| | I | I | O | |
--------------------------
| | X | I | O | |
--------------------------
| | | X | O | |
--------------------------
| | | | | |
--------------------------
| | | | | |
Turn: 11
Turn is Human
Where would you like to place 1 (1-7) (1-7)? 6 5
| | | X | | |
--------------------------
| | | I | | |
--------------------------
| | I | I | O | |
--------------------------
| | X | I | O | |
--------------------------
| | | X | O | |
--------------------------
| | | | X | |
--------------------------
| | | | | |
Turn: 12
Turn is DQ1
| | | X | | |
--------------------------
| | | I | O | |
--------------------------
| | I | I | O | |
--------------------------
| | X | I | O | |
--------------------------
| | | X | O | |
--------------------------
| | | | X | |
--------------------------
| | | | | |
I lost...
Winner : DQ1
Human:0,DQ1:1,DQ2:0,DRAW:0
普通に負けました。
DQNがそれぞれ, 最初に相手の石と距離を取って置いてからそれに繋げるように石を置いていくという定石を身につけていることがわかります!
ただターン10でIの番の時, IがOのリーチを止める場所に打ってくれればOの勝利を止められたのですが, Iは自分が繋げやすい位置に打ってしまい, Xだけでは止めきれず負けてしまいました。
3 playersだと必要になるような、協力プレイは身についていないようです。
まとめ
強化学習を使って, 3 playersの四目並べAIを作ってみました。
テーブル形式のQ学習, ニューラルネットワークを使ったQ学習, 簡易版DQNの3つで試しました。
畳み込み層にしないと学習がほぼ進まなかったり, 学習に時間がかかったり, 実際に作ってみて分かった発見が多くて面白かったです。
次は3playersのオセロや囲碁を実装してみたいです。