この記事について
UNIX系のパソコンについて基本的なことをまとめています。この記事を読んでちゃんと理解すればUNIXについての理解がかなり深まると思います。前編は以下のリンクからどうぞ。
UNIXの基礎(前編)
https://qiita.com/minnsou/items/6b6b74fcd79bd00ace1a
環境設定
環境の設定方法
UNIXで使われるシェル(sh, csh, bashなど)はカスタマイズができるようになっている。コマンドのカスタマイズの仕方は大きく分けて2つある。
- 設定ファイルによる方法
設定ファイルとはコマンドの設定を記述するファイルで、一般に設定ファイルを使うコマンドは、起動されると最初に設定ファイルの内容を読み込み、その記述によって動作を変える。設定ファイルは例えばshなら.profileだし、bashなら.bash_profileや.bashrcを使う。これはシェルによって異なる。 - 環境変数による方法
環境変数は変数に値を設定して使う。コマンドは起動されると必要に応じて環境変数の値を調べ、設定されている値によって動作を変える。環境変数は設定ファイルの中で設定するのが普通。
対話的シェルと非対話的シェル
シェルの起動には対話的と非対話的の2種類がある。対話的というのは「人間が要求を出すとそれをコンピュータが処理する」というような作業を繰り返し行うような形態のこと。非対話的というのは処理の内容をすべてあらかじめファイルか何かに記述しておき、コンピュータがその内容を読み出して処理するような形態のこと。
cshの設定ファイルである.cshrcのように非対話的シェルでも読み込まれるような設定ファイルでは、メッセージを表示したり端末を設定する場合には通常エラーになるので注意。cshならシェル変数$promptを使って場合分けをする必要がある。
シェル変数と環境変数
シェルの設定ファイルではシェル変数および環境変数、エイリアスなどの設定を行う。
シェル変数はシェルが固有にもつ変数。この変数の中には特別な意味を持った変数があり、そういった変数を設定することでシェルの動作を変更できる。
環境変数はシェルではなく、UNIXで使われるすべてのプロセスがそれぞれ保有する変数。あるプロセスから別のプロセスが作られた時に、新しく作られたプロセスは元のプロセスで設定されていた環境変数をそのまま受け継ぐようになっている。
シェル変数と環境変数は、「環境変数は子プロセスに渡されるが、シェル変数は渡されない(環境変数はカーネルが管理しているので、子プロセスが生成されたとき、つまりシェルからコマンドが起動されたときにカーネルがシェルの環境変数のコピーを子プロセスに渡せるが、シェル変数はシェルが管理するのでカーネルは感知しない)」という点で異なる。シェル変数と環境変数が混乱する時は**「シェル変数はシェル自身の動作を設定するために使い、環境変数はシェルが起動するコマンドの動作を設定するために使う」**と覚えると良い。
シェル変数はsh、bash、zshだとvariable=valueで設定する。=の両端にスペースは入れない。シェル変数の例としては、
- プロンプト(
PS1は$、PS2は>、PS4は#が基本の設定。なお、MacのPS1のデフォルトは\h:\W \u \$で、\hはホスト名、\Wがカレントディレクトリ名、\uはユーザ名を表す。) - historyに保存するコマンドの数(
HISTSIZE) - ヒストリ置換で用いられる文字(
histchars、これはデフォルトで!と^だけど変数には何も入っていないので、histchars=%みたいに設定すればこの文字は変えられる)
などがある。
環境変数の例としてはPATH, TERM, HOME, USER, SHELLなど(bashは小文字ではだめ)で、一般に大文字である。どれもecho $PATHとかで見れる。自分が定義したシェル変数aを環境変数にしたい時は、export aとする。ただしこのようにした環境変数も、そのシェルからログアウトすると消えてしまうので、永続的に残したい時には.bashrc等に書いておく必要がある。
printenvコマンドやexportコマンドで全ての環境変数が見れるし、man environでそのシステムで使われている代表的な環境変数についての説明が見れる。シェル変数を全部見るのはdeclareコマンド(ただし定義されている関数も見える)。
エイリアス
コマンドに別名をつける機能。この機能により、次のようなことができる。
- タイピングの手間を減らす(
alias md=mkdirとか) - 新しいコマンドを作る(独自のコマンドを作るとか)
- タイプミスを先取りする(
alias mroe=moreとか) - コマンドの意味を変える(
alias ls='ls -F'とか) - シェルスクリプトではできないことを行う(現在使っているシェルのシェル変数や環境変数を設定するのはシェルスクリプトでは無意味、なぜならそのシェルスクリプトを実行する時には別のシェルが起動されるから)
端末の設定
端末の設定も、シェルの設定ファイルで設定される項目の一つ。端末の設定の最も重要なコマンドはsttyコマンドである。sttyコマンドでは、端末の割り当てキーや出力のモードなどの設定を行うことができる。例えばstty erase ^Hというコマンドで一文字削除のキーがCtrl-Hになる。以下はsttyで変更できるキーのうち、よく使うものを書き出した。
| 機能 | デフォルトのキー | 意味 |
|---|---|---|
| erase | ^? (Del) | 1文字削除 |
| kill | ^U | 1行削除 |
| werase | ^W | 1単語削除 |
| susp | ^Z | サスペンド(ジョブ制御) |
| intr | ^C | 実行の停止 |
| eof | ^D | ファイルの終了(シェルの場合ログアウト) |
(UNIXでの)正規表現
正規表現とは、ある規則に基づいて文字列の集合を表す方法の1つである。今後この記事で使われる正規表現は、UNIXで使われる正規表現であって、オートマトン理論や言語理論で使われる正規表現とは少し異なることに注意。
例えば^a.*tion$という文字列では、「行の最初(^)にaがあり、任意の1文字(.)の0回以上の繰り返し(*)があり、tionが続いて、行の終わり($)がある」という意味になる。^や*のように、特別な意味を持つ文字のことをメタキャラクタという。
正規表現は1種類ではなく、ツールによって実現している機能が制限されていたり、表現方法が微妙に異なる。ここでは、大きく2つに分けて紹介する。
-
grepやed、vi、sed、less系の正規表現 -
egrepやawk系の正規表現
なお、シェルのファイル名置換で使われる*(任意の文字列)や?(任意の1文字)のようなメタキャラクタとは記号の意味が少し異なることに注意。ps | grep *tionのようにコマンド入力してしまうと、*がシェルによって先にファイル名置換されてしまう。ps | grep '*.tion'のように''で囲む必要がある。
1. grepやed、vi、less系の正規表現
-
\mメタキャラクタmの意味をなくす -
^行の先頭 -
$行の終わり -
.任意の一文字 -
[c1c2...cn]並べた文字のうちの任意の1文字(例えば[abc]ならaかbかc) -
[^c1c2...cn]並べた文字以外の任意の1文字(例えば[^abs]ならaとbとs以外の任意の1文字) -
r*正規表現rの0回以上の繰り返し -
\(r\)タグ付き正規表現r(これは正規表現をグループ化するもので、この後ろに*をつけると0回以上の繰り返しが表せる) -
\NN番目のタグ付き正規表現がマッチした文字列を表す
例えば、
-
a*cは、「c」「ac」「aac」などにマッチする。 -
\([ab]c\)\1は、「acac」または「bcbc」にマッチする。「\([ab]c\)」で「ac」をマッチした時は「\1」は「ac」を表すので、「acbc」などにはマッチしない。
2. egrepやawk系の正規表現
基本的には上記の正規表現と同じだが、言語理論で定義されている正規表現の形式が使えるようになった。
-
r+正規表現rの1回以上の繰り返し -
r?正規表現rが1つある、またはない -
r1 | r2正規表現r1またはr2(orの意味) -
(r)正規表現rのグループ化(これによりタグ付き正規表現はegrep等では使えなくなった)
例えば、
-
ab+cは、「abc」「abbc」「abbbc」などにマッチする -
(a|b)cは、「ac」または「bc」にマッチする
検索と置換
検索
基本的にファイル内の単語の検索にはviとかemacsの検索やgrepを使い、ファイル名の検索はfindコマンドを使う。
viではコマンドモードで/keywordで順方向検索、?keywordで逆方向検索をする。emacsはCtrl-S keywordで順方向検索、Ctrl-R keywordで逆方向検索をする。
grepやegrep、fgrepは、あるデータを受け取り、その中から指定された文字列と一致する行を抜き出して出力するコマンド。grep keyword filesというのが基本の形で、ファイル名filesが指定されていない時は、標準入力からデータを入力する。grepはいわゆる「grepファミリー」の中で最古参のもの。egrepは基本はgrepだが、扱える正規表現が拡張されている。fgrepは複数の文字列を同時に検索できるが、正規表現は使えない。
findコマンドはファイルそのものの検索を行う。findコマンドの標準的な使い方は以下。
find ディレクトリ 検索条件
例えばfind . -name '*.py'とすればカレントワーキングディレクトリ以下で名前の最後が.pyとなっているファイルを全部探すという意味になる。他にもfind . -name '*.py' -atime +15とすれば16日以上アクセスされていないファイルを検索してくれる。-atimeは最終アクセス時刻(access time)を表す。
もう少し実用的な例としてはfind . -name '*~' -exec rm {} \; -printがある。これは~で終わるファイル名を削除(rm {})して、表示をする(-print)というもの。-execオプションは、エスケープされたセミコロン(\;)までのUNIXコマンドを実行するもので、{}には条件に適合したパス名が入るようになっている。
置換
viでの置換は、viのもう1つの顔であるexコマンドの置換機能と同じである。edやsedも似たような置換コマンドを使う。基本的には次のような書式をしていて、patternにマッチする文字列をstringに置換する。
range s/pattern/string/g
rangeには置換範囲を指定する。例えば%で全体、start,endでstartからendまでの行を表す。patternやstringには正規表現が使える。最後の/gは1行中にある全ての置換該当箇所を変更することを意味する。ここらへんの詳細は、sedコマンドを紹介するところで詳しく扱う。なお、emacsの置換はM-%(M-x query-replace)で可能。
フィルタ
フィルタとは、標準入力から入力したデータを加工して、その結果を標準入力へ出力するようなプログラムのこと。大きく分けて2つあり、1つ目はフィルタ自身にプログラムを与えてフィルタ機能を指定できるもの(sed、awk、perlなど)、2つ目ははじめから機能が決まっているもの(head、tailなど)である。
フィルタの例
headコマンドとtailコマンドを用いて新しい機能を持つフィルタを例として作る。belly n mでn行目からm行目までを取り出すフィルタとする。bellyの中身は以下。
#!/bin/bash
from=$1
to=$2
arg=$(($to - $from + 1))
head -$to | tail -$arg
これでcat -n foo.txt | ./belly 12 14というコマンドでfoo.txtの12行目から14行目を取り出すことができる。
teeコマンド
引数として指定したファイルと標準出力の両方に、標準入力からの入力を出力するフィルタ。
例えば make | tee bar.txt とすればmakeコマンドの結果をbar.txtに出力しつつ、画面にも出力できる。
sortコマンド
標準入力からの入力を行単位でソートして標準出力に出すフィルタ。
例えば ls -l | sort -nr +4 だと4番目のフィールド(ファイルの大きさ)を数値として比較し降順に並べる。
-nは数値として比較する、-rは指定された方法で逆順で表示、-fは大文字と小文字を区別しないという意味。
uniqコマンド
標準入力からの入力の隣接した行が同じ内容であれば重複とみなし、その重複行を除いて標準出力に出すフィルタ。
例えばOLDディレクトリにファイルaaとbb、ccがありNEWディレクトリにファイルaa1とbb、ccがあるとする。
(ls OLD; ls NEW) | sortとすると
aa
aa1
bb
bb
cc
cc
と表示されるが、(ls OLD; ls NEW) | sort | uniqとすると
aa
aa1
bb
cc
と表示される。かぶっているbbとccが消える。
trコマンド
標準入力からの入力を文字単位で置換して標準出力に出すフィルタ。
tr old-string new-stringという形で使い、old-stringに現れる文字をnew-stringに対応する文字で置き換える。tr ab XYならaをXに、bをYに置き換える。tr a-z A-Zなら全てのアルファベットが大文字で置換されて表示される。
例えばls | tr a-z A-Zとすれば、ファイル名が全て大文字で表示される。
なお、-dオプションを指定すると、指定した文字を削除するフィルタになるので、cat file | tr -d '\015'とすると制御文字のCRを消したものができる(Windowsは行末がCR LFでUNIXはLFだけなので上記のコマンドで改行が直る)。
expandコマンド
標準入力からの入力のタブを相当する数の空白に変換して標準出力に出すフィルタ。
unexpandは逆に連続した空白をタブに置き換えるフィルタ。
foldコマンド
標準入力からの入力を、各行の長さが一定文字数となるように強制改行してから標準出力に出すフィルタ。
例えばexpand file | fold -65というコマンドで行幅を65文字にする。foldコマンドはタブを解釈しないのでこの例のようにexpandで前処理する。
prコマンド
標準入力からの入力をラインプリンタ向けの出力形式に変換して標準出力に出力するフィルタ。具体的には、各ページ番号のヘッダとして、ファイルの名前や時刻、ページ番号を追加することや文章をマルチカラム化するといった処理が可能になる。
sedコマンド
sed(stream editor)はフィルタとして用いることを目的として設計されたエディタ。
sed commandというのが基本的な形。commandは「どのアドレスにマッチする行に、どのような関数を適用するか」を表したもの。[ address1 [, address2 ] ] functionという形式である。アドレスを1つ指定するとその行のみ、アドレスを2つ指定するとその2つのアドレスの間の全ての行に対して、アドレスを指定しないと全ての行に対して関数functionを適用する。
アドレスの指定にはいくつかの方法がある。数字で行数を表したり、正規表現も使える。例えば10pなら、10行目にp関数を適用する。/^a/,/^b/pなら、aで始まる行からbで始まる行までにp関数を適用する。
各関数については以下。
- p関数は処理中の行の内容を出力するために使う関数。sedは標準ではコマンドで処理した結果を出力するが、
-nオプションを指定した時は自動的な行の出力を行わないようになるので、p関数で明示した行だけが表示されるようになる。例えばcat -n /usr/share/dict/words |sed -n '100, 105p'ってやると100行目から105行目までの各行が表示される。 - d関数は入力から不要な行を削除するために使う関数。例えば
sed '/^BEGIN/,/^END/d'というコマンドだと行頭でBEGINから始まる行から、行頭でENDで始まる行までを削除する。
q関数はアドレスにマッチした時点でsedの実行を終了する関数でsed -e '100, 105p' -e '105q'のように使う。-eは複数の関数を処理したい時に使うオプション。この例では105行目の時点でsedの実行が終了する。 - s関数は正規表現を利用した文字列置換を行う関数。
s/regular-expression/replacement/flagsという形で表現する。処理中の行に関して検索パターンregular-expressionに指定した正規表現にマッチする最初の文字列を、置換パターンreplacementに指定した文字列で置換する。flagsにはs関数の動作を変更するためのフラグを指定する。例えばgなら行内で正規表現にマッチする文字列を全て置換する(デフォルトでは最初にマッチする文字列のみしか置換しない)。pならマッチした行を出力する。 - y関数は
trコマンドと同じく、入力単位で置換する関数。例えばy/aiueo/AIUEO/とすればaiueoの文字が全て大文字になる。
その他にも分岐や中間保存の結果などできるが、詳細は省略する。
awk(オーク)コマンド
awkはパターンに従って入力行を処理するための言語。入力の各行がスペースやタブのような区切り文字で分割されている表のような形式のファイルの処理を得意としている。cに少し近い。awkを実行するにはawk programという引数としてprogramを指定する方法と、awk -f program-fileとしてプログラムをファイルprogram-fileに書き込んでおいてそれを-fオプションで指定する方法がある。
programの中身は
pattern1 { action1 }
pattern2 { action2 }
...
であり、**入力に対するパターンpatternとパターンにマッチした際に実行するアクションaction**を対にして記述する。patternが省略された時は、全ての入力行に大してアクションactionが行われる。{ action }が省略された時は、patternにマッチした行を出力する。
正規表現によるパターンは/囲んで指定する。awk '/^From:/'とすればFrom:で始まる行を全て出力する。なお、コマンドラインでawkプログラムを指定する場合には、awkに与えるプログラムが1つの引数になるように'で囲むのを忘れないようにする。
awkは入力行を区切り文字によって自動的にフィールドに分割する。例えばls -lなら$1にモード(-rw-r--r--とかのやつ)、$2にハードリンクの数、$3は所有者名、$4にグループ名、$5にはファイルの大きさなどのように入る(ls -lの表示順になっている)。
例えばls -l | awk '$5 > 1000{ print "size of file", $9, "is", $5;}'とすると
size of file filename1 is 34694
size of file filename2 is 1011
size of file filename3 is 56203
のようにファイルのサイズが1000より大きいものだけ表示される。なお、actionにはprint以外にも変数の代入や演算、ifやforなどの制御文も入れることができるが詳しくは省略する。
圧縮とアーカイブ
圧縮
コンピュータ科学の分野では、何らかの形式で表現された情報をその内容を失うことなくその分量(データ量)を減らすための仕組みが古くから考えられてきた。このような仕組みのことをデータ圧縮、あるいは単に圧縮という。圧縮されたファイルを元に戻すことを伸長という。
compressコマンドは圧縮率はそこまで高くないけど、処理速度も遅くなく、ほとんどのUNIXシステムに標準で付属している。圧縮すると.Zという拡張子が付く。伸長にはuncompressコマンドを使う。
gzipコマンドだと、.gzという拡張子が付く。これはGNUソフトウェアの一種。gzipコマンドで圧縮されたファイルを伸張する時にはgunzipコマンドを使う。なおzcatというコマンドを使えばcompressコマンドで圧縮されたファイルもgzipコマンドで圧縮されたファイルも伸長できる場合がある。bzip2という圧縮コマンドもある。伸長にはbunzip2コマンドを使う。
アーカイブ
複数のファイルをまとめて1つのファイルにすることをアーカイブするという。アーカイブするためのコマンドにはtar, shar, cpio, zipなどがある。
tarはtape archiveの略で、元々は磁気テープにアーカイブファイルを作るためのコマンドだった。しかし、使用できるメディアが磁気テープに限られているわけではない。このコマンドはtar key filename...という形で使用する。keyにはc、t、x、r、uという5つのコマンド文字のうち1つのみと、必要な場合はオプションが含まれる。
-
cはtarファイルを作る -
tはtarファイルの中身を調べる -
xはtarファイルからファイルを取り出す -
rとuはtarファイルの末尾にファイルを追加する
よく使うオプションは以下。
-
vオプションはverbose(おしゃべりな)の意味で、これを指定するとアーカイブの処理対象となるファイル名を順次出力する -
fオプションは引数を1つ取り、作成するtarファイルの名前を指定する
ただしtarにおけるオプションには「-」という文字を付けずに、コマンド文字や他のオプションと繋げて指定する。例えばtar cvf srcfiles.tar ./srcで、./srcを元にscrfiles.tarというtarファイルを作る。
GNU tarもあり、元々のtarコマンドを拡張している。これはgtarというコマンド名の時もあるし、tarというコマンド名になっている時もある。
アーカイブのためのコマンドとしてはshar、cpio、zipなど他にもたくさんあるが、ここでは省略する。
時刻
現在の時刻を知る
時刻を見るにはdateコマンドを使う。-uオプションでグリニッジ標準時になる。
カレンダーを見る
カレンダーを見るにはcalコマンド。例えばcal 11 2019で2019年11月のカレンダーが見れる。なお、引数が1つの場合には、年であると解釈されるので注意。
アラーム時計を使う
leaveコマンドはアラーム時計として使うことができる。leave 1920とすれば19時20分にアラームがセットされ、ビープ音とともにメッセージが出てくる。leave +30という指定の仕方(30分後にメッセージを出す)もあり、現在からの相対時間でアラームを設定することも可能。いらない時はkillコマンドを使う。
インターバルを取る
sleepコマンドでは、文字通り何もしないで休むコマンドである。引数に与えられた秒数だけ何もしないで休み、終了するコマンド。例えばsleep 300; echo "Tea is just ready." &というコマンドを実行すると、5分後にechoコマンドが実行されてメッセージが表示される。
指定した時刻にコマンドを実行する
自分の決めた時刻にコマンドを実行する方法のひとつとして、atコマンドがある。これは指定した時間に指定されたシェルスクリプトを実行するもの。at time [filename]という書式でtimeに起動する時間、filenameに実行するシェルスクリプト名を入れる。filenameを指定しないときは標準入力からシェルスクリプトを読み込んでそれを実行する。例えばat 6am 6 scriptというコマンドなら6月6日の午前6時にscriptが実行される。ただしこのコマンドはデフォルトでshを使う。またこのスクリプトの標準出力や標準エラー出力はメールで来るので、それが嫌ならリダイレクション(> result.outとか)をする。
atコマンドで実行を指定したシェルスクリプトの状況はatqコマンドで知ることができる。atコマンドで指定したシェルスクリプトの実行を取り消すにはatrmコマンドを使う。
定期的に仕事を行う
UNIXには定期的にコマンドを起動するような仕組みが用意されている。この仕組みを使うと毎日不要なファイルを自動的に削除する、というようなことが可能になる。この仕組みはcronというデーモンによって実現されている。また、定期的に実行されるコマンドの設定を行うファイルをcrontabファイルという。cronデーモンはcrontabファイルの内容を参照して、コマンドの定期的な実行を行う。
crontabファイルの設定にはcrontabコマンドを使う。crontabファイルを新たに作成する場合や、その内容を変更する場合にはcrontab -eとする。そうするとエディタが起動され、そのユーザのcrontabファイルが読み込まれる。
crontabファイルには、1行に1つの設定をかく。一般ユーザが使うcrontabファイルでは、各行は空白で区切られた以下のような6つの要素で構成される。
min hour day mon day-of-week command
最初の4つは、分(min)、時(hour)、日(day)、月(mon)の指定である。day-of-weekは曜日の指定で、0が日曜日、1が月曜日のように指定する。
例えば
0 0 1 1 * find $HOME -name '*core' -atime +7 exec rm {} \;
という行があると、1月1日の0時0分にfind $HOME -name '*core' -atime +7 exec rm {} \;というコマンドが実行される。コマンドを指定する最初の5つのフィールドで数字の代わりに*を指定すると、そのフィールドの数字がいくつの時でもコマンドが実行されるようになる。crontabファイルの内容の表示には-lオプションをつけて実行する。crontabファイルを削除する時にはcrontab -rで削除する。
コマンドの実行時間を測る
コマンドの実行時間を測るにはtimeコマンドを使う。time commandの形式。
bashプログラミング
シェルスクリプト
一括で実行するようにコマンドをあらかじめファイルに格納したものをシェルスクリプトという。やや古めかしい言い方だが、実行を開始する前に処理方法を決めておくという意味でバッチと呼ぶこともある。また何らかの目的のために処理が組まれているという点からシェルプログラムと呼ばれることもある。
シェルスクリプトを実行するときに毎回bash script_nameと打つのは面倒なので、ファイルの先頭に#!/bin/bashと入れておくとコマンドとして実行できるようになる。つまり./file_nameと打つだけでこれが実行できるようになる(ただしchmod +x file_nameのようにファイルのモードを実行可能にしておく必要がある)。このようにコマンドとして実行できるシェルスクリプトをシェルコマンドと呼ぶ。
シェルコマンド実行時の挙動
まずbashはコマンド名がfile_nameということを知ると、コマンドサーチパスからこのファイルを探す(ただし./file_nameの時は既にパスを指定しているのでパスから探すことはしない)。そしてそのファイルが実行可能モードの時、ファイルの1行目をみる。
- 行頭が
#!の時は、そのファイルの実行をカーネルに要求する。そして#!の後の絶対パス名で指定されるファイルをプログラムとして起動する。例えば#!/bin/cshとか#!/usr/bin/pythonとか。テキストファイルをその入力とする。絶対パスの後に書かれているものは引数とみなす。 - それ以外の場合は
bashを起動して、残りのテキストファイルをその入力とする
なお#の扱いは対話的にシェルを使っている時と、非対話的異なるので注意。シェルスクリプトで#を使っている時はコメントとして認識されてしまうので注意。例えばrm important#とコマンドラインから実行させるのとシェルスクリプトで実行させるのでは、消えるファイルが異なってしまう。シェルスクリプトでimportant#を消したい時には、important\#のようにエスケープする。
bashとかを起動させた時、起動させるbashのカレントワーキングディレクトリと起動させたカレントワーキングディレクトリは一致している。相対パスも使ってシェルコマンドを実行させることもできる。
変数の詳細
bashにおいて、変数では配列も使用することができる。例えばnames=(hatter duchess alice)という配列を宣言する。これでecho ${names[0]}のように値を参照することができる。
シェルスクリプトを書く時には、ある変数が定義されていない時にはデフォルト値を使用したり、配列の数に応じた処理をしたい時がある。そのためにbashには、変数が定義されているかどうかを調べたり、配列の数を調べる方法が用意されている。基本的なものを以下にあげる。
| 指定 | 意味 |
|---|---|
| ${variable} | 変数varibleの値(例えば変数の値$aの直後に文字zをつけたい時に$azだと変数azと解釈されてしまうので${a}zとする) |
| ${#variable} | 配列variableの要素数 |
| $# | シェルコマンドを起動した時の引数の数 |
| $0 | シェルコマンドのファイル名 |
| $num | シェルコマンドを起動した時のnum番目の引数 |
| $* | シェルコマンドを起動した時の全ての引数(配列ではなく文字列) |
| ${variable:-word} | variableで指定される変数が定義されていればその値、定義されていなければwordの値 |
| ${variable:=word} | variableで指定される変数が定義されていればその値、定義されていなければwordの値として、さらにその値をvariableにセットする |
| ${variable:?word} | variableで指定される変数が定義されていればその値、定義されていなければwordの値を表示して終了 |
| ${variable:+word} | variableで指定される変数が定義されていればその値、定義されていなければ空文字列 |
なお、標準入力から変数に入力するにはreadコマンドを使う。
シェルスクリプトの実際の例はscript.shというファイルに書いた。
#!/bin/bash
echo "this result is produced by $0"
echo '$#' is $#
echo '$*' is $*
echo '$$' is $$ '(process id)'
echo ${word:-abcg}
echo '$1' is ${word:=$1}
これを./script.sh hello bashとコマンドラインで実行すると以下のようになる。
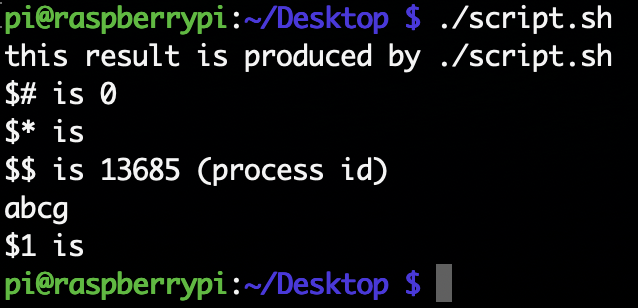
$$はそのシェルのプロセスIDを表す。これを使う典型例としてシェルスクリプトで使う一時ファイルを作るという例がある。tmp=tmp.$$のように代入しておけば、プロセスIDはそのプロセスが終了するまでは絶対に被らないという性質を用いて安全に一時ファイルが作れる。
I/Oリダイレクション
プロセスの入力や出力はデスクリプタと呼ばれる0から始まる番号を使って指定する。0は標準入力、1は標準出力、2は標準エラー出力を表す。num>fileという形でデスクリプタnumへの出力をfileに出力することが可能。リダイレクションの>の後に&とデスクリプタnumをつけて>&numとすると、numのファイルにその出力がリダイレクトされる。分かりづらいので例を挙げる。
以下のoutput.shは標準出力にstdoutという文字列を、標準エラー出力にstderrという文字列を出すスクリプトである。
#!/bin/bash
echo "stdout" >&1
echo "stderr" >&2
これはhttps://qiita.com/laikuaut/items/e1cc312ffc7ec2c872fc からいただきました。
-
./output.sh > aで、aにstdoutの文字列が入る。これは./output.sh 1> aと同じで1が省略されているだけ。 -
./output.sh 2> aで、aにstderrの文字列が入る。 -
./output.sh 1> a 2> bで、stdoutの文字列がaに、stderrの文字列がbに入る。 -
./output.sh >& aで、aに両方の文字列が入る。>と&の間にスペースを入れるとエラーとなる。 -
./output.sh > a 2>&1では、aに両方の文字列が入る。 -
./output.sh 2>&1 > aでは、aにstdoutの文字列しか入らない。これは最初の2>&1の時点でstderrという文字列を標準出力に出力してしまうからである。そのあとで> aをするので標準出力だけがファイルに書き込まれる。
制御構造について
プログラミングでは、条件判断をした上で、次にどの部分を実行するか決めたり、ある条件を満たすまで処理を繰り返すということが必要な場合がある。このような実行を制御するための構文として、ここでは
- if
- for
- while
- case
- 関数
- 制御構造を支えるその他のコマンド
を取り上げる。
1. if
ifの文法は以下。
if commandlist1
then commandlist2
else commandlist3
fi
コマンドリスト(commandlist) とは、コマンドを;や改行などで区切って並べたもの。ifコマンドではcommandlist1の実行結果(つまり最後のコマンドの終了ステータス)が正常終了(0)の時は条件が成立したとしてcommandlist2を実行する。そうでなければcommandlist3を実行する。fiはifを逆にしたもの。elifも存在する。
2. for
forの文法は以下。
for variable in list
do commandlist
done
for文では、リストlistの先頭のワードを変数variableの値としてセットして、doからdoneまでのコマンドリストcommandlistを実行する。次にリストの2番目のワードをvariableにセットして...を繰り返す。continueコマンドやbreakコマンドもある。
リストは複数の表現方法がある。for i in a1.py a2.pyのように列挙しても良いし、for i in *.pyのようにファイル名置換を用いても良い。bashではIFSという区切り文字を表す環境変数に:を設定してfor i in $PATHとすることで、パスのひとつひとつを変数iに代入することができる。
具体例としては以下のif_for.sh。
#!/bin/bash
for i in u.c t.c
do
echo $i
cc -c $i
if [ $? != 0 ] # ここはif test $? != 0でも同じ
then break
fi
done
ccはコンパイルするコマンド。コンパイルに失敗する(u.cとかt.cというファイル名は適当に決めた名前なのでコンパイルできない)ので$?には0以外の値が入る。[コマンドは[ exp ]という形式で、expの式を計算して結果が真なら正常終了し(終了ステータスとして0を返す)、そうでないなら異常終了する(終了ステータスとして1を返す)コマンド。[コマンドと同じものにtestコマンドがある。今回はu.cというファイルは(多分)存在しないのでちゃんとforループが止まれば大丈夫。
式expには様々な表現があるので一部を示す。
-
-a filenameファイルfilenameが存在する -
-d filenameファイルfilenameが存在してディレクトリである -
str1 = str2文字列str1と文字列str2が等しい -
str1 != str2文字列str1と文字列str2が等しくない -
num1 -eq num2数として比較した時に、整数num1 = 整数num2(equal)である -
num1 -gt num2数として比較した時に、整数num1 > 整数num2(greater than)である
3. while
whileの文法は以下。
while commandlist1
do commandlist2
done
これはcommandlist1が正常終了する(終了ステータスとして0を返す)までcommandlist2を繰り返すというもの。具体例としては以下のwhile.sh。
while true
do
sleep 10
w
done
これは10秒ごとにwコマンドを実行するというもの。wコマンドは誰がログインしているか、そして何をしているかを表示するコマンド。whileの後のコマンドは、それが正常終了すれば(つまり$?が0のとき)ループに入る。trueコマンドは正常終了するだけのコマンドなので永遠にループする。falseコマンドもあり、これは異常終了するだけのコマンド。
4. case
caseの文法は以下。
case string in
pattern1 ) commandlist1 ;;
pattern2 ) commandlist2 ;;
...
esac
まず文字列stringがpattern1とマッチするかを調べて、マッチしたらcommandlist1を実行する。マッチしない時はpattern2に移る。これを繰り返すというのがcase文である。最後のesacはcaseを逆から記述したもの。具体例としては以下のcase.sh。
#!/bin/bash
for word in *
do
case $word in
*.out)
echo $word is out file;;
*.sh)
echo $word is sh file;;
*)
echo $word is other file;;
esac
done
例えばあるディレクトリにaa.out bb.sh cc.txtというファイルがある時、これを実行すると
aa.out is out file
bb.sh is sh file
cc.txt is txt file
と表示される。
5. 関数
関数はname () { commandlist ; }という形式で定義できる。この定義を実行した後では、nameをコマンドとして実行すると、対応するcommandlistが実行される。具体例は以下で、func.shに書いた。
go () {
echo "file name = $1"
if test ! -r $1 # !は否定の意味
then echo $1 is not found
else echo $1 is found
fi
}
go foo.txt
go bar.txt
foo.txtというファイルが存在し、bar.txtというファイルが存在しないディレクトリで./func_script.shで実行すると
file name = foo.txt
foo.txt is found
file name = bar.txt
bar.txt is not found
となる。
6. 制御構造を支えるその他のコマンド
・execコマンドは、現在execコマンドを実行しているシェル自体の実行を終了して、指定されたファイルを実行する。例としてexec /bin/shというコマンドなら、これに成功すればshに移るし、失敗すればそのままのシェルで続行される。
・evalコマンドは、コマンドラインcommandlineを引数として与えてそれを実行させる。例えばeval echo helloならhelloだけが表示される。これが使われるのは
- あるコマンドが出力した文字列自体をコマンドとして実行するとき
- 入れ子になった変数を評価するとき
である。1の例としてはeval $SHELL --versionとかで、これでバージョンがわかる。2の例としてはeval '$'$tempで、これで変数tempが指す変数の中身を参照できる。
・exitコマンドは、そのシェルの実行を終了させるもの。exit exprとすると式exprの値を終了ステータスとして終了する。正常終了ならexit 1で、異常終了ならexit 0とするというのが普通である。式exprは省略可能。
・sourceコマンドは、cshやbash、zshなら存在する。shの場合は.を使う。bash shell_scriptの場合は新たにbashのプロセスを起動してshell_scriptを実行するが、sourceや.で実行するとそのシェルで実行する。以下のsource_dot.shをsourceとbashでそれぞれ実行すれば、終了後のカレントディレクトリが異なることがわかる。ただしzshは.でsourceの代わりとすることはできなくなった。
echo 1 \$PWD is $PWD
echo 2 ls
ls
echo 3 change dir
cd ..
echo 4 \$PWD is $PWD
echo 5 ls
ls
・gotoコマンドは、goto labelという行があると、label:と書かれた行に移動するコマンド。
シグナル処理
bashとかshではtrapコマンドにより、シェルスクリプト中に受け取ったシグナルに対する処理を指定できる。trap command numならシグナル番号numで指定されたシグナルが発生した場合にコマンドcommandを実行する。trap '' numならシグナル番号numで指定されたシグナルを受け付けない(''を実行する)ようにする。trap numならシグナル番号numで指定されたシグナルの処理をもとに戻す。具体的な例としてCtrl-Cで止めることのできないスクリプトであるloop.shを紹介する。
trap "echo 'you tried to kill me!'" TERM
trap "echo 'you hit CTRL-C!'" INT
while true; do
sleep 5
ps
done
これをbash loop.shとかで起動すると、5秒毎にpsコマンドを実行し続ける。このプロセスはCtrl-Cでは止めることができない。Ctrl-CではINTというシグナルが送られるが、echoコマンドを実行した後に、またwhile文に戻ってしまうためである。Ctrl-Zで一度プロセスを停止して、psコマンドでプロセスID(PID)を調べてkillコマンドを打ってもこのプロセスは生きている(fgコマンドでフォアグラウンドに戻ってもyou tried to kill me!が表示されてまたpsコマンドが実行され続ける)。これはkillコマンドではTERMというシグナルが送られるからである。このプロセスを終了したい時は、kill -KILLコマンドを使えば良い。
ログアウトの時に送られるシグナル
UNIXの設定によっては、ログアウトするとその端末から実行している全てのプロセスにHUP(HangUP)シグナルを送ることがある。HUPシグナルに対する処理を特にしていないプロセスはHUPシグナルを受け取ると終了する。ログアウト後も実行させたいプロセスはnohupの後にコマンドをつけて起動する。例えばnohup python aa.py &としておけば、ログアウトしたあともpython aa.pyは動き続ける。
複雑な置換
変数nに変数名が格納されているとき、その値を取り出すために${$n}と書いても置換が行われない。これは$nの変数置換後には、もう変数置換を行わないからである。その変数の値を取り出すにはevalなどを利用してもう一度評価させる必要がある。具体的には以下。
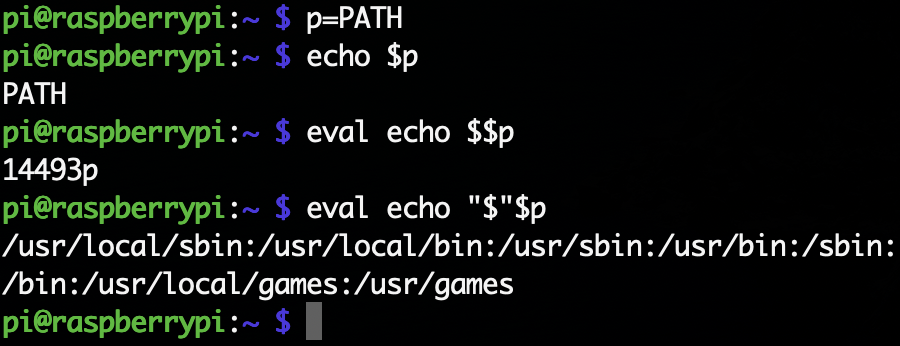
シェルは置換(エイリアス置換、ヒストリ置換、変数置換、コマンド置換、ファイル名置換など)が全て終わった後でコマンドラインを引数に分解する。そのため、変数の値が空文字列であったり空白を含む場合であると、n番目の引数と取得するといった時に添字がずれる可能性があるので注意。
組み込みコマンド
シェル自身が実行するコマンドを組み込みコマンドという。組み込みコマンドを内部コマンドと呼び、それ以外のコマンドを外部コマンドということもある。あるシェルのプロセスの状態を参照したり、状態を変更することは基本的に他のプロセスからはできない。よってシェルのプロセスのカレントワーキングディレクトリを変更するcdとかは組み込みコマンドである。killコマンドのように組み込みコマンドと外部コマンドの両方が存在する場合もあるが、外部コマンドのkillはシェルが記憶しているジョブ番号を利用できないという制約がある。
bashを支えるコマンド
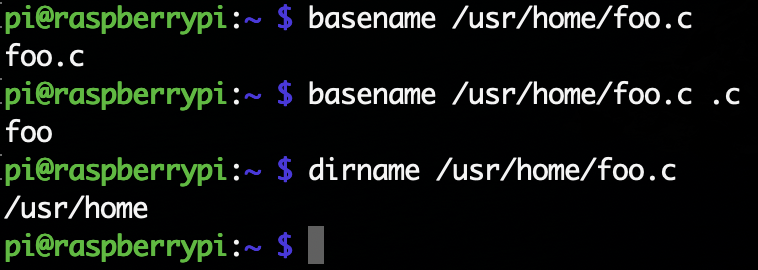
・basenameコマンドとdirnameコマンド
basenameコマンドはパス名からディレクトリと拡張子を取り去ったものを出力する。拡張子を指定しなければ、パス名からディレクトリを取り除いたものを出す。
dirnameコマンドはパス名からファイル名を取り去ったものを出力する。実行例を見る方がわかりやすい。
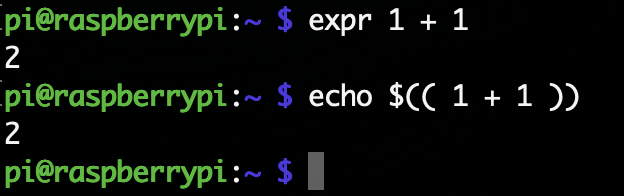
・exprコマンド
引数の式を計算し、計算結果を標準出力に出力するコマンド。expr expという形式。式expには様々な形式があり、その一部を示す。
| 指定 | 意味 |
|---|---|
exp1 & exp2 |
式exp1と式exp2のどちらかが空や0なら0を出力し、そうでないとexp2を出力する |
exp1 = exp2 |
式exp1とexp2が整数で一致すれば1を出力し、そうでなければ0を出力する(どちらかが整数でなければ文字列の比較を行う) |
exp1 + exp2 |
加算した結果を出力する(他にも-や*、/、%などが使える) |
length str |
文字列strの長さを出す |
substr string exp1 exp2 |
文字列stringのexp1番目からexp2番目の部分文字列を出力する |
ただしbashには$(( exp ))という構文が組み込まれているので、このコマンドを使わなくても良い。shではよく使うコマンドである。
シェルについて
UNIXでは様々なシェルが使われる。最も代表的なシェルはshやcshだが、現在ではこれらのシェルが使われることはあまりない。なぜなら、これらをベースに色々と機能を強化した便利なシェルがあるからである。代表的なシェルを簡単に紹介する。
- tcshは、cshを元に機能を拡張したシェル。特にコマンドライン編集などの対話的作業のための機能の拡張が充実している。
- kshは、shの機能を強化したシェル。David Korn氏によって開発されたので頭文字のkを取っている。
- bashは、GNUプロジェクトで開発されているシェル。shの構文をベースにしている。
- zshは「決定版のシェル」を目指して作られたシェル。およそ現存するほとんど全ての機能を取り込んでいる野心的なシェル。shの構文をベースにしている。
便利な機能
比較的新しいシェルには、shやcshにない様々な機能がある。代表的な機能について、以下のようなものがある。
- 数値の範囲を指定するファイル名置換
- スペルの自動修正機能
- コマンドの定期的な実行機能
- 高度なリダイレクション
- コマンドの定期的な実行
- 時間を指定したコマンドの実行
- ログインとログアウトの監視機能
シェルはいっぱいあるので、自分にあうシェルを探そう。
終わりに
これでまとめは一旦終わりです。以上の内容はUNIX super textの上巻だけなので、機会があれば下巻もやるかも。なんかミス等あればご指摘いただけると幸いです。