この記事について
UNIX系のパソコンについて基本的なことをまとめています。2003年という少し前の本になりますが、山口先生、古瀬先生らのUNIX Super Textという素晴らしい本があったので、これを参考にしています。この本の内容は、古い記述もたくさんあります(記憶装置として磁気テープとかが紹介されてます)が、そういう点は飛ばして、今も変わらないところを中心に解説します。
-
cdとかlsとか基本的なUNIX系コマンドは使えるけどbashとかUNIXとかよくわからない - Linux系ってどうやって動いているの?
- 環境変数ってなに?
という人向けの記事になると思います。かなり文量が多いので、前後編に分けました。後編は以下のリンクをどうぞ。
UNIXの基礎(後編)
https://qiita.com/minnsou/items/2f8173b08c0a3d5cfc48
書式
・[ ]は省略可能
・|はそのいずれかならOK(例えば[a|b|c]ならaかbかcか)
・filename...のように...がある時はfilenameを空白で区切っていくつも入力可能
これはmanコマンドなどでマニュアルを見る時にも共通の書き方である。
歴史
UNIXはAT&T(The American Telephone & Telegraph company)のBell研究所で1969年に動き出した。UNIXには大きく分けてBSD系とSystem V系の2種類がある。
・BSDはBerkeley Software Distributionの略で、カリフォルニア大学バークレー校を中心として機能拡張されたUNIX。例えばMacOSはBSD系に属する。
・System V系はAT&T社に由来するUNIXで「システムファイブ」と読む。Sun Microsystems(現oracle)が作ったSolarisとかはSystem V系に属する。
また、GNUプロジェクトによりUNIXを真似したLinuxが作られる。LinuxはBSD系とSystem V系の両方の特徴が混じっているが、正式なUNIXではない。
要はMacOSもSolarisもLinuxのUbuntuとかも全部UNIX(正確にはUNIX系)なので、この記事の話はほぼ適用できる。
UNIXの基本
キーボードの見方
キーの表面には文字が書かれており、このキーの表面をキートップという。shiftキーを押すと上部、かなキーを押すと右半分、何も押さないと左下の文字になる。Caps Lockはshiftキーを押している状態になる。

パスワードの変更
passwdコマンドを使う。
プロンプト
プロンプトはターミナルを開くと出てくる記号のこと。
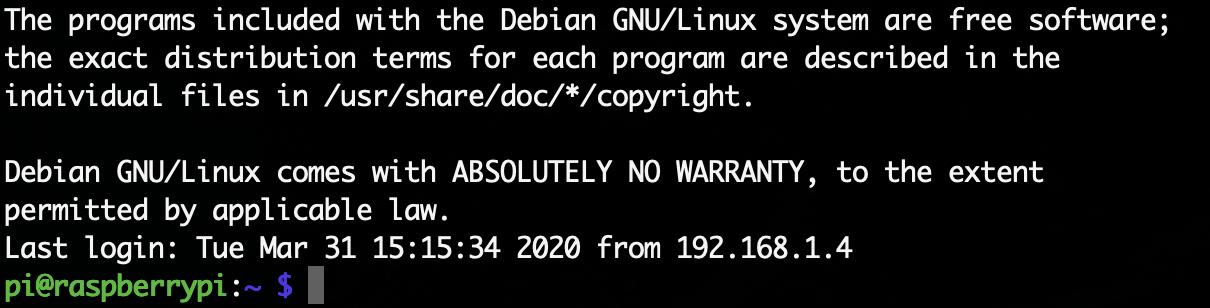
上の例はラズパイにログインした時の表示であるが、最終行のpi@raspberry:~ $の部分をプロンプトという。csh系(cshとかtcshとか)のプロンプトは%、sh系(shとかbashとかzshとか)のプロンプトは$、スーパーユーザのプロンプトは#が一般的。
I/Oリダイレクションと標準入出力
UNIXにはコマンドへの入力やコマンドからの出力を簡単に切り替える機能が用意されている。これをI/Oリダイレクションという。echo 1 + 2 > aa.outとかの>によって出力を切り替えている。なお、>はそのファイルに上書きするもので、末尾に追加したい時は>>を使う。
例えばbc < aa.out > answerとすればanswerには3が入る。なおbcコマンドは計算をしてくれるコマンド。
詳細は後半の「bashプログラミング」の章で解説する。
manについて
UNIXのオンラインマニュアルを参照するにはmanコマンドを使う。章を指定するときにはman section titleという書き方をする。sectionが指定されない時は、最初に見つかった章のマニュアルが表示される。
- ユーザーコマンド
- システムコール
- ライブラリ関数
- デバイスとネットワークインターフェース
- ファイルフォーマット
- ゲームとデモ
- 公共ファイル、テーブル、TROFFマクロ
- メンテナンスコマンド
以上は標準的な章構成で、実際にはこれ以外の章があったりする。
キーワードで検索したいときには
man -k keywordとする。
これらのマニュアルは、/usr/share/manや/usr/manに存在するが、そのマニュアルはroffというデータ形式で記述されている。これらのマニュアルを直接見たいときにはnroff -man filenameのようにnroffコマンドを使う。
ディレクトリ
.は自分自身のディレクトリ、..は親のディレクトリの名前を指す。rmdirコマンドは空のディレクトリを消すコマンドだけど、この二つは入っていてもOK(以下の例のように、空のディレクトリでもls -aすると必ず.と..が入っているのが確認できる)。
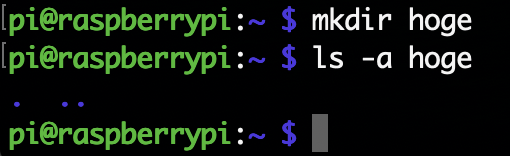
ホームディレクトリは~で指定する。また~nameとユーザー名を書いた時はユーザー名がnameの人のホームディレクトリを表す。
ファイルの属性
UNIXのファイルとディレクトリは、所有者、更新された日付などの属性を持っている。ls -lコマンドでファイルの属性が表示される。
属性の1つにモードがある。これはファイルの型とファイルへのアクセスを決めるためのもの。
モードの一番最初の文字はファイルの型を表し、-ならファイルで、dならディレクトリとなっている。
続く9つの文字はアクセスの可否を表す。rは読み出し可、wは書き出し可、xは実行可(ディレクトリの時は検索可)。最初の3文字がファイルの所有者、次の3文字がファイルが属しているグループのメンバ、最後の3文字がそれ以外の人を表す。
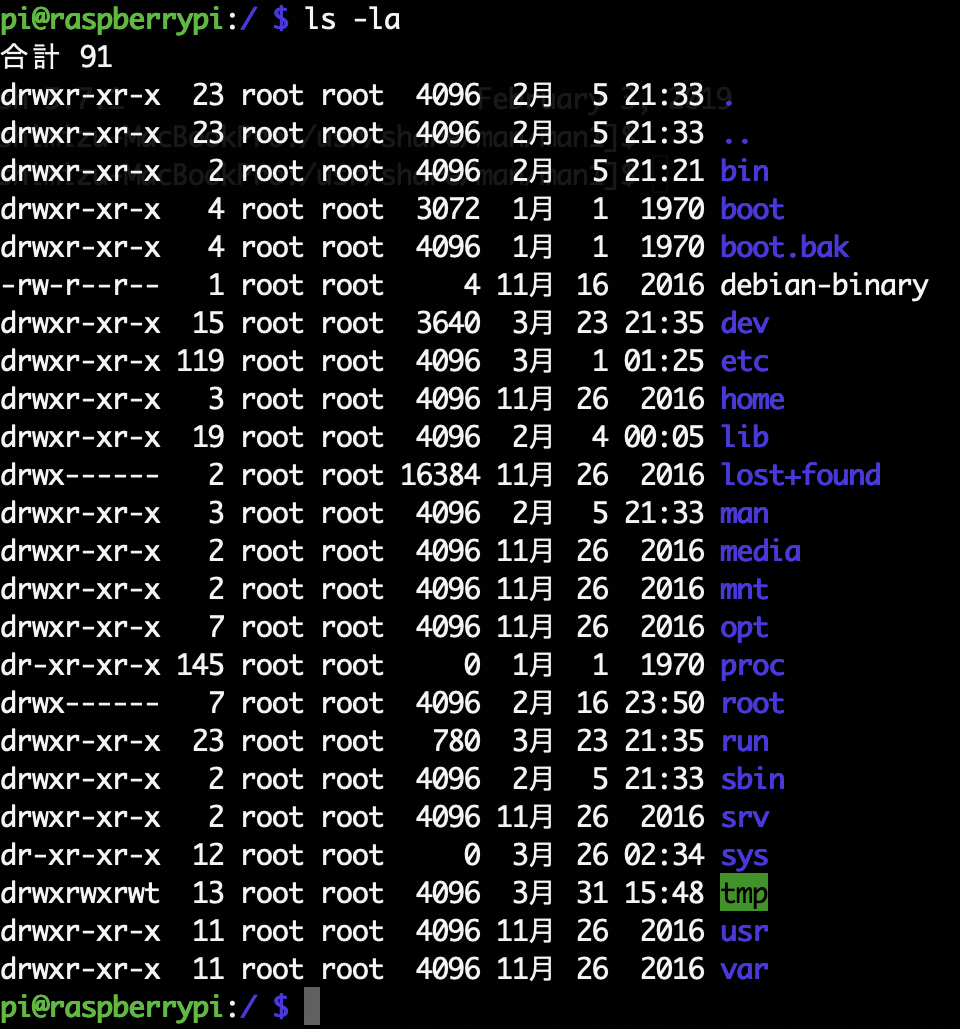
モードを変更するにはchmodコマンドを使う。
chmod set file1 file2 ...という書式
setは[ugoa][=+-][rwx]で指定する。アルファベットはそれぞれuser, group, others, allの意味。
例えばchmod go+r fileならグループとそれ以外の人に対するfileの読み出し可能の許可を与えるということ。
ここも「ファイルとディレクトリについて」の章で詳しく扱う。
プロセス
ネットワークからの要求に対してサービスを提供するプロセスや、プリンタの制御をするプロセスは特定の端末と結び付けられていない。このように端末と結び付けられていないプロセスのことをデーモンプロセスという。psコマンドの端末表示名(TTとかTTYで表示される行)が?になっているものはデーモンプロセス。
キーによるプロセスの強制終了について、Ctrl-Cが有名でみんな使うけど、Ctrl-\もできる。Ctrl-\ではデバッグ用にcoreという名前のファイルができる。
ここも「プロセスについて」の章で詳しく解説する。
bash入門
シェルとは
コマンドを実行するために使われているシェルについて、ちゃんと解説していく。まずは、シェルが何をするものなのかを理解するために、「コマンドを実行する」までにどのような処理がなされるかをざっと眺める。次の1から6までの処理が行われている。
- プロンプト(
$とか%とか)を出力してコマンドの入力を促す - キーボードから入力された文字をEnterが押されるまでためておく
- Enterが押されたら、その文字列を空白などで区切ってコマンドの文字列と引数の文字列に分ける
- コマンドの名前からその名前のプログラムを見つけ出す
- 見つけたプログラムを起動して、引数の文字列を渡す
- 特に指定しなければ、シェルは起動したプログラムが終了するまで待つ
文字列として与えられるコマンドを解釈、実行するものを一般にコマンドインタプリタと言う。UNIXのではOSの中心にカーネルという核があるが、コマンドインタプリタはカーネルの機能を使ってキーボードから文字を受け取ったりプログラムを起動したりする「殻」の部分に位置する。なのでUNIXのコマンドインタプリタはシェルと呼ばれている。
シェルにはshやcsh、bash、fish、zshなどたくさんあるが、今回はbashに話を絞る。Linuxの標準のシェルはbashだし、Macも前までbashだったから(macOS Catalinaからzshになった)。この章で出てくる大半の話はどのシェルでも同じように動作する。
ログインシェル
ログインに成功すると、シェルが起動されてキーボードからコマンドを受け付けるようになる。このシェルをログインシェルという。
ログインシェルには
- ログイン直後に起動されるシェルの種類
- ログイン直後に起動されるシェルのプロセス
の2つの意味がある。どちらの意味で使っているかは文脈で判断すべし。UbuntuやMacとかのデフォルトのログインシェルはbash(MacはMacOS Catalinaからzsh)である。
シェルは基本的にexitコマンドでもlogoutコマンドでも終了できる。ただしログインシェルじゃない時にlogoutしてもそのシェルを終わらせることはできないので注意。
キーバインド
コマンドライン編集にはEmacsのキーバインドが使える。だからCtrl-Pで一つ前のコマンド履歴が遡れるし、Ctrl-Aで行頭に移動できる。もしviっぽく使いたければset -o viと打てば良い。
よく使うEmacs風のキーバインドは以下
-
Ctrl-Pコマンド履歴を戻る(↑と同じ、previous line) -
Ctrl-Nコマンド履歴を進む(↓と同じ、next line) -
Ctrl-Fカーソルを右へ1文字進める(forward char) -
Ctrl-Bカーソルを左へ1文字進める(bach char) -
Ctrl-Aカーソルを行頭に移動(beginning of line) -
Ctrl-Eカーソルを行末に移動(end of line) -
Ctrl-Dカーソルの位置の文字を削除(delete) -
Ctrl-Kカーソルより右を全て削除(kill line)
リダイレクション
コマンドの実行結果は基本的に画面に表示されるが、表示された結果を使って次の処理をしたい時がある。シェルにはコマンドの入力や出力を切り替える機能を持っている。切り替えの対象となる入出力として、
- 標準入力(普通はキーボード)
- 標準出力(普通は画面)
- 標準エラー出力(普通は画面)
の三つは切り替えがある。>を使って標準出力先などを変更することをリダイレクション、リダイレクトと呼ぶ。
ここの詳細も後半の「bashプログラミング」の章で述べる。
パイプ
標準出力と標準入力を繋ぎたい2つのコマンドを|で並べること。これによりファイルに中間結果を出力する必要がなくなる。
例 ps ux | grep user名 | sort -r
これによりpsコマンドでuser名が含まれているものをソートして表示される。ps uxの出力をgrep user名に渡し、その出力をsortに渡すという感じ。user名を自分のものに変えて実行してみよう。
>と似てるけど、>> は標準出力の出力をファイルの末尾に追加する。>&だと標準出力だけでなく標準エラー出力もリダイレクションされる。なお、cshのパイプには|&という標準出力と標準エラー出力を同時に送るコマンドがあるが、bashでは使えない。bashは|だけで標準出力も標準エラー出力も送る。
変数
シェルでは普通のプログラミング言語と同じように、変数が使える。echo $xというコマンドで変数xの中身を確認できる。bashでは、変数の代入はx=12のように行う。=の両端にスペースは入れない。変数にはシェル変数と環境変数の2種類がある。
環境変数は、全てのサブプロセスが知ることのできる変数である。export variableで変数variableを環境変数に設定できる。環境変数は起動されたコマンドから参照できるが、シェル変数は参照できない。以下の例を考える。
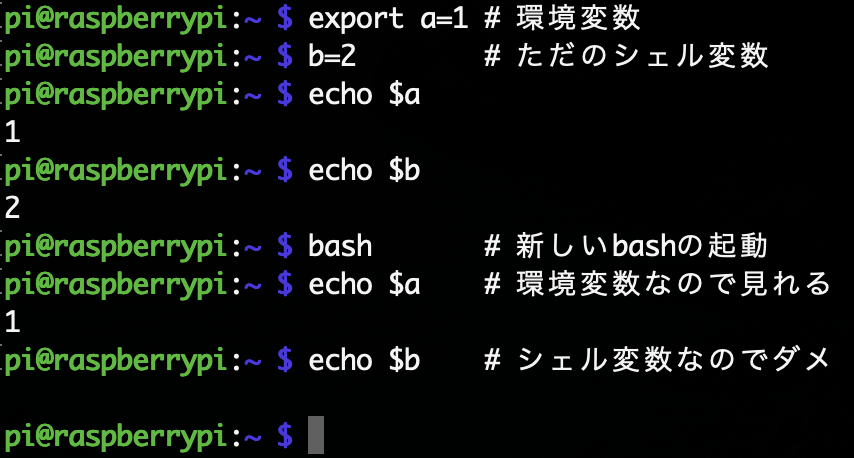
環境変数には、コマンド検索に使われるPATHやホームディレクトリを指定するHOMEなどがある。また全ての環境変数はprintenvコマンドやexportコマンドで見ることができる。
シェル変数は、シェルで使われる全ての変数を指す。bashを起動した時点で勝手に設定される組み込み変数(例えば端末の表示列数を表すCOLUMNSとか)もシェル変数であるし、環境変数もシェル変数である。全てのシェル変数を見たい時はdeclareコマンドで見れる。
メタキャラクタとエスケープ
コマンドラインの文字には「シェルが解釈する文字」(>とか|とか)と「コマンドに渡される文字」(コマンド名や引数など)がある。「シェルが解釈する文字」をメタキャラクタという。メタキャラクタとして解釈しないで単なる文字として扱うことをエスケープするという。
\を使えば全てのメタキャラクタをエスケープできる。でも複数ある時はそれぞれに\をつけるのは面倒なので、''で囲むという方法もある。ただしこれでも!はエスケープされない。また""で囲むという方法もあるけど、これも!や$はエスケープされない。
例えばa$1という名前のディレクトリが直下にあったとして、cd 'a$1'で移動ができるが、cd "a$1"では移動できない。これは$1が変数だと解釈され、空文字列に変更される(もし変数に値が入っていたらその値に変更される)からである。
ファイル名置換
*は任意の文字列、?は任意の1文字、[str]はstrの中の1文字、{str1,str2,...}はそれぞれをファイル名置換したもの(つまりstr1とかの中に?とかが入っていないといけない)を示す。
また、例えば[aA]ならaかAを表す、[0-9]なら数字を表す。

これらは、ファイルの名前にシェルが変換する機能なので、それにマッチするファイルが存在しない場合はそのままの文字列が表示される。

ジョブ
UNIXでは一連の仕事しているプロセスの集合をジョブという。
フォアグラウンドジョブ:シェルがそのコマンドの終了までプロンプトを出さずに待っているジョブ。
バックグラウンドジョブ:シェルがコマンドの終了をまたずに、キーボードから切り離された状態で実行されるジョブ。バックグラウンドジョブにするためには末尾に&をつける。
順次実行の記号は;
例えばcd /tmp ; du -aとすればcd ..コマンドの後にdu -aコマンドが実行される。ちなみにduコマンドはDisc Usageの意味でファイルの容量を確認できる。
グループ化の記号は()
例えば(cd /tmp ; du -a) > tempとしたとき、tempファイルはカレントワーキングディレクトリに作られる。()で囲むことによって、それが一つのコマンドとなるようにサブシェルで実行される。bashでは{}も使えて{ cd /tmp ; pwd ; }とすればサブシェルではなくそのシェルで実行される。{}の前後にはスペースがいることに注意。
とりあえず( cd /tmp ; pwd ; )と{ cd /tmp ; pwd ; }をそれぞれ実行してみれば、実行後のディレクトリが違うことがわかるはず。前者を実行してもディレクトリは移動しないが、後者ではカレントワーキングディクレクトリが/tmpになっている。
終了ステータス
コマンドの成功・失敗を簡単な整数値で表したもの。正常に終了すれば0、異常終了したらそれ以外の値をとるのが基本。echo $?とすると一つ前のコマンドの終了ステータスが見れる(bashでは$?に終了ステータスが入っているので、echo $?で見れる)。例えばcan't open fileなら2、command not foundなら127が$?に入る。
コマンドの終了ステータスを利用して、実行を制御する簡単な方法は以下になる。より複雑な制御については、後半の「bashシェルプログラミング」に記述した。
・&&は前のコマンドが正常終了したら、そのあとのコマンドを実行する
・||は前のコマンドが異常終了したら、そのあとのコマンドを実行する
例えばcd /aaa && lsというコマンドなら/aaaは(たぶん)存在しないのでlsが実行されないけど、cd /aaa || lsならlsは実行される。
ヒストリー機能
以前に入力したコマンドを簡単に参照できる機能をシェルは備えている。
historyコマンドで今まで打ったコマンドの一覧を見ることができる。!!とすると直前のコマンドを実行。!strとすると先頭の文字列がstrであるもっとも近いコマンドを実行する。bashは↑を押せば以前のコマンド履歴を遡れるが、何回も↑を押すのが面倒な時には!strは便利である。例えば、pythonでプログラムを何回も実行させる時にpython foo.pyとかを繰り返し実行する時は、!pと押すだけで良い。
ヒストリーで記憶しているのはコマンドライン全体だが、その一部だけを使いたい時がある。コマンドラインを空白でワードに区切り、その中から必要なワードだけを指定できるものとしてワード指定子が存在する。:numならnum番目のワード(つまり0ならコマンド名となる)。:*ならコマンド名を除く全てのワードのように指定する。
例えばヒストリーに554 cd ~/Desktopがあったとき(554番目にcd ~/Desktopというコマンドを打っていた時の話、この順番はhistoryコマンドで見れる)、echo !554:1とするとecho ~/Desktopが実行される。
コマンドサーチパス
- commandが
/を含めば、パス名を指定したものとしてそのプログラムを実行 - commandが組み込みコマンドなら、その組み込みコマンドを実行
- シェル変数
PATHを使って、実行可能なファイルを探し、最初に見つけたものを実行 - Command not foundを出す
コマンド名に対してどのファイルが実行されるかを知るにはwhichコマンドを使う。
こんな時どうする
キー入力がおかしい時は、まずはCaps Lockやかなキーが押されていないかを確認する。キーボードや本体の状態に問題がない時は、端末回線設定をリセットする。例えばBSD系ならresetコマンド、System V系ならstty saneコマンドをいれる。またBackSpaceキーで文字が消せずに^Hが表示される時は、stty erase ^Hと設定し直すのも良い。
異常な名前のファイルができたとき、rm -i *コマンドを使うのが良い。-iオプションは消す時に一つ一つ確認してくれるもので、シェルのメタキャラクタを含んだファイル名とか大丈夫である。でも/を含んだファイル名はこれでも消せない。
キー入力がおかしくて、ログアウトすらできない時は、外部からログインシェルを終了させる。psコマンドからプロセスIDを見つけて、killコマンドを使う。ただしシェルは通常のkillコマンドでは殺すことができず、kill -HUP 10089のようにハングアップシグナル(もしくはキルシグナル)を使う必要がある。
知っていると便利なコマンド集
・whereisコマンドでも、指定したコマンドのパス名を表示できる。ただし、これはコマンドサーチパスを探すのではなく、あらかじめ決められたディレクトリを全て探す。
・fileコマンドは引数で指定したファイルのタイプを推定する。
・diffコマンドは行単位で2つのファイルの比較をする。
例えばtest1ファイルが
test,
for test,
This is a test.
という中身で、test2ファイルが
test,
For test,
This is a text.
という中身の時にdiff test1 test2とすると
2,3c2,3
< for test,
< This is a test.
\ No newline at end of file
---
> For test,
> This is a text.
\ No newline at end of file
と出力される。最初の行の2,3c2,3は第一引数のtest1の2行目と3行目が変更された(c:change)ことを示している。diffコマンドは第一引数のファイルから第二引数のファイルを作るための操作で表現される。
・ファイルの行数を知りたい時はwcコマンド(word count)を使う。表示されるのは、「ファイルの行数」「単語数」「文字数」である。
・画面出力の保存としてscriptコマンドがある。これを実行するとbashが新たに起動されて、exitする(もしくはCtrl-Dを押す)までの画面の出力(制御記号付き)をtypescriptというファイルに書き込む。最初からファイル名を指定してscript filenameというコマンドでも良い。
ファイルとディレクトリについて
ファイルの名前とファイルの内容を入れる入れ物は別である。後者をファイルの実体という。ファイルの実体にはi-ノード番号という識別番号がついている。これはls -iで見ることができる。コマンドは基本的に「ファイル名」⇨「ファイルの実体(i-ノード番号)」⇨「ファイルの内容」という順番に辿られる。
ハードリンクとシンボリックリンク
ファイル名には二つある。
- ハードリンク
- シンボリックリンク
である。ハードリンクはファイルの本名で、どんなファイルも必ず1つは持っており、全てのハードリンクがなくなるとファイルの実体が消される。ハードリンクの数はls -lで確認できる(モードの次の数字がハードリンクの数を表す)。ln oldname newnameのようにlnコマンドでハードリンクを増やすことができる。これで片方のファイルを変更すると、もう片方のファイルも書き変わることになる。また、新たに追加したハードリンクを以前からあったファイル名(ハードリンク)と区別することはできない。
シンボリックリンクはただのファイルの別名である。シンボリックリンクを増やすには、ln -s oldname newnameというコマンドを使う。
これらの違いはrmコマンドを使ったときに現れる。file1にハードリンクを新しく貼ってfile2を作ったとき、rm file1してもファイルの実態はfile2として残っている。しかし、file1にシンボリックリンクを貼ってfile3を作ったとき、rm file1とするとfile3という名前ではそのファイルにアクセスできない。シンボリックリンクにはリンク先のパス名が記録されているだけなので、リンク先が消えたらアクセスはできなくなる。
ディレクトリは、そのディレクトリの中にあるファイルとディレクトリの内容の名前の一覧を情報として持つファイルとみることができる。この見方のディレクトリをディレクトリファイルという。ファイルの場合、ハードリンクの数は最初は1であるが、ディレクトリの場合は2である。なぜなら、そのディレクトリの中にそのディレクトリを表す.があるため。ディレクトリの木構造が崩れるようなループが生じてしまうと、カーネルの中でディレクトリの探索が無限ループとなり、システムが落ちてしまうことを防ぐため、ディレクトリにはハードリンクが貼れないようになっている。ただしシンボリックリンクはディレクトリにも貼ることができる。
ディレクトリに関する小技
・ファイルを削除禁止する方法
直接削除禁止にはできないが、そのファイルが格納されているディレクトリを書き込み禁止にすることで、そのファイル名を削除した結果をディレクトリファイルに書き込めないから削除できないという方法がある。例えばdir1に入っているfile1について、chmod a-w dir1とすることで、rm dir1/file1ができなくなる。そのディレクトリ内でファイルの作成もできなくなるが、file1の変更はできる。
・ファイル名で記号を使う
-から始まるファイル名について、これはファイル名やディレクトリ名に使っても良い記号だが、UNIXの多くのコマンドラインで-をコマンドのオプションの指定と解釈するために、これをファイル名に下手に使うと問題が生じやすい。先頭が-じゃなければ良いので、絶対パスにするとか、.から始まる相対ファイル名にするなどで解決可能。(''で括るではだめ)
マスクとモード
ファイルを新たにつくった時に作成されたファイルのモードは
- ファイルを作るプログラムの中で指定したモード
- マスク
の二つから決まる。具体的には1から2を落とす(「落とす」とは、1になっているビットを0にすること)。
モードとはファイルの型と許可されたアクセス方法を制御するビット列(16ビット)のこと。
モードの上位4ビットはファイルの型を表す。ls -lで左端の1文字。-なら普通のファイル、dならディレクトリなど。
第11ビットはset-uidビット(User-IDビット)といい、このファイルの所有者のユーザIDが実行プロセスの実行ユーザIDにセットされる(つまりコマンドを実行したユーザの権限ではなく、ファイルの所有者の権限で実行される)。
第10ビットはset-gidビット(Group-IDビット)であり、set-uidビットのグループ版。つまりこのプログラムを実行する時に、このファイルのグループIDがプロセスの実行グループにセットされる。
第9ビットはstickyビットで、このビットが立っているファイルはls -lで右端にtと表示される。ディレクトリにこのビットが立っている時は、ファイルの消去や名前変更を許されるのがその所有者だけに限定される。実行可能ファイルに立っている時はプロセスが終了した時にテキストのスワップイメージを保存して次に同じコマンドが実行される時の速度が速くなるが、仮想記憶が導入されてからはこの機能の効果は薄れて、この機能が無効になっているUNIXもある。
モードの下位9ビットは許可されたアクセス方法(パーミッション)を表す。(例えばrw-r--r--とか)
ファイルのモードを変えるのに記号を使った例を先に紹介した(chmod a+x file1など)が、chmod 644 file1のように数字で変えるという方法もある。
マスクを設定するにはumaskコマンドを使う。
umask 0を実行して、マスクを0にした時にfileを作成するとモードはrw-rw-rw-であるが、マスクを022にしてfileを作成するとrw-r--r--となる(下二つのwを落とす)。これは設定ファイル(.bash_profileとか)に書いておくこともある。
ファイル属性の変更
・所有者属性の変更
chown owner file1 file2 ... filen
file1からfilenまでownerの所有となる。基本的にはスーパーユーザが使える。
・グループ属性の変更
chgrp group file1 file2 ... filen
file1からfilenまでgroupの所有となる。
・ファイルの時刻属性の変更
ファイルには三つの時刻属性がある。
- 最終アクセス時刻
- 最終更新時刻
- 最終変更時刻
である。2の最終更新時刻はファイルの内容の変更時刻で、3の最終変更時刻は属性の変更時刻を指す。
touchコマンドでは最終アクセス時刻や最終更新時刻を好きな時間に変更できるが、3は現在の時刻に変わる。例えば
touch -t 201909080706 file
ならfileの最終更新時刻は2019年9月8日7時6分となる。
デバイスファイル
ハードウェアのデバイスを表すファイルをデバイスファイルという。通常/devの下にある。デバイスファイルにはブロック型と文字型の2種類がある。前者はディスク装置を操作するためのデバイスファイルで、後者はそれ以外を扱うためのファイルである。
デバイスファイルは、そのファイル名を使って操作するデバイスと、メジャー番号とマイナー番号で関連づけられている。メジャー番号は、RAMディスクなら1番のように、デバイスの種類ごとに決められている。マイナー番号は、同じディスクのパーティションを区別したりするのに使う。
ソケット
ソケットはプロセス間通信の終端点である。プロセス間通信にはパイプやTCP/IPなど色々な方法があるが、その中に数えられるUNIXドメインのソケット(同一コンピュータの内容で閉じたプロセス間通信で使うソケット)はファイルとして見ることができる。
プロセスファイル
/procというディレクトリの下にプロセスの状態がファイルとして見れるようになっているシステムが存在する(MacOSは違うけど)。例えばLinux全般や、FreeBSDなど。このファイルを読むことで、プロセスのメモリの状態が得られるようになっている。
マウントとアンマウント
ディスク上に作られたファイルシステムは、最初は単に一続きの大きなデータとしてしか扱われない。この状態からUNIXのカーネルにファイルシステムの木があることを認識させることをマウントするという。例えばmountコマンドを使ってmount /dev/sd0g /usrとすると、/dev/sd0gで示されたディスクパーティションにあるファイルシステムがUNIXに認識される。これ以降に/usrにアクセスすると、/dev/sd0gにあるファイルシステムのルートにアクセスできる。この場合/usrを/dev/sd0gのマウントポイントという。
NFSマウント
NFS(Network File System)とは、Sunが開発したネットワークファイルシステムである。ネットワークファイルシステムとは、ネットワークで繋がった別のコンピュータにあるファイルをあたかも自分自身が持っているディスクにあるファイルのように扱うことができる仕掛けのこと。
どんなファイルシステムがマウントされているかは、一般ユーザでも見ることができる。mountと入力すればよい。
ディスクの残り容量
ファイルシステムのディスクの容量を調べるにはdfコマンド(disk free space)を使う。
macOSでdfコマンドを打つと、Filesystemにはディスクパーティションに対応したデバイスファイルの名前、Mounted onにはどこにマウントされているかを示すマウントポイントなどが表示される。
ファイルシステムという木全体のディスク容量ではなく、あるディレクトリ以下という部分木のディスク容量を調べるにはduコマンド(disk usage)を使う。/でduコマンドを使うと、全てのファイルのサイズを表示しようとするので時間がかかる。
ファイルシステムのiノード番号
先ほど紹介したiノード番号は、ファイルシステムごとに割り振られる。そのため、ファイルシステムが違えば同じiノード番号が存在することになる。

例えばラズパイでは/bootと/procと/sysは同じiノード番号として1が割り振られている。UNIXでは名前が違っていても、同じファイルの実体を示していることがある。正確にファイルが同じかどうかを調べるにはiノード番号だけでなく、ファイルシステムまで合わせて比較する必要がある。
ルートファイルシステム
/によくあるディレクトリとその内容について簡単にまとめる。
| ディレクトリ名 | 意味 |
|---|---|
/bin(binary) |
sh, ls, mv, cpなど基本的なコマンドが置かれる。システムにトラブルがあるとルートファイルシステムしか使えない時があるから、そのような時でも必要なコマンド。 |
/sbin(system binary) |
システム管理用のバイナリ(実行可能な機械語のことをバイナリという)で、特にブート時に必要なもの。 |
/etc(et cetera) |
重要なシステム管理用のコマンドやデータファイルがある。sshとかmountとか。 |
/root |
BSD系のUNIXやLinuxでは、rootのホームディレクトリとしてここを使う。 |
/tmp(temporary) |
一時的なファイルを置くディレクトリ。 |
/var |
起動時には不要で、実行時に変化するもの、複数のホストで共有できないものを置く。 |
/usr |
ユーザシステムファイルには一般的なコマンドの実行形式やライブラリを置く。昔は個々のユーザのホームディレクトリなどが置かれていたからこの名前。User System Resourceの略という説もあるけど、どうやら嘘らしい。今はユーザのホームディレクトリとかは/homeとかの他の場所に置くことが多くなったけども、引き続き使われているとのこと。/binほど重要なコマンドではないけど、UNIXで標準的なコマンドは/usr/binに置かれていることが多い。 |
/opt(optional) |
後から追加するソフトウェアパッケージを置くために使われる。 |
/home |
ユーザのホームディレクトリ。MacOSでは/Usersの下にユーザーのホームディレクトリが置かれる。Linuxでは/homeの下にユーザのホームディレクトリがあることが多い。 |
プロセスについて
プロセスの資源と属性
プロセスには資源と属性がオペレーティングシステムによって割り当てられる。
プロセスが持つ資源には以下のようなものがある。
- メモリ
- スワップ領域(主記憶が不足した場合にプロセスのメモリイメージを格納する二次記憶上の領域で、通常はハードディスク)
- レジスタセット
- 開いたファイル(UNIXではプロセスごとにファイルを開いて、データをファイルから読んだりファイルに書き出したりしている。プロセスはその開いたファイルの表を持つ)
- 制御端末(プロセスごとにキーボードからのシグナルを受けとる端末が1つ定められており、この端末のこと)
- カレントワーキングディレクトリ
- ルートディレクトリ
プロセスが持つ属性には以下のようなものがある。
- プロセスID(PID)
- 親プロセスのプロセスID(PPID、プロセスがある命令を実行すると新しくプロセスができる。これ以外の方法ではプロセスはできない。つまりプロセスにはそのプロセスの生みの親がある。これを親プロセスという)
- ユーザID(UID)
- グループID(GID)
- マスク
- 状態(RとかDとかSとかZとか、
psコマンドのSTATに書いてある) - 優先順位
- 制限資源量(CPU時間とか同時に生成できるプロセス数とか)
他にもTTY(そのプロセスがどの端末と結びついているかを示す。TTなら省略形、TTYならフルネームで示す)とか。
シグナル
UNIXではプロセスにシグナルを送ることができる。プロセスはシグナルを受け取るとその時に実行中の機械語命令を中断してシグナルに対して設定された動作を実行する。シグナルには種類がある。INTなら受け取ったプロセスを終了する(interrupt)、TSTPならプロセスを殺す(terminal stop)、KILLならプロセスを殺す(TERMより強力)、STOPならプロセスを停止するなど。ここの話はBashプログラミングの章でも述べる。
ジョブ
UNIXのジョブとは、一連の仕事をしているプロセスの集合のこと。例えばls -l | lessというコマンドなら、このパイプで繋がった二つのプロセスからなる集合が一つのジョブとなる。このコマンドをCtrl-Zでどちらのプロセスも止めることができ、ジョブを止めたり殺したり再開したりすることをジョブ制御という。
キーボードの入力を伝えるジョブをフォアグラウンドジョブ、それ以外のジョブをバックグラウンドジョブという。ジョブ制御の1つの側面は、端末入出力の交通整理である。例えばcat & catというコマンドだと、前のcatはバックグラウンドジョブとして、後ろのcatはフォアグラウンドジョブとして実行される。ジョブの停止(Ctrl-Z)や終了(Ctrl-C)などはプロセスとほぼ同じ。ジョブをフォアグランドで実行するにはfgコマンドを、ジョブをバックグラウンドで実行するにはコマンドの最後に&を付ける。実行中のジョブを見るにはjobsコマンドを使う。ジョブの指定には%を用いる。例えば%nでジョブ番号nのジョブを表す。
なお、シェル自身はCtrl-Zでは止まらない。シェル自身を止めるにはsuspendコマンドを使う。ログインシェルではエラーが出てsuspendは使えないが、kill -STOP $$とすることでシェルを無理やり止めることもできる。なお、これをログインシェルでやった場合は、同じホストに開いた別のシェルからkill -CONT pid(pidは止めたシェルのプロセスID)として、再度シェルを再開させる必要がある。
インタプリタとプロセス
シェルスクリプトやperlスクリプトなどはインタプリタにより実行されるプログラム。このような実行ではプロセスはインタプリタの実行形式から作られ、インタプリタに与えるプログラムはそのプロセスが読み込む単なるデータと見なされる。一般のインタプリタの形式は以下。
#!interpreter arg-1 arg-2 arg-3
(以下プログラム)
ここでinterpreterはインタプリタの実行形式の絶対パス名。
シェルスクリプトの最初につける#!/bin/bashとかは、インタプリタとしてそのシェルを起動しなさいという意味。シェバンとかシバン(Shebang)という。ただし#!の行を解釈するのはUNIXとかのカーネルなのでシェル変数や環境変数、エイリアスは使うことができない。
プロセスの優先順位の制御
ps lのPRIが優先順位で、NIがnice値。このnice値は-20から19の数で、デフォルトでは0。この数字を大きくすると優先順位を表す数字が大きくなり、結果的に優先度が下がる。nice値を大きくするにはniceコマンドを使う。
プロセスとシステムコール
プロセスが動いている間は基本的にはメモリ中の機械語のプログラムに従ってメモリの中のデータが読み書きされていく。ファイルからデータを読み込んだり端末に文字を出力するためには、プロセスはオペレーティングシステムの機能を呼び出すことになる。これをシステムコールという。プロセスが実行していく過程でどのようにシステムコールを発行していったのかの足跡をプロセスのトレースという。Linuxではstraceコマンドで見ることができる。例えばecho hogeというコマンドのトレースを表示するにはstarce echo hogeとする。
BSD系のMacはktraceコマンドでトレースを表示して、kdumpで表示する。
アクセス制御
ユーザーとグループ
ユーザは、UNIXの外の世界では、コンピュータを使う人間のこと。UNIXの内部ではユーザ名という文字列、またはそれとほぼ1対1に対応した16ビットの整数であるユーザーIDで表す。グループとは、UNIXの外の世界では、コンピュータを扱う人間の集合のこと。UNIXの内部ではユーザと同様にグループ名という文字列、またはそれとほぼ1体1に対応した16ビットの整数であるグループIDで表す。ただし、一人のユーザが複数のグループに属するということがある。
全てのファイルやプロセスはあるユーザの所有物で、その属性にユーザID(UID)を持たせることで実現している。またユーザIDと同様に、ファイルとプロセスは属性としてグループIDも持っている。プロセスは複数のグループIDを持っているが、ファイルは一つのグループIDしか持っていない。
プロセスの所有者を見るにはwhoamiコマンドを使う。そうするとそのシェルプロセスの所有者のユーザIDがわかる。またシェルプロセスが属しているグループのグループ名を表示させるにはgroupsコマンドを使う。idというコマンドでも良い。
ユーザ名とユーザIDの対応づけはパスワードファイル/etc/passwdに記述されている。グループ名とグループIDの対応づけは/etc/groupに記述されている。
アクセス制御
アクセス制御とは、あるプロセスがファイルや他のプロセスに対して許されている操作だけを実行させること。ファイルなら内容の読み出しや書き込み、実行、属性の読み出し、変更ができるかを調べ、プロセスならシグナルを送れるかどうかを調べる。「ファイルの内容のアクセス制御」に関して、UNIXでは3段階で行う。
- ファイルのユーザIDがプロセスのユーザIDと同じ場合
- ファイルのグループIDがプロセスのグループIDのリストのどれかと同じ場合
- 上記以外の場合
「ファイルの属性のアクセス制御」については2種類あり、
- ファイルのユーザIDがプロセスのユーザIDと同じ場合
- 上記以外の場合
である。前者は全てのファイルの属性を読み出すことができてモードやグループ、時刻とかを変更できる(chmod, chgrp, touch)が、後者は読み出すのみ。
「プロセスのアクセス制御」は2段階で行う。
- 操作対象のプロセスが操作するプロセスのユーザIDと一致する場合
- 上記以外の場合
プロセスの操作としては、シグナルを送ることができるかどうかや、デバッガでデバッグすることができるか、トレースを調べることができるか、などがある。それらの操作は前者の場合は許されるが、そうでない場合は許されない。
set-uidとset-gidについて
プロセスには属性としてユーザーIDがある。これは、例えばファイルを開くときにファイルの所有者属性と比べられ、シグナルを送るときにそのシグナルを受けるプロセスのユーザIDと比べられる。プロセスのユーザID属性は、通常親プロセスから引き継ぐ。
set-uid(set user id)とは、そのコマンドを実行するときに、そのコマンドの実行形式を保存しているファイルのユーザ属性を、プロセスの属性であるユーザIDにセットして、そのユーザIDの権限でプロセスを実行する仕組みである。グループIDでもset-uidと類似の仕組みがあり、それはset-gid(set group id)と呼ばれる。
set-uidは主にスーパーユーザの権限でコマンドを実行する場合に利用される。set-uidのコマンドはls -lで見ると、ユーザによる実行可能を表すxが表示される位置にsと表示される。set-gidのコマンドはグループによる実行可能を表すxが表示される位置にsと表示される。

その他のコマンドはls -l /bin/ | egrep '^...s'などで探せる。なお、set-uid、set-gidのコマンドを作るにはchmod u+s fileやchmod g+s fileなど、chmodコマンドを使って作る。
実効ユーザIDと実ユーザID
ユーザIDには実効ユーザIDと実ユーザIDの2種類がある。同様にグループIDにも実効グループIDと実グループIDの2種類がある。アクセス制御(ファイルの読み出し書き出し、シグナルの送出など)に使われるのは実効ユーザID(実効グループID)である。実ユーザIDは、set-uidのプログラムを実行しても変わらない。実効ユーザIDが変わってしまっても、元のユーザIDは実ユーザIDを見ることで調べることができる。
インターネット
「インターネット」とは、元々ネットワークのネットワーク、つまりいくつかのネットワークをルータという機器を使って相互接続したもの。ここでいうネットワークとは、それぞれ独立した方針で運営されているコンピュータネットワークのこと。組織内のLANやパソコン通信は、「インターネット」ではないネットワークに分類される。世界最大の「インターネット」は、そのままインターネットと呼ばれている。この固有名詞としてのインターネットは次のような意味を含んでいる。
- TCP/IPという共通の通信プロトコルに基づくネットワークのネットワーク
- このネットワークを活用し発展させる人々のコミュニティ
- このネットワークを通じて到達できる資源の集積
プロトコルとは、通信を行う機器、コンピュータ、あるいはプログラムの間でどのような手順で通信するのかを定めた規則のこと。
インターネットの特徴5つ
- 繋がっている機器はコンピュータ
- ネットワークを流れるデータはコンピュータで扱える2進数
- コンピュータにはIPアドレスと呼ばれる番号が振られている
- どのコンピュータもどのコンピュータとも接続可能
- 通信をするとき使う人はIPアドレスを指定するだけでよく、使う人は途中の通信を中継しているルータの存在を気にしなくて良い
インターネットでよく利用されるアプリケーション
- 電子メール
- ファイル転送(ftp, archie)
- リモートログイン
- WWW
TCP/IPによるインターネットの仕組み
TCP/IPを用いた通信では、4つのプロトコルの層が使われることになる。TCP/IP自身は、TCP層とIP層という2つのプロトコルから成り立っている。ネットワーク通信では様々なプロトコルが決められ、全体として層をなしている。これをプロトコルスタックという。
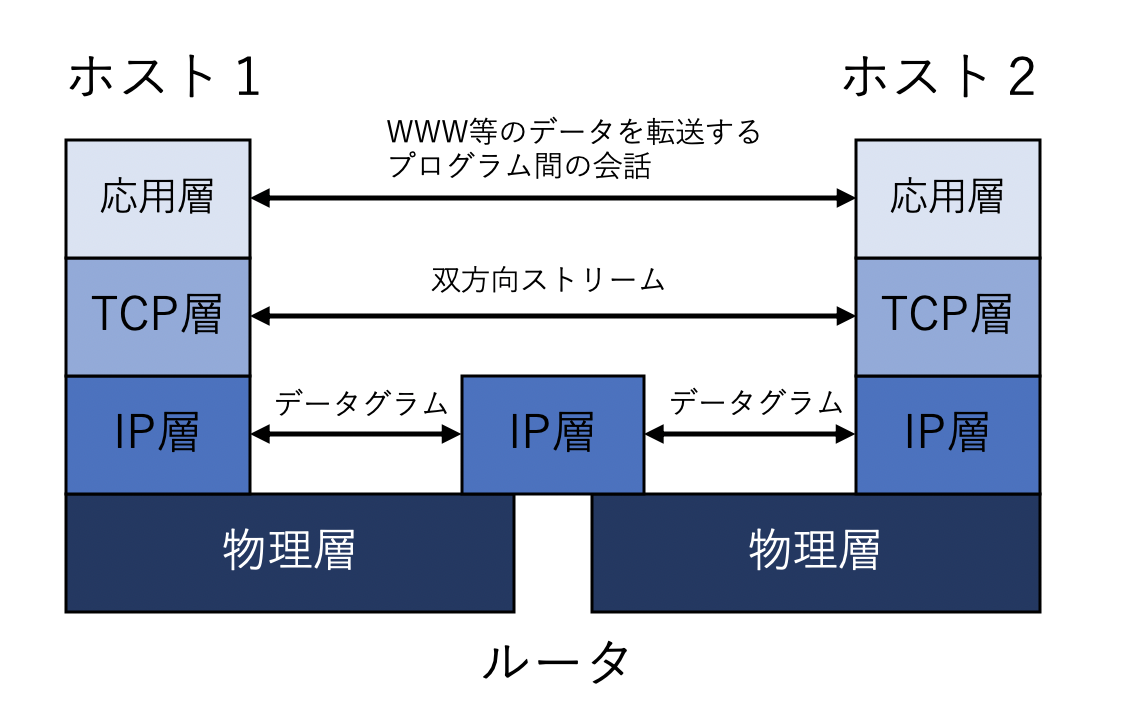
IP(Internet Protocol ) は信頼性がないデータグラム転送サービスを提供する通信プロトコル。データグラムは
- データの送り手と受け手の間に結合、通信路が作られない
- 複数回に分けて送り出したデータの順番が入れ替わる可能性がある
- 送り出したデータが途中で失われることがある
の3つの特徴がある。データグラムはパケットとも言う。IPのデータグラムが配達される時に使われる番号がIPアドレスである。
TCP(Transmission Control Protocol)はIPの機能を利用して信頼性のある双方向のストリーム転送サービスを提供する通信プロトコル。ストリームは
- データの送り手と受け手の間にコネクションが作られる
- 複数回に分けて送り出したデータの順番が入れ替わることはないが、データの区切りは保存されない
- 送り出したデータが相手に届くようにする(再送機能あり)
の3つの特徴がある。TCPで通信するためにはIPアドレスとポート番号がいる。ポート番号は16ビットの整数で、よく使われるアプリケーションにはあらかじめどの番号を使うか決まっている。このすでに決められている番号のことをwell-kwownポート番号という。
TCP層の上には応用層(アプリケーション層)が定義されている。この層では、電子メールの転送やファイル転送、リモートログイン、WWWといったTCP/IPを利用するプログラムの間の通信方法が定義されている。TCP/IPの上位に定義されているプロトコルとそのプロトコルで使われるポート番号の例を以下に示す。
| ポート番号 | プロトコルの名前 | 目的 |
|---|---|---|
| 21 | FTP(File Transfer Protocol) | ファイル転送 |
| 22 | SSH(Secure Shell) | リモートログイン |
| 25 | SMTP(Simple Mail Transfer Protocol) | 電子メールの転送 |
| 80 | HTTP(HyperText Transfer Protocol) | WWWのデータ転送 |
| 110 | POP3(Post Office Protocol ver3) | 電子メールの受信 |
| 443 | HTTPS(HTTP over TLS/SSL) | WWWのデータ転送 |
物理層では、IPのデータグラムを転送するために、様々な物理的な媒体が使われる。例えばイーサネットなど。
UDP(User Datagram Protocol) もTCPと同じようにIP上に構築されたプロトコルで、IPと同様にデータグラム転送サービスを提供する。通信相手を識別するにはIPアドレスとポート番号が必要。トランスポートプロトコルの2大有名プロトコルとしてTCPとUDPがある。
ネットワークに接続されているコンピュータの中で、ネットワークに1箇所の出入り口(ネットワークインターフェイス)を持っているものはホストと呼ばれる。2箇所以上のネットワークインターフェイスを持っているコンピュータはルータと呼ばれている。ルータはゲートウェイと呼ばれることもある。なお、ゲートウェイは異なるプロトコルを使う通信を中継するという意味もある。
仮想回線
TCP/IPで、プロセス間に形成されたストリーム通信のことを、コンピュータ間に張られた物理的な回線と考え、仮想回線という。仮想回線は以下の手順で作られる。
- サーバプロセスがポート番号を指定して、接続要求受付用ポートを作って待機する。このポートではデータの送受信はできない。
- クライアントプロセスが通信用ポートを作る。サーバプロセスが動いているホストのIPアドレスと接続要求受付用ポート番号を使って、接続要求を行う。
- 接続要求が受け付けられると、サーバプロセスは新たに通信用ポートを作る。これでお互いが通信用ポートで接続ができるようになる。
TCP/IPの通信路開設では、クライアントはサーバ側の接続要求受付用ポートのポート番号を事前に知っている必要がある(1番での話)。サーバ側は基本的には、アプリケーションごとに決まっているwell-knownポート番号を使う。クライアント側の通信用のポート番号は、OSにより空いている番号から自動で割り振られる。
DNS(Domain Name System)
TCP/IPで通信するには、通信相手のIPアドレスとポート番号が必要になる。しかし、このIPアドレスとポート番号はコンピュータにとって扱いやすいものであるが、人間にとってはわかりにくい。そこで人間にとってわかりやすいアルファベットなどを使ったホスト名からIPアドレスに変換するサービスが生まれた。このサービスを名前サービスという。これを行うプロセスを名前サーバと言い、「名前」から「名前を指している番号」に変換することを名前解決という。
インターネットで使われている名前サービスは、DNS(Domain Name System)という。DNSでは、膨大な数のホスト名を含む名前空うかんを階層的にドメイン(領域)に分割して管理する。
例えば「host1.is.u-ust.ac.jp」という名前を考える。このようにDNSで使われるホストの名前は.で区切られた文字列である。DNSで使われる名前はUNIXのファイルのパス名とは逆で、右から左に向かって解釈される。例えば上のホスト名をUNIXのパス名のように書くと「/jp/ac/u-ust/is/host1」のようになる。
このように根からの長い名前を完全ドメイン名(Full Qualified Domain Name)という。文脈によっては単にドメイン名といっただけでFQDNを意味することもあるし、ホスト名といっただけで最後の葉の部分(この例ではhost1)を指すこともある。
根の直下には、トップレベルドメイン(TLD)がある。TLDには、ISOが定めた2文字による国別コード(country code)を使う国別コード(ccTLD)と、国別コードを使わない汎用TLD(gTLD)がある。日本のccTLDは.jpであり、gTLDの例としては.comや.net、.eduなどがある。
名前サーバのクライアントとして名前解決する部分をリゾルバという。例えば「host1.is.u-ust.ac.jp」というホスト名のIPアドレスを探すことを考える。ローカルの名前サーバは、まずルートの名前サーバに問い合わせる。ルートの名前サーバは自分で知らないので、代わりにjpの名前サーバの名前とIPアドレスを返す。ローカルの名前サーバは、今度は、jpの名前サーバに問い合わせる。これも自分では知らないので、acの名前サーバのホスト名とIPアドレスを返す。こうしてさらにu-ust、isと検索が進み、最後にこのisの名前サーバが持っているhost1のIPアドレスが返されることになる。
電子メール
メールボックスはUNIXではファイルやディレクトリとして表現され、それらに直接アクセスすることでメールができる。しかし、ネットワークの別のコンピュータ上にあるメールボックスを扱う場合は、NFSを使って別のコンピュータ上にあるファイルを同一のコンピュータ上にあるものとして扱うようにするか、POPやIMAPというTCP/IP上に定義された通信プロトコルを使う必要がある。
ftpとtelnet
file transfer protocolに由来しており、ftpで使われるプロトコルを大文字でFTPと書くことが一般的。小文字の時はそのプロトコルを使って実際に通信を行うコマンド(ソフトウェア)をさすことが多い。FTPでは認証のためのユーザ名やパスワード、転送データは暗号化されないため、今ではFTPの通信をSSL/TLSにより保護したFTPSや、SSHの仕組みを利用したSFTPなどの代替プロトコルに置き換えられている。
telnetはリモートにログインするためのコマンド。これも認証を含め全て平文で送るので今はSSHが使われる。
WWW
WWW(the World Wide Web)はハイパーメディアという仕組みによって作られている。ハイパーメディアとはマルチメディアが発展し、他の情報への参照(ポインタ、リンク、ハイパーリンクとも呼ばれる)を含むようになったもの。マルチメディアとは文字や数値といったデータに加えて、静止画像、動画、音声といったデータを統合的に扱うことができるもの。ハイパーメディアの特徴は、参照をたぐって、他の情報に簡単に移動することができるという点にある。データとしてテキストしか含まれていない場合は、ハイパーテキストという。
文書に「ここは表題」といった文書の構造を示す目印をつけることをマークアップするという。マークアップのための目印を文書に埋め込むための人工言語をマークアップ言語という。HTML、LATEX、SGMLなどが代表的。軽量マークアップ言語(人間がシンプルなテキストエディタを使っての入力が容易になるように設計された簡潔な文法を持つマークアップ言語)の例としてMarkdownがある。QiitaもgithubもMarkdownを採用している。
HTMLでは他のデータの参照を実現するために URL(Uniform Resource Locator) という形式を用いる。一般的なURLの形は以下。
http://www.u-ust.ac.jp/dir/index.html
上の例でのURLの先頭のhttpはHTTP(HyperText Transfer Protocol)という通信プロトコルを表している。このプロトコルは、WWWのデータを保持しているプロセス(WWWサーバ、あるいはHTTP Daemonやhttpdなど)と、WWWを表示するプロセス(WWWクライアント、普通はWWWブラウザ)の間で通信によりデータをやりとりする形式を定めた約束。
www.u-ust.ac.jpはそのデータを持っているコンピュータの名前(ドメイン名)で、残りの/dir/index.htmlの部分が、そのコンピュータの中でのデータの名前(普通はファイルの名前が使われる)だが、最近はこの構造のURLも少なくなってきている。
URLの一般的な形
scheme:scheme-specific-part
scheme(スキーム)とは、データを取ってくるための仕組み。schemeには通信プロトコル(http, ftpなど)が来ることが多いが、それ以外もある(file, mailtoなど)。インターネットで使われるURLだとscheme-specific-partの部分は//host/pathnameという形が多い。これは次の//user:password@host:port/pathnameという一般形が省略されたもの。
他のURLの例としてはhttp://host1.is.u-ust.ac.jp/path?patternというものもある。これは多くの場合、/pathに対応したプログラムが実行されて、patternがその引数となる。
他にもfile:///dir1/file1では、同一ホスト上の「/dir1/file1」という名前のファイルを示す。
Proxyとキャッシュ
WWWサーバは基本的には直接WWWサーバに要求を送る。WWWサーバ(httpd)は普通はファイルからデータを読み出し、WWWブラウザに返す。しかし、設定によってはWWWブラウザは直接WWWサーバに要求を送らずに、WWWProxyサーバに要求を送ることがある。プロキシとは代理の意味で、WWWブラウザに変わってWWWサーバと通信をするプロセスを表す。WWWProxyはWWWブラウザから受け取った要求をWWWサーバに送り、WWWサーバから送られてきた結果をWWWブラウザに返す。
WWWプロキシを使う目的は以下
- キャッシング(caching)
一度アクセスした内容のページを自分のハードディスクに保存する。この保存されたものをキャッシュ(cache)という。同じページに対する要求が来た場合にはProxyはローカルのハードディスクにあるキャッシュを返す - ファイアーウォールを超えるため
セキュリティ確保のため、ファイアーウォールの内側のコンピュータは外のコンピュータに直接接続できないようになっていることがあるので、その中継のため - より高速な通信経路を選ぶため
なお、キャッシングは、ブラウザのメモリやブラウザが動いているホストのディスク(ファイル)に行われることもある。この場合、WWWブラウザはWWWサーバに要求を送る前に、まずメモリやファイルにキャッシュが保存されていないかをチェックし、あればそれを使うようになる。
CGI
WWWサーバは、普通はファイルに保存されたHTMLデータやイメージデータを読み込み、WWWブラウザに返す。これに対して、CGI(Common Gateway Interface)では、ファイルが読み込まれる代わりにコマンドが実行され、その実行結果がブラウザに返される。ここでいうGatewayは、WWWで使われているHTTPというプロトコルへの入り口という意味。
SSI(Server Side Include)
CGIではどのようなプログラムも実行することができるが、設定が少し複雑になる。これに対してSSIは、CGIよりも手軽にHTMLの途中に、他のファイルの内容や、プログラムの実行結果を埋め込むための仕組みである。
残りは後編に続きます。